基于swin transformer的低剂量ct去噪方法
技术领域
1.本发明涉及计算机医学成像技术领域,尤其涉及一种基于swin transformer的低剂量ct去噪方法。
背景技术:
2.计算机断层成像(computed tomography,ct)技术使用x射线从不同方向采集被扫描物体的投影信息,利用重建算法计算物体内部线性衰减系数分布,能够无创、非接触地探测物体内部结构信息并进行高分辨率成像。
3.随着ct成像系统在医学诊断上的广泛使用,x射线辐射剂量可能造成的危害逐步成为公众关注的焦点。由于辐射的累加效应,当辐射剂量超出安全范围时,会对人体生理健康产生影响,增加肿瘤、基因突变等疾病的患病风险,甚至有破坏人体组织器官的可能性。降低诊断过程的辐射剂量对于改善以上问题具有重要作用,低剂量ct(low-dose computed tomography,ldct)概念由naidich等人(d.p.naidich,c.h.marshall,c.gribbin,r.s.arams,and d.i.mccauley,low-dose ct of the lungs:preliminary observations[j],radiology,1990,175(3):729-731.)率先提出,并逐步得到ct成像领域研究学者的广泛关注。
[0004]
目前,在实际应用中实现ldct的方法主要有两种:一是采用x射线源管电流降低的方式来减弱投影采集时x射线的强度,二是通过减少实际扫描过程中的投影采集数量来实现辐射剂量的降低,即稀疏采样过程。降低管电流操作简便、易于实现,已成为临床上获取ldct图像的主要方式。然而,降低x射线光子的强度会导致投影数据的光子统计噪声增大,致使重建的ct图像质量严重退化。
技术实现要素:
[0005]
针对低剂量ct成像过程中投影图像包含严重噪声的情况,本发明提供了一种基于swin transformer的低剂量ct去噪方法,该方法构建了一种去噪的深度网络,能够利用投影图像的图像特征,对投影图像信息的分布特征进行充分挖掘,减少图像误差对细节信息保留能力,最终实现了低剂量ct噪声去除。
[0006]
本发明提供一种基于swin transformer的低剂量ct去噪方法,包括:
[0007]
步骤1:构建并训练去噪深度网络,所述去噪深度网络包括噪声估计子网络和基于swin transformer的去噪和图像恢复子网络;
[0008]
步骤2:将待去噪ct投影输入至训练好的噪声估计子网络中得到噪声水平估计图;
[0009]
步骤3:将所述待去噪ct投影和对应的噪声水平估计图同时输入至训练好的基于swin transformer的去噪和图像恢复子网络中得到去噪后的ct投影。
[0010]
进一步地,所述训练去噪深度网络具体包括:
[0011]
步骤1.1:构建低剂量ct投影中的噪声模拟生成模型;
[0012]
步骤1.2:对所述噪声模拟生成模型中的噪声参数进行调整以构建不同噪声水平
下的低剂量ct投影图像集,记作仿真数据集;
[0013]
步骤1.3:利用仿真数据集对所述去噪深度网络进行训练,得到训练好的噪声估计子网络和基于swin transformer的去噪和图像恢复子网络。
[0014]
进一步地,所述噪声模型采用公式(1)表示:
[0015][0016]
其中,i表示x射线的路径,k表示x射线光子到电子的转换增益,n0代表着x射线初始入射强度,σ2表示高斯噪声的方差。pi表示原始光子数,表示加噪后的光子数。
[0017]
进一步地,步骤1中,训练所述去噪深度网络的过程中采用公式(2)所示的损失函数:
[0018]
loss=λ1l
sl
(x,y) λ2l1(x,y)
ꢀꢀꢀ
(2)
[0019]
其中,l
sl
代表结构相似损失,λ1和λ2分别代表结构相似损失l
sl
和l1损失的权重参数,x是网络预测的输出图像,y是x对应的标签图像。
