基于半监督迁移学习的新冠肺炎ct图像分类方法
技术领域
1.本发明属于数字图像处理方法技术领域,具体涉及一种基于半监督迁移学习的新冠肺炎ct图像分类方法。
背景技术:
2.随着人工智能的高速发展,越来越多的领域开始应用深度学习算法,帮助解决更多实际生活中的问题。在医学图像领域,将人工智能技术应用于患者ct图像等医学图像的处理已经变得十分普遍。将深度学习图像分类算法应用于新冠肺炎患者ct图像分类中,可以辅助医生的诊断工作,极大地减轻医生的工作负担,具有十分重要的现实意义。
3.对大量的临床影像数据进行标记需要巨大的人力成本,而目前,针对大量未标记的数据所提出的半监督分类算法都是在公开数据集上进行实验。我们尝试应用半监督学习算法处理大量未标记的火神山医院的3900多条实际 ct数据集,然而,实际的分类效果并不理想。我们采取自监督学习方法充分利用ct图像本身的图片信息,使用分割的辅助任务,提高分类效率。
技术实现要素:
4.本发明的目的是提供一种基于半监督迁移学习的新冠肺炎ct图像分类方法,解决了现有半监督学习算法实际应用于完全未标记数据集上效果不好的问题。
5.本发明所采用的技术方案是:
6.基于半监督迁移学习的新冠肺炎ct图像分类方法,具体按照以下步骤实施:
7.步骤1、构建感染新冠肺炎的ct图像数据集;
8.步骤2、将步骤1获得的数据集放入inf-net网络中进行病灶的分割,加入transformer模块提高边缘表示;
9.步骤3、将步骤2中inf-net网络输出的病灶表示与原图进行像素级的融合,突出病灶在原图中的表示;
10.步骤4、利用已做好分类标记的ct公开数据集对小样本模型进行训练,作为半监督迁移学习的预训练模型;
11.步骤5、将步骤3融合后的图片放入到经过步骤4训练的半监督迁移学习框架中,对新冠肺炎ct图像进行普通、重症、危重症的分类,得到分类准确率。
12.本发明的特点还在于:
13.步骤1具体按照以下步骤实施:
14.步骤1.1、将dcm类型的原始ct图像转化为png格式图像;
15.步骤1.2、对每张图像的所有像素对应的数值进行求和,剔除和的数值低于40000000阈值的图像,保留阈值高于40000000的图像。
16.步骤3具体按照以下步骤实施:
17.对图像进行融合叠加,将两张图像中的每个像素的值乘以0.5,然后对应点相加,
最后输出,得到新的图像作为半监督迁移学习网络框架的输入。
18.步骤4具体按照以下步骤实施:
19.步骤4.1、对已做好分类标记的ct公开数据进行增强,使用的策略依次为:
20.(1)随机左右翻转,概率p=0.5;
21.(2)随机裁剪,将图像大小调整为32*32,每边填充4,填充类型为反射;
22.(3)转化为张量,归一化至[0-1];
[0023]
(4)标准化,对数据按照通道进行标准化,均值为(0.4811,0.4575,0.4078),标准差为(0.2605,0.2533,0.2683);
[0024]
步骤4.2、将增强后的ct公开数据集送入半监督迁移学习神经网络中提取特征表示,训练神经网络,使用resnet50作为特征提取器,在提取器的末端加入l2归一化层,使得特征向量具有单位长度;
[0025]
步骤4.3、将每个类别的样本对应特征向量都作为该类别的权重向量存储到权重矩阵中;
[0026]
步骤4.4、计算样本的特征向量与权重矩阵中对应的各个类别的权重向量之间的内积,再利用softmax分类器映射成未归一化的logit分数,利用 softmax激活函数,从而在所有类别上产生概率分布。
[0027]
步骤5具体按照以下步骤实施:
[0028]
步骤5.1、对经步骤3融合后的ct图像进行数据增强;
[0029]
