一种基于无源rfid的垃圾袋信息收集方法
技术领域
1.本发明属于信息技术领域,具体涉及一种基于无源rfid的垃圾袋信息收集方法。
背景技术:
2.生活垃圾分类回收是破解“垃圾围城”困境和开发“城市矿产”的有效途径。迄今为止,全国已有46个城市启动垃圾分类工作,取得了一定的成效。在垃圾分类执行过程中,其中很大一部分成本是垃圾的信息管理,包括垃圾投掷是否符合分类要求、垃圾来源登记、垃圾数量统计等。目前大多数垃圾分类应用场景都设置专职的管理员,负责垃圾桶管理,但是这种方法消耗大量人力物力,成本较高。因此,如何利用自动化、信息化的方法实现垃圾信息自动管理,是一个非常有研究意义和实用价值的课题。
3.电子标签(rfid)可以实现非接触式信息识别和提取,具有较强的穿透力,对水、油和化学药品等物质具有很强抵抗性,因此可以作为垃圾袋的信息存储介质,应用于垃圾分类场景中。rfid技术在垃圾信息处理中已有部分研究成果,如公开号为cn215708915u的中国专利提出了一种垃圾分类投放装置,该技术方案在垃圾桶上贴有rfid标签,rfid标签和智能终端信号连接,智能终端的输出信号和射频芯锁连接,智能终端的输出信号通过无线模块和社区服务器连接。又如公开号为cn215624415u的中国专利提出了一种用于厨余垃圾收集的智慧桶,该技术方案在垃圾桶底部通过快拆机构安装于底座上,底座内嵌设有rfid芯片,底座的底面上固定有磁性件,解决了背景技术中所提出的现有能够追踪和识别家庭厨余垃圾倾倒过程的智能垃圾桶容易损坏且成本高的问题。公开号为cn112722641a的中国专利提出了一种基于rfid自动识别的垃圾车载称重设备,该技术方案可以自动对垃圾桶上的标签进行识别,进行垃圾的分类称重。以上专利技术都是着眼于垃圾桶的硬件设计,而在实际使用过程中,rfid信息读取会受到影响,如多个标签读取冲突、标签读取遗漏等,标签信息的误操作会影响垃圾分类的准确性和信息登记完整性,显著影响垃圾分类的效果。
4.在rfid信息读取理论研究方面,目前的研究成果大多面向防冲突机制的设计,如文献[李欣怡,李晓武,游进国,等.单阅读器移动rfid系统下改进的标签防碰撞算法[j].化工自动化及仪表,2021,48(5):486-490]、文献[莫磊,唐斌,房梦旭.一种减少通信复杂度的rfid搜索树防碰撞算法[j].电讯技术,2021,61(10):1297-1301]以及文献[王冬云,张维平,汪志佳.基于改进aloha算法的rfid标签防碰撞研究[j].包装工程,2021,42(17):244-248]都有提出相应的技术方案。但与其他rfid应用场合不同,小区垃圾分类箱每天只开放两次,每次两小时,剩下的时间都是封闭的,没有新的垃圾产生,有大量的时间可以用于信息收集,因此对时效性要求不高。由于垃圾桶空间限制,垃圾袋rfid标签信息读取时必然会发生标签碰撞,因此垃圾信息收集主要的关注点是信息的完整性,必须最大程度确保收录每一袋垃圾的信息。
[0005]
综上所述,小区垃圾分类使用场景下的垃圾袋rfid信息收集,有以下需求:
[0006]
1.由于垃圾袋数量巨大,rfid条成本要求尽量低,因此只能选择无源rfid条。
[0007]
2.由于垃圾投掷行为错综复杂,无法在投掷时统计总数,单个垃圾桶内rfid条总
数不明,因此需要设计算法来估计,而且精确度要求高。
[0008]
3.由于单个垃圾桶容积有限,垃圾袋重叠堆放,造成rfid读取很容易发生冲突,因此需要设计rfid读取防冲突机制。
技术实现要素:
[0009]
鉴于上述,本发明提供了一种基于无源rfid的垃圾袋信息收集方法,能够满足各种小区垃圾分类场景下垃圾信息收集的需求,覆盖面广,准确度高,成本低,有较好地普适性和灵活性。
[0010]
一种基于无源rfid的垃圾袋信息收集方法,包括如下步骤:
[0011]
(1)预设rfid标签各字段信息,并将rfid条贴在垃圾袋上,同时在垃圾桶内安装一个rfid标签阅读器;
[0012]
(2)利用rfid标签阅读器对垃圾桶内的垃圾袋进行第一轮标签信息读取,第一轮的读取次数s1为预先设定,每次读取仅接受一条标签响应并记录该标签信息,因此总共会接收到s1条标签响应,若这s1条标签响应来自m个标签,则统计本轮检测到的这m个标签各自的响应次数以及最长连续响应次数,并以此计算下一轮的读取次数;
[0013]
