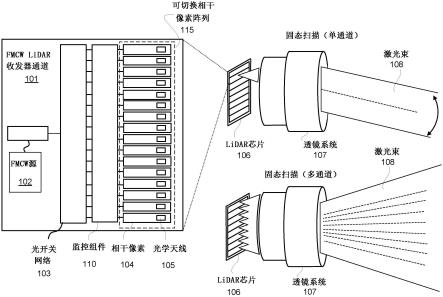
1.本技术涉及糖尿病检测领域,特别涉及一种预测受试者患有糖尿病的可能性的标记物及其应用。
背景技术:
2.糖尿病是世界四大非传染性疾病之一,近年来患病人数逐渐增多。目前,对于妊娠期糖尿病,口服葡萄糖耐量试验(oral glucose tolerance test,ogtt)是早起筛查是否患有糖尿病的主要方法,但该方法存在一些缺点。例如,进行ogtt需要至少8小时的隔夜禁食和5分钟内饮用含有75克葡萄糖的液体,但一些人(例如,孕妇)不能轻易应用隔夜禁食,对葡萄糖饮料难以耐受,可能会引起不良反应,包括恶心、呕吐、腹胀和头痛。此外,检测结果为正常的人也不得不进行ogtt,但是并没有获得任何临床益处。因此,鉴于目前筛选方法的缺陷,亟需一种更客观、更方便且无不良反应的糖尿病检测方法。
技术实现要素:
3.根据本技术的一方面,提供标记物在制备用于预测受试者患有糖尿病的可能性的试剂、组合物或试剂盒中的应用。所述预测可以包括:基于来自所述受试者的样品,确定所述标记物的浓度,其中,所述标记物包括α-羟基丁酸(α-hydroxybutyric acid,α-hb)、1,5-脱水葡萄糖醇(1,5-anhydroglucitol,1,5-ag)、非对称性二甲基精氨酸(asymmetric dimethylarginine,adma)、胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸、羟赖氨酸、l-天冬氨酸中的至少一种;以及基于所述标记物的浓度,使用与所述标记物相关的预测模型预测所述受试者患有糖尿病的可能性。
4.在一些实施例中,所述糖尿病可以包括一型糖尿病、二型糖尿病或妊娠期糖尿病(gestational diabetes mellitus,gdm)。
5.在一些实施例中,所述标记物可以包括α-hb。
6.在一些实施例中,所述标记物可以包括1,5-ag和adma。
7.在一些实施例中,所述标记物可以包括胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸和羟赖氨酸。
8.在一些实施例中,所述标记物可以包括α-hb、1,5-ag、胱氨酸、乙醇胺、牛磺酸和l-天冬氨酸。
9.在一些实施例中,基于所述标记物的浓度,使用与所述标记物相关的预测模型预测所述受试者患有糖尿病的可能性可以包括:所述标记物的浓度作为所述预测模型的输入,所述预测模型输出预测值;以及通过比较所述预测值和阈值,预测所述受试者患有糖尿病的可能性。
10.在一些实施例中,通过比较所述预测值和阈值预测所述受试者患有糖尿病的可能性可以包括:若所述预测值大于或等于所述阈值,预测所述受试者患有糖尿病的可能性较高;或若所述预测值小于所述阈值,预测所述受试者患有糖尿病的可能性较低。
11.在一些实施例中,所述预测模型还可以与所述受试者的年龄和bmi相关。
12.在一些实施例中,所述预测模型由公式表示,其中,p表示所述受试者为糖尿病的概率值,表示对数优势比,α-hb表示α-hb的浓度,单位为μmol/l。
13.在一些实施例中,所述预测模型由公式表示,其中,p表示所述受试者为糖尿病的概率值,表示对数优势比,1,5-ag和adma分别表示1,5-ag和adma的浓度,单位为μmol/l。
14.在一些实施例中,所述预测模型由公式表示,其中,p表示所述受试者为糖尿病的概率值,表示对数优势比,胱氨酸、乙醇胺、l-亮氨酸、l-色氨酸、羟赖氨酸和牛磺酸分别表示胱氨酸、乙醇胺、l-亮氨酸、l-色氨酸、羟赖氨酸和牛磺酸的浓度,单位为μmol/l。
15.在一些实施例中,所述预测模型由公式表示,其中,p表示所述受试者为糖尿病的概率值,表示对数优势比,1,5-ag、α-hb、牛磺酸、l-天冬氨酸、胱氨酸和乙醇胺分别表示1,5-ag、α-hb、牛磺酸、l-天冬氨酸、胱氨酸和乙醇胺的浓度,单位为μmol/l。
16.在一些实施例中,所述预测模型在验证集中auc值均大于0.7,在验证集中的敏感度和特异度均大于65%。
17.根据本技术的另一方面,还提供了用于预测受试者患有糖尿病的可能性的标记物,其特征在于,所述标记物包括α-hb、1,5-ag、adma、胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸、羟赖氨酸、l-天冬氨酸中的至少一个。
18.根据本技术的再一方面,还提供了预测模型在制备用于预测受试者患有糖尿病的可能性的试剂、组合物或试剂盒中的应用。所述预测模型与预测受试者患有糖尿病的可能性的标记物相关,其中,所述标记物包括α-hb、1,5-ag、adma、胱氨酸、乙醇胺、牛磺酸、l-亮
氨酸、l-色氨酸、羟赖氨酸、l-天冬氨酸中的至少一个;所述预测模型的输入为所述标记物的浓度,所述预测模型的输出为预测值,将所述预测值与阈值比较,预测所述受试者患有糖尿病的可能性。
19.根据本技术的再一方面,提供了一种用于治疗糖尿病的方法。所述方法可以包括:基于来自受试者的样品,确定标记物的浓度,其中,所述标记物包括α-hb、1,5-ag、adma、胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸、羟赖氨酸、l-天冬氨酸中的至少一种;基于所述标记物的浓度,使用与所述标记物相关的预测模型预测所述受试者患有糖尿病的可能性;以及若预测结果为所述受试者患有糖尿病,对所述受试者施用治疗糖尿病的药物。
20.根据本技术的再一方面,提供了一种用于预测受试者患有糖尿病的可能性的系统。所述系统可以包括获取模块,用于获取受试者样品的标记物的浓度,其中,所述标记物包括α-hb、1,5-ag、adma、胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸、羟赖氨酸、l-天冬氨酸中的至少一种;训练模块,用于利用训练集训练初始模型获得预测模型,所述预测模型与所述标记物相关;以及预测模块,用于基于所述标记物的浓度,使用预测模型预测所述受试者患有糖尿病的可能性。
附图说明
21.本说明书将以示例性实施例的方式进一步说明,这些示例性实施例将通过附图进行详细描述。这些实施例并非限制性的,在这些实施例中,相同的编号表示相同的结构,其中:
22.图1a和图1b分别是根据本技术一些实施例所示的25种氨基酸及其衍生物的标准品和血浆样品中25种氨基酸及其衍生物的总离子流色谱图;
23.图2a和图2b分别是根据本技术一些实施例所示的1,5-ag、tmao、adma和sdma的标准品总离子流色谱图和血浆样本中1,5-ag、tmao、adma和sdma的总离子流色谱图;
24.图3a和图3b分别是根据本技术一些实施例所示的α-hb、oa和lgpc的标准品总离子流色谱图和血浆中α-hb、oa和lgpc的总离子流色谱图;
25.图4a到图4l是根据本技术一些实施例所示的5个预测模型的全部变量与gdm显著关系的分布图,其中,黑色表示gdm,白色表示非gdm;
26.图5a到图5j是根据本技术一些实施例所示的5个预测模型在训练集和验证集中的roc曲线图。
具体实施方式
27.为了更清楚地说明本技术实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单的介绍。显而易见地,下面描述中的附图仅仅是本技术的一些示例或实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图将本技术应用于其它类似情景。除非从语言环境中显而易见或另做说明,图中相同标号代表相同结构或操作。