步骤5.2、将经步骤5.1增强后的数据集放入到半监督迁移学习框架中,模型框架有两条网络分支,分别为步骤4中的预训练模型和目标模型,目标模型就是学习参数的模型;
[0030]
步骤5.3、目标模型初始值与步骤4的预训练模型设置相同,将待测试数据集中的数据,一批大小为16,分批喂入预训练模型和目标模型,将提取的特征进行akc正则化,并更新目标模型的参数,再通过arc正则项将未标记数据与标记数据的分布相似,并更新目标模型参数;
[0031]
步骤5.4、半监督迁移学习模型的迭代次数设置为50次,每次喂入模型的一批大小为16,使用sgd优化器,学习率为0.001,权重衰减默认为0.001,动量速率为0.9,akc和arc参数设置为:正则化权重因子λk=1、λr=50,阈值k和r默认值为0.7;设置好参数后,将待测试数据集放入到半监督迁移学习框架中,得到分类准确率。
[0032]
步骤5.1中对ct图像进行数据增强的具体步骤为:
[0033]
将待测试数据分为标记数据和未标记数据,对标记数据采用的随机数据增强策略依次为:
[0034]
(1)随机左右翻转,概率p=0.5;
[0035]
(2)随机裁剪,当图片大小为224时,将放缩调整为224/0.875,随后随机裁剪,大小为224;否则,随机裁剪,高为图片大小,宽为图片大小乘以 0.125,填充模式为reflect;
[0036]
(3)标准化,均值为(0.485,0.456,0.406),标准差为(0.229,0.224,0.225);
[0037]
(4)添加噪声,采用高斯噪音,标准差为0.15;
[0038]
对于未标记数据,分为弱数据增强和强数据增强,弱数据增强的步骤与上述标记数据相同,强数据增强是在弱数据增强的基础上,增加了随机遮挡,概率float=0.5。
[0039]
步骤5.3中的akc正则项和arc正则项具体为:
[0040]
akc正则项的输入就是预训练模型和目标模型提取出来的特征向量, akc的正则项为:
[0041][0042]
其中,b
l
为标记实例,bu为未标记实例,l表示b
l
的微型批次,u表示 bu的微型批次,w为权重;
[0043]
arc表示目标模型中标记数据和未标记数据之间的自适应表示一致性,使用最大平均差异mmd来衡量标记数据和未标记数据的数据分布之间的距离,arc的正则项为:
[0044][0045]
其中,q
f*l
为所选标记样本的分布,q
f*u
为所选未标记样本的分布;
[0046]
完整的自适应一致性由akc和arc组成的正则化为:
[0047]
r(θ)=λ
krk
λrrr。
[0048]
本发明的有益效果是:
[0049]
1.本发明在半监督迁移学习算法的基础上,结合自监督学习方法,使用分割的辅助任务,充分利用图片本身信息,无需外部标记信息,能够在不充足的ct影像数据的训练下对新冠肺炎ct图像进行良好准确的分类,完成了对新冠肺炎ct图像的普通、重症和危重症的三分类效果;
[0050]
2.本发明分类方法具有标记数据少,实际分类效果好的特点,使用本方法进行ct图像分类取得了比现行方法更好的分类结果。
附图说明
[0051]
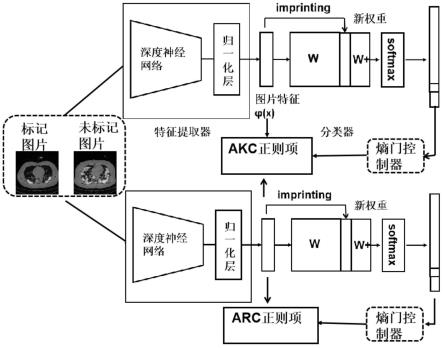
图1是本发明基于半监督迁移学习的新冠肺炎ct图像分类方法的半监督迁移分类框架图;
[0052]
图2是普通型新冠肺炎ct图像原图、病灶图和融合图的对比图;
[0053]
图3是重症型新冠肺炎ct图像原图、病灶图和融合图的对比图;
[0054]
图4是危重症型新冠肺炎ct图像原图、病灶图和融合图的对比图。
具体实施方式
[0055]
下面结合附图和具体实施方式对本发明进行详细说明。
[0056]
本发明基于半监督迁移学习的新冠肺炎ct图像分类方法,具体按照以下步骤实施:
[0057]