(3)从第二轮开始,每一轮的读取次数由上一轮计算得到,并将检测到的新标签记录下来,除此之外还需要计算每一轮的迭代预测系数,并将迭代预测系数与阈值进行比较,若小于阈值,则进行下一轮;若大于等于阈值,则进入后续轮,并计算出后续轮的读取次数r;
[0014]
(4)后续轮的读取次数r固定,每次读取仅接受一条标签响应并记录该标签信息,因此总共会接收到r条标签响应,若这r条标签响应来自p个标签,如其中存在新标签则记录下来,进而统计本轮检测到的这p个标签各自的响应次数以及最长响应间隔,以此计算本轮的置信系数;
[0015]
(5)将置信系数与阈值进行比较,若小于阈值,则根据步骤(4)进行下一轮;若大于等于阈值,则停止,并根据之前记录下来的标签信息确定垃圾桶内的垃圾袋总数量以及错误投掷的垃圾袋数量。
[0016]
进一步地,所述步骤(1)中预设rfid标签各字段信息,将标签中第1~8位设为所在城市区域信息,9~16位设为街道信息,17~32位设为小区信息,33~44位设为家庭单元户信息,45~47位设为垃圾类型信息,48位设为误投标志,49~64位设为序列号,剩下的为保留位。
[0017]
进一步地,对于第i 1轮,其读取次数s
i 1
的计算表达式如下:
[0018][0019]
其中:ai和a
i-1
分别为第i轮和第i-1轮的全局散布系数,a
max
为a1~ai的最大值,bi为第i轮的聚合系数,b
max
为b1~bi的最大值,δ为预设参数,si为第i轮的读取次数,i为大于0的自然数,a0=0;
[0020]
若算得的s
i 1
>1.2s
max
,则将s
i 1
限制为1.2s
max
,s
max
为s1~si的最大值;若算得的si 1
<0.8s
min
,则将s
i 1
限制为0.8s
min
,s
min
为s1~si的最小值。
[0021]
进一步地,所述全局散布系数ai的表达式如下:
[0022][0023]
其中:xj为第i轮检测到第j个标签的响应次数,g1和g2为给定的权重值,x
avg
为第i轮检测到所有标签响应次数的平均值。
[0024]
进一步地,所述聚合系数bi的表达式如下:
[0025][0026]
其中:xj为第i轮检测到第j个标签的响应次数,yj为第i轮检测到第j个标签的最长连续响应次数,x
avg
为第i轮检测到所有标签响应次数的平均值,x
max
为第i轮检测到所有标签响应次数的最大值。
[0027]
进一步地,对于第i轮,其迭代预测系数ei的计算表达式如下:
[0028][0029]
其中:α、β1和β2为预设参数,ai为第i轮的全局散布系数,bi为第i轮的聚合系数,ci为第i轮的回归期望系数,di为第i轮的差分系数,d
max
为d1~di的最大值,d
avg
为d1~di的平均值,c
max
为c1~ci的最大值,b
avg
为b1~bi的平均值,i为大于0的自然数。
[0030]
进一步地,所述回归期望系数ci的表达式如下:
[0031][0032]
其中:xj为第i轮检测到第j个标签的响应次数,x
max
为第i轮检测到所有标签响应次数的最大值,yj为第i轮检测到第j个标签的最长连续响应次数,y
max
为第i轮检测到所有标签最长连续响应次数的最大值,ρ为预设参数。
[0033]
进一步地,所述差分系数di的表达式如下:
[0034][0035]
其中:xj为第i轮检测到第j个标签的响应次数,x
avg
为第i轮检测到所有标签响应次数的平均值,x
max
为第i轮检测到所有标签响应次数的最大值,yj为第i轮检测到第j个标签的最长连续响应次数,y
avg
为第i轮检测到所有标签最长连续响应次数的平均值,y
max
为第i轮检测到所有标签最长连续响应次数的最大值,λ为预设参数。
[0036]
进一步地,对于第i轮,若其迭代预测系数ei大于等于阈值,则通过以下表达式计算后续轮的读取次数r;
[0037][0038]
其中:s
max
为s1~si的最大值,s
min
为s1~si的最小值,s
avg
为s1~si的平均值,si为第i轮的读取次数,i为大于0的自然数;
[0039]
若算得的r>1.3s
max
,则将r限制为1.3s
max
;若算得的r<0.9s
min
,则将r限制为0.9s
min
。
[0040]
进一步地,所述步骤(4)中置信系数的计算表达式如下:
[0041][0042]
其中:f为本轮的置信系数,xk为本轮检测到第k个标签的响应次数,zk为本轮检测到第k个标签的最长响应间隔,gk对应为zk的权重系数,g3和g4为给定的权重值,φ和γ为预设参数,xa为本轮检测到所有标签响应次数的平均值,xm为本轮检测到所有标签响应次数的最大值,z
