1.本技术实施例涉及金融科技(fintech)的数据处理技术领域,涉及但不限于一种作业调度方法、作业调度系统及存储介质。
背景技术:
2.随着计算机计算的发展,越来越多的技术应用在金融领域,传统金融业正在逐步向金融科技(fintech)转变,然而,由于金融行业的安全性、实时性要求,金融科技也对技术提出了更高的要求。金融科技领域下,随着银行金融体系的不断丰富和完善,以及金融系统中的数据量急速增长,金融系统通常使用hadoop(分布式计算平台)进行数据处理,hadoop平台中的核心组件yarn(yet another resource negotiator,另一种资源协调者),是一种新的资源管理器。这里,yarn是一个通用资源管理系统,为hadoop计算任务提供统一的资源管理和调度。
3.相关技术中,针对批处理作业调度方法是,作业调度系统基于每个作业在执行前的等待时长,以及在上一周期n内的平均执行时长,得到每个作业的响应比;然后,从批处理作业中选出响应比最高的作业进行调度,即将响应比最高的作业的资源请求提交至大数据计算平台hadoop,以使大数据计算平台根据存储的数据和资源请求为响应比最高的作业分配资源,进而使该作业调度执行。然而,在作业历史执行过程中,由于yarn实际资源分配问题,得到的平均执行时长不准确,进而导致计算的响应比不准确的问题。
技术实现要素:
4.本技术实施例提供一种作业调度方法、作业调度系统及存储介质,以解决相关技术中由于yarn实际资源分配问题,得到的平均执行时长不准确,进而导致计算的响应比不准确的问题。
5.本技术实施例的技术方案是这样实现的:
6.本技术实施例提供一种作业调度方法,包括:
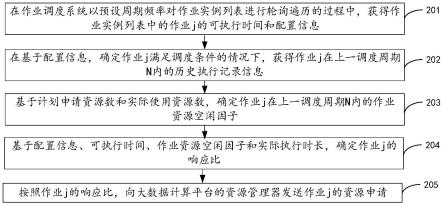
7.在作业调度系统以预设周期频率对作业实例列表进行轮询遍历的过程中,获得所述作业实例列表中的作业j的可执行时间和配置信息;
8.在基于所述配置信息,确定所述作业j满足调度条件的情况下,获得所述作业j在上一调度周期n内的历史执行记录信息;其中,所述历史执行记录信息包括实际执行时长t、计划申请资源数和实际使用资源数;
9.基于所述计划申请资源数和所述实际使用资源数,确定所述作业j在所述上一调度周期n内的作业资源空闲因子;
10.基于所述配置信息、所述可执行时间、所述作业资源空闲因子和所述实际执行时长,确定所述作业j的响应比;
11.按照所述作业j的响应比,向大数据计算平台的资源管理器发送所述作业j的资源申请。
12.本技术实施例提供一种作业调度装置,包括:
13.获得模块,用于在作业调度系统以预设周期频率对作业实例列表进行轮询遍历的过程中,获得所述作业实例列表中的作业j的可执行时间和配置信息;
14.所述获得模块,还用于在基于所述配置信息,确定所述作业j满足调度条件的情况下,获得所述作业j在上一调度周期n内的历史执行记录信息;其中,所述历史执行记录信息包括实际执行时长t、计划申请资源数和实际使用资源数;
15.确定模块,用于基于所述计划申请资源数和所述实际使用资源数,确定所述作业j在所述上一调度周期n内的作业资源空闲因子;
16.所述确定模块,还用于基于所述配置信息、所述可执行时间、所述作业资源空闲因子和所述实际执行时长,确定所述作业j的响应比;
17.发送模块,用于按照所述作业j的响应比,向大数据计算平台的资源管理器发送所述作业j的资源申请。
18.本技术实施例提供一种作业调度系统,包括:
19.存储器,用于存储可执行指令;
20.处理器,用于执行存储器中存储的可执行指令时,实现上述的方法。
21.本技术实施例提供一种存储介质,存储有可执行指令,用于引起处理器执行时,实现上述的方法。
22.本技术实施例具有以下有益效果:
23.本技术实施例通过引入作业资源空闲因子,解决了相关技术中因资源空闲问题导致的计算出的响应比不准确,进而导致作业调度顺序出现差错的问题;这里,作业调度系统计算不同资源状态下的作业资源空闲因子,并基于不同资源状态下作业的执行时长和对应的作业资源空闲因子,计算出作业相对于处于资源充足状态下的执行时长,如此,提高了作业的平均执行时长的准确性,从而提高了作业在当前时刻的响应比的准确性,使得作业调度系统更合理的调度作业的执行;同时,降低了作业处于不同资源状态时作业响应值的偏差率,优化了作业的调度顺序。
附图说明
24.图1a是相关技术中提供的在资源紧张时刻作业k的执行时间线的意图;
25.图1b是相关技术中提供的在资源充足时刻作业k的执行时间线的意图;
26.图2a是相关技术中提供的在资源紧张时刻作业k的执行情况的示意图;
27.图2b是相关技术中提供的在资源充足时刻作业k的执行情况的示意图;
28.图3是本技术实施例提供的终端的一个可选的架构示意图;
29.图4是本技术实施例提供的作业调度方法的一个可选的流程示意图;
30.图5是本技术实施例提供的多个作业的执行顺序的示意图;
31.图6是本技术实施例提供的作业调度方法的一个可选的流程示意图;
32.图7是本技术实施例提供的作业调度方法的一个可选的流程示意图;
33.图8是本技术实施例提供的根据重要程度和紧急程度,对作业进行划分的四种情况的示意图;
34.图9是本技术实施例提供的作业调度方法的一个可选的流程示意图;
35.图10是本技术实施例提供的作业调度方法的一个可选的流程示意图;
36.图11是本技术实施例提供的作业调度方法的一个可选的流程示意图;
37.图12是本技术实施例提供的作业调度方法的一个可选的流程示意图;
38.图13是本技术实施例提供的作业调度方法的一个可选的流程示意图;
39.图14是本技术实施例提供的作业调度方法的一个可选的流程示意图。
具体实施方式
40.为了使本技术的目的、技术方案和优点更加清楚,下面将结合附图对本技术作进一步地详细描述,所描述的实施例不应视为对本技术的限制,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本技术保护的范围。
41.在以下的描述中,涉及到“一些实施例”,其描述了所有可能实施例的子集,但是可以理解,“一些实施例”可以是所有可能实施例的相同子集或不同子集,并且可以在不冲突的情况下相互结合。除非另有定义,本技术实施例所使用的所有的技术和科学术语与属于本技术实施例的技术领域的技术人员通常理解的含义相同。本技术实施例所使用的术语只是为了描述本技术实施例的目的,不是旨在限制本技术。
42.为了更好地理解本技术实施例中提供的作业调度方法,首先对相关技术中的作业调度方法进行说明:
43.作业调度系统作为基于工作流的批处理作业调度器,负责按依赖和预定的调度策略来调度大数据作业。作业调度系统提交计算作业到大数据计算平台hadoop,大数据计算平台则根据存储的数据和调度系统提交的计算逻辑计算出对应的数据。
44.相关技术中,批处理作业调度方法使用的是最高响应比优先算法(highest response_ratio next,hrn),hrn调度算法考虑每个作业的等待时间长短和在上一周期n内的平均执行时长,得到每个作业的响应比,从所有作业中选出响应比最高的作业投入执行。
45.这里,计算响应比r可通过如下(公式1)得到,
[0046][0047]
