1.本发明涉及人工智能技术领域,尤其是涉及一种核保方法、电子设备和计算机可读存储介质。
背景技术:
2.目前,核保需要业务人员与核保目标进行函件沟通处理,在获得核保目标许可或者同意的前提下,基于核保目标所提供的健康评定材料,业务人员按照手册和经验对健康评定材料中存在的异常健康信息进行确认,从而做最终核保决定。然而,由于业务人员不一定是医学专业人士,因此相关技术中仅靠人工处理核保任务,难以从健康评定材料中精准确定核保所需要参照的医学信息。因此,业内亟需一种核保方法,能够准确判断核保目标健康评定材料中所反映的健康状况。
技术实现要素:
3.本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明提出一种核保方法、电子设备和计算机可读存储介质,能够准确判断核保目标健康评定材料中所反映的健康状况。
4.根据本发明的第一方面实施例的核保方法,包括:
5.获取健康评定材料,所述健康评定材料为反映核保目标健康状况的文本材料;
6.对所述健康评定材料进行文本内容提取,得到健康评定字段;
7.基于自然语言识别模型从所述健康评定字段中提取所述核保目标的异常健康信息;
8.从预设核保数据库中筛选出与所述异常健康信息对应的核保结论。
9.可选的,根据本发明的一些实施例,所述基于自然语言识别模型从所述健康评定字段中提取所述核保目标的异常健康信息,包括:
10.基于所述自然语言识别模型对所述健康评定字段进行疾病名称识别,得到所述核保目标所患疾病的患病名称;
11.根据所述患病名称,从所述预设核保数据库中查询得到与所述患病名称对应的预设疾病特征;
12.根据与所述患病名称对应的所述预设疾病特征,通过所述自然语言识别模型从所述健康评定字段中提取所述异常健康信息。
13.可选的,根据本发明的一些实施例,所述根据与所述患病名称对应的所述预设疾病特征,通过所述自然语言识别模型从所述健康评定字段中提取所述异常健康信息,包括:
14.以所述预设疾病特征为基准,通过所述自然语言识别模型在所述健康评定字段中进行语义比对;
15.根据所述语义比对,获取所述异常健康信息中的患病症状,所述患病症状与所述预设疾病特征的语义相匹配;
16.基于所述患病症状在所述健康评定字段中的位置,通过所述自然语言识别模型进行上下文比对;
17.根据所述上下文比对,获取所述异常健康信息中与所述患病症状对应的病症参数。
18.可选的,根据本发明的一些实施例,所述从预设核保数据库中筛选出与所述异常健康信息对应的核保结论,包括:
19.根据所述异常健康信息,获取所述患病名称、所述患病症状与所述病症参数之间的核保映射关系;
20.基于所述核保映射关系,从所述预设核保数据库中匹配得到核保结论。
21.可选的,根据本发明的一些实施例,所述对所述健康评定材料进行文本内容提取,得到健康评定字段,包括:
22.对所述健康评定材料进行光学字符识别,获取所述健康评定材料中的材料文本内容;
23.对所述材料文本内容进行语义筛选,得到健康评定字段。
24.可选的,根据本发明的一些实施例,所述对所述材料文本内容进行语义筛选,得到健康评定字段,包括:
25.对所述材料文本内容进行第一文本切分处理,获取材料文本字段;
26.将所述材料文本字段向量化,获取与所述材料文本字段对应的材料文本向量;
27.基于预设规范文集获取预设规范向量,所述预设规范文集为符合通用医学规范的医学词汇文集;
28.将所述材料文本向量与所述预设规范向量进行匹配,并计算所述材料文本向量与所述预设规范向量之间的欧氏距离;
29.当所述欧氏距离小于预设阈值,获取所述预设规范向量在所述预设规范文集中对应的预设规范字段;
30.将所述预设规范字段确定为所述健康评定字段。
31.可选的,根据本发明的一些实施例,所述基于预设规范文集获取预设规范向量,包括:
32.对所述预设规范文集进行第二文本切分处理,获取所述预设规范字段;
33.将所述预设规范字段向量化,获取与所述预设规范字段对应的所述预设规范向量。