avg
为本轮检测到所有标签最长响应间隔的平均值,am为后续轮之前所有轮全局散布系数的最大值,cm为后续轮之前所有轮回归期望系数的最大值,ca为后续轮之前所有轮回归期望系数的平均值,ba为后续轮之前所有轮聚合系数的平均值。
[0043]
基于上述技术方案,本发明具有以下有益技术效果:
[0044]
1.本发明使用无源rfid标签作为信息存储和收集介质,成本低。
[0045]
2.本发明可以完整收集整个垃圾桶内所有垃圾袋的信息,准确度高。
[0046]
3.本发明算法复杂度较低,有利于编程实现。
附图说明
[0047]
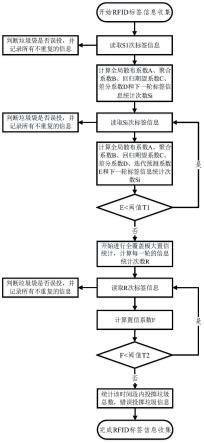
图1为本发明垃圾袋信息收集方法的流程示意图。
具体实施方式
[0048]
为了更为具体地描述本发明,下面结合附图及具体实施方式对本发明的技术方案进行详细说明。
[0049]
本发明基于无源rfid的垃圾袋信息收集方法的基本思路是:在每个垃圾桶内安装一个rfid标签阅读器,每个垃圾袋贴一个rfid标签;当读卡器发出读卡请求时,会有一个或者多个标签响应。由于无源rfid标签的功能局限,每次发生标签响应冲突时,阅读器只能接收其中一个标签页的信息,而且在本应用场景中,垃圾袋和rfid标签页的总数是未知的;因此,本发明需要解决的主要问题是如何遍历所有的rfid标签页。理论上来说,只要发送无限多的读卡请求次数,就能够遍历所有的rfid标签页;但在实际应用中,不可能无限制读卡,如何判断所有rfid标签页已经被读取,尽可能在有限的时间内提高信息收集的完整度,是本发明需要解决的主要问题。
[0050]
通过理论研究表明,在一对多rfid读写、单个响应场景中,分析多次(超过1000次)读写请求的结果可得,各个不同的rfid标签页读取次数的数理统计特征值(概率分布、连续读取次数、读取间隔数等)与rfid标签页总数存在一定关系。因此,可以通过大量的实验样本,利用这些数理统计特征值来反推rfid标签页总数,故本发明方法的具体流程如图1所示:
[0051]
(1)预设rfid标签各字段信息,并将rfid条贴在垃圾袋上。
[0052]
在垃圾分类应用中,信息收集者关注的信息主要有:
[0053]
垃圾来源:垃圾袋投递者的地址、房间号等。
[0054]
垃圾类型:目前垃圾主要分四类,垃圾类型信息的设定,主要是为了判断该垃圾与垃圾桶是否匹配,即垃圾投递是否符合规则。
[0055]
垃圾袋识别号:用于垃圾袋的追溯,垃圾桶每日进出垃圾数量统计等。
[0056]
目前常用的无源rfid标签页可以存储100位以上的信息,本发明将标签中第1~8位设为该垃圾袋所在城市区域信息,9~16位设为街道信息,17~32位设为小区信息,33~44位设为家庭单元户信息,45~47位设为垃圾类型信息,48位设为误投标志,49~64设为序列号,剩下的比特位为保留位。
[0057]
(2)第一轮读取s1次标签信息,每次仅接受一条标签响应。比较该标签信息的45~47位标识的垃圾类型与垃圾桶是否一致,若不一致,将第48位标识为1,记录误投;在数据库中搜索该标签49~64位的序列号,若数据库中没有该标签信息,则记录该标签信息。统计这s1次中m个不重复的标签各自响应次数x1,x2,
…
,xm以及各自的最长连续响应次数y1,y2,
…
,ym,在此基础上计算全局散布系数a、聚合系数b、回归期望系数c和差分系数d,在此基础上计算下一轮标签信息统计次数si。
[0058]
本发明通过分析rfid标签页读取次数的数理统计特征值来反推rfid标签页总数,用到的特征值有:反映读取次数散布规律的全局散布系数a、反映读取次数集中度的聚合系数b、反映读取次数重复度的回归期望系数c、反映不同标签读取重复度的差分系数d。通过一轮s次读取响应计算得到的以上系数,并不能完整反映整个数据集的真实情况,因此需要多轮测试,以提高结果的准确度。本发明在计算以上系数的基础上计算下一轮标签信息统计次数si,a、b、c、d和si的计算方法如下所示:
[0059][0060][0061][0062][0063][0064]
si=1.2
×smax
ꢀꢀꢀ
if si>1.2
×smax
[0065]
si=0.8
×smin
ꢀꢀꢀ
if si<0.8
×smin
[0066]
其中:x
avg