其中,t为上一周期n内的平均执行时长,w为作业在后备状态队列中的等待时长。当作业调度系统要进行作业调度时,系统计算每个作业的响应比,将对应的响应比r最大的作业投入执行。这样,即使是长作业,随着它等待时长的增加,w/t也就随着增加,也就有机会获得优先调度执行。
[0048]
然而,上一周期n内的平均执行时长t指的是针对hive on spark作业的预估执行时间,采用上述(公式1)的计算方式,存在因yarn实际资源分配问题造成的偏差较大;也就是说,在相同的作业相同的数据量,不同的yarn资源充足和不充足的情况下的平均执行时长存在较大差距。因平均执行时长t的不准确,造成了最高响应比优先算法投递不能如预期效果,即实际为短作业被预估为长作业,相同的等待时长w下,最高响应比相比其他作业可能被错误的计算成更低的值,导致晚于其他作业的投递。
[0049]
示例性的,创建批处理作业的作业标识为ads_rpt.blc_scale_trade_1d,将该作业简称为作业k,且该作业k的作业类型为hive on spark类型,作业的资源需求为需申请40个执行进程(executors)。作业调度系统需要在同日的05:20(资源紧张时刻)与21:28(资源
充足时刻)分别提交作业k,并通过spark监控(user interface,ui)界面分析作业k的执行耗时情况,参照图1a、图1b、图2a和图2b所示,图1a示出的是在资源紧张时刻作业k的执行时间线的示意图,图1b示出的是在资源充足时刻作业k的执行时间线的示意图,图2a示出的是在资源紧张时刻作业k的执行情况的示意图,图2b示出的是在资源充足时刻作业k的执行情况的示意图。
[0050]
参见图1a和图2a,当作业调度系统中的作业k在5:20跑批时,由于yarn集资源紧张,在作业k(job0)启动之前,只有驱动模块(driver)启动;在job0执行过程中陆续只有9个executor启动,由于作业k的资源需求为40个executor,故剩下的executor在05:45之后才陆续添加进来,且作业k在资源紧张时刻的执行时长为16分钟(minutes,min)。需要说明的是,由于spark任务的特性,只要申请到资源,集群就会根据已有的资源进行作业跑批,而不是等待所有资源申请到才开始跑批。
[0051]
参见图1b和图2b,当作业调度系统中的作业k在21:28跑批时,由于yarn集资源充足(或空闲),在job0启动之前,job0执行所需要的40个executor均已启动,且作业k在资源充足时刻的执行时长为6.6min。明显,yarn集资源充足的情况下,job0的执行时长大幅缩短。
[0052]
这里,作业k在资源紧张时刻的实际使用资源是9个executor,实际执行时长为16min=960s,等待时长w假设为300s,通过上述(公式1),计算出作业k在资源紧张时刻的响应比ru为1.3125。作业k在资源充足时刻的实际使用资源是40个executor,实际执行时长为6.6min=396s,等待时长w假设也为300s,通过上述(公式1),计算作业k在资源充足时刻的响应比re为1.7576;进一步地,确定作业k在资源紧张与资源充足时刻的响应比的偏差率rd为:
[0053]
由上述可知,在同样的作业同样的数据量(计算量),不同的资源分配条件下,作业k的执行时长存在较大差距,从而导致得到的作业k的平均执行时长不准确,进而导致得到的作业k的响应比r值不准确,最终导致与其他作业竞争性降低的问题。
[0054]
下面说明本技术实施例提供的作业调度系统的示例性应用,本技术实施例提供的作业调度系统可以实施为笔记本电脑,平板电脑,台式计算机,智能机器人等任意具有屏幕显示功能的终端,也可以实施为服务器。下面,将说明作业调度系统实施为终端时的示例性应用。
[0055]
参见图3,图3是本技术实施例提供的终端100的结构示意图,图3所示的终端100包括:至少一个处理器110、至少一个网络接口120、用户接口130和存储器150。终端100中的各个组件通过总线系统140耦合在一起。可理解,总线系统140用于实现这些组件之间的连接通信。总线系统140除包括数据总线之外,还包括电源总线、控制总线和状态信号总线。但是为了清楚说明起见,在图3中将各种总线都标为总线系统140。
[0056]
处理器110可以是一种集成电路芯片,具有信号的处理能力,例如通用处理器、数字信号处理器(dsp,digital signal processor),或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等,其中,通用处理器可以是微处理器或者任何常规的处理器等。
[0057]
用户接口130包括使得能够呈现媒体内容的一个或多个输出装置131,包括一个或
多个扬声器和/或一个或多个视觉显示屏。用户接口130还包括一个或多个输入装置132,包括有助于用户输入的用户接口部件,比如键盘、鼠标、麦克风、触屏显示屏、摄像头、其他输入按钮和控件。
[0058]
存储器150可以是可移除的,不可移除的或其组合。示例性地硬件设备包括固态存储器,硬盘驱动器,光盘驱动器等。存储器150可选地包括在物理位置上远离处理器110的一个或多个存储设备。存储器150包括易失性存储器或非易失性存储器,也可包括易失性和非易失性存储器两者。非易失性存储器可以是只读存储器(read only memory,rom),易失性存储器可以是随机存取存储器(random access memory,ram)。本技术实施例描述的存储器150旨在包括任意适合类型的存储器。在一些实施例中,存储器150能够存储数据以支持各种操作,这些数据的示例包括程序、模块和数据结构或者其子集或超集,下面示例性说明。
[0059]
操作系统151,包括用于处理各种基本系统服务和执行硬件相关任务的系统程序,例如框架层、核心库层、驱动层等,用于实现各种基础业务以及处理基于硬件的任务;
[0060]
网络通信模块152,用于经由一个或多个(有线或无线)网络接口120到达其他计算设备,示例性地网络接口120包括:蓝牙、无线相容性认证(wifi)、和通用串行总线(universal serial bus,usb)等;
[0061]
输入处理模块153,用于对一个或多个来自一个或多个输入装置132之一的一个或多个用户输入或互动进行检测以及翻译所检测的输入或互动。
[0062]
在一些实施例中,本技术实施例提供的装置可以采用软件方式实现,图3示出了存储在存储器150中的一种作业调度装置154,该作业调度装置154可以是终端100中的作业调度装置,其可以是程序和插件等形式的软件,包括以下软件模块:获得模块1541、确定模块1542、发送模块1543和处理模块1544,这些模块是逻辑上的,因此根据所实现的功能可以进行任意的组合或进一步拆分。将在下文中说明各个模块的功能。
[0063]
在另一些实施例中,本技术实施例提供的装置可以采用硬件方式实现,作为示例,本技术实施例提供的装置可以是采用硬件译码处理器形式的处理器,其被编程以执行本技术实施例提供的作业调度方法,例如,硬件译码处理器形式的处理器可以采用一个或多个应用专用集成电路(application specific integrated circuit,asic)、dsp、可编程逻辑器件(programmable logic device,pld)、复杂可编程逻辑器件(complex programmable logic device,cpld)、现场可编程门阵列(field-programmable gate array,fpga)或其他电子元件。