28.应当理解,尽管术语“第一”、“第二”、“第三”等可以在本文中用于描述各种元素,但这些元素不应受这些术语的限制。这些术语仅用于将一个元素与另一个元素区分开来。例如,第一产物可以被称为第二产物,并且类似地,在不脱离本技术的示例性实施例的范围
的情况下,第二产物可以被称为第一产物。
29.如本技术和权利要求书中所示,除非上下文明确提示例外情形,“一”、“一个”、“一种”和/或“该”等词并非特指单数,也可包括复数。一般说来,术语“包括”与“包含”仅提示包括已明确标识的步骤和元素,而这些步骤和元素不构成一个排它性的罗列,方法或者设备也可能包含其它的步骤或元素。
30.本技术中使用了流程图用来说明根据本技术的实施例的系统所执行的操作。应当理解的是,前面或后面操作不一定按照顺序来精确地执行。相反,可以按照倒序或同时处理各个步骤。同时,也可以将其他操作添加到这些过程中,或从这些过程移除某一步或数步操作。
31.本技术提供了用于预测受试者患有糖尿病的可能性的标记物,还提供了标记物在制备用于预测受试者患有糖尿病的可能性的试剂、组合物或试剂盒中的应用,还提供了预测模型在制备用于预测受试者患有糖尿病的可能性的试剂、组合物或试剂盒中的应用,还提供了一种用于治疗糖尿病的方法,还提供了一种用于预测受试者患有糖尿病的可能性的系统。在本技术中,标记物可以包括α-hb、1,5-ag、adma、胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸、羟赖氨酸、l-天冬氨酸中的至少一个。标记物可以应用到预测模型中,以预测受试者患有糖尿病的可能性。这里的糖尿病包括一型糖尿病、二型糖尿病或gdm。在一些实施例中,糖尿病为gdm。gdm被定义为在妊娠期间首次诊断出的葡萄糖耐量障碍。患有gdm的母亲患妊娠高血压和先兆子痫的风险更高,gdm母亲的胎儿可能出生体重增加(例如巨大儿),因此增加肩难产的风险,而肩难产是分娩的严重不良结果。此外,gdm会促进代谢并发症的发展,包括肥胖、代谢综合征、二型糖尿病(t2dm)和母亲及后代晚年的心血管疾病。因此,gdm在全球范围内给孕妇、胎儿和社会增加了极大的负担。
32.根据2014年中国gdm指南,基于iadpsg标准和国际糖尿病联合会,建议所有妊娠24~28周的孕妇进行“一步”2小时75g口服葡萄糖耐量试验(ogtt)。但是ogtt存在一些缺点,首先是ogtt的程序,包括至少8小时的隔夜禁食和5分钟内饮用含有75克葡萄糖的液体,很多孕妇不能轻易应用隔夜禁食,而且一些孕妇对葡萄糖饮料难以耐受,可能会引起不良反应,包括恶心、呕吐、腹胀和头痛;此外,一项基于3098名中国孕妇的研究发现,75.8%的血糖正常的妇女不得不接受ogtt,但是并没有获得任何临床益处,因此,“一步法”ogtt并未被统一采用。美国通常使用两步测试,先进行非空腹50克筛查,然后对筛查呈阳性的人进行100克ogtt,而风险因素筛查是由意大利国家卫生系统提倡的,只有高危女性接受诊断性75g ogtt。然而,这两种方法的诊断价值都低于ogtt。而在本技术中,能够根据受试者样本中的标记物的浓度,通过预测模型来预测受试者患有糖尿病的风险,使受试者(尤其是孕妇)无需隔夜禁食,无需口服葡萄糖进行葡萄糖耐量试验,对受试者身体友好,不会对受试者造成不良反应,且更为客观也更方便。
33.如本技术中所使用的,“受试者”(也可称为“个体”、“对象”)为接受糖尿病检测或预测的对象。在一些实施例中,受试者可以是脊椎动物。在一些实施例中,脊椎动物为哺乳动物。哺乳动物包括但不限于灵长类(包括人和非人灵长类)以及啮齿动物(例如,小鼠和大鼠)。在一些实施例中,受试者可以是人。在一些实施例中,受试者为孕妇。
34.根据本技术的一方面,提供了用于预测受试者患有糖尿病的可能性的标记物。糖尿病可以包括一型糖尿病、二型糖尿病或gdm。在一些实施例中,糖尿病可以是一型糖尿病。
在一些实施例中,糖尿病可以是二型糖尿病。在一些实施例中,糖尿病可以是gdm。
35.在一些实施例中,标记物可以与糖尿病相关的代谢有关,例如,与胰岛素抵抗相关的代谢、肠道微生物代谢、甘油磷脂代谢等。在一些实施例中,标记物可以包括葡萄糖类似物、有机酸、有机化合物、氨基酸等。在一些实施例中,葡萄糖类似物可以包括1,5-ag。有机酸可以包括α-hb。有机化合物可以包括乙醇胺、氧化三甲胺(trimethylamine oxide,tmao)。氨基酸可以包括l-苯丙氨酸、l-色氨酸、l-酪氨酸、l-异亮氨酸、l-亮氨酸、l-缬氨酸、瓜氨酸、胱氨酸、谷氨酰胺、谷氨酸、羟赖氨酸、l-天冬氨酸、l-丙氨酸、l-脯氨酸、l-苏氨酸、赖氨酸、蛋氨酸、牛磺酸等。在一些实施例中,标记物还可以包括其他化合物,例如,adma、对称性二甲基精氨酸(symmetric dimethylarginine,sdma)、油酸(oleic acid,oa)、亚油酰甘油磷酸胆碱(linoleylglycerophosphocholine,lpgc)等。
36.在一些实施例中,所述标记物可以包括α-hb、1,5-ag、adma、胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸、羟赖氨酸、l-天冬氨酸中的至少一个。在一些实施例中,所述标记物可以是α-hb。在一些实施例中,所述标记物可以包括1,5-ag和adma中的至少一个。在一些实施例中,所述标记物可以包括1,5-ag和adma中的全部。在一些实施例中,所述标记物可以包括胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸和羟赖氨酸中的至少一个。在一些实施例中,所述标记物可以包括胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸和羟赖氨酸中的全部。在一些实施例中,所述标记物可以包括α-hb、1,5-ag、胱氨酸、乙醇胺、牛磺酸、l-天冬氨酸中的至少一个。在一些实施例中,所述标记物可以包括α-hb、1,5-ag、胱氨酸、乙醇胺、牛磺酸、l-天冬氨酸中的全部。
37.在一些实施例中,所述标记物可以作为模型的变量应用在预测模型中。预测模型可以包括多个预测模型,例如,实施例中的预测模型2-5。每个预测模型可以与上述标记物中的至少一个有关(例如,作为预测模型的变量)。在一些实施例中,预测模型2可以与α-hb有关。在一些实施例中,预测模型3可以与1,5-ag和adma有关。在一些实施例中,预测模型4可以与胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸和羟赖氨酸有关。在一些实施例中,预测模型5可以与α-hb、1,5-ag、胱氨酸、乙醇胺、牛磺酸、l-天冬氨酸有关。在一些实施例中,预测模型还可以包括其他变量,例如,常规变量(例如,受试者的年龄、bmi)。在一些实施例中,预测模型2-5还可以与受试者的年龄和bmi相关。在一些实施例中,预测模型还可以包括预测模型1,其仅与受试者的年龄、bmi有关。应当注意的是,对于受试者为妊娠期女性,bmi则为孕前bmi。在一些实施例中,预测模型还可以是一个模型,该模型整合有上述多个预测模型。
38.可以基于上述标记物的浓度,预测模型可以输出概率值,以预测受试者患有糖尿病的可能性。具体地,这些标记物可以作为相关预测模型的变量,将受试者的标记物的浓度输入到相关的预测模型中,预测模型可以输出概率值,将概率值与模型对应的阈值相比较,即可判断出受试者患有糖尿病的可能性。若概率值大于等于阈值,则预测受试者患有糖尿病的可能性较大。否则,预测受试者患有糖尿病的可能性较小。