[0020]
进一步地,所述噪声估计子网络由四层卷积层组成。
[0021]
进一步地,所述基于swin transformer的去噪和图像恢复子网络包括三个相同结构的特征信息处理模块,分别记作第一特征信息处理模块、第二特征信息处理模块和第三特征信息处理模块;第一特征信息处理模块和第二特征信息处理模块分别对输入的待去噪ct投影和对应的噪声水平估计图进行特征处理,将两个特征信息处理模块的输出进行特征融合后输入至第三特征信息处理模块,第三特征信息处理模块的输出即为去噪后的ct投影。
[0022]
进一步地,所述特征信息处理模块具体包括三个卷积层和两个swin transformer模块,分别记作第一卷积层、第二卷积层、第三卷积层、第一swin transformer模块和第二swin transformer模块;
[0023]
所述特征信息处理模块的特征信息处理过程具体包括:第一卷积层对输入的特征图进行特征提取,将提取出的特征信息记作第一特征信息;第一特征信息依次经第一swin transformer模块和第二卷积层处理,将处理后输出的特征信息记作第二特征信息;将第一特征信息和第二特征信息进行特征融合后再依次经第二swin transformer模块和第三卷积层进行处理处理,将处理后输出的特征信息记作第三特征信息;将第一特征信息、第二特征信息和第三特征信息进行特征融合后作为所述特征信息处理模块的输出。
[0024]
进一步地,所述第一特征信息处理模块对待去噪ct投影处理得到的中间特征被传递至所述第二特征信息处理模块中的第一swin transformer模块中。
[0025]
本发明的有益效果:
[0026]
本发明首先通过噪声估计子网络对不同扫描条件下的噪声进行估计和提取,然后去噪和图像恢复子网络将带噪的ct投影图像和噪声水平图作为输入,基于swintransformer的去噪和图像恢复子网络进行全局结构特征提取和细节恢复。为了在网络训练过程中提升噪声去除和细节恢复能力,又创新性的提出了结构相似性损失和l1损失相结合的损失约束。通过生成大量的训练数据,可以很好地完成网络训练,通过获得的训练参数,可以快速有效地解决低剂量ct噪声去除问题。
附图说明
[0027]
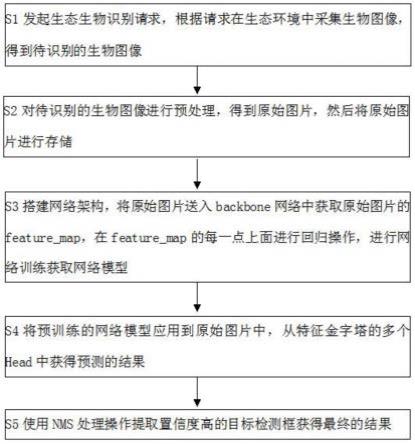
图1为本发明实施例提供的基于swin transformer的低剂量ct去噪方法的流程示意图之一;
[0028]
图2为本发明实施例提供的噪声估计子网络的示意图;
[0029]
图3为本发明实施例提供的去噪和图像恢复子网络的示意图;
[0030]
图4为本发明实施例提供的去噪的深度网络进行去噪的示意图;
[0031]
图5为本发明实施例提供的测试结果示意图。
具体实施方式
[0032]
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0033]
实施例1
[0034]
如图1所示,本发明实施例提供一种基于swin transformer的低剂量ct去噪方法,包括以下步骤:
[0035]
s101:构建并训练去噪深度网络,所述去噪的深度网络包括噪声估计子网络和基于swin transformer的去噪和图像恢复子网络;
[0036]
具体地,ct投影图像中的噪声主要包含在高频信息中,低频信息不仅包含图像的主要内容,还有减弱的图像纹理信息,利用低频信息中的图像纹理信息可以更高效的去除高频信息中的噪声。
[0037]
基于以上特性,本发明实施例设计了投影图像的去噪网络,为了完成投影图像中噪声的去除和图像细节信息的保留和恢复,将去噪网络分为两个子网络:噪声估计子网络和去噪和图像恢复子网络。噪声估计子网络用于后续以噪声特性为损失约束从ct投影图像中估计获取噪声水平估计图。去噪和图像恢复子网络用于后续将ct投影图像和噪声水平估计图作为输入得到最终的去噪结果。