34.可选的,根据本发明的一些实施例,所述将所述材料文本向量与所述预设规范向量进行匹配,并计算所述材料文本向量与所述预设规范向量之间的欧氏距离,包括:
35.对所述材料文本字段进行词性识别,并将名词性质的所述材料文本向量与所述预设规范向量进行匹配;
36.计算名词性质或者形容词性质的所述材料文本向量与所述预设规范向量之间的所述欧氏距离。
37.第二方面,本发明实施例提供了一种电子设备,包括:存储器、处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现如本发明第一方面实施例中任意一项所述的核保方法。
38.第三方面,本发明实施例提供了一种计算机可读存储介质,所述存储介质存储有程序,所述程序被处理器执行实现如本发明第一方面实施例中任意一项所述的核保方法。
39.根据本发明实施例的核保方法、电子设备和计算机可读存储介质,至少具有如下有益效果:
40.本发明实施例的核保方法中,先获取反映核保目标健康状况的健康评定材料,然后对健康评定材料进行文本内容提取,得到健康评定字段,再基于自然语言识别模型从健康评定字段中提取核保目标的异常健康信息,进而从预设核保数据库中筛选出与异常健康信息对应的核保结论。根据本发明提供的核保方法,可以从核保目标所提供的健康评定材料中,筛选出核保所需要参照的、反映核保目标健康状况的异常健康信息,从而准确判断核保目标健康评定材料中所反映的健康状况,最终以异常健康信息为依据得到对应的核保结论。
41.本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
42.本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
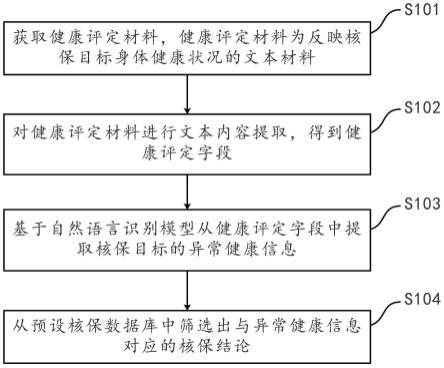
43.图1为本发明实施例提供的核保方法流程示意图;
44.图2为本发明实施例提供的核保方法另一流程示意图;
45.图3为本发明实施例提供的核保方法另一流程示意图;
46.图4为本发明实施例提供的核保方法另一流程示意图;
47.图5为本发明实施例提供的核保方法另一流程示意图;
48.图6为本发明实施例提供的核保方法另一流程示意图;
49.图7为本发明实施例提供的核保方法另一流程示意图;
50.图8为本发明实施例提供的核保方法另一流程示意图;
51.图9为本发明实施例提供的核保方法另一流程示意图;
52.图10为本发明实施例提供的执行核保方法的电子设备示意图。
具体实施方式
53.下面详细描述本发明的实施例,实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
54.在本发明的描述中,若干的含义是一个或者多个,多个的含义是两个以上,大于、小于、超过等理解为不包括本数,以上、以下、以内等理解为包括本数。如果有描述到第一、第二只是用于区分技术特征为目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量或者隐含指明所指示的技术特征的先后关系。
55.在本发明的描述中,需要理解的是,涉及到方位描述,例如上、下、左、右、前、后等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和
操作,因此不能理解为对本发明的限制。
56.在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示意性实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
57.本发明的描述中,需要说明的是,除非另有明确的限定,设置、安装、连接等词语应做广义理解,所属技术领域技术人员可以结合技术方案的具体内容合理确定上述词语在本发明中的具体含义。另外,下文中对于具体步骤的标识并不代表对于步骤顺序与执行逻辑的限定,各个步骤之间的执行顺序与执行逻辑应参照实施例所表述的内容进行理解与推定。
