1.本发明属于图像模型识别技术领域,特别是涉及一种基于图像文本学习的小样本番茄病害识别系统及方法。
背景技术:
2.在番茄生产过程中,由于细菌、真菌和病毒等病原体的存在,会导致番茄病害频繁发生。这些病害严重影响蔬菜的质量和产量,每年导致十分严重的经济损失。传统的番茄病害诊断主要通过农学专家或者技术员根据经验进行识别和评估,存在耗时、费力且效率低的问题,难以适应病害快速防治的实时性与准确性要求。在过去几年中,深卷积网络的发展推动了大规模基准数据集如imagenet上通用视觉识别的快速发展。这些基于cnn的模型和算法已被证明可用于解决病害识别问题。因此越来越多的研究聚焦于蔬菜病害检测和分类,并取得了一定的成功。
3.基于深度学习的番茄叶部病害识别模型通常需要大规模的病害叶片图像作为训练数据集,构建时空分布广泛、不同病害阶段的数据集费时耗力,而且在复杂环境下,番茄病害图像中常包含其他植株、土壤、地膜、水管等各种背景。因此,在现有番茄病害数据集中,一方面,病害图像数量不足以支撑训练参数量大的识别模型,另一方面,病害图像的背景单一,直接使用此种类型的数据集进行训练,在真实环境下测试将会存在较大误差。
技术实现要素:
4.本发明的目的是提供一种基于图像文本学习的小样本番茄病害识别系统,以解决上述现有技术存在的问题。
5.为实现上述目的,本发明提供了一种基于图像文本学习的小样本番茄病害识别系统,包括:图像分类模块、文本分类模块及联合分类模块;
6.所述图像分类模块,基于番茄图像得到番茄病害种类的第一预测概率;
7.所述文本分类模块,基于番茄文本信息得到番茄病害种类的第二预测概率;
8.所述联合分类模块,用于将所述第一预测概率和所述第二预测概率进行联合输出,得到病害类别。
9.优选地,所述图像分类模块包括:第一特征提取网络和第一概率计算单元;
10.所述第一特征提取网络,用于对番茄图像进行特征提取,得到第一提取结果;其中所述第一提取结果包括:番茄特征图像和番茄特征图像标签;
11.所述第一概率计算单元,基于所述第一提取结果计算第一预测概率。
12.优选地,所述文本分类模块包括:第二特征提取网络和第二概率计算单元;
13.所述第二特征提取网络,用于对番茄文本信息进行特征提取,得到文本信息提取结果;其中所述番茄文本信息包括:病斑生长的位置信息、叶片的正背面信息及病害特征的本身信息,所述文本信息提取结果包括:番茄特征文本和番茄特征文本标签;
14.所述第二概率计算单元,用于基于所述文本信息提取结果计算第二预测概率。
15.优选地,所述第二特征提取网络包括:上下文网络和当前文本网络;
16.所述上下文网络,通过双向循环神经网络对上下文信息进行特征提取,得到第二提取结果;其中所述上下文信息包括所述病斑生长的位置信息和所述叶片的正背面信息;
17.所述当前文本网络,通过卷积神经网络对当前文本信息进行特征提取,得到第三提取结果;其中所述当前文本信息为所述病害特征的本身信息。
18.优选地,所述联合分类模块包括:联合输出单元和病害识别单元;
19.所述联合输出单元,用于将所述番茄图像和所述番茄文本进行联合输出,得到第三预测概率;
20.所述病害识别单元,基于所述第三预测概率对番茄病害进行识别,得到病害类别。
21.另一方面,为实现上述技术目的,本发明提供了一种基于图像文本学习的小样本番茄病害识别方法,包括以下步骤:
22.基于番茄图像得到番茄病害种类的第一预测概率;
23.基于番茄文本信息得到番茄病害种类的第二预测概率;
24.将所述第一预测概率和所述第二预测概率进行联合输出,得到病害类别。
25.优选地,得到番茄病害种类的第一预测概率的过程包括:
26.对番茄图像进行特征提取,得到第一提取结果;其中所述第一提取结果包括:番茄特征图像和番茄特征图像标签;基于所述第一提取结果计算第一预测概率。
27.优选地,得到番茄病害种类的第二预测概率的过程包括:
28.对番茄文本信息进行特征提取,得到文本信息提取结果;基于所述文本信息提取结果计算第二预测概率;其中所述番茄文本信息包括:病斑生长的位置信息、叶片的正背面信息及病害特征的本身信息,所述文本信息提取结果包括:番茄特征文本和番茄特征文本标签。
29.优选地,对番茄文本信息进行特征提取的过程包括:
30.通过双向循环神经网络对上下文信息进行特征提取,得到第二提取结果;其中所述上下文信息包括所述病斑生长的位置信息和所述叶片的正背面信息;
31.通过卷积神经网络对当前文本信息进行特征提取,得到第三提取结果;其中所述当前文本信息为所述病害特征的本身信息;
32.其中所述文本信息提取结果包括:所述病斑生长的位置信息、所述叶片的正背面信息及所述病害特征的本身信息。
33.优选地,得到病害类别的过程包括:
34.将所述番茄图像和所述番茄文本进行联合输出,得到第三预测概率;基于所述第三预测概率对番茄病害进行识别,得到病害类别。
35.本发明的技术效果为:本发明基于番茄图像得到番茄病害种类的第一预测概率,基于番茄文本得到番茄病害种类的第二预测概率,以图像通道和文本通道两种通道并行的方式进行病害种类分类;本发明在图像数据集的基础上,以文本的形式,增加了病害描述信息,从而构成病害图像-文本对作为病害识别模型的数据集。本发明在文本通道中通过描述病害症状,进一步增强了病害的特征表达,削弱了病害图像背景对识别过程带来的影响。本发明通过联合分类模块,能够将图像-文本对输入模型,最终模型能够输出番茄病害类别。
附图说明
36.构成本技术的一部分的附图用来提供对本技术的进一步理解,本技术的示意性实施例及其说明用于解释本技术,并不构成对本技术的不当限定。在附图中:
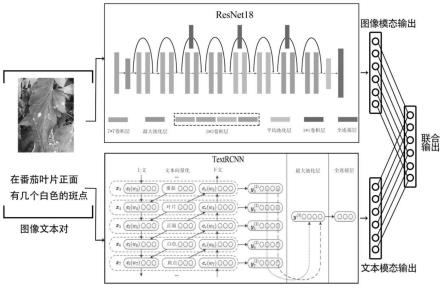
37.图1为本发明实施例中的小样本番茄病害识别网络结构示意图;
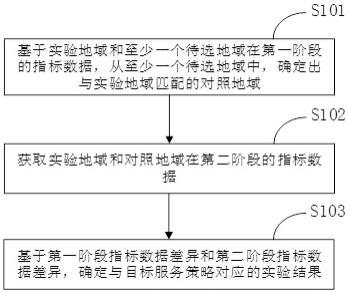
38.图2为本发明实施例中的小样本番茄病害识别方法流程图。
具体实施方式
39.需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本技术。
40.需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
41.实施例一
42.如图1所示,本实施例中提供一种基于图像文本学习的小样本番茄病害识别系统,包括:图像分类模块、文本分类模块及联合分类模块;
43.图像分类模块,基于番茄图像得到番茄病害种类的第一预测概率;
44.文本分类模块,基于番茄文本信息得到番茄病害种类的第二预测概率;
45.联合分类模块,用于将所述第一预测概率和所述第二预测概率进行联合输出,得到病害类别。
46.在一些实施例中,图像分类模块包括:第一特征提取网络和第一概率计算单元;第一特征提取网络,用于对番茄图像进行特征提取,得到第一提取结果;其中第一提取结果包括:番茄特征图像和番茄特征图像标签;第一概率计算单元,基于所述第一提取结果计算第一预测概率。
47.本实施例中,图像分类模块具体包括:不同结构的图像特征提取网络针对不同的识别任务展现了其不同的优越性,其网络大多由卷积层、池化层以及全连接层组成。在本网络结构中,综合考虑网络性能与模型大小,使用resnet18作为图像分支的特征提取网络img-net。
48.给定图像i和图像标签l作为img-net的输入,经过特征提取后得到图像分支的输出[p
i1
,p
i2
,p
i3
,p
i4
,p
i5
]
img
,如式(1)所示。
[0049]
[p
i1
,p
i2
,p
i3
,p
i4
,p
i5
]
img
=s(w(i),l)
ꢀꢀꢀ
(1)
[0050]
其中w(
·
)表示特征提取网络img-net的提取结果,s(
·
)为softmax函数,p代表每种病害种类的预测概率。
[0051]