[0038]
s102:将待去噪ct投影输入至训练好的噪声估计子网络中得到噪声水平估计图;
[0039]
s103:将所述待去噪ct投影和对应的噪声水平估计图同时输入至训练好的基于swin transformer的去噪和图像恢复子网络中得到去噪后的ct投影。
[0040]
具体地,噪声估计子网络获取的噪声水平估计图包含主要的噪声信息,同时由于网络深度及非线性刻画能力以及损失约束不充分,因此噪声水平估计图也会包含图像的纹理信息。
[0041]
因此,本发明实施例提供的基于swin transformer的低剂量ct去噪方法,首先通过噪声估计子网络对带噪的ct投影图像中的噪声进行估计和提取得到噪声水平估计图,然后基于swintransformer的去噪和图像恢复子网络将带噪的ct投影图像和噪声水平估计图作为输入,去噪和图像恢复子网络能够从原始低剂量ct投影图像中提取内容特征和潜在纹理特征,以及从噪声水平估计图中提取高频纹理特征,从而进行全局结构特征提取和细节恢复,提升了输出图像的去噪精度。
[0042]
实施例2
[0043]
在上述实施例的基础上,本发明实施例还提供一种基于swin transformer的低剂量ct去噪方法,包括以下步骤:
[0044]
s201:构建低剂量ct投影中的噪声模型;
[0045]
具体地,发明人认为引起ldct中的噪声有两个本质原因:(1)在x射线发射过程中存在相互作用的量子波动从而存在噪声,该类噪声称为光子统计噪声,通常服从复合泊松分布,即使在理想探测系统下,该噪声仍然不可避免。(2)在实际应用中,理想的探测系统是不存在的,电子器件和系统本身存在噪声,进而导致投影数据存在噪声,该类噪声通常称为探测系统热噪声,一般假设该噪声服从高斯分布。
[0046]
基于上述的分析,本发明实施例综合考虑了光子统计噪声和系统热噪声的统计特性,充分利用了投影数据的统计特性,将低剂量ct投影中的噪声模型采用公式(1)表示:
[0047][0048]
其中,i表示x射线的路径,k表示x射线光子到电子的转换增益,n0代表着x射线初始入射强度,σ2表示高斯噪声的方差。pi表示原始光子数,表示加噪后的光子数。
[0049]
s202:对所述噪声模型中的噪声参数进行调整以构建不同噪声水平下的低剂量ct投影图像集,记作仿真数据集;
[0050]
具体地,通过修改n0和σ2这两个噪声参数来调整噪声的强度和复杂性。噪声去除的难度随噪声的强度和复杂性的增加而增大。为了提升网络的泛化能力,本发明实施例调整了多组参数值,仿真了不同的噪声水平,从而构建了丰富的样本数据。本实施例中,共制作了50000张训练样本数据,5000张验证样本数据。
[0051]
s203:构建去噪深度网络,所述去噪深度网络包括如图2所示的噪声估计子网络和如图3所示的基于swin transformer的去噪和图像恢复子网络;
[0052]
具体地,所述噪声估计子网络由四层卷积层组成。网络通过噪声分布的空间距离约束,实现对输入投影图像的噪声水平估计。
[0053]
所述基于swin transformer的去噪和图像恢复子网络包括三个相同结构的特征信息处理模块,分别记作第一特征信息处理模块、第二特征信息处理模块和第三特征信息处理模块;第一特征信息处理模块和第二特征信息处理模块分别对输入的待去噪ct投影和对应的噪声水平估计图进行特征处理,将两个特征信息处理模块的输出进行特征融合后输入至第三特征信息处理模块,第三特征信息处理模块的输出即为去噪后的ct投影。
[0054]
其中,如图3所示,每个所述特征信息处理模块均包括:三个卷积层和两个swin transformer模块,分别记作第一卷积层、第二卷积层、第三卷积层、第一swin transformer模块和第二swin transformer模块;
[0055]