58.人工智能(artificial intelligence,ai):是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学;人工智能是计算机科学的一个分支,人工智能企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。人工智能可以对人的意识、思维的信息过程的模拟。人工智能还是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理技术、操作/交互系统、机电一体化等技术。人工智能软件技术主要包括计算机视觉技术、机器人技术、生物识别技术、语音处理技术、自然语言处理技术以及机器学习/深度学习等几大方向。
59.本技术实施例提供的核保方法,涉及人工智能技术领域。本技术实施例提供的核保方法可应用于终端中,也可应用于服务器端中,还可以是运行于终端或服务器端中的软件。在一些实施例中,终端可以是智能手机、平板电脑、笔记本电脑、台式计算机等;服务器端可以配置成独立的物理服务器,也可以配置成多个物理服务器构成的服务器集群或者分布式系统,还可以配置成提供云服务、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、cdn以及大数据和人工智能平台等基础云计算服务的云服务器;软件可以是实现核保方法的应用等,但并不局限于以上形式。
60.本技术可用于众多通用或专用的计算机系统环境或配置中。例如:个人计算机、服务器计算机、手持设备或便携式设备、平板型设备、多处理器系统、基于微处理器的系统、置顶盒、可编程的消费电子设备、网络pc、小型计算机、大型计算机、包括以上任何系统或设备的分布式计算环境等等。本技术可以在由计算机执行的计算机可执行指令的一般上下文中描述,例如程序模块。一般地,程序模块包括执行特定任务或实现特定抽象数据类型的例程、程序、对象、组件、数据结构等等。也可以在分布式计算环境中实践本技术,在这些分布式计算环境中,由通过通信网络而被连接的远程处理设备来执行任务。在分布式计算环境中,程序模块可以位于包括存储设备在内的本地和远程计算机存储介质中。
61.需要说明的是,在本技术的各个具体实施方式中,当涉及到需要根据核保目标的身份信息、核保目标的行为数据,核保目标的历史数据以及核保目标的位置信息等与核保目标身份或特性相关的数据进行相关处理时,都会先获得核保目标的许可或者同意,而且,
对这些数据的收集、使用和处理等,都会遵守相关国家和地区的相关法律法规和标准。此外,当本技术实施例需要获取核保目标的敏感个人信息时,会通过弹窗或者跳转到确认页面等方式获得核保目标的单独许可或者单独同意,在明确获得核保目标的单独许可或者单独同意之后,再获取用于使本技术实施例能够正常运行的必要的核保目标相关数据。
62.目前,核保需要业务人员与核保目标进行函件沟通处理,在获得核保目标许可或者同意的前提下,基于核保目标所提供的健康评定材料,业务人员按照手册和经验对健康评定材料中存在的异常健康信息进行确认,从而做最终核保决定。然而,由于业务人员不一定是医学专业人士,因此相关技术中仅靠人工处理核保任务,难以从健康评定材料中精准确定核保所需要参照的医学信息。因此,业内亟需一种核保方法,能够准确判断核保目标健康评定材料中所反映的健康状况。
63.本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明提出一种核保方法、电子设备和计算机可读存储介质,能够准确判断核保目标健康评定材料中所反映的健康状况。
64.下面参照附图作出较为详尽的实施例说明。
65.参照图1,根据本发明的第一方面实施例的核保方法,包括:
66.步骤s101,获取健康评定材料,健康评定材料为反映核保目标健康状况的文本材料;