步骤1、新冠肺炎ct图像数据集的构建,数据集构建工作将为本研究提供数据基础:
[0058]
步骤1.1、使用原始火神山ct图像构建数据集,由于原始火神山ct图像格式为dcm格式文件,这是一种数位成像文件格式,广泛运用于医学领域,需要进行一定的图像格式转换处理才可用于神经网络的训练。首先要将 dcm类型的文件转化为方便读取的png格式图像;
[0059]
步骤1.2、由于拍摄时角度、光照、设备等问题,一些图像较暗导致无法在训练中使用,我们需要将这些图片剔除后才可用于深度神经网络学习。这里用到的方法原理是这样的:一般灰度图中,一个像素的明暗用一个[0, 255]间的数字表示,0表示完全黑色,255表示完全白色,使用一个矩阵就可以表示一张图像。彩色图像由rgb三色组成,原理同灰度图一致。我们注意到较暗的像素表示该像素点对应的数值更接近0,所以我们对所有像素对应的数值进行求和,如果和低于40000000,则表示这是一张较暗图像,应当剔除,之后我们就能得到良好的数据。
[0060]
步骤2、由于直接将实际数据集应用于半监督迁移学习框架中的效果并不理想,我们首先对步骤1得到的数据集进行处理,将数据集放入inf-net 网络中进行病灶的分割,加入transformer模块提高边缘表示。
[0061]
步骤3、利用步骤2中inf-net网络输出的病灶表示与原图进行像素级的融合,突出病灶在原图中的表示,具体步骤为:
[0062]
利用opencv中的函数cv2.addweighted()对图片进行叠加,其中,将两张图片都设置成200*200大小,将两张图像中的每个像素的值乘以0.5,然后对应点相加,最后输出,得到新的图像作为半监督迁移学习网络框架的输入。
[0063]
步骤4、利用已做好分类标记的ucsd-ai4h/covid-ct公开数据集对小样本模型进行训练,作为半监督迁移学习的预训练模型:
[0064]
步骤4.1、在训练期间应用数据增强策略。对于ucsd-ai4h/covid-ct 数据集,采用的随机数据增强策略依次为:(1)随机左右翻转,概率p=0.5; (2)随机裁剪,将大小调整为32*32,每边填充4,填充类型为反射;(3)转化为张量,归一化至[0-1];(4)标准化,对数据按照通道进行标准化,均值为 (0.4811,0.4575,0.4078),标准差为(0.2605,0.2533,0.2683);
[0065]
步骤4.2、首先将增强后的ucsd-ai4h/covid-ct数据集送入半监督迁移学习神经网络中提取特征表示,训练神经网络,使用resnet50作为特征提取器,然后利用提取器末端的l2归一化层,使得特征向量具有单位长度;
[0066]
步骤4.3、每个类别的样本对应特征向量都作为该类别的权重向量存储到权重矩阵中。将权重矩阵的每一列看作是对应类别的特征向量。如果一个类别存在多个样本,将一个类别中所有样本的特征向量取平均值作为这个类别所对应的权重向量。当有新的类别加入且类别的样本非常小时,就无法满足训练模型需要大量数据的要求,构建权重矩阵后,可以不用重新对模型进行训练,直接将样本对应的特征向量作为权重矩阵,在分类时也能达到很好的分类效果;
[0067]
步骤4.4、计算样本的特征向量与权重矩阵中对应的各个类别的权重向量之间的内积,再利用softmax分类器映射成未归一化的logit分数,利用 softmax激活函数,从而在所有类别上产生概率分布。
[0068]
步骤5、将步骤3融合后的图片放入到经过步骤4训练的半监督迁移学习框架中,对新冠肺炎的普通、重症、危重症三类进行分类,得到分类准确率:
[0069]
步骤5.1、首先将步骤3合成的ct图像进行图像增强,对于火神山医院的数据集,首先分为标记数据和未标记数据,其中标记数据采用的随机数据增强策略依次为:(1)随机左右翻转,概率p=0.5;(2)随机裁剪,当图片大小为224时,将放缩调整为224/0.875,随后随