所述特征信息处理模块的特征信息处理过程具体包括:第一卷积层对输入的特征图进行特征提取,将提取出的特征信息记作第一特征信息;第一特征信息依次经第一swin transformer模块和第二卷积层处理,将处理后输出的特征信息记作第二特征信息;将第一特征信息和第二特征信息进行特征融合后再依次经第二swin transformer模块和第三卷积层进行处理处理,将处理后输出的特征信息记作第三特征信息;将第一特征信息、第二特征信息和第三特征信息进行特征融合后作为所述特征信息处理模块的输出。
[0056]
其中,swin transforme模块(stb)用于将输入图像拆分为非重叠等尺寸的小块,
每个小块分别被视为一个标识。若给定的输入图像尺寸为h*w*c,stb拆分出的小块尺寸为p2*c,其中h、w为图像的长和宽,c为通道数,p为小块尺寸。则共可拆分出n=h*w/p2个小块。在本发明实施例中,给定ldct图像尺寸为512*512*1,如此每张输入图像被处理成了4096个图片小块,每个小块被展平为128维的标识向量,整体上是一个展平的4096*128维序列。卷积层用于将维度为4096*128的张量进行映射以提取图像特征。
[0057]
为了进一步提取噪声中的纹理特征,所述第一特征信息处理模块对待去噪ct投影处理得到的中间特征被传递至所述第二特征信息处理模块中的第一swin transformer模块中,通过该操作,原始的待去噪ct投影图像的中间特征会传递给噪声水平估计图的特征处理过程中,进而实现噪声水平图像中纹理信息的恢复,提高整个网络对图像中的细节纹理信息的恢复能力。
[0058]
在图3所示的特征信息处理模块的结构的基础上,作为一种可实施方式,原始的待去噪ct投影图像的第二特征信息被传递至噪声水平估计图的特征处理过程中,以便与噪声水平估计图的第一特征信息进行特征融合。
[0059]
与传统的多头自注意模块不同,swintransforme模块(stb)是基于局部注意力与移位窗口机制构建的。图3的下半部分给出了stb的架构图。该stb中包括基于窗口的多头自注意模块和基于移位窗口的多头自注意模块,当不同层的窗口划分固定时,不同局部窗口之间不存在新交互。因此,窗口划分与窗口移位用于进行跨窗口信息交互。
[0060]
s204:利用仿真数据集对所述去噪深度网络进行训练,得到训练好的噪声估计子网络和基于swin transformer的去噪和图像恢复子网络;
[0061]
具体地,在训练去噪深度网络时,构建损失函数来指导训练过程是很关键的。本发明将投影去噪作为一个图像复原任务,为了提升网络对噪声的去除以及细节的保留能力,本实施例设计了由结构相似损失和l1损失两部分组成的损失函数。该损失函数采用公式(2)表示:
[0062]
loss=λ1l
sl
(x,y) λ2l1(x,y)
ꢀꢀꢀ
(2)
[0063]
其中,l
sl
代表结构相似损失,λ1和λ2分别代表结构相似损失l
sl
和l1损失的权重参数,x是网络预测的输出图像,y是x对应的标签图像。
[0064]
本实施例中,之所以同时引入结构相似损失l
sl
和l1损失两种损失的原因在于:结构相似(ssim)损失对于图像产生的均匀偏差非常不敏感,单独作为损失函数时会造成颜色的变化或亮度的改变,但可以较好的保留高频区域的对比度;l1损失单独作用时可以保留颜色和亮度,但会造成局部细节模糊。因此本实施例将两个损失结合,设置不同的权重,通过整体优化进一步提高恢复图像的质量。
[0065]
s205:将待去噪ct投影输入至训练好的噪声估计子网络中得到噪声水平估计图;
[0066]
s206:将所述待去噪ct投影和对应的噪声水平估计图同时输入至训练好的基于swin transformer的去噪和图像恢复子网络中得到去噪后的ct投影。
[0067]
具体地,如图4所示,将待去噪ct投影输入至第一特征信息处理模块中,将对应的噪声水平估计图输入至第二特征信息处理模块中,两个特征信息处理模块输入的特征进行融合后输入至第三特征信息处理模块中从而得到去噪后的ct投影。