67.需要说明的是,核保目标指的是需要核保的目标对象,应理解,核保目标一般指的是自然人。健康评定材料,指的是能够反映核保目标健康状况的文本材料,常见的健康评定材料包括但不限于体检报告、病例、住院报告、检查诊断报告等。需要强调,获取健康评定材料的目的是为了从健康评定材料中获取反映核保目标健康状况的医学信息,以供后续从预设核保数据库中筛选出与异常健康信息对应的核保结论。
68.步骤s102,对健康评定材料进行文本内容提取,得到健康评定字段;
69.需要说明的是,对健康评定材料进行文本内容提取指的是对健康评定材料中的文本内容进行信息抽取(information extraction),以得到健康评定字段。信息抽取,指从自然语言文本中抽取指定类型的实体、关系、事件等事实信息,并形成结构化数据输出的文本处理技术。信息抽取是从文本数据中抽取特定信息的一种技术。文本数据是由一些具体的单位构成的,例如句子、段落、篇章,文本信息正是由一些小的具体的单位构成的,例如字、词、词组、句子、段落或是这些具体的单位的组合。抽取文本数据中的名词短语、人名、地名等都是文本信息抽取,其中,文本信息抽取技术所抽取的信息还可以是各种其他类型的信息。应理解,健康评定字段指的是,健康评定材料文本内容的片段。由于健康评定材料包括反映核保目标健康状况的医学信息,因此通过对健康评定材料的文本内容进行处理,从而获取健康评定字段,可以便于后续基于自然语言识别模型从健康评定字段中提取核保目标的异常健康信息。
70.步骤s103,基于自然语言识别模型从健康评定字段中提取核保目标的异常健康信息;
71.由于不同医院出具的健康评定材料中对异常健康信息的表述存在一定差异,并且处理核保事宜的人员并不一定是医学专业人士,因此仅仅依靠人工处理较难准确判断核保目标的健康情况。因此,根据本发明提供的一些实施例,基于自然语言识别模型从健康评定
字段中提取核保目标的异常健康信息,从而提升了核保方法的效率与准确性。需要说明的是,自然语言处理(natural language processing,nlp),指的是用计算机来处理、理解以及运用人类语言(如中文、英文等),自然语言处理属于人工智能的一个分支,是计算机科学与语言学的交叉学科,又常被称为计算语言学。自然语言处理包括语法分析、语义分析、篇章理解等。自然语言处理常用于机器翻译、手写体和印刷体字符识别、语音识别及文语转换、信息意图识别、信息抽取与过滤、文本分类与聚类、舆情分析和观点挖掘等技术领域,它涉及与语言处理相关的数据挖掘、机器学习、知识获取、知识工程、人工智能研究和与语言计算相关的语言学研究等。而本发明一些实施例中的自然语言识别模型,即自然语言处理所用到的人工智能模型。相关技术中,常用的自然语言识别模型包括但不限于埃尔莫模型(embeddings from language models,elmo)、预训练生成模型(generative pre-training,gpt)以及bert模型等众多类型的模型。应理解,基于自然语言识别模型对健康评定字段进行语义识别,能够从健康评定字段中获取异常健康信息,其中,异常健康信息指的是反映核保目标异常健康状况的医学信息,例如“肺部肿块”、“肺部阴影”可以是反映核保目标肺部健康状况的异常健康信息,又例如“甲状腺结节”、“甲状腺超声异常”可以是反映核保目标甲状腺健康状况的异常健康信息。需要强调,异常健康信息可以是患病名称,也可以是患病症状、患病参数,还可以是其他能够体现核保目标异常健康状况的文本内容。
72.步骤s104,从预设核保数据库中筛选出与异常健康信息对应的核保结论。
73.需要说明的是,预设核保数据库是指,预先设定的、与各种异常健康状况相匹配的核保信息数据库。在核保过程中,需要根据核保目标是否患有疾病以及核保目标所患疾病的严重程度,来从预设核保数据库中匹配与核保目标健康状况相适应的核保方案。因此,根据本发明提供的一些实施例,在获取到异常健康信息之后,需要先从预设核保数据库中筛选出与异常健康信息相匹配的核保映射关系,然后基于核保映射关系确定核保目标是否患有预设核保数据库中所列明的疾病、核保目标所患疾病的严重程度,从而得出与核保目标的异常健康信息对应的核保结论。