[0064]
下面将结合本技术实施例提供的终端100的示例性应用和实施,说明本技术实施例提供的作业调度方法。参见图4,图4是本技术实施例提供的作业调度方法的一个可选的流程示意图,将结合图4示出的步骤进行说明,
[0065]
步骤201、在作业调度系统以预设周期频率对作业实例列表进行轮询遍历的过程中,获得作业实例列表中的作业j的可执行时间和配置信息。
[0066]
本技术实施例中,预设周期频率是预先设置的固定的周期频率,示例性的,预设周期频率可以为5秒(second,s)。
[0067]
本技术实施例中,可执行时间可以理解为作业当前可执行的起始时间。
[0068]
本技术实施例中,作业可以理解为对数据执行的操作,作业j为作业实例列表中的至少一个。作业包括短作业和长作业,短作业可以理解为执行时间短的作业,长作业可以理
解为执行时间长的作业。
[0069]
本技术实施例中,作业实例可以理解为每个调度周期内执行的作业;示例性的,若按每天执行一次为调度周期的作业,则每天执行的作业即为该作业的实例。作业实例列表可以理解为多个作业组成的列表。
[0070]
本技术实施例中,作业的配置信息包括但不限于作业标识、作业描述、作业类型、作业的依赖作业、调度周期内的起始时间、超时起始时间、资源需求量、预估执行时长、作业固定优先级和可重试次数。
[0071]
在一种可实现的大数据离线计算场景中,参照图5所示,作业调度系统中存在一个大的离线计算作业m,大作业m可以分成h、a、b和c四个小作业,作业a和作业b的执行依赖作业h的执行结果,作业a和作业b之间没有依赖关系,作业c的执行依赖作业a和作业b的执行结果,作业h、a、b和c之间的执行过程是一个有向无环图(directed acylic graph,dag)。这里,表1中示例性的展示了不同类别的作业的配置信息。
[0072][0073]
表1
[0074]
步骤202、在基于配置信息,确定作业j满足调度条件的情况下,获得作业j在上一调度周期n内的历史执行记录信息。
[0075]
其中,历史执行记录信息包括实际执行时长、计划申请资源数和实际使用资源数,当然,历史执行记录信息还可以包括作业执行日期、作业名称、实际重试次数和作业执行时的资源情况。
[0076]
本技术实施例中,计划申请资源数是从作业的配置信息中确定的需要申请的资源数,实际使用资源数是作业在实际的执行过程中,分配给作业a的实际资源数。
[0077]
需要说明的是,作业在实际执行过程中的实际使用的资源数e_used,与实际执行时长t的关系为:
[0078]
在一种可实现的场景中,以作业a和作业b为例,参照图5和表1所示,假设调度周期n为5天,且当前日期为20220506,作业a和作业b每天执行一次,故作业a和作业b在上一调度周期n(20220501-20220505)的历史执行记录信息如表2所示,
[0079][0080]
表2
[0081]
本技术实施例中,调度周期n为预先设置的时长;示例性的,n可以以周为单位设置的时长,n还可以以月为单位设置的时长,当然,n还可以为其他时长,对此,本技术不做具体限制。作业的执行过程可以理解为作业在预先设置的时长内,以固定时间间隔按同样的顺序重复执行的过程。
[0082]
本技术实施例中,实际执行时长可以理解为作业j在上一调度周期n中第n次执行时的执行时长,其中,n为大于或等于1,且小于或等于n的整数,n为一个调度周期内的总天数,n为正整数。
[0083]
在一些实施例中,作业j的配置信息包括作业j的作业类型、作业j的依赖作业和作业j的调度周期内的起始时间,针对步骤202中的基于配置信息,确定作业j满足调度条件的过程可以通过如下方式实现:作业类型为预设作业类型,作业j的依赖作业已执行完成,以及作业j的可执行时间达到调度周期内的起始时间。
[0084]
本技术实施例中,作业类型包括但不限于spark on hive类型和java类型。这里,spark on hive可以理解为数据存储在hive中,用户处理和分析数据使用的hql,但用户提交执行时,底层会经过hive的解析优化编译,最后以spark作业的形式运行。需要说明的是,由于java的特性,只有申请到所有资源,集群才会根据已有的资源进行作业跑批。
[0085]
本技术实施例中,预设作业类型可以为spark on hive类型。
[0086]
本技术实施例中,作业j的依赖作业已执行成功可以理解完作业j的上游作业已执行完成。
[0087]
本技术实施例中,作业j的可执行时间达到调度周期内的起始时间,可理解为作业j的可执行时间在调度周期内的起始时间之后。示例性的,若设置的作业j的调度周期内的起始时间为每天凌晨05:00:00,作业j当前可执行时间为05:30:05,作业j当前可执行时间在作业j的调度周期内的起始时间之后,故作业j的可执行时间达到调度周期内的起始时间。
[0088]
需要说明的是,上述spark是专为大规模数据处理而设计的快速通用的计算引擎,spark使用了内存运算技术,能在数据尚未写入硬盘时在内存分析运算。
[0089]
上述hive是基于hadoop的一个数据仓库工具,用于数据提取、转化、加载,这是一种可以存储、查询和分析存储在hadoop中的大规模数据的机制,hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供sql查询功能。
[0090]
上述hive sql可以将sql语句转变成mapreduce任务来执行,通过自身的sql去查询分析存储在hadoop分布式文件系统中的数据。hive中通过类似sql语句实现快速mapreduce统计,使不熟悉mapreduce的用户很方便的利用sql语言查询、汇总、分析数据。
[0091]
在一些可实现场景中,若作业j的依赖作业已执行完成,且作业j的可执行时间达到调度周期内的起始时间,但作业j的作业类型不为预设作业类型,作业调度系统可按照相关技术中的作业调度方法计算作业j的响应比r。
[0092]
步骤203、基于计划申请资源数和实际使用资源数,确定作业j在上一调度周期n内的作业资源空闲因子。
[0093]
本技术实施例中,作业资源空闲因子是通过作业j预计申请的计划申请资源数和实际使用资源数确定的。
[0094]
步骤204、基于配置信息、可执行时间、作业资源空闲因子和实际执行时长,确定作业j的响应比。
[0095]
步骤205、按照作业j的响应比,向大数据计算平台的资源管理器发送作业j的资源申请。
[0096]
本技术实施例中,大数据计算平台可以是hadoop,资源管理器可以是yarn。在yarn中,资源分配单元是执行进程(executor),executor是spark程序中的一个java虚拟机(java virtual machine,jvm)进程,负责执行spark作业的具体任务(task);spark任务通过设置单个executor使用的中央处理器(central processing unit,cpu)核数以及内存乘以executor的个数来设置需要整个spark作业需要申请的资源。