机裁剪,大小为224;否则,随机裁剪,高为图片大小,宽为图片大小乘以0.125,填充模式为reflect;(3) 标准化,均值为(0.485,0.456,0.406),标准差为(0.229,0.224,0.225);(4) 添加噪声,采用高斯噪音,标准差为0.15。对于未标记数据,分为弱数据增强和强数据增强,弱数据增强同上述标记数据采取的步骤一样,强数据增强在弱数据增强的基础上,增加了随机遮挡,概率float=0.5;
[0070]
步骤5.2、将经步骤5.1增强后的数据集放入到半监督迁移学习框架中,框架图如图1所示,模型框架有两条网络分支,上面就是步骤4的预训练模型,下面是目标模型,目标模型就是学习参数的模型;
[0071]
步骤5.3、目标模型初始值与步骤4的预训练模型设置相同,将火神山医院ct图像数据集中的大量数据,一批大小为16,分批喂入预训练模型和目标模型,将提取的特征进行akc正则化,并更新目标模型的参数。为了防止目标模型的过拟合问题,通过arc正则项将未标记数据与标记数据的分布相似,并更新目标模型参数:
[0072]
步骤5.3.1、akc是abuduweili等人提出的第一个正则项,它的输入就是预训练模型和目标模型提取出来的特征向量。为了保留预训练模型中的泛性,目标模型提取的特征要尽可能地与预训练模型提取的特征表示相似,但是并不要求完全一致。所以,就需要对进入akc的预训练模型中的特征提取设置一个门槛,即熵门控制函数,如图1所示。当预训练模型输出的数据分布logits区分度很高时,说明样本属于某个类别的概率远大于其他类别,说明当前的特征提取是非常有效的,因此可以参与到akc当中,所以使用 logits的熵来进行区分,所以akc的正则项为:
[0073][0074]
其中,b
l
为标记实例,bu为未标记实例,l表示b
l
的微型批次,u表示 bu的微型批次,w为权重;
[0075]
步骤5.3.2、arc表示目标模型上标记数据和未标记数据之间的自适应表示一致性。arc正则项主要是为了解决在标记数据不足的情况下的过拟合问题,中心思想是尽可能地让未标记数据的分布和标记数据的分布相似。使用经典的度量最大平均差异mmd来衡量标记数据和未标记数据的数据分布之间的距离,所以arc正则项为:
[0076][0077]
其中,q
f*l
为所选标记样本的分布,q
f*u
为所选未标记样本的分布;
[0078]
步骤5.4、半监督迁移学习模型的迭代次数设置为50次,每次喂入模型的一批大小为16,使用sgd优化器,学习率为0.001,权重衰减默认为0.001,动量速率为0.9。akc和arc参数设置为如下:正则化权重因子λk=1、λr= 50,阈值k和r默认值为0.7。每四次迭代自动保存一个检查点,用于评价和存储模型。设置好参数后,将待测试数据集放入到半监督迁移学习框架中,得到分类准确率。
[0079]
图2~4分别为普通、重症和危重症三种类型的新冠肺炎ct图像原图、通过inf-net网络分割后的病灶图、将病灶图与原图融合后的图片的对比图。我们将实际临床原图放入半监督迁移学习模型中进行分类的效果并不理想,模型无法从原图学习到有效的信息,从而进行分类。从图2~图4可以看出,经过本发明的方法处理之后,inf-net网络可以有效地
将原图中的病灶进行分割,原图和病灶图的融合可以有效地突出原图中不明显的病灶,辅助半监督迁移学习模型进行分类,经过实验,使用本发明的方法对新冠肺炎ct图像进行分类的准确率达到了86%,得到了较好的分类效果。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。