39.根据本技术的另一方面,提供了标记物在制备用于预测受试者患有糖尿病的可能性的试剂、组合物或试剂盒中的应用。该预测包括如下步骤:
40.基于来自所述受试者的样品,确定所述标记物的浓度,其中,所述标记物包括α-hb、1,5-ag、adma、胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸、羟赖氨酸、l-天冬氨酸中的
至少一种;以及
41.基于所述标记物的浓度,使用与所述标记物相关的预测模型预测所述受试者患有糖尿病的可能性。
42.在一些实施例中,受试者可以是患有或不患有糖尿病的个体。在一些实施例中,受试者可以是孕妇。受试者的样品可以是血清样品、血浆样品、唾液样品、尿液样品等。在一些实施例中,样品可以是血清样品或血浆样品。
43.在一些实施例中,所述标记物包括上文描述的标记物。在一些实施例中,标记物可以包括α-hb、1,5-ag、adma、胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸、羟赖氨酸、l-天冬氨酸中的至少一种。在一些实施例中,所述标记物可以是α-hb。在一些实施例中,所述标记物可以包括1,5-ag和adma中的至少一个。所述标记物可以包括1,5-ag和adma中的全部。在一些实施例中,所述标记物可以包括胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸和羟赖氨酸中的至少一个。在一些实施例中,所述标记物可以包括胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸和羟赖氨酸中的全部。在一些实施例中,所述标记物可以包括α-hb、1,5-ag、胱氨酸、乙醇胺、牛磺酸、l-天冬氨酸中的至少一个。在一些实施例中,所述标记物可以包括α-hb、1,5-ag、胱氨酸、乙醇胺、牛磺酸、l-天冬氨酸中的全部。
44.在一些实施例中,标记物的浓度可以通过质谱法(例如,液相色谱-质谱法(liquid chromatography-mass spectrometry,lc-ms)、气相色谱-质谱法(gas chromatography-mass spectrometry,gc-ms)、基质辅助激光解吸/电离飞行时间质谱(matrix-assisted laser desorption/ionization time-of-flight mass spectrometry,maldi-tof ms)、免疫法、酶法等在样品中进行测定。在一些实施例中,标记物的浓度可以通过lc-ms确定。关于标记物的浓度确定方法可以参考实施例中“代谢物浓度测定”部分。
45.在一些实施例中,不同的预测模型的变量可以包括不同的标记物。每个预测模型可以与上述标记物中的至少一个标记物相关。在一些实施例中,预测模型可以包括多个预测模型,例如,实施例中的预测模型2-5。每个预测模型可以与上述标记物中的至少一个有关。在一些实施例中,预测模型2可以与α-hb有关。在一些实施例中,预测模型3可以与1,5-ag和adma有关。在一些实施例中,预测模型4可以与胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸和羟赖氨酸有关。在一些实施例中,预测模型5可以与α-hb、1,5-ag、胱氨酸、乙醇胺、牛磺酸、l-天冬氨酸有关。在一些实施例中,预测模型还可以包括其他变量,例如,常规变量(例如,受试者的年龄、bmi)。在一些实施例中,预测模型还可以包括预测模型1,其与受试者的年龄、bmi有关。在一些实施例中,预测模型还可以包括一个模型,该模型整合有上述多个预测模型。
46.在一些实施例中,预测模型(例如,预测模型2)可以由公式(1)表示:
47.在一些实施例中,预测模型(例如,预测模型3)可以由公式(2)表示:
48.在一些实施例中,预测模型(例如,预测模型4)可以由公式(3)表示:
49.在一些实施例中,预测模型(例如,预测模型5)可以由公式(4)表示:
50.在上述公式中,p值为受试者为糖尿病的概率值,为对数优势比,各个标记物的名称均表示各个标记物的浓度,单位为μmol/l。这里的单位μmol/l仅为示例,还可以是本领域人员所知悉的其他浓度单位,例如,mol/l、ug/ml、g/l等,本技术并不对此做出限制。应当注意的是,对于受试者为妊娠期女性,上述公式中的bmi为孕前bmi。
51.在一些实施例中,预测模型可以通过模型训练获得。可以用训练集来获得和训练初始模型,得到训练后模型。训练集可以包括样本标记物的浓度、受试者常规特征(例如,年龄、bmi)样本受试者是否患有糖尿病(例如,妊娠糖尿病)的分类数据。在一些实施例中,还可以使用验证集来测试训练后模型,并不断调整模型参数。在一些实施例中,还可以使用验证集来验证预测模型。
52.在一些实施例中,可以通过逻辑回归方法、基于支持向量机(svm)的方法、基于贝叶斯分类器的方法、基于k-最近邻(knn)的方法、决策树方法等或其任何组合来建立预测模型。在一些实施例中,预测模型可以是逻辑回归模型。
53.接收者操作特性(receiver operating characteristics,roc)曲线可以用于评估预测模型的性能。roc曲线可以说明预测模型的预测能力。roc曲线以敏感度(真阳性率)为纵坐标,特异度(真阴性率)为横坐标绘制的曲线。可以基于roc曲线确定曲线下面积(area under the curve,auc)。auc可以用来表示预测模型的准确性,auc值越高,预测模型预测的准确率越高。
54.在一些实施例中,预测模型的auc可以大于0.7。在一些实施例中,预测模型的auc可以大于0.75。在一些实施例中,预测模型的auc可以大于0.8。在一些实施例中,预测模型的auc可以大于0.85。在一些实施例中,预测模型的auc可以大于0.9。具体地,在一些实施例中,预测模型2的auc可以大于0.7。在一些实施例中,预测模型3的auc可以大于0.75。在一些实施例中,预测模型4的auc可以大于0.85。在一些实施例中,预测模型5的auc可以大于0.85。在一些实施例中,预测模型5的auc可以大于0.9。在一些实施例中,预测模型2-5的auc均大于0.7,均有一定的准确度,但预测模型2-5可以具有不同的auc值。例如,预测模型2-5的auc依次递增,即,预测模型5的准确率优于预测模型4的准确率优于预测模型3的准确率优于预测模型2的准确率。
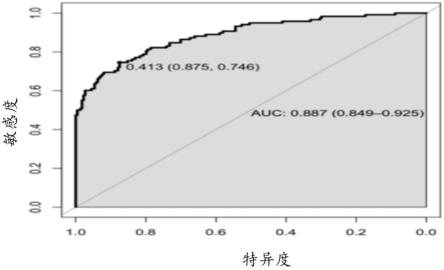
55.图5c-5j是根据本技术一些实施例所示的预测模型2-5分别在训练集和验证集中的roc。示例性的,预测模型2在验证集中的auc为0.734,预测模型3在验证集中的auc为0.773,预测模型4在验证集中的auc为0.852,预测模型5在验证集中的auc为0.887。
56.在一些实施例中,预测模型的敏感度可以大于65%。在一些实施例中,预测模型的
敏感度可以大于70%。在一些实施例中,预测模型的敏感度可以大于75%。在一些实施例中,预测模型的敏感度可以大于80%。在一些实施例中,预测模型的敏感度可以大于85%。在一些实施例中,预测模型的敏感度可以大于90%。具体地,在一些实施例中,预测模型2的敏感度可以大于65%。在一些实施例中,预测模型2的敏感度可以大于65%。在一些实施例中,预测模型3的敏感度可以大于70%。在一些实施例中,预测模型4的敏感度可以大于70%。在一些实施例中,预测模型5的敏感度可以大于70%。