应理解,核保映射关系的形式可以是“预设疾病名称-预设疾病特征-核保结论”的形式,也可以是“预设疾病名称-预设疾病特征-预设疾病参数-核保结论”的形式,还可以是其他类型的形式,当获取核保映射关系中任一环节的内容,都可以基于该环节锁定并获取其对应的核保映射关系的其他内容。需要说明,核保结论即核保过程中根据核保目标的健康状况所得出的结论,核保结论可以基于核保目标的健康状况对不同险种(例如寿险、重疾险、医疗险、意外险、意外医疗险等)输出不同的核保结论(例如标体、除责、加费、延期、拒保等)。需要强调,从预设核保数据库中筛选出与异常健康信息对应的核保结论包括但不限于上述举出的具体实施例。
74.本发明实施例的核保方法中,先获取反映核保目标健康状况的健康评定材料,然后对健康评定材料进行文本内容提取,得到健康评定字段,再基于自然语言识别模型从健康评定字段中提取核保目标的异常健康信息,进而从预设核保数据库中筛选出与异常健康信息对应的核保结论。根据本发明提供的核保方法,可以从核保目标所提供的健康评定材料中,筛选出核保所需要参照的、反映核保目标健康状况的异常健康信息,从而准确判断核保目标健康评定材料中所反映的健康状况,最终以异常健康信息为依据得到对应的核保结论。
75.参照图2,由于不同医院出具的健康评定材料中,关于核保目标患病症状的表述通
常存在不够规范的问题,从而影响核保过程中对核保目标健康状况的判断,进而影响核保方法的效率。因此,根据本发明提供的一些较为优选的实施例,基于自然语言识别模型从健康评定字段中提取核保目标的异常健康信息,包括:
76.步骤s201,基于自然语言识别模型对健康评定字段进行疾病名称识别,得到核保目标所患疾病的患病名称;
77.根据本发明提供的一些实施例,健康评定字段中包括核保目标所患疾病的患病名称。疾病名称识别,指的是基于自然语言识别模型,对健康评定字段进行语义识别。疾病名称识别中,当自然语言识别模型识别到某一字段所表述的语义匹配上某一疾病的名称,随即将该名称认定为核保目标的患病名称。应理解,本发明一些实施例中,患病名称可以作为异常健康信息被自然语言识别模型输出。
78.步骤s202,根据患病名称,从预设核保数据库中查询得到与患病名称对应的预设疾病特征;
79.根据本发明提供的一些实施例,预设核保数据库指的是预先设定的、与各种异常健康状况相匹配的核保信息数据库。在核保过程中,需要根据核保目标是否患有疾病以及核保目标所患疾病的严重程度,来从预设核保数据库中匹配与核保目标健康状况相适应的核保方案。应理解,核保映射关系的形式可以是“预设疾病名称-预设疾病特征-核保结论”的形式,也可以是“预设疾病名称-预设疾病特征-预设疾病参数-核保结论”的形式,还可以是其他类型的形式,当获取核保映射关系中任一环节的内容,都可以基于该环节锁定并获取其对应的核保映射关系的其他内容,故而,得到核保目标所患疾病的患病名称之后,可以从预设核保数据库中查询得到与患病名称对应的预设疾病名称,再根据预设疾病名称得到与患病名称对应的预设疾病特征,一些实施例中还可以获取与患病名称对应的疾病参数。需要明确,预设疾病名称、预设疾病特征、预设疾病参数,均为预设核保数据库中预先设置的信息;而患病名称、患病症状、患病参数,则指的是反映核保目标自身健康状况的信息。
80.步骤s203,根据与患病名称对应的预设疾病特征,通过自然语言识别模型从健康评定字段中提取异常健康信息。
81.根据本发明提供的一些实施例,在从预设核保数据库中查询得到与患病名称对应的预设疾病特征之后,参照与患病名称对应的预设疾病特征,通过自然语言识别模型从健康评定字段中提取异常健康信息。需要说明的是,本发明一些实施例中,通过自然语言识别模型从健康评定字段提取异常健康信息,是基于预设疾病特征的文本语义,来对健康评定字段进行识别,进而筛选出与预设疾病特征语义相匹配的内容,最终提取出异常健康信息。应理解,由于预设疾病特征与核保目标的患病名称相对应,故而一些实施例中,从健康评定字段中提取到的异常健康信息包括核保目标的患病症状。根据与患病名称对应的预设疾病特征,通过自然语言识别模型从健康评定字段中提取异常健康信息之后,即可准确判断核保目标健康评定材料中所反映的健康状况,最终从预设核保数据库中筛选出与异常健康信息对应的核保结论。