在一些实施例中,文本分类模块包括:第二特征提取网络和第二概率计算单元;第二特征提取网络,用于对番茄文本信息进行特征提取,得到文本信息提取结果;其中番茄文本信息包括:病斑生长的位置信息、叶片的正背面信息及病害特征的本身信息,文本信息提取结果包括:番茄特征文本和番茄特征文本标签;第二概率计算单元,用于基于所述文本信息提取结果计算第二预测概率。
[0052]
在一些实施例中,第二特征提取网络包括:上下文网络和当前文本网络;上下文网络,通过双向循环神经网络对上下文信息进行特征提取,得到第二提取结果;其中上下文信
息包括病斑生长的位置信息和叶片的正背面信息;当前文本网络,通过卷积神经网络对当前文本信息进行特征提取,得到第三提取结果;其中当前文本信息为所述病害特征的本身信息。
[0053]
本实施例中,文本分类模块具体包括:与图像特征提取网络不同的是,为了更好的提取文本之间的上下文信息,文本特征提取网络大多由循环神经网络层组成,但是在蔬菜病害描述文本中,特征提取网络不仅要提取文本之间的上下文信息(比如病斑生长的位置、叶片的正背面信息等),对于病害特征本身的信息也十分重要,而卷积层对比循环神经网络层具有提取特定特征的优势,因此在本网络结构中,使用textrcnn作为文本分支的特征提取网络text-net。
[0054]
给定预处理后的文本c(ti)和文本标签l作为text-net的输入,先将文本c(ti)经过双向循环神经网络(lstm)后得到文本的上下文特征c
l
(ti)和cr(ti),其计算公式如式(2)和(3)所示。
[0055]cl
(ti)=f(w
(l)cl
(t
i-1
) w
(sl)
e(t
i-1
))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0056]cr
(ti)=f(w
(r)cr
(t
i 1
) w
(sr)
e(t
i 1
))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0057]
其中f(
·
)为tanh激活函数,ti为当前向量化文本,t
i-1
和t
i 1
分别为向量化文本的上文和下文,w
(l)
和w
(r)
分别为左右两个循环神经网络隐含层向下一个隐含层的转换矩阵,w
(sl)
和w
(sr)
分别为当前向量化文本语义与下一个向量化文本的左语义与右语义的结合矩阵,c
l
和cr分别为当前向量化文本的左向量化文本和右向量化文本,e(t
i-1
)和e(t
i 1
)分别表示当前向量化文本的左词嵌入向量和右词嵌入向量。
[0058]
将得到的上下文特征与当前文本特征拼接后作为特定特征提取器的输入,其中特定特征提取器使用最大池化层(maxpool),提取向量化文本中特征最明显的文本特征,最后得到文本分支的输出[p
t1
,p
t2
,p
t3
,p
t4
,p
t5
]
text
,如式(4)所示。
[0059]
[p
t1
,p
t2
,p
t3
,p
t4
,p
t5
]
text
=s(fc(m(c
l
(ti) c(ti) cr(ti))),l)
ꢀꢀꢀ
(4)
[0060]
其中s(
·
)为softmax函数,fc(
·
)为全连接层,m(
·
)为最大池化层(maxpool),p代表每种病害种类的预测概率。
[0061]
在一些实施例中,联合分类模块包括:联合输出单元和病害识别单元;联合输出单元,用于将番茄图像和番茄文本进行联合输出,得到第三预测概率;病害识别单元,基于第三预测概率对番茄病害进行识别,得到病害类别。
[0062]
本实施例中,联合分类模块具体包括:img-net和text-net分别从不同的角度提取图像-文本对中不同模态的特征,进行特征融合后可以结合两种模态的特征,进而使大概率分类值与小概率分类值之间的差值进一步增大,从而使联合分类器的分类置信度增加。联合输出公式如式(5)所示。
[0063]
[p
j1
,p
j2
,p
j3
,p
j4
,p
j5
]
joint
=[p
i1 t1
,p