[0097]
这里,资源包括但不限于操作系统的内存(memory,mem)、cpu、输入/输出(input/output,io)传输速度、磁盘和网络带宽。
[0098]
本技术实施例中,首先,在作业调度系统以预设周期频率对作业实例列表进行轮询遍历的过程中,获得作业实例列表中的作业j的可执行时间和配置信息;接着在基于配置信息,确定作业j满足调度条件的情况下,获得作业j在上一调度周期n内的历史执行记录信息,如实际执行时长、计划申请资源数和实际使用资源数;然后,基于计划申请资源数和实际使用资源数,确定作业j在上一调度周期n内的作业资源空闲因子;进一步地,基于配置信息、可执行时间、作业资源空闲因子z和实际执行时长t,确定作业j的响应比;最后,在存在满足条件的多个作业j的情况下,按照响应比的大小确定作业的优先级,并向大数据计算平台的资源管理器优先发送优先级高的作业的资源申请。
[0099]
本技术实施例提供一种作业调度方法,通过在作业调度系统以预设周期频率对作业实例列表进行轮询遍历的过程中,获得作业实例列表中的作业j的可执行时间和配置信息;在基于配置信息,确定作业j满足调度条件的情况下,获得作业j在上一调度周期n内的历史执行记录信息;其中,历史执行记录信息包括实际执行时长t、计划申请资源数和实际使用资源数;基于计划申请资源数和实际使用资源数,确定作业j在上一调度周期n内的作业资源空闲因子;基于配置信息、可执行时间、作业资源空闲因子和实际执行时长,确定作业j的响应比;按照作业j的响应比,向大数据计算平台的资源管理器发送作业j的资源申请。如此,通过引入作业资源空闲因子,解决了相关技术中因资源空闲问题导致的计算出的响应比不准确,进而导致作业调度顺序出现差错的问题;这里,作业调度系统计算不同资源状态下的作业资源空闲因子,并基于不同资源状态下作业的执行时长和对应的作业资源空
闲因子,计算出作业相对于处于资源充足状态下的执行时长,如此,提高了作业的平均执行时长的准确性,从而提高了作业在当前时刻的响应比的准确性,使得作业调度系统更合理的调度作业的执行;同时,降低了作业处于不同资源状态时作业响应值的偏差率,优化了作业的调度顺序。
[0100]
参见图6,图6是本技术实施例提供的作业调度方法的一个可选的流程示意图,将结合图5示出的步骤进行说明,
[0101]
步骤301、在作业调度系统以预设周期频率对作业实例列表进行轮询遍历的过程中,获得作业实例列表中的作业j的可执行时间和配置信息。
[0102]
步骤302、在基于配置信息,确定作业j满足调度条件的情况下,获得作业j在上一调度周期n内的历史执行记录信息。
[0103]
其中,历史执行记录信息包括实际执行时长、计划申请资源数和实际使用资源数。
[0104]
步骤303、基于计划申请资源数和实际使用资源数,确定作业j在上一调度周期n内的作业资源空闲因子。
[0105]
在一些实施例中,针对步骤303基于计划申请资源数和实际使用资源数,确定作业j在上一调度周期n内的作业资源空闲因子的过程结合图7作进一步说明,
[0106]
步骤401、针对作业j在上一调度周期n内的第n次执行过程,计算作业j的计划申请资源数与实际使用资源数的第一和值。
[0107]
步骤402、计算实际使用资源数与第一预设数值的第一乘积。
[0108]
本技术实施例中,第一预设数值可以为2。
[0109]
步骤403、计算第一和值和第一乘积的比值,得到作业j在第n次的作业资源空闲因子,直至得到作业j在上一调度周期n内的n个作业资源空闲因子。
[0110]
本技术实施例中,作业调度系统获得作业j在上一个调度周期n的历史执行记录信息后,针对作业j在上一调度周期n内的第n次执行过程,计算作业j的计划申请资源数e_needn与实际使用资源数e_usedn的第一和值;然后,计算实际使用资源数e_usedn与第一预设数值的第一乘积;进一步地,将第一和值和第一乘积的比值,作为作业j在第n次的作业资源空闲因子zn;最后,针对作业j在上一调度周期n内的n次执行过程,得到作业j在上一个调度周期n内的n个作业资源空闲因子zn。
[0111]
本技术实施例中,计算作业j在第n次的作业资源空闲因子zn可以通过如下(公式2)得到,
[0112][0113]
其中,zn为作业j一个调度周期n内第n次的作业资源空闲因子;e_needn为作业j在一个调度周期n内的第n次执行前计划申请资源数;e_usedn为作业j在一个调度周期n内的第n次实际执行过程中分配到的实际使用资源数;这里,计划申请资源数和实际使用资源数均可以从第n次的历史执行记录信息中得到。
[0114]
在一种可实现的场景中,以作业a和作业b为例,参照表1和表2,作业a计划申请资源数为40个executor,作业a在一个调度周期n内实际使用资源数分别为40个executor、33个executor、4个executor、10个executor、6个executor;作业b计划申请资源数为4个executor,作业b在一个调度周期n内实际使用资源数均为4个executor。作业调度系统采用
上述(公式2),计算作业a在一个调度周期n内的n个作业资源空闲因子zan,结果如表3所示,其中,表3中包括作业执行日期、作业名称、作业a的计划申请资源数、作业a的实际使用资源数。作业调度系统采用上述(公式2),计算作业b在一个调度周期n内的n个作业资源空闲因子zbn,结果如表4所示,其中,表4中包括作业执行日期、作业名称、作业b的计划申请资源数、作业b的实际使用资源数。
[0115]
作业执行日期作业名称计划申请资源数实际使用资源数作业资源空闲因子20220501作业a40 executor40 executor120220502作业a40 executor33 executor1.106120220503作业a40 executor4 executor5.520220504作业a40 executor10 executor2.520220505作业a40 executor6 executor3.8333
[0116]
表3
[0117]
作业执行日期作业名称计划申请资源数实际使用资源数作业资源空闲因子20220501作业b4 executor4 executor120220502作业b4 executor4 executor120220503作业b4 executor4 executor120220504作业b4 executor4 executor120220505作业b4 executor4 executor1
[0118]
表4
[0119]
步骤304、获得作业j的依赖作业的执行完成时间,作业j在本次执行过程中执行失败次数,以及为作业实例列表中的作业设置的最大固定优先级。
[0120]
本技术实施例中,最大固定优先级是根据作业的业务重要性和产出时点划分的最高的等级,即作业固定优先级可设置的最大值;示例性的,最大固定优先级l
max
可以为10,作业可设置的固定优先级可以为1-10之间的正整数;需要说明的是,作业固定优先级越大,优先级越高,也就是说,在至少两个相同条件下的作业,优先级高的作业优先调度。
[0121]
本技术实施例中,执行失败次数为作业j在每一实际执行过程中执行失败的次数,执行失败次数又称实际重试次数,作业在本次执行过程中执行失败次数又称为作业在本次执行过程中的实际重试次数。