57.在一些实施例中,预测模型的特异度可以大于65%。在一些实施例中,预测模型的特异度可以大于70%。在一些实施例中,预测模型的特异度可以大于75%。在一些实施例中,预测模型的特异度可以大于80%。在一些实施例中,预测模型的特异度可以大于85%。在一些实施例中,预测模型的特异度可以大于90%。具体地,在一些实施例中,预测模型2的特异度可以大于65%。在一些实施例中,预测模型3的特异度可以大于70%。在一些实施例中,预测模型4的特异度可以大于80%。在一些实施例中,预测模型5的特异度可以大于85%。
58.图5c-5j是根据本技术一些实施例所示的预测模型2-5分别在训练集和验证集中的roc。示例性的,预测模型2在验证集中的敏感度为68.6%,特异度为67.9%;预测模型3在验证集中的敏感度为72%,特异度为71.9%,预测模型4在验证集中的敏感度为73.7%,特异度为83%,预测模型5在验证集中的敏感度为74.6%,特异度为87.5%。
59.关于预测模型的更详细的内容可以参考实施例“预测模型的确定”部分。
60.在一些实施例中,基于所述标记物中的至少一个标记物的浓度,使用与所述标记物中的至少一个标记物相关的预测模型预测所述受试者患有糖尿病的可能性可以包括:将每个预测模型对应的标记物的浓度作为输入,输出预测值。通过比较预测值和阈值,可以预测所述受试者患有糖尿病的可能性。以预测模型5为例,将预测模型5相关的标志物的浓度(单位为μmol/l)输入到公式(4)中,预测模型5可以输出预测值(即,概率值p),并与预测模型5对应的阈值进行比较,从而预测所述受试者患有糖尿病的可能性。
61.在一些实施例中,预测模型的阈值可以是通过约登指数(youden's index)计算的阈值。例如,只考虑敏感度和特异度这2个指标分别对应的单个值,使用约登指数(youden'sindex)可以计算roc曲线上的阈值。在一些实施例中,预测模型2的阈值为0.336。在一些实施例中,预测模型3的阈值为0.336。在一些实施例中,预测模型4的阈值为0.363。在一些实施例中,预测模型5的阈值为0.413。
62.在一些实施例中,预测模型的阈值可以是选定阈值范围中的任一数值。在一些实施例中,阈值范围可以根据敏感度和特异度范围确定。例如,根据敏感度和特异度的范围,选择阈值范围。预测模型的阈值可以从阈值范围中确定。在一些实施例中,可以选择预测模型5的敏感度和特异度在[0.8,0.85]对应的阈值范围,例如,[0.288597,0.323644]。在一些实施例中,可以选择预测模型4的敏感度和特异度在[0.75,0.8]对应的阈值范围,例如,[0.274613,0.323241]。在一些实施例中,可以选择预测模型3的敏感度和特异度在[0.7,0.75]对应的阈值范围,例如,[0.317268,0.360159]。在一些实施例中,可以选择预测模型2的敏感度和特异度在[0.65,0.7]对应的阈值范围,例如,[0.309508,0.374544]。
[0063]
在一些实施例中,若所述预测值大于或等于所述阈值,预测所述受试者患有糖尿病的可能性较高。若所述预测值小于所述阈值,预测所述受试者患有糖尿病的可能性较低。
受试者患有糖尿病的可能性较高指的是受试者患有糖尿病的概率大于等于80%、85%、90%、95%、98%、100%。在一些实施例中,受试者患有糖尿病的可能性较高为受试者患有糖尿病。受试者患有糖尿病的可能性较低指的是受试者不患有糖尿病的概率大于等于80%、85%、90%、95%、98%、100%。在一些实施例中,受试者患有糖尿病的可能性较低为受试者不患有糖尿病。
[0064]
关于预测模型预测受试者患有糖尿病的可能性的更详细的内容可以参考实施例“预测模型的应用”部分。
[0065]
根据本技术的又一方面,提供了预测模型在制备用于预测受试者患有糖尿病的可能性的试剂、组合物或试剂盒中的应用。预测模型可以与所述标记物相关。在一些实施例中,所述标记物可以包括α-hb、1,5-ag、adma、胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸、羟赖氨酸、l-天冬氨酸中的至少一个。在一些实施例中,预测模型可以包括多个预测模型,例如,实施例中的预测模型2-5。每个预测模型可以与上述标记物中的至少一个有关(例如,作为预测模型的变量)。在一些实施例中,预测模型2可以与α-hb有关。在一些实施例中,预测模型3可以与1,5-ag和adma有关。在一些实施例中,预测模型4可以与胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸和羟赖氨酸有关。在一些实施例中,预测模型5可以与α-hb、1,5-ag、胱氨酸、乙醇胺、牛磺酸、l-天冬氨酸有关。在一些实施例中,预测模型还可以包括其他变量,例如,常规变量(例如,受试者的年龄、bmi)。在一些实施例中,预测模型还可以包括预测模型1,其与受试者的年龄、bmi有关。在一些实施例中,预测模型还可以包括一个模型,该模型整合有上述多个预测模型。在一些实施例中,预测模型2-5分别由上述公式(1)-(4)表示。应当注意的是,对于受试者为妊娠期女性,bmi则为孕前bmi。
[0066]
在一些实施例中,可以通过逻辑回归方法、基于支持向量机(svm)的方法、基于贝叶斯分类器的方法、基于k-最近邻(knn)的方法、决策树方法等或其任何组合来建立预测模型。在一些实施例中,预测模型可以是逻辑回归模型。
[0067]
在一些实施例中,预测模型的auc可以大于0.7。在一些实施例中,预测模型的auc可以大于0.75。在一些实施例中,预测模型的auc可以大于0.8。在一些实施例中,预测模型的auc可以大于0.85。在一些实施例中,预测模型的auc可以大于0.9。具体地,在一些实施例中,预测模型2的auc可以大于0.7。在一些实施例中,预测模型3的auc可以大于0.75。在一些实施例中,预测模型4的auc可以大于0.85。在一些实施例中,预测模型5的auc可以大于0.85。在一些实施例中,预测模型5的auc可以大于0.9。在一些实施例中,预测模型2-5的auc均大于0.7,均有一定的准确度,但预测模型2-5可以具有不同的auc值。例如,预测模型2-5的auc依次递增,即,预测模型5的准确率优于预测模型4的准确率优于预测模型3的准确率优于预测模型2的准确率。
[0068]
图5c-5j是根据本技术一些实施例所示的预测模型2-5分别在训练集和验证集中的roc。示例性的,预测模型2在验证集中的auc为0.734,预测模型3在验证集中的auc为0.773,预测模型4在验证集中的auc为0.852,预测模型5在验证集中的auc为0.887。
[0069]
在一些实施例中,预测模型的敏感度可以大于65%。在一些实施例中,预测模型的敏感度可以大于70%。在一些实施例中,预测模型的敏感度可以大于75%。在一些实施例中,预测模型的敏感度可以大于80%。在一些实施例中,预测模型的敏感度可以大于85%。
在一些实施例中,预测模型的敏感度可以大于90%。具体地,在一些实施例中,预测模型2的敏感度可以大于65%。在一些实施例中,预测模型2的敏感度可以大于65%。在一些实施例中,预测模型3的敏感度可以大于70%。在一些实施例中,预测模型4的敏感度可以大于70%。在一些实施例中,预测模型5的敏感度可以大于70%。
[0070]