82.需要强调,步骤s201至步骤s203之所以需要先从健康评定字段中得到核保目标所患疾病的患病名称,再根据患病名称,从预设核保数据库中查询得到与患病名称对应的预设疾病特征,最后又基于与患病名称对应的预设疾病特征,通过自然语言识别模型从健康评定字段中提取异常健康信息,其原因在于,在众多类型的健康评定材料中,疾病的名称相
较于描述疾病症状、疾病严重程度的用语往往更为规范和统一。因此,患病名称可以作为健康评定字段中反映核保目标身体状况的线索,在预设核保数据库中查询得到与患病名称对应的一系列预设疾病特征之后,再以众多预设疾病特征的语义内容于其他健康评定字段进行比对,从而提取出反映核保目标身体状况的一系列异常健康信息。
83.参照图3,根据本发明的一些实施例,根据与患病名称对应的预设疾病特征,通过自然语言识别模型从健康评定字段中提取异常健康信息,包括:
84.步骤s301,以预设疾病特征为基准,通过自然语言识别模型在健康评定字段中进行语义比对;
85.步骤s302,根据语义比对,获取异常健康信息中的患病症状,患病症状与预设疾病特征的语义相匹配;
86.应理解,健康评定字段指的是,健康评定材料文本内容的片段。由于健康评定材料包括反映核保目标健康状况的医学信息,因此通过对健康评定材料的文本内容进行处理,从而获取健康评定字段,可以便于自然语言识别模型从健康评定字段中提取核保目标的异常健康信息。本发明一些实施例中,以预设疾病特征为基准,通过自然语言识别模型在健康评定字段中进行语义比对的目的,是为了在健康评定字段中找到与预设疾病特征语义相匹配的内容,从而进一步获取异常健康信息中的患病症状。
87.步骤s303,基于患病症状在健康评定字段中的位置,通过自然语言识别模型进行上下文比对;
88.步骤s304,根据上下文比对,获取异常健康信息中与患病症状对应的病症参数。
89.根据本发明提供的一些实施例,异常健康信息指的是反映核保目标异常健康状况的医学信息,例如“肺部肿块”、“肺部阴影”可以是反映核保目标肺部健康状况的异常健康信息,又例如“甲状腺结节”、“甲状腺超声异常”可以是反映核保目标甲状腺健康状况的异常健康信息。需要强调,异常健康信息可以是患病名称,也可以是患病症状、患病参数,还可以是其他能够体现核保目标异常健康状况的文本内容。需要说明的是,在核保过程中,需要参考的异常健康信息不仅仅包括核保目标的患病名称、患病症状,还包括对核保目标所患疾病症状的描述信息。例如,同样患有“肺炎”的患者,其中一位严重程度较轻,ct图显示肺部没有出现明显异样,而另一位严重程度较重,ct图显示肺部出现片状、斑点状或者斑片状的阴影,此时对于两个核保目标的核保策略必然会有差异。故而,本发明一些实施例中除了要获取患病名称,还要基于患病症状在健康评定字段中的位置,通过自然语言识别模型进行上下文比对,进而获取异常健康信息中与患病症状对应的病症参数。
90.需要说明的是,病症参数指的是健康评定字段中,反映核保目标患病症状的异常健康信息。其中,病症参数的含义应作广义理解,病症参数既可以表示某种患病病症的严重程度,例如肿瘤的尺寸参数,也可以表示某种患病病症的有无,例如肺部具有阴影则记为1,肺部没有阴影则记为0。
91.参照图4,根据本发明的一些实施例,从预设核保数据库中筛选出与异常健康信息对应的核保结论,包括:
92.步骤s401,根据异常健康信息,获取患病名称、患病症状与病症参数之间的核保映射关系;
93.步骤s402,基于核保映射关系,从预设核保数据库中匹配得到核保结论。