[0122]
在一种可实现的应用场景中,参照图8所示,根据作业的业务重要性(重要程度)和产出时点(紧急程度)对作业进行划分,其中,横轴从左向右表示作业的紧急程度逐渐增加,纵轴从下向上表示作业的重要程度逐渐增加;如此,可以将作业划分为按照重要并紧急、不重要紧急、重要不紧急和不重要不紧急等四种情况。对于重要并紧急的作业,作业的作业固定优先级值越高,对于不重要不紧急的作业,作业的作业固定优先级值越低。
[0123]
步骤305、基于可执行时间和依赖作业的执行完成时间,确定作业j在后备状态队列中的等待时长。
[0124]
本技术实施例中,在作业j的依赖作业执行完成后,作业调度系统获取依赖作业的执行完成时间,并以预设周期频率对作业实例列表进行轮询遍历,确定作业j本应该发起调度的初步起始时间;其中,初步起始时间为作业j的依赖作业的执行完成时间以预设周期频率进行变化后得到的时间。进一步地,作业调度系统计算作业j的可执行时间减去作业j的
初步起始时间,得到作业j在后备状态队列中的等待时长w。
[0125]
在一种可实现的场景中,参照表1所示,以作业a、作业b和作业h为例,假设当前日期为20220506,当前时间为凌晨05:30:05;因作业a和作业b依赖于作业h的执行结果,且依赖作业h在05:10:00执行完成,作业a和作业b的可执行时间均为05:30:05,分别达到调度周期内的起始时间05:00:00;另外作业a和作业b的作业类型均为预设作业类型spark on hive,故作业a和作业b均满足调度条件。需要说明的是,由于依赖作业h在05:10:00执行完成,且预设周期频率为5s,故作业a与作业b本应该在05:10:05发起调度;但由于yarn资源不足,作业a与作业b发起执行失败,直至在05:30:05才执行成功。此时,作业a与作业b的等待时长均为:w=date(05:30:05)-date(05:10:05)=1200s,作业a在05:10:05至05:30:05期间的执行失败次数为1,作业b在05:10:05至05:30:05期间的执行失败次数为2;需要说明的是,作业在05:10:05至05:30:05期间的执行失败次数又称为作业在05:10:05至05:30:05期间的实际重试次数。
[0126]
步骤306、基于可执行时间、超时起始时间、等待时长、可重试次数、执行失败次数和最大固定优先级,确定作业j的作业动态优先级。
[0127]
本技术实施例中,作业动态优先级是由作业在历史实际执行过程中的执行失败次数,以及当前执行过程中可执行时间与超时起始时间的时间差共同决定的;这里,可执行时间与超时起始时间的时间差越大,作业动态优先级越高,执行失败次数越多,作业动态优先级越低。
[0128]
本技术实施例中,配置信息还可以包括:作业j的作业固定优先级、超时起始时间和可重试次数。可重试次数为作业在实际执行过程中,允许执行失败的次数。
[0129]
本技术实施例中,作业调度系统基于作业j的可执行时间、超时起始时间、等待时长、可重试次数、执行失败次数和最大固定优先级,确定作业j的作业动态优先级。
[0130]
在一些实施例中,针对步骤306基于可执行时间、超时起始时间、等待时长、可重试次数、执行失败次数和最大固定优先级,确定作业j的作业动态优先级的过程结合图9作进一步说明,
[0131]
步骤501、计算可执行时间减去超时起始时间的差值,得到作业j的超时时长。
[0132]
本技术实施例中,作业j的配置信息包括超时起始时间,超时时长ct等于作业j的可执行时间减去超时起始时间的差值。
[0133]
在一种可实现的场景中,参照表1所示,以作业a、作业b和作业h为例,假设当前日期为20220506,当前时间为凌晨05:30:05;作业a和作业b的超时起始时间均设置为每天凌晨05:20:00,故作业a的超时时长ct为date(05:30:05)-date(05:20:00)=605秒,作业b的超时时长ct为date(05:30:05)-date(05:20:00)=605秒。
[0134]
步骤502、计算等待时长和超时时长的第二和值。
[0135]
步骤503、计算第二和值与等待时长的第一比值。
[0136]
步骤504、计算可重试次数减去执行失败次数的第一差值。
[0137]
步骤505、计算第一差值与可重试次数的第二比值。
[0138]
步骤506、计算最大固定优先级、第一比值和第二比值三者的乘积,得到作业动态优先级。
[0139]
本技术实施例中,作业调度系统用可执行时间减去超时起始时间,得到的差值作
为作业j的超时时长ct,计算等待时长w与超时时长ct的第二和值(w ct),计算第二和值(w ct)与等待时长w的第一比值(w ct)/w;进一步地,计算可重试次数et减去执行失败次数st的第一差值(et-st);计算第一差值(et-st)与可重试次数et的第二比值(et-st)/et;最后,将最大固定优先级l
max
、第一比值(w ct)/w和第二比值(et-st)/et三者相乘,得到的乘积作为作业j的作业动态优先级l
adj
。
[0140]
本技术实施例中,计算作业j的作业动态优先级可以通过如下(公式3)得到,
[0141][0142]
其中,l
adj
为作业j的作业动态优先级,l
max
为最大固定优先级,w为作业j在后备状态队列中的等待时长,ct为作业j的超时时长,et为作业j设置的可重试次数,st为作业j在本次执行过程中的执行失败次数。
[0143]
在一种可实现的场景中,参照表1所示,以作业a、作业b和作业h为例,假设当前日期为20220506,当前时间为凌晨05:30:05;作业a和作业b的超时起始时间均设置为每天凌晨05:20:00,作业a的超时时长ct=605s,作业a的等待时长w=1200s,作业a设置的可重试次数et=5,作业a的执行失败次数st=1;作业b的超时时长ct=605s,作业b的等待时长w=1200s,作业b设置的可重试次数et=5,作业b的执行失败次数st=2;且最大固定优先级l
max
=10,通过上述(公式3),计算作业a的作业动态优先级l
adj
为12.03,计算作业b的作业动态优先级l
adj
为9.03。
[0144]
步骤307、基于作业j在上一调度周期n内的第n次执行过程中的实际执行时长和对应的作业资源空闲因子,确定作业j在上一调度周期n内的平均执行时长。
[0145]
本技术实施例中,作业调度系统从作业j的历史执行记录信息中,获得作业j在上一调度周期n内的第n次执行时对应的实际执行时长tn和作业资源空闲因子zn,针对上一调度周期n,基于得到的n个实际执行时长tn和n个作业资源空闲因子zn,确定作业j在上一调度周期n内的平均执行时长t。
[0146]
在一些实施例中,针对步骤307基于作业j在上一调度周期n内的第n次执行过程中的实际执行时长tn和作业资源空闲因子zn,确定作业j在上一调度周期n内的平均执行时长t的过程结合图10作出进一步说明,
[0147]
步骤601、获得n个实际执行时长中的最大实际执行时长和最小实际执行时长。
[0148]
步骤602、计算在第n次执行过程中,实际执行时长与对应的作业资源空闲因子的第三比值。
[0149]
步骤603、从n个第三比值中,分别减去最大实际执行时长对应的第三比值、最小实际执行时长对应的第三比值,得到n-2个第三比值。