在一些实施例中,预测模型的特异度可以大于65%。在一些实施例中,预测模型的特异度可以大于70%。在一些实施例中,预测模型的特异度可以大于75%。在一些实施例中,预测模型的特异度可以大于80%。在一些实施例中,预测模型的特异度可以大于85%。在一些实施例中,预测模型的特异度可以大于90%。具体地,在一些实施例中,预测模型2的特异度可以大于65%。在一些实施例中,预测模型3的特异度可以大于70%。在一些实施例中,预测模型4的特异度可以大于80%。在一些实施例中,预测模型5的特异度可以大于85%。
[0071]
图5c-5j是根据本技术一些实施例所示的预测模型2-5分别在训练集和验证集中的roc。示例性的,预测模型2在验证集中的敏感度为68.6%,特异度为67.9%;预测模型3在验证集中的敏感度为72%,特异度为71.9%,预测模型4在验证集中的敏感度为73.7%,特异度为83%,预测模型5在验证集中的敏感度为74.6%,特异度为87.5%。
[0072]
本技术中构建的预测模型均有较好的准确度,能够准确预测受试者是否为糖尿病。关于预测模型的更多内容可以参考本技术其他地方所述,在此不再赘述。
[0073]
根据本技术的再一方面,提供了一种用于治疗糖尿病的方法。所述方法可以包括:
[0074]
基于来自所述受试者的样品,确定所述标记物的浓度,其中,所述标记物包括α-hb、1,5-ag、adma、胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸、羟赖氨酸、l-天冬氨酸中的至少一个。在一些实施例中,所述标记物可以包括α-hb、1,5-ag、adma、胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸、羟赖氨酸、l-天冬氨酸中的至少一个。在一些实施例中,所述标记物可以是α-hb。在一些实施例中,所述标记物可以包括1,5-ag和adma中的至少一个。所述标记物可以包括1,5-ag和adma中的全部。在一些实施例中,所述标记物可以包括胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸和羟赖氨酸中的至少一个。在一些实施例中,所述标记物可以包括胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸和羟赖氨酸中的全部。在一些实施例中,所述标记物可以包括α-hb、1,5-ag、胱氨酸、乙醇胺、牛磺酸、l-天冬氨酸中的至少一个。在一些实施例中,所述标记物可以包括α-hb、1,5-ag、胱氨酸、乙醇胺、牛磺酸、l-天冬氨酸中的全部。
[0075]
在一些实施例中,标记物的浓度可以通过质谱法(例如,液相色谱-质谱法、气相色谱-质谱法、基质辅助激光解吸/电离飞行时间质谱)、免疫法、酶法等在样品中进行测定。在一些实施例中,标记物的浓度可以通过液相色谱串联质谱确定。
[0076]
基于所述标记物的浓度,使用与所述标记物相关的预测模型预测所述受试者患有糖尿病的可能性。
[0077]
在一些实施例中,可以使用上文描述的预测模型(例如,预测模型2-5)来预测受试者患有糖尿病的可能性。关于该步骤的更多内容可参考上文描述,在此不再赘述。
[0078]
若预测结果为所述受试者患有糖尿病(例如,预测模型输出的概率值大于等于对应的阈值),对于不同的受试者,可以采取不同的处理方式。
[0079]
在一些实施例中,若受试者为妊娠期女性,且预测结果为该受试者患有糖尿病,则
对该受试者采用ogtt进行进一步诊断,若ogtt结果也为该受试者患有糖尿病,则可以对该受试者施用治疗糖尿病的药物。通过本技术的预测模型,可以筛选掉无需做ogtt的非gdm的妊娠期女性,减少妊娠期女性在进行ogtt检查时的痛苦和不便。预测模型的预测结果能够为后续的诊断和治疗提供了可靠且准确的参考。
[0080]
在一些实施例中,若受试者为非妊娠期女性,且预测结果为该受试者患有糖尿病,则可以对该受试者施用治疗糖尿病的药物。在一些实施例中,若受试者为妊娠期女性,可以对该受试者进行后续诊断(例如,ogtt)来进一步确诊,再对受试者施用治疗糖尿病的药物。
[0081]
在一些实施例中,治疗糖尿病的药物可以包括胰岛素、磺脲类胰岛素促分泌剂、非磺脲类胰岛素促分泌剂、双胍类药物、α-葡萄糖苷酶抑制剂(例如,阿卡波糖(拜糖平))、噻唑烷二酮类(例如,吡格列酮、马来酸罗格列酮)等。磺脲类胰岛素促分泌剂可以包括格列苯脲(优降糖)、格列吡嗪(美吡哒)、格列齐特(达美康)、格列喹酮(糖适平)、格列美脲等。非磺脲类胰岛素促分泌剂可以包括瑞格列奈(诺和龙、孚来迪)、那格列奈(唐力)等。双胍类药物可以包括二甲双胍缓释片、迪化糖锭、格化止等。
[0082]
根据本技术的再一方面,提供了一种用于预测受试者患有糖尿病的可能性的系统。该系统可以包括:获取模块、训练模块和预测模块。
[0083]
该获取模块可用于获取受试者样品的标记物的浓度。所述标记物可以包括α-hb、1,5-ag、adma、胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸、羟赖氨酸、l-天冬氨酸中的至少一种。在一些实施例中,所述标记物可以是α-hb。在一些实施例中,所述标记物可以包括1,5-ag和adma中的至少一个。所述标记物可以包括1,5-ag和adma中的全部。在一些实施例中,所述标记物可以包括胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸和羟赖氨酸中的至少一个。在一些实施例中,所述标记物可以包括胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸和羟赖氨酸中的全部。在一些实施例中,所述标记物可以包括α-hb、1,5-ag、胱氨酸、乙醇胺、牛磺酸、l-天冬氨酸中的至少一个。在一些实施例中,所述标记物可以包括α-hb、1,5-ag、胱氨酸、乙醇胺、牛磺酸、l-天冬氨酸中的全部。该获取模块还可用于获取受试者的常规特征,例如,年龄、bmi、身高、体重等。
[0084]
该训练模块可以用于利用训练集训练初始模型获得预测模型。在一些实施例中,训练模块可以用于利用训练集训练初始模型获得多个预测模型,例如,预测模型2-5。所述预测模型与所述标记物中的至少一个标记物相关,例如,预测模型2-5与不同的标记物有关。所述预测模型还可以与受试者的年龄与bmi相关。在一些实施例中,预测模型2可以与α-hb有关。在一些实施例中,预测模型3可以与1,5-ag和adma有关。在一些实施例中,预测模型4可以与胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸和羟赖氨酸有关。在一些实施例中,预测模型5可以与α-hb、1,5-ag、胱氨酸、乙醇胺、牛磺酸、l-天冬氨酸有关。关于预测模型的更多内容可以参考本技术其他地方的描述,在此不再赘述。
[0085]
该预测模块可以用于基于所述标记物中的至少一个标记物的浓度,使用预测模型预测所述受试者患有糖尿病的可能性。例如,将与预测模型对应的标记物的浓度输入到预测模型中,预测模型可以输出预测值。将预测值与预测模型的阈值相比较,当预测值大于等于阈值时,预测模块可以预测受试者患有糖尿病的可能性较高;当预测值小于阈值时,预测模块可以预测受试者患有糖尿病的可能性较低。
[0086]
应当理解,该用于预测受试者患有糖尿病的可能性的系统及其模块可以利用各种