i2 t2
,p
i3 t3
,p
i4 t4
,p
i5 t5
]
ꢀꢀꢀ
(5)
[0064]
其特征联合的损失函数如式(6)所示。
[0065][0066]
其中t为样本类别数,和为标签值,且两者值相同,和分别为text-net和img-net的预测结果概率值。
[0067]
本实施例中,图像分类模块和文本分类模块的学习率均为0.0001,优化器采用adam,批处理大小为16。模型训练过程包括以下步骤:
[0068]
步骤一,数据预处理。为了增加原始数据集的多样性需要对原始数据集进行预处理,由于原始数据集为实地拍摄并且考虑了真实应用中的情况,因此不对病害图像做数据增强处理,只将原始图像统一重新调整大小为224
×
224像素,对病害描述文本数据采用词袋模型进行向量化,向量化长度为20。
[0069]
步骤二,对整个网络进行50轮次的训练。
[0070]
步骤三,网络测试,在测试集上对网络进行测试。
[0071]
本实施例的有益效果:
[0072]
本实施例以图像通道和文本通道两种通道并行的方式进行病害种类分类;本实施例在病害图像数据的基础上增加病害描述文本信息,辅助诊断过程,使得病害识别模型可以在少量图像-文本对的基础上得到很好的效果。不同病害在叶片上的表现各不相同,针对病害特征在叶片正面和背面都存在的情况,增加了病害叶片的背面图像,辅助病害诊断过程。
[0073]
与现有病害识别模型相比,本发明构建了图像与文本协同表征学习的蔬菜病害识别模型(itc-net),利用了病害图像特征与文本描述之间的相关性和互补性,在复杂环境蔬菜病害小样本数据集中取得了超过图像模态单独训练和文本模态单独训练的效果,其测试集的准确率、精确率、灵敏度和特异性分别为99.48%、98.90%、98.78%和99.66%。本文工作为实际农业场景下,基于图像文本协同表征学习的小样本病害识别提供可行方案。
[0074]
实施例二
[0075]
如图2所示,本实施例提供了一种基于图像文本学习的小样本番茄病害识别方法,包括以下步骤:
[0076]
基于番茄图像得到番茄病害种类的第一预测概率;
[0077]
基于番茄文本信息得到番茄病害种类的第二预测概率;
[0078]
将第一预测概率和第二预测概率进行联合输出,得到病害类别。
[0079]
在一些实施例中,得到番茄病害种类的第一预测概率的过程包括:对番茄图像进行特征提取,得到第一提取结果;其中所述第一提取结果包括:番茄特征图像和番茄特征图像标签;基于所述第一提取结果计算第一预测概率。
[0080]
在一些实施例中,得到番茄病害种类的第二预测概率的过程包括:对番茄文本信息进行特征提取,得到文本信息提取结果;基于所述文本信息提取结果计算第二预测概率;其中所述番茄文本信息包括:病斑生长的位置信息、叶片的正背面信息及病害特征的本身信息,所述文本信息提取结果包括:番茄特征文本和番茄特征文本标签。
[0081]
在一些实施例中,对番茄文本信息进行特征提取的过程包括:通过双向循环神经网络对上下文信息进行特征提取,得到第二提取结果;其中所述上下文信息包括所述病斑生长的位置信息和所述叶片的正背面信息;通过卷积神经网络对当前文本信息进行特征提取,得到第三提取结果;其中所述当前文本信息为所述病害特征的本身信息;其中文本信息提取结果包括:病斑生长的位置信息、叶片的正背面信息及病害特征的本身信息。
[0082]
在一些实施例中,得到病害类别的过程包括:将番茄图像和番茄文本进行联合输出,得到第三预测概率;基于第三预测概率对番茄病害进行识别,得到病害类别。
[0083]
以上所述,仅为本技术较佳的具体实施方式,但本技术的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本技术的保护范围之内。因此,本技术的保护范围应该以权利要求的保护范围为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。