[0150]
步骤604、计算n-2个第三比值的平均数,得到平均执行时长。
[0151]
本技术实施例中,计算作业j的平均执行时长t可以通过如下(公式4)得到,
[0152][0153]
其中,t为作业j的平均执行时长,为在第n次执行过程中,实际执行时长tn与作业资源空闲因子zn的第三比值,t
max
表示作业j在上一调度周期n内的最大实际执行时长,zmax
表示作业j的与最大实际执行时长对应的最大作业资源空闲因子,t
min
表示作业j在上一调度周期n内的最小实际执行时长,z
min
表示作业j的与最小实际执行时长对应的最小作业资源空闲因子,表示最大实际执行时长t
max
对应的第三比值,表示最小实际执行时长t
min
对应的第三比值。
[0154]
在一种可实现的场景中,参照表2、表3和表4所示,以作业a和作业b为例,调度周期n=5,作业a在上一调度周期n中的实际执行时长分别为1000s、1200s、10000s、4000s和7000s,作业a在上一调度周期中的作业资源空闲因子分别为1、1.1061、5.5、2.5和3.8333,作业a在上一调度周期n中的最大实际执行时长t
max
=10000,作业a在上一调度周期n中的最小实际执行时长t
min
=1000;将上述参数代入上述(公式4),得到作业a的平均执行时长
[0155]
同样的,作业b在上一调度周期n中的实际执行时长分别为1000s、1100s、1200s、1300s和1100s,作业b在上一调度周期中的作业资源空闲因子均为1,作业b在上一调度周期n中的最大实际执行时长t
max
=10000,作业b在上一调度周期n中的最小实际执行时长t
min
=1000;将上述参数代入上述(公式4),得到作业b的平均执行时长
[0156]
这里仍以相关技术中的数据为例,作业k在资源紧张时刻的实际使用资源是9个executor、计划申请资源数40个executor、实际执行时长为16min=960s,等待时长w假设为300s,通过上述(公式2),计算出作业k在资源紧张时刻的作业资源空闲因子z为3;若仅考虑作业资源空闲因子,通过如下(公式5),计算出作业k在资源紧张时刻的响应比ru为1.8507。
[0157][0158]
其中,r表示作业的响应比,w表示作业在后备状态队列中的等待时长,表示作业在上一调度周期n内的平均执行时长。
[0159]
作业k在资源充足时刻的实际使用资源是40个executor,计划申请资源数40个executor、实际执行时长为6.6min=396s,等待时长w假设也为300s,通过上述(公式2),计算出作业k在资源紧张时刻的作业资源空闲因子z为1;若仅考虑作业资源空闲因子,通过上述(公式5),计算作业k在资源充足时刻的响应比re为1.7576;进一步地,在考虑作业资源空闲因子的情况下,确定作业k在资源紧张与资源充足时刻的响应比的偏差率rd为:而相关技术中在不考虑作业资源空闲因子的情况下,作业k在资源紧张与资源充足时刻的响应比的偏差率rd为-25.32%。明显,在不考虑作业资源空闲因子得到的偏差率与考虑作业资源空闲因子得到的偏差率相比,偏差率由-25.32%优化到6.31%,且偏差率为正数,更有利于hive on spark任务的正常投递。
[0160]
由上述可知,由于作业实际分配的资源越少,作业的执行执行时间越长本技术实施例通过添加资源空闲因子z,将作业实际执行时长t除以资源空闲因子z的值作为新的作业执行时长参与到作业的响应比的计算中,即确定作业资源的空闲因子z是由该作业计划申请的资源数如executor总数与该作业实际分配到的实际使用资源数如executor个数之和的算术平均值作为分子,实际使用资源数作为分母的分数值;将作业执行时长t与作业实际的作业空闲资源因子z相比后,能更接近作业处于资源充足状态下的执行时长,从而得到作业的平均执行时长更加准确,进而使得计算的作业当前时刻的响应比也更加准确,更有利于hive on spark任务的正常投递。
[0161]
步骤308、基于等待时长、作业固定优先级、作业动态优先级和平均执行时长,确定作业j的响应比。
[0162]
本技术实施例中,作业j的响应比是基于作业j的等待时长w、作业j的作业固定优先级l
fix
、作业j的作业动态优先级l
adj
和作业j在上一调度周期n内的平均执行时长t得到的。
[0163]
在一些实施例中,针对步骤308基于等待时长、作业固定优先级、作业动态优先级和平均执行时长,确定作业j的响应比的过程结合图11作进一步说明,
[0164]
步骤701、基于作业固定优先级、作业动态优先级和最大固定优先级,确定作业j的优先级系数。
[0165]
本技术实施例中,作业j的优先级系数cm是基于作业j的作业固定优先级l
fix
、作业j的作业动态优先级l
adj
和最大固定优先级得到的。
[0166]
在一些实施例中,针对步骤701基于作业固定优先级、作业动态优先级和最大固定优先级,确定作业j的优先级系数的过程结合图12作进一步说明,
[0167]
步骤801、计算作业固定优先级和作业动态优先级的第三和值。
[0168]
步骤802、计算第三和值与最大固定优先级的第四比值。
[0169]
步骤803、计算第四比值与第二预设数值的之和,得到优先级系数。
[0170]
本技术实施例中,计算作业j的优先级系数cm可以通过如下(公式6)得到,
[0171][0172]
其中,cm为作业j的优先级系数,l
fix
表示作业j的作业固定优先级,l
adj
表示作业j的作业动态优先级,l
max
表示最大固定优先级,第二预设数值为1。
[0173]
在一种可实现的场景中,参照图5和表1所示,以作业a和作业b为例,最大固定优先级l
max
为10,作业a的作业固定优先级l
fix
为10,作业a的作业动态优先级l
adj
为12.03,将上述参数代入上述(公式6),得到作业a的优先级系数cm为3.20。
[0174]
同样的,最大固定优先级l
max
为10,作业b的作业固定优先级l
fix
为5,作业b的作业动态优先级l
adj
为9.03,将上述参数代入上述(公式6),得到作业b的优先级系数cm为2.40。
[0175]
由上述可知,本技术实施例中,通过引入作业的优先级系数,对于不同的作业,相同的等待时间前提下,对作业差异化配置优先级,并基于差异化的优先级计算不同作业的响应比,从而使得响应比大的作业获得优先投递权,符合业务使用预期;实现了作业的调度顺序的优化,也实现了对不同的作业进行差异化的调度。
[0176]
步骤702、基于等待时长、优先级系数和平均执行时长,确定作业j的响应比。
[0177]
本技术实施例中,作业j的响应比r是基于作业j的等待时长w、作业j的优先级系数cm和作业j在上一调度周期n内的平均执行时长t得到的。
[0178]
在一些实施例中,针对步骤702基于等待时长、优先级系数和平均执行时长,确定作业j的响应比的过程结合图13作进一步说明,
[0179]
步骤901、计算等待时长和优先级系数的第二乘积。
[0180]
步骤902、计算第二乘积与平均执行时长的第五比值。
[0181]
步骤903、计算第五比值和第三预设数值的和,得到作业j的响应比。
[0182]