方式来实现。例如,在一些实施例中,系统及其模块可以通过硬件、软件或者软件和硬件的结合来实现。其中,硬件部分可以利用专用逻辑来实现;软件部分则可以存储在存储器中,由适当的指令执行系统,例如微处理器或者专用设计硬件来执行。本领域技术人员可以理解上述的方法和系统可以使用计算机可执行指令和/或包含在处理器控制代码中来实现,例如在诸如磁盘、cd或dvd-rom的载体介质、诸如只读存储器(固件)的可编程的存储器或者诸如光学或电子信号载体的数据载体上提供了这样的代码。本技术的系统及其模块不仅可以有诸如超大规模集成电路或门阵列、诸如逻辑芯片、晶体管等的半导体、或者诸如现场可编程门阵列、可编程逻辑设备等的可编程硬件设备的硬件电路实现,也可以用例如由各种类型的处理器所执行的软件实现,还可以由上述硬件电路和软件的结合(例如,固件)来实现。实施例gdm组和非gdm组的临床变量的显著性检验
[0087]
本研究将369名受试者(例如,孕妇)进行使用75g的ogtt,并将测试结果分成两组,gdm组和非gdm组。并对两组中的受试者检测下表1中显示的临床变量,并进行显著性统计检验,以发现在两组中明显有区别的变量。年龄、收缩压和舒张压使用的显著性统计检验方法为学生t检验(student's t-test),其它临床变量使用的显著性统计检验方法为曼-惠特尼u检验(mann-whitney u test)。p值小于0.05为显著。表1 gdm组与非gdm组的临床特征
其中,上述数据为平均值(标准差)或中值(四分位数范围);p值为诊断为gdm和非gdm的患者之间的差异;*表示分析前对数变换。
[0088]
从上表1中的结果可知,相比于非gdm组,gdm组中受试者的年龄、孕前bmi(p《0.001)显著较大,血压、甘油三酯、糖化血红蛋白、胰岛素抵抗的指标(p《0.02)均显著升高,高密度脂蛋白胆固醇和胰岛细胞功能指标(均p《0.01)显著降低,总胆固醇、低密度脂蛋白胆固醇和空腹胰岛素则无显著差异(p》0.05)。代谢物浓度测定
[0089]
通过lc-ms测量与上述确定的具有显著差异的变量(除年龄与孕前bmi的其他临床变量)相关的代谢物浓度,以进行显著性差异分析。
[0090]
具体地,获取369名受试者的血浆样本并使之通过蛋白沉淀后,振荡、离心取上清衍生后进样,先利用超高效液相色谱将待测代谢物进行分离,再利用质谱同位素内标定量法,以标准品与内标物的浓度比为x轴,标准品与内标物的峰面积比为y轴,建立校准曲线,从而能够计算相关代谢物的含量。但不同的代谢物高效液相色谱条件和质谱条件不同,具
体条件如下。
[0091]
一、25种氨基酸及其衍生物检测
[0092]
(1)高效液相色谱条件:
[0093]
流动相a:水(含0.1%甲酸);
[0094]
流动相b:乙腈(含0.1%甲酸);
[0095]
色谱柱:acquity uplc beh c18(2.1
×
100mm,1.7μm);
[0096]
采用梯度洗脱的方式,见表2;
[0097]
流速为0.4ml/min,柱温为50℃,进样体积为1μl;表2流动相梯度洗脱参数
[0098]
(2)质谱条件:
[0099]
在电喷雾电离正离子检测模式下,采用多反应监测的质谱扫描模式;喷雾电压为3.0kv;去溶剂温度为120℃;雾化气温度为400℃,雾化气流速为800l/h,锥孔气流速为150l/h;同时监测了待测代谢物及其内标;各个待测代谢物的去簇电压和碰撞电压参数见表3。表3氨基酸及其衍生物质谱参数
[0100]
图1a和图1b分别示出了25种氨基酸及其衍生物的标准品和血浆样品中25种氨基酸及其衍生物的总离子流色谱图。如图中所示,25种氨基酸及其衍生物的标准品和血浆样品的峰形比较对称,且没有杂峰干扰,说明在此条件下能够得到良好的检测。
[0101]
采用同位素内标定量法,利用targetlynx软件以标准物与内标物的浓度比为x轴,标准物与内标物峰面积比为y轴,建立校准曲线,25种氨基酸及其衍生物在各自浓度范围内的线性方程的线性良好,相关系数在0.99以上,满足定量要求,具体见表4。根据标准曲线的线性方程,计算出血浆中待测代谢物的浓度。表4 25种氨基酸及其衍生物线性回归方程及线性相关系数
[0102]
二、1,5-ag、tmao、adma和sdma检测
[0103]
(1)高效液相色谱条件:
[0104]
流动相a:水(含0.1%甲酸);
[0105]
流动相b:乙腈(含0.1%甲酸);
[0106]
色谱柱:acquity uplc beh amide(2.1
×
100mm,1.7μm);
[0107]
采用梯度洗脱的方式,见表5;
[0108]
流速为0.4ml/min,柱温为50℃,进样体积为1μl;表5流动相梯度洗脱参数
[0109]
(2)质谱条件:
[0110]
采用电喷雾电离正负离子切换多反应监测的质谱扫描模式;喷雾电压为esi( )3.0kv/esi(-)2.5kv;去溶剂温度为120℃;雾化气温度为400℃,雾化气流速为800l/h,锥孔气流速为150l/h;同时监测了待测代谢物及其内标;各个待测代谢物的去簇电压和碰撞电压参数见表6。表6待测代谢物质谱参数表6待测代谢物质谱参数
[0111]
图2a和图2b分别为1,5-ag、tmao、adma和sdma的标准品总离子流色谱图和血浆样本中1,5-ag、tmao、adma和sdma的总离子流色谱图。如图所示,1,5-ag、tmao、adma和sdma的标准品和血浆样品的峰形比较对称,且没有杂峰干扰,说明在此条件下能够得到良好的检测。
[0112]
采用同位素内标定量法,利用targetlynx软件以标准物与内标物的浓度比为x轴,
标准物与内标物峰面积比为y轴,建立校准曲线,1,5-ag、tmao、adma和sdma在各自浓度范围内的线性拟合方程,线性良好,相关系数在0.99以上,满足定量要求,见表7。根据标准曲线的线性方法,计算出血浆中待测物的浓度。表7 1,5-ag、tmao、adma和sdma线性回归方程及线性相关系数
[0113]
三、α-hb、oa和lgpc检测
[0114]
(1)高效液相色谱条件:
[0115]
流动相a:水(含0.1%甲酸);
[0116]
流动相b:乙腈(含0.1%甲酸);
[0117]
色谱柱:acquity uplc beh c18(2.1
×
50mm,1.7μm);
[0118]
采用梯度洗脱的方式,见表8;
[0119]
流速为0.5ml/min,柱温为50℃,进样体积为1μl;表8流动相梯度洗脱参数
[0120]
(2)质谱条件:
[0121]
采用电喷雾电离正负离子切换多反应监测的质谱扫描模式;喷雾电压为esi( )3.0kv/esi(-)2.5kv;去溶剂温度为120℃;雾化气温度为400℃,雾化气流速为800l/h,锥孔气流速为150l/h;同时监测了目标物及其内标;各个目标物的去簇电压和碰撞电压参数见表9。表9目标物质谱参数
[0122]
图3a和图3b示出了α-hb、oa和lgpc的标准品总离子流色谱图和血浆中α-hb、oa和lgpc的总离子流色谱图。如图所示,α-hb、oa和lgpc的标准品和血浆样品的峰形比较对称,且没有杂峰干扰,说明在此条件下能够得到良好的检测。
[0123]
采用同位素内标定量法,利用targetlynx软件以标准物与内标物的浓度比为x轴,标准物与内标物峰面积比为y轴,建立校准曲线,α-hb、oa和lgpc在各自浓度范围内的线性拟合方程,线性良好,相关系数在0.99以上,满足定量要求,见表10。根据标准曲线的线性方程,计算出血浆中待测代谢物物的浓度。表10 α-hb、oa和lgpc线性回归方程及线性相关系数gdm组和非gdm组的代谢物的显著性检验
[0124]
通过上述标准曲线可以确定出各个代谢物的浓度,之后进行显著性统计分析,以确定显著差异的代谢物。在gdm组和非gdm组中显著性统计检验方法为曼-惠特尼u检验(mann-whitney u test),p值小于0.05为显著。具体代谢物及其路径以及p值结果如下表11所示。表11 gdm组和非gdm组受试者的代谢物水平