[0068]
本发明实施例提供的基于swin transformer的低剂量ct投影去噪方法,首先通过分析投影的生成过程及噪声生成机制,对投影数据噪声的固有统计特性进行刻画,并基于
投影图像特性,制作匹配的训练样品数据集。通过综合图像特征信息和噪声信息,设计网络损失函数,提升噪声去除的针对性和对细节保留的有效性。利用噪声估计子网络对不同扫描条件下的噪声进行估计和提取,获得投影图像的噪声水平估计图。利用基于swin transformer块的去噪和图像恢复子网络分别对投影图像和噪声水平估计图进行深度特征提取。从原始低剂量投影图像中提取内容特征和潜在纹理特征,并从噪声水平图提取高频纹理特征。最后,将两个特征信息处理模块提取的特征融合后进一步反馈给最后的swin transformer块,实现图像的恢复,以提升输出图像的去噪精度;网络经过训练后获得网络参数,利用所得参数可以快速准确的完成投影图像噪声去除。
[0069]
为了证明本发明方法的有效性,本发明还提供了下述对比实验。
[0070]
(1)准备仿真数据集和实际数据集
[0071]
仿真数据集的构建过程在上文中已给出,此处不再赘述。
[0072]
因为噪声产生原因的复杂性,难以利用简化的模型进行精确刻画,仿真过程中只能模拟其中主要的方面,无法得到与真实噪声一致的图像。因此,为了验证本发明提出的方法在实际条件下对真实噪声的去噪效果,进一步构建了实际数据集进行实际数据的处理。
[0073]
构建实际数据集:利用16层医用ct(somatom sensation,siemens)对胸腔体膜进行扫描。扫描过程中通过设置不同的电流值实现对正常剂量和低剂量投影图像的获取,管电压为150kvp,正常剂量电流设置为120mas,用于实现ldct的管电流设置为30mas。
[0074]
(2)去噪深度网络的训练和测试
[0075]
网络的训练和测试均是在amax工作站上的pytorch(版本1.14.0)环境下完成训练和测试。所使用的amax工作站的两个cpu型号均为intel xeon gold 5118,可用内存为64gb。网络训练和测试使用的四个计算显卡型号均为geforce rtx a5000,每个显卡内存为24gb。网络选择的目标函数优化器为adam,学习率设置为1
×
10-4
。在仿真实验中,批量大小为32,训练过程迭代轮数共30轮,整个网络的训练需花费约100小时。
[0076]
(3)对比网络
[0077]
选择了dncnn,cbdnet作为对比网络。
[0078]
(4)实验结果
[0079]
分别采用本发明的去噪网络、dncnn网络和cbdnet网络对实际数据集中的待去噪ct投影进行去噪测试,测试结果如图5所示。
[0080]
图5显示了低剂量腹部ct的重建图像结果。从图5中可以看出,包含噪声的ct图像质量严重恶化,一些细小的结构模糊不清。所有应用的方法在不同程度上实现了对图像噪声的抑制。在dncnn和cbdnet虽然在一定程度上可以抑制ct图像中的噪声,但是仍有肉眼可见的噪声残余。在图5中,本发明方法在抑制伪影噪声和保留特征方面都有进一步的提高,在外观上最接近正常剂量的ct图像。这是因为,相较于其他网络,transformer框架特有的注意力机制可以有效的获取全局特征信息,大批量训练数据的投入,为充分发挥网络效能提供了基础。获得的校正结果表明,本方法提出的基于swin transformer的低剂量ct投影去噪方法可以充分地提取ldct图像的特征信息,能够有效地去除ct图像中的噪声。
[0081]
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;
而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。