本技术实施例中,计算作业j的响应比可以通过如下(公式7)得到,
[0183][0184]
其中,r为作业j的响应比,w为作业j在后备状态队列中的等待时长,cm为作业j的优先级系数,t为作业j在上一调度周期n内的平均执行时长,第三预设数值为1。
[0185]
在一种可实现的场景中,参照图5所示,以作业a和作业b为例,作业a的等待时长w为1200s,作业a的优先级系数cm为3.20,作业a在上一调度周期n内的平均执行时长t为1503.67s,将上述参数代入上述(公式7),得到作业a的响应比r为3.55。
[0186]
同理,作业b的等待时长w为1200s,作业b的优先级系数cm为2.40,作业b在上一调度周期n内的平均执行时长t为1133.33s,将上述参数代入上述(公式7),得到作业b的响应比r为3.54。
[0187]
步骤309、按照作业j的响应比,向大数据计算平台的资源管理器发送作业j的资源申请。
[0188]
本技术实施例中,作业调度系统获得作业j的响应比之后,将所有作业j的响应比按照由大到小的顺序进行排序,并按照排序后的响应比,向大数据计算平台的资源管理器发送响应比对应的作业的资源申请。
[0189]
在一种可实现的应用场景中,以作业a和作业b为例,作业a的响应比r为3.55,作业b的响应比为3.54,作业调度系统确定作业a的响应比大于作业b的响应比,即作业a获得优先投递执行;也就是说,作业调度系统先发送作业a的资源申请至大数据计算平台的资源管理器yarn,之后,再发送作业b的资源申请至大数据计算平台的资源管理器yarn。资源管理器yarn的资源将按作业a和b作业的投递顺序,先满足作业a的资源申请,再满足作业b的资源申请;即资源管理器yarn根据现有资源分配资源优先供作业a执行,之后yarn根据现有资源分配资源供作业b执行。进一步地,作业调度系统中的作业a、作业b按先后顺序执行spark程序。然后,在作业a、作业b执行完成后,通过作业调度系统中的yarn资源同步模块同步作业a和作业b在本次执行过程中的执行记录信息。这里,作业a和作业b在本次执行过程中的执行记录信息如表5所示,
[0190]
作业类别作业a作业b作业标识1648799282759_5089811648799282759_508985本次执行计划申请资源数40个executor4个executor本次执行实际使用资源数33个executor4个executor本次实际执行时长1200秒1000秒
[0191]
表5
[0192]
这里,通过作业调度系统中的yarn资源同步模块同步作业a和作业b在本次执行过程中的执行记录信息,实现过程为:
[0193]
首先,通过作业调度系统中的yarn资源同步模块启动日志解析模块;其次,通过日志解析模块根据作业a和作业b的作业标识如spark jobid,调用spark rest应用程序编程接口(application programming interface,api),从资源管理器yarn中分别查询作业a和作业b的本次执行的日志信息;然后,通过日志解析模块获取作业a和作业b的日志信息,并从日志信息中解析出作业a和作业b的执行记录信息,如本次执行计划申请资源数、本次执行实际使用资源数和本次实际执行时长;最后,记录作业a与作业b的执行记录信息到作业调度系统中的作业执行流水记录表中,以方便后期在作业执行流水记录表查询各个作业的执行情况。
[0194]
在一种可实现的应用场景中,参照图14所示,对本技术实施例提供的作业调度方法的作进一步说明,
[0195]
步骤1001、作业调度系统以预设周期频率(如5秒)发起轮询遍历作业实例列表,在05:30:05时刻时,发起遍历作业实例。
[0196]
步骤1002、作业调度系统基于获得的各个作业的配置信息,确定作业满足基础调度条件。
[0197]
本技术实施例中,作业的配置信息包括但不限于作业标识、作业描述、作业类型、作业的依赖作业、调度周期内的起始时间、超时起始时间、资源需求量、预估执行时长、作业固定优先级和可重试次数。
[0198]
本技术实施例中,调度条件包括基础调度条件,基于作业的配置信息,确定作业满足基础调度条件包括:作业的依赖(上游)作业已执行完成,以及作业的可执行时间达到调度周期内的起始时间。
[0199]
步骤1003、作业调度系统判断作业的作业类型是否为spark on hive类型。
[0200]
本技术实施例中,若确定作业的作业类型为spark on hive类型,则执行步骤1004;若确定作业的作业类型不为spark on hive类型,则执行步骤1005。
[0201]
步骤1004、作业调度系统选择与spark on hive类型对应的第一策略.
[0202]
这里,第一策略是本技术提供的计算作业的响应比对应的策略。
[0203]
步骤1005、作业调度系统选择第二策略。
[0204]
这里,第一策略是相关技术提供的计算作业的响应比对应的策略。
[0205]
步骤1006、作业调度系统计算各个作业的响应比,并按照响应比由大到小的顺序对各作业进行排序,得到排序结果。
[0206]
步骤1007、作业调度系统按照排序结果,调度作业投递。
[0207]
步骤1008、作业调度系统将各个作业的资源申请按照投递顺序发送至大数据计算平台的资源管理器yarn。
[0208]
步骤1009、资源管理器yarn按照作业的投递顺序为作业分配资源。
[0209]
步骤1010、作业调度系统中的各个作业根据分配的资源执行。
[0210]
步骤1011、在各个作业执行完成后,触发作业调度系统中的yarn资源同步模块。
[0211]
步骤1012、作业调度系统通过yarn资源同步模块中的日志解析模块,根据各个作业的作业标识,调用spark rest api,从资源管理器yarn中分别查询各个作业的本次执行
的日志信息。
[0212]
步骤1013、从日志信息中解析出各个作业的执行记录信息,并将各个作业的执行记录信息记录到作业调度系统中的作业执行流水记录表中。
[0213]
由上述可知,本技术实施例中,通过引入作业资源空闲因子,能够计算出作业处于资源充足状态下的执行时长,从而提高了作业的平均执行时长的准确性,进而提高了作业在当前时刻的响应比的准确性,使得作业调度系统更合理的调度作业的执行;同时,降低了作业处于不同资源状态时作业响应值的偏差率,优化了作业的调度顺序;通过引入作业的优先级系数,对于不同的作业,相同的等待时间前提下,对作业差异化配置优先级,并基于差异化的优先级计算不同作业的响应比,从而使得响应比大的作业获得优先投递权,符合业务使用预期;实现了作业的调度顺序的优化,也实现了对不同的作业进行差异化的调度。
[0214]
下面继续说明本技术实施例提供的作业调度装置154实施为软件模块的示例性结构,在一些实施例中,如图3所示,存储在存储器150的作业调度装置154中的软件模块可以是终端100中的作业调度装置,包括:
[0215]
获得模块1541,用于在作业调度系统以预设周期频率对作业实例列表进行轮询遍历的过程中,获得作业实例列表中的作业j的可执行时间和配置信息;
[0216]
获得模块1541,还用于在基于配置信息,确定作业j满足调度条件的情况下,获得作业j在上一调度周期n内的历史执行记录信息;其中,历史执行记录信息包括实际执行时长t、计划申请资源数和实际使用资源数;