[0125]
根据表11可知,相比于非gdm组,gdm组的胱氨酸、羟赖氨酸、α-hb和油酸水平显著升高(其p《0.001);而1,5-ag、乙醇胺、l-苯丙氨酸、l-色氨酸、l-异亮氨酸、l-亮氨酸、l-天冬氨酸、l-丙氨酸、l-苏氨酸、赖氨酸、蛋氨酸、牛磺酸、非对称性二甲基精氨酸、对称二甲基精氨酸和谷氨酸均显著降低(所有p《0.01)。预测模型的确定模型获取概述
[0126]
本实施例采用的预测模型为逻辑回归模型,适用于二分类问题。使用该模型可以用于预测受试者是否为gdm。
[0127]
逻辑回归模型是广义线性模型,假设因变量y服从二项分布,线性模型的拟合形式如下公式(5)所示:其中,p值为受试者为gdm概率值,为对数优势比,β0为截距,xi为纳入的各种变量(例如,各种标记物、年龄、孕前bmi等),βi为斜率。
[0128]
将369名受试者的代谢物浓度数据以及年龄、孕前bmi、分类信息(即,受试者是否为gdm)等作为样本数据集。使用10次重复*10折交叉验证方法将上述样本数据集分为训练集、验证集。训练集和验证集用于估计公式(5)中β0和βi参数。具体地,首先根据训练集,即提供变量数据xi和样本分类信息,结合最大似然估计方法评估最优β0和βi参数。确定β0和βi,即得到训练后的模型(即,预测模型)。根据验证集中的数据和训练后的模型,可对验证集中的受试者进行预测,并将预测结果和真实分类信息进行比较。最后,根据训练集和验证集的计算结果,绘制roc曲线,并计算roc曲线的auc值(area under the curve of roc)以及模型中各变量的优势比(odds ratio)和显著性p值。logistic regression模型中变量的显著性检验方法使用wald test,统计显著标准p《0.05。
各个预测模型中变量的显著性检验
[0129]
具体地,年龄和孕前bmi是已知与gdm发生显著相关的危险因子(在表1中p《0.001),需要纳入所有多变量模型中作为校正因子。将变量只有年龄和孕前bmi的预测模型记为预测模型1,作为对照。其它代谢物根据其属性归类(见表11)依次纳入模型中,根据上述步骤的描述依次分析每个多变量模型的roc曲线、auc值和多变量模型中各变量的优势比和显著性p值。
[0130]
根据上述数据结果,基于筛选原则筛选出合适的多变量模型。筛选原则是模型对应的auc值最高,并且模型中各变量的优势比是统计显著(统计显著标准p《0.05)。最终筛选得到符合筛选原则的多变量模型分别命名为:预测模型2、预测模型3、预测模型4、预测模型5。这5个预测模型各变量的优势比见下表12。表12 5个模型中纳入的变量和各变量的p值和优势比
[0131]
其中,p值*表示显著,p值**表示很显著,p值***非常显著,ci表示置信区间。
[0132]
根据表12可知,筛选出的这5个模型的各变量的优势比均显著,均符合筛选原则。其中,年龄和孕前bmi(均p《0.01)在所有5个预测模型中均显著。预测模型2的变量包括常规风险因素(即,年龄和孕前bmi)和α-hb(p《0.001)。预测模型3的变量包括常规风险因素、1,5-ag和adma(均p《0.001)。预测模型4包括常规风险因素和氨基酸,包括胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸和羟赖氨酸(所有p《0.05)。预测模型5包括常规风险因素、α-hb、1,5-ag、胱氨酸、乙醇胺、牛磺酸和l-天冬氨酸(所有p《0.05)。使用多变量调整模型,α-hb、1,5-ag、adma、胱氨酸、乙醇胺、牛磺酸、亮氨酸、色氨酸、l-天冬氨酸和羟赖氨酸的水平与gdm发生显著相关。
[0133]
图4a到图4l是5个预测模型的全部变量与gdm显著关系的分布图。5个预测模型所涉及到的12个变量在gdm和非gdm组的数据分布见图4a到图4l,从图中可知,这些变量均与gdm显著相关。预测模型参数的确定
[0134]
根据公式(5),分别输入不同模型的变量xi。预测模型1的变量为年龄和孕前bmi,预测模型2的变量为年龄、孕前bmi和α-hb,预测模型3的变量为年龄、孕前bmi、1,5-ag、adma,预测模型4的变量为年龄、孕前bmi、胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸和羟赖氨酸,预测模型5的变量为年龄、孕前bmi、α-hb、1,5-ag、胱氨酸、乙醇胺、牛磺酸和l-天冬氨酸。
[0135]
根据上述变量以及训练集中受试者的真实分组数据,结合最大似然估计方法评估5个模型中的各个β0和βi参数的最优值,即可得到训练后的各个模型(即,预测模型)。5个预测模型如下表13所示。表13 5个预测模型的公式5个预测模型的公式
计算各个预测模型的敏感度(sensitivity)和特异度(specificity)和阳性预测值(ppv)和阴性预测值(npv)
[0136]
将369个样本数据分别代入上表13中的各个预测模型的公式中,以计算各个预测模型的敏感度(sensitivity)和特异度(specificity)和阳性预测值(positive predictive value,ppv)和阴性预测值(negative predictive value,npv)。以预测模型1为例,进行说明。根据每个样本的年龄和孕前bmi和预测模型1公式,可以计算每个样本属于gdm的概率值p。概率值取值范围在[0,1]之间,对[0,1]之间数值划分201个分位数(第0个分位数是0.0th,第1个分位数是0.5th,第2个分位数1.0th,第3分位数1.5th,第4个分位数2.0th,...,第200个分位数100th),每个分位数对应一个值叫阈值(threshold)。对于第一个样本p值,如果p值大于等于该0个分位数对应的阈值,预测诊断该样本为gdm,小于该阈值,预测诊断该样本为非gdm。同样的,随后对第二个样本到第369个样本,分别比较各样本p值和0个分位数对应的阈值的大小关系,预测每个样本是否为gdm。将预测诊断的gdm和非gdm的样本与真实分组类别进行比较,计算敏感度和特异度和阳性预测值和阴性预测值。按照第0个分位数对应的阈值预测样本是否为gdm的过程,分别计算第1个和第200个分位数对应阈值条件下,预测369个样本是否为gdm,随后计算各阈值的敏感度、特异度、阳性预测值和阴性预测值。剩余的模型依次按照上述过程计算敏感度和特异度和阳性预测值和阴性预测值。
[0137]
表14是5个预测模型的各阈值和对应的敏感度、特异度、ppv、npv的比较结果。如下表14所示,在敏感度和特异度均大于等于85%的条件下,5个预测模型未筛选到相关阈值,都未达到该标准(即,敏感度和特异度均大于等于85%)。但是敏感度或特异度达到85%,5个模型可筛选到相关阈值(数据未示出)。
[0138]
敏感度和特异度均在[0.8,0.85]之间条件下,预测模型5筛选到的阈值范围为[0.288597,0.323644],即在此阈值范围内任意选一个值,均可保证模型的敏感度和特异度在[0.8,0.85]之间。
[0139]
敏感度和特异度均在[0.75,0.8]之间条件下,预测模型4和预测模型5筛选到相关阈值,并且预测模型5阈值范围更宽,表示预测模型5较预测模型4更稳定。敏感度、特异度、ppv和npv均在[0.75,0.8]之间的条件下,只有预测模型5筛选到相关阈值。
[0140]
在敏感度和特异度均在[0.70,0.75]之间,预测模型3、预测模型4和预测模型5筛选到相关阈值范围,阈值范围宽度为预测模型3《预测模型4《预测模型5。敏感度、特异度、ppv和npv均在[0.70,0.75]之间的条件下,预测模型4和预测模型5筛选到相关阈值范围,预测模型3未筛选到。
