技术特征:
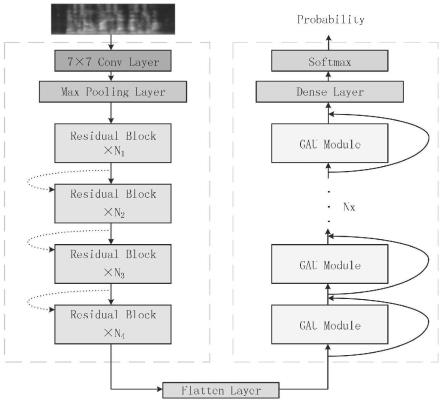
1.基于resnet-gau模型的pcvcs端到端语音识别方法,其特征在于,包括以下步骤:采用resnet提取待识别的语音信号的时频域特征;通过多个串联的gau module,捕捉时频域特征的词序信息;将词序信息传入dense layer,在特征空间上进行线性变化后通过softmax层获得最终的语音分类预测概率。2.根据权利要求1所述的基于resnet-gau模型的pcvcs端到端语音识别方法,其特征在于,所述采用resnet提取待识别的语音信号的时频域特征,包括以下步骤:输入待识别语音,经过7
×
7conv layer,卷积核在工作时,会有规律地扫过输入特征,在感受野内对输入特征做矩阵元素乘法求和并叠加偏差量;输出的特征图被传递至max pooling layer进行特征选择和信息过滤;pooling layer包含预设定的池化函数,将特征图中单个点的结果替换为其相邻区域的特征图统计量;将最大池化后的特征向量依次经过由不同数量的residual block组成的堆,得到高度提纯的特征,其中block内部,堆与堆均引入shortcut connections,将输入跨层传递并与卷积的结果相加,缓解在cnn中增加深度带来的梯度消失问题;通过flatten layer将resnet最终输出的特征进行降维处理,作为多个串联的gau module的输入。3.根据权利要求2所述的基于resnet-gau模型的pcvcs端到端语音识别方法,其特征在于,还包括:对输入添加绝对位置编码,保证在时间维度上的一致性;将gau module与gau module之间同样进行residual connections。4.根据权利要求3所述的基于resnet-gau模型的pcvcs端到端语音识别方法,其特征在于,所述捕捉时频域特征的词序信息,包括以下步骤:输入的时频域特征经过layer norm,再分别经过dense layer与非线性变换得到门控矩阵u与计算注意力的value,query和key;u=φ
u
(xw
u
) v=φ
v
(xw
v
)∈r
t
×
e
q&k=φ
q&k
(xw
q&k
)∈r
t
×
s
其中,x∈r
t
×
d
,t表示序列长度,d表示model size;w
u
,wv∈r
d
×
e
,e表示expanded intermediate size;w
q&k
∈r
d
×
s
,s表示head size;表示激活函数;计算attention score采用relu2激活函数并加入relative position bias:a=relu2(qk
t
b)∈r
t
×
t
o=(u
⊙
av)w
o
∈r
t
×
d
其中,a是attention矩阵,负责融合token之间的信息;
⊙
表示element-wise multiplication;通过dropout layer防止模型训练过程出现过拟合现象。5.根据权利要求1所述的基于resnet-gau模型的pcvcs端到端语音识别方法,其特征在于,还包括,对resnet以及多个串联的gau module构成的语音识别模型进行训练,包括以下步骤:对源领域语音数据库中的语音数据采用特征增强技术,获得增强后的源领域语音数据库;
引入迁移学习,将在增强后的源领域语音数据库中训练后的语音识别模型,在目标领域空中交通管制语音数据库中进行微调,获得训练好的语音识别模型。6.根据权利要求5所述的基于resnet-gau模型的pcvcs端到端语音识别方法,其特征在于,所述语音识别模型在大规模的源领域aishell corpus上训练模型,然后在小规模的目标领域atc corpus上继续微调训练模型。7.根据权利要求6所述的基于resnet-gau模型的pcvcs端到端语音识别方法,其特征在于,所述对源领域语音数据库中的语音数据采用特征增强技术,包括以下步骤:采用specaugment中的时频掩蔽技术,设定时间、频域轴方向连续掩码的最大范围是250ms、100hz,在源领域aishell corpus的[0,250]、[0,100]范围内进行均匀采样一个t(f),在[0,τ-t]、[0,τ-f]范围内随机确定一个点t0(f0),从t0(f0)位置开始沿着时间、频域轴方向连续进行t(f)次掩码,其中,τ表示时间维度,v表示频域维度;在源领域aishell corpus中添加一定信噪比的高斯白噪声;在源领域aishell corpus中进行语速增强操作。8.根据权利要求1所述的基于resnet-gau模型的pcvcs端到端语音识别方法,其特征在于,还包括根据时序分类算法将不等长的输入和输出的序列自动对齐,通过引入特殊字符blank使语音序列每帧能一一对应的预测其在输出标签序列上的条件概率分布。9.根据权利要求1所述的基于resnet-gau模型的pcvcs端到端语音识别方法,其特征在于,还包括:用语音增强技术从待识别的电磁干扰噪声背景中提取有用的语音信号作为待识别的语音信号。
技术总结
本发明提供基于ResNet-GAU模型的PCVCs端到端语音识别方法,属于语音识别技术领域,包括:采用ResNet提取待识别的语音信号的时频域特征;通过多个串联的GAUmodule,捕捉时频域特征的词序信息;将词序信息传入Denselayer,在特征空间上进行线性变化后通过softmax层获得最终的分类预测概率。其中,本发明中的ResNet利用CNN的平移不变性和局部相关性提取语音信号的时频域信息;GAU利用门控的单头注意力机制不仅能更好地捕获序列长距离依赖关系来获得更大的感受野和上下文信息,同时也拥有更快的训练收敛速度;CTC利用引入blank和产生重复token解决了语音信号和文本标签硬对齐的问题。题。题。
技术研发人员:梁海军 孔建国 潘卫军 韩琪聪 张时雨
受保护的技术使用者:中国民用航空飞行学院
技术研发日:2022.06.01
技术公布日:2022/9/6
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。