为所有xi的均值,x
max
为所有xi的最大值,y
avg
为所有yi的均值,y
max
为所有yi的最大值,g1~g2为给定权重值,ρ和λ为预设参数,a
max
为目前为止所有a的最大值,ab为上一轮计算得到的a值,b
max
为目前为止所有b的最大值,s为上一轮的统计次数,第一轮统计次数s1为预设值,s
max
为所有si的最大值,s
min
为所有si的最小值。
[0067]
(3)第二轮开始,每一轮读取si次标签信息,si为上一轮计算的结果,每次仅接受一条标签响应。比较该标签信息的45~47位标识的垃圾类型与垃圾桶是否一致,若不一致,将第48位标识为1,记录误投。在数据库中搜索该标签49~64位的序列号,若数据库中没有该标签信息,则记录该标签信息,统计这s2次中n个不重复的标签各自响应次数x1,x2,
…
,xm以及各自的最长连续响应次数y1,y2,
…
,ym,并以此计算新的全局散布系数a、聚合系数b、回归期望系数c、差分系数d和迭代预测系数e,在此基础上计算下一轮标签信息统计次数s
i 1
。系数a、b、c、d和s
i 1
的计算方法同步骤(2),迭代预测系数e的计算方法如下所示:
[0068][0069]
其中:b
avg
为到目前为止所有b的平均值,c
max
为到目前为止所有c的最大值,d
avg
为到目前为止所有d的平均值,d
max
为到目前为止所有d的最大值,α、β1和β2为预设参数。
[0070]
(4)将迭代预测系数e与阈值t1进行比较,若e小于t1,则代表尚未得到最精确的数理统计特征值,需要重复第(3)步,计算新的全局散布系数a、聚合系数b、回归期望系数c、差分系数d和迭代预测系数e,在此基础上计算下一轮标签信息统计次数si;直到e大于等于t1,得到足够精确度的数理统计特征值,停止重复第(3)步,开始后续的多轮全覆盖极大置信统计,后续每一轮的全覆盖极大置信统计,需要发起的信息统计次数r由已有的每一轮统计次数计算得到,如下式所示:
[0071][0072]
si=1.3
×smax
ꢀꢀꢀ
if si>1.3
×smax
[0073]
si=0.9
×smin
ꢀꢀꢀ
if si<0.9
×smin
[0074]
其中:s
avg
为所有si的平均值,s
max
为所有si的最大值,s
min
为所有si的最小值。
[0075]
(5)读取r次标签信息,每次仅接受一条标签响应,比较该标签信息的45~47位标识的垃圾类型与垃圾桶是否一致,若不一致,将第48位标识为1,记录误投。在数据库中搜索该标签49~64位的序列号,若数据库中没有该标签信息,则记录该标签信息;统计这r次中p个不重复的标签各自响应次数x1,x2,
…
,x
p
以及各自的最长响应间隔z1,z2,
…
,z
p
,并以此计算置信系数f,如下式所示:
[0076][0077][0078]
其中:x
avg
为所有xi的平均值,x
max
为所有xi的最大值,z
avg
为所有zi的平均值,a
max
为步骤(2)和(3)中所有a的最大值,b
avg
为步骤(2)和(3)中所有b的平均值,c
max
为步骤(2)和(3)中所有c的最大值,c
avg
为步骤(2)和(3)中所有c的平均值,φ和γ为预设参数,g3~g4为给定权重值。
[0079]
(6)将置信系数f与阈值t2进行比较,若f小于t2,代表可能存在rfid标签条尚未被记录,继续重复步骤(5),并计算新置信系数f,直到f大于等于t2,代表所有rfid标签条都已被记录,停止重复步骤(5),整个信息收集工作完成。
[0080]
(7)根据所有记录的标签信息,统计该时间段内投掷垃圾总数以及错误投掷垃圾信息。
[0081]
本实施方式中的参数设定值为:s1=1200,t1=174,t2=26.3,g1=0.55,g2=0.47,g3=0.64,g4=0.53,α=1.6,β1=0.92,β2=0.37,λ=1.4,ρ=1.2,δ=1.52,φ=1.2,γ=0.8。
[0082]
上述对实施例的描述是为便于本技术领域的普通技术人员能理解和应用本发明。熟悉本领域技术的人员显然可以容易地对上述实施例做出各种修改,并把在此说明的一般原理应用到其他实施例中而不必经过创造性的劳动。因此,本发明不限于上述实施例,本领域技术人员根据本发明的揭示,对于本发明做出的改进和修改都应该在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。