[0217]
确定模块1542,用于基于计划申请资源数和实际使用资源数,确定作业j在上一调度周期n内的作业资源空闲因子;
[0218]
确定模块1542,还用于基于配置信息、可执行时间、作业资源空闲因子和实际执行时长,确定作业j的响应比;
[0219]
发送模块1543,用于按照作业j的响应比,向大数据计算平台的资源管理器发送作业j的资源申请。
[0220]
在一些实施例中,配置信息包括作业j的作业类型、作业j的依赖作业和作业j的调度周期内的起始时间,基于配置信息,确定作业j满足调度条件,包括:作业类型为预设作业类型,作业j的依赖作业已执行完成,以及作业j的可执行时间达到调度周期内的起始时间。
[0221]
在一些实施例中,处理模块1544,还用于针对作业j在上一调度周期n内的第n次执行过程,计算作业j的计划申请资源数与实际使用资源数的第一和值;计算实际使用资源数与第一预设数值的第一乘积;计算第一和值和第一乘积的比值,得到作业j在第n次的作业资源空闲因子,直至得到作业j在上一调度周期n内的n个作业资源空闲因子。
[0222]
在一些实施例中,获得模块1541,还用于获得作业j的依赖作业的执行完成时间、作业j在本次执行过程中执行失败次数,以及为作业实例列表中的作业设置的最大固定优先级;确定模块1542,还用于基于可执行时间和依赖作业的执行完成时间,确定作业j在后备状态队列中的等待时长;基于可执行时间、超时起始时间、等待时长、可重试次数、执行失败次数和最大固定优先级,确定作业j的作业动态优先级;基于作业j在上一调度周期n内的第n次执行过程中的实际执行时长和对应的作业资源空闲因子,确定作业j在上一调度周期n内的平均执行时长;基于等待时长、作业固定优先级、作业动态优先级和平均执行时长,确定作业j的响应比。
[0223]
在一些实施例中,处理模块1544,还用于计算可执行时间减去超时起始时间的差值,得到作业j的超时时长;
[0224]
计算等待时长和超时时长的第二和值;
[0225]
计算第二和值与等待时长的第一比值;
[0226]
计算可重试次数减去执行失败次数的第一差值;
[0227]
计算第一差值与可重试次数的第二比值;
[0228]
计算最大固定优先级、第一比值和第二比值三者的乘积,得到作业动态优先级。
[0229]
在一些实施例中,获得模块1541,还用于获得n个实际执行时长中的最大实际执行时长和最小实际执行时长;处理模块1544,还用于计算在第n次执行过程中,实际执行时长与对应的作业资源空闲因子的第三比值;从n个第三比值中,分别减去最大实际执行时长对应的第三比值、最小实际执行时长对应的第三比值,得到n-2个第三比值;计算n-2个第三比值的平均数,得到平均执行时长。
[0230]
在一些实施例中,确定模块1542,还用于基于作业固定优先级、作业动态优先级和最大固定优先级,确定作业j的优先级系数;基于等待时长、优先级系数和平均执行时长,确定作业j的响应比。
[0231]
在一些实施例中,处理模块1544,还用于计算作业固定优先级和作业动态优先级的第三和值;计算第三和值与最大固定优先级的第四比值;计算第四比值与第二预设数值的之和,得到优先级系数。
[0232]
在一些实施例中,处理模块1544,还用于计算等待时长和优先级系数的第二乘积;计算第二乘积与平均执行时长的第五比值;计算第五比值和第三预设数值的和,得到作业j的响应比。
[0233]
需要说明的是,本技术实施例装置的描述,与上述方法实施例的描述是类似的,具有同方法实施例相似的有益效果,因此不做赘述。对于本装置实施例中未披露的技术细节,请参照本技术方法实施例的描述而理解。
[0234]
本技术实施例提供一种存储有可执行指令的存储介质,其中存储有可执行指令,当可执行指令被处理器执行时,将引起处理器执行本技术实施例提供的方法,例如,如图4、图6-图7以及图9-图14示出的方法。
[0235]
本技术提供的存储介质,通过在作业调度系统以预设周期频率对作业实例列表进行轮询遍历的过程中,获得作业实例列表中的作业j的可执行时间和配置信息;在基于配置信息,确定作业j满足调度条件的情况下,获得作业j在上一调度周期n内的历史执行记录信息;其中,历史执行记录信息包括实际执行时长t、计划申请资源数和实际使用资源数;基于计划申请资源数和实际使用资源数,确定作业j在上一调度周期n内的作业资源空闲因子;基于配置信息、可执行时间、作业资源空闲因子和实际执行时长,确定作业j的响应比;按照作业j的响应比,向大数据计算平台的资源管理器发送作业j的资源申请。如此,通过引入作业资源空闲因子,解决了相关技术中因资源空闲问题导致的计算出的响应比不准确,进而导致作业调度顺序出现差错的问题;这里,作业调度系统计算不同资源状态下的作业资源空闲因子,并基于不同资源状态下作业的执行时长和对应的作业资源空闲因子,计算出作业相对于处于资源充足状态下的执行时长,如此,提高了作业的平均执行时长的准确性,从而提高了作业在当前时刻的响应比的准确性,使得作业调度系统更合理的调度作业的执
行;同时,降低了作业处于不同资源状态时作业响应值的偏差率,优化了作业的调度顺序。
[0236]
在一些实施例中,存储介质可以是计算机可读存储介质,例如,铁电存储器(fram,ferromagnetic random access memory)、只读存储器(rom,read only memory)、可编程只读存储器(prom,programmable read only memory)、可擦除可编程只读存储器(eprom,erasable programmable read only memory)、带电可擦可编程只读存储器(eeprom,electrically erasable programmable read only memory)、闪存、磁表面存储器、光盘、或光盘只读存储器(cd-rom,compact disk-read only memory)等存储器;也可以是包括上述存储器之一或任意组合的各种设备。
[0237]
在一些实施例中,可执行指令可以采用程序、软件、软件模块、脚本或代码的形式,按任意形式的编程语言(包括编译或解释语言,或者声明性或过程性语言)来编写,并且其可按任意形式部署,包括被部署为独立的程序或者被部署为模块、组件、子例程或者适合在计算环境中使用的其它单元。
[0238]
作为示例,可执行指令可以但不一定对应于文件系统中的文件,可以可被存储在保存其它程序或数据的文件的一部分,例如,存储在超文本标记语言(超文本标记语言,hyper text markup language)文档中的一个或多个脚本中,存储在专用于所讨论的程序的单个文件中,或者,存储在多个协同文件(例如,存储一个或多个模块、子程序或代码部分的文件)中。作为示例,可执行指令可被部署为在一个计算设备上执行,或者在位于一个地点的多个计算设备上执行,又或者,在分布在多个地点且通过通信网络互连的多个计算设备上执行。
[0239]
以上所述,仅为本技术的实施例而已,并非用于限定本技术的保护范围。凡在本技术的精神和范围之内所作的任何修改、等同替换和改进等,均包含在本技术的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。