[0141]
在敏感度和特异度均在[0.65,0.7]之间的条件下,5个模型均筛选到相关阈值,阈值范围宽度是预测模型1《预测模型2《预测模型3《预测模型4《预测模型5;在敏感度、特异度、ppv和npv均在[0.65,0.7]之间的条件下,模型4和模型5筛选到相关阈值。
[0142]
在敏感度和特异度均在[0.60,0.65]之间的条件下,5个预测模型均筛选到相关阈值,阈值范围宽度依然是预测模型1《预测模型2《预测模型3《预测模型4《预测模型5;在敏感度、特异度、ppv和npv均在[0.60,0.65]之间的条件下,预测模型3、预测模型4和预测模型5筛选到相关阈值,阈值范围宽度是预测模型3《预测模型4《预测模型5。表14 5个预测模型的阈值范围比较
[0143]
阈值、敏感度和特异度的3者关系是阈值越大,特异度越高,敏感度越低;阈值越小,敏感度越高,特异度越低。可以根据敏感度和特异度来选择阈值范围。例如,预测模型5的敏感度和特异度在[0.8,0.85],选择预测模型5在[0.8,0.85]的阈值范围[0.288597,0.323644]。模型4的敏感度和特异度在[0.75,0.8],选择预测模型4在[0.75,0.8]的阈值范围[0.274613,0.323241]。预测模型3的敏感度和特异度在[0.7,0.75],选择预测模型3在[0.7,0.75]的阈值范围[0.317268,0.360159]。预测模型2的敏感度和特异度在[0.65,0.7],选择预测模型2在[0.65,0.7]的阈值范围[0.309508,0.374544]。预测模型1的敏感度和特异度在[0.65,0.7],选择预测模型1在[0.65,0.7]的阈值范围[0.329666,0.332614]。各个预测模型的阈值可以根据需要来选择阈值范围内的任一数值。各个预测模型的性能评估
[0144]
根据上述步骤确定的各个预测模型的敏感度和特异度,绘制roc曲线。图5a到图5j是5个预测模型的roc曲线图。
[0145]
根据图5a到图5j,5个预测模型性能评估数据见表15。预测模型1的验证集auc为0.683(0.624-0.743)。预测模型2在预测模型1变量基础上再加入α-hb,验证集auc为0.734(0.679-0.789)。预测模型3在预测模型1变量基础上再加入1,5-ag和adma,验证集auc为0.773。预测模型4在预测模型1变量基础上再加入胱氨酸、乙醇胺、牛磺酸、l-亮氨酸、l-色氨酸和羟赖氨酸,验证集auc为0.852(0.808-0.898)。特别的,预测模型5在预测模型1变量基础上再加入α-hb、1,5-ag、胱氨酸、乙醇胺、牛磺酸和l-天冬氨酸后,验证集auc为0.887(0.849-0.926)。验证集的auc值越高,表示预测模型的预测准确率最好。5个模型的auc值由高到低排序依次预测模型5、预测模型4、预测模型3、预测模型2和预测模型1。预测模型2-5均可以用于预测受试者是否患有糖尿病。表15 5个预测模型的训练集auc值和验证集auc值
[0146]
根据图5a到图5j,只考虑敏感度和特异度这2个指标分别对应的单个值,使用约登指数可以确定各个预测模型的阈值,及其对应的敏感度、特异度、阳性预测值和阴性预测值。表16列出5个预测模型的阈值及其对应的敏感度、特异度、阳性预测值和阴性预测值的结果。表16.5个预测模型在验证集中的敏感度、特异度、阳性预测值和阴性预测值结果模型敏感度(%)特异度(%)ppv(%)npv(%)阈值预测模型156.875.054.576.70.370预测模型268.667.952.980.40.336预测模型372.071.957.483.00.336预测模型473.783.069.685.70.363预测模型574.687.575.986.70.413
[0147]
可以看出预测模型5约登指数计算的阈值对应的4个指标结果最好,其对应的特异度为87.5%,敏感度为74.6%,阳性预测值为75.9%,阴性预测值为86.7%,阈值为0.413。预测模型的应用
[0148]
对于gdm分类未知的受试者,使用确定的这5个预测模型预测该受试者是否为gdm。
[0149]
首先,对新的受试者进行采血取样,之后检测5个预测模型所对应的变量的代谢分子的浓度值(例如,单位为μmol/l),并获取受试者的年龄和孕前bmi值。将这些变量输入到对应的各个预测模型中,各个预测模型可以输出概率值p。将概率值p与各个预测模型对应的阈值(约登指数确定的阈值或从阈值范围内选定)进行比较,若概率值大于等于阈值,则预测受试者患有糖尿病,即为gdm;若概率值小于阈值,则预测受试者不患有糖尿病,即为非gdm。将5个预测模型结果进行比较,查看结果是否一致。其中,预测模型5的准确度最高。
[0150]
预测模型的预测结果能够为医生对受试者的后续诊断/治疗提供准确参考。例如,若预测模型的预测结果为孕妇患有gdm,则可以对孕妇进行进一步的ogtt检测。之后,医生可以将检测结果与孕妇临床信息结合分析,可对孕妇今后生活方式给予进一步指导或提供药物治疗。
[0151]
上文已对基本概念做了描述,显然,对于本领域技术人员来说,上述详细披露仅仅作为示例,而并不构成对本说明书的限定。虽然此处并没有明确说明,本领域技术人员可能会对本说明书进行各种修改、改进和修正。该类修改、改进和修正在本说明书中被建议,所以该类修改、改进、修正仍属于本说明书示范实施例的精神和范围。
[0152]
同时,本说明书使用了特定词语来描述本说明书的实施例。如“一个实施例”、“一实施例”、和/或“一些实施例”意指与本说明书至少一个实施例相关的某一特征、结构或特点。因此,应强调并注意的是,本说明书中在不同位置两次或多次提及的“一实施例”或“一个实施例”或“一个替代性实施例”并不一定是指同一实施例。此外,本说明书的一个或多个实施例中的某些特征、结构或特点可以进行适当的组合。
[0153]
一些实施例中使用了描述成分、属性数量的数字,应当理解的是,此类用于实施例描述的数字,在一些示例中使用了修饰词“大约”、“近似”或“大体上”来修饰。除非另外说明,“大约”、“近似”或“大体上”表明所述数字允许有
±
20%的变化。相应地,在一些实施例中,说明书和权利要求中使用的数值参数均为近似值,该近似值根据个别实施例所需特点可以发生改变。在一些实施例中,数值参数应考虑规定的有效数位并采用一般位数保留的方法。尽管本说明书一些实施例中用于确认其范围广度的数值域和参数为近似值,在具体实施例中,此类数值的设定在可行范围内尽可能精确。
[0154]
针对本说明书引用的每个专利、专利申请、专利申请公开物和其他材料,如文章、书籍、说明书、出版物、文档等,特此将其全部内容并入本说明书作为参考。与本说明书内容不一致或产生冲突的申请历史文件除外,对本说明书权利要求最广范围有限制的文件(当前或之后附加于本说明书中的)也除外。需要说明的是,如果本说明书附属材料中的描述、定义、和/或术语的使用与本说明书所述内容有不一致或冲突的地方,以本说明书的描述、定义和/或术语的使用为准。
[0155]
最后,应当理解的是,本说明书中所述实施例仅用以说明本说明书实施例的原则。其他的变形也可能属于本说明书的范围。因此,作为示例而非限制,本说明书实施例的替代配置可视为与本说明书的教导一致。相应地,本说明书的实施例不仅限于本说明书明确介绍和描述的实施例。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。