94.根据本发明提供的一些较为优选的实施例,在获取病症参数后,往往需要与患病名称、患病症状建立核保映射关系。例如{甲状腺结节;甲状腺超声异常,甲状腺异常肿大;1,0}表示核保目标患有“甲状腺结节”这一疾病,其中出现了“甲状腺超声异常”(记为1),没有出现甲状腺异常肿大(记为0)。又例如{肺炎;肺部出现片状阴影,咳血;1,0}表示核保目标患有“肺炎”这一疾病,其中核保目标肺部出现片状阴影(记为1),没有咳血(记为0)。如此一来,根据核保目标异常健康信息所反映出的不同的身体健康状况,即可相应的从预设核保数据库中准确匹配得到对应的核保结论。应理解,核保映射关系可以包括,但不限于上述举出的具体实施例。
95.参照图5,根据本发明的一些实施例,对健康评定材料进行文本内容提取,得到健康评定字段,包括:
96.步骤s501,对健康评定材料进行光学字符识别,获取健康评定材料中的材料文本内容;
97.需要说明的是,光学字符识别(optical character recognition,ocr)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程,亦即将图像中的文字进行识别,并以文本的形式返回。应理解,ocr技术处理能够对图像中的文字进行识别,还可以通过对图像像素的处理,将图像中的颜色进行识别与分类。典型的ocr的技术路线包括但不限于以下环节:输入、图像预处理、图像检测、内容识别、输出。
98.需要说明的是,图像预处理通常是针对图像的成像问题进行修正,常见的预处理包括但不限于:几何变换(透视、扭曲、旋转等)、畸变校正、去除模糊、图像增强和光线校正等过程。传统ocr基于数字图像处理和传统机器学习等方法对图像进行处理和特征提取。常用的二值化处理有利于增强简单场景的文本信息,但对于复杂背景二值化的收效甚微。传统方法上采用方向梯度直方图(histogram of oriented gradient,hog)对图像进行特征提取,然而hog对于图像模糊、扭曲等问题鲁棒性很差,对于复杂场景泛化能力不佳。由于深度学习的飞速发展,现在普遍使用基于卷积神经网络(convolutional neural networks,cnn)的神经网络作为特征提取手段。得益于cnn强大的学习能力,配合大量的数据可以增强特征提取的鲁棒性,面临模糊、扭曲、畸变、复杂背景和光线不清等图像问题均可以表现良好的鲁棒性。图像检测即检测图像组成的各个元素所在位置和范围及其布局,图像检测通常也包括版面分析、文字行检测等,图像检测主要解决的问题是图像中各个元素的位置,图像中各个元素的范围有多大。内容识别是在图像检测的基础上,对图像中各个元素的内容进行识别,例如将图像中的文本信息转化为文本信息。内容识别主要解决的问题是图像中各个元素所蕴含的信息是什么,识别出的内容通常需要再次核对以保证其正确性,内容校正也被认为属于这一环节。因此,对健康评定材料进行光学字符识别,即可获取健康评定材料中的材料文本内容;
99.步骤s502,对材料文本内容进行语义筛选,得到健康评定字段。
100.需要说明的是,从健康评定材料中获取到的材料文本内容并不都能够反映核保目标的身体健康状况,因此一些较为优选的实施例中会对材料文本内容进行语义筛选,从而得到健康评定字段。应理解,对材料文本内容进行语义筛选可以通过多种方式进行,包括但不限于通过自然语言识别模型对材料文本内容进行语义筛选,从而得到健康评定字段。需要强调,本发明一些实施例通过对健康评定材料进行光学字符识别,获取健康评定材料中
的材料文本内容,再进一步对材料文本内容进行语义筛选,得到健康评定字段,减少了对无效字段的处理过程,从而进一步提高本发明实施例核保方法的处理效率,有助于后续对核保目标的异常健康信息进行提取。
101.参照图6,根据本发明的一些实施例,对材料文本内容进行语义筛选,得到健康评定字段,包括:
102.步骤s601,对材料文本内容进行第一文本切分处理,获取材料文本字段;
103.需要说明的是,为了便于对材料文本内容进行语义筛选,需要在筛选之前对材料文本内容进行第一文本切分处理,以获取材料文本字段,之后再以材料文本字段为基础进行语义筛选,以便于文本匹配。
104.步骤s602,将材料文本字段向量化,获取与材料文本字段对应的材料文本向量;
105.根据本发明提供的一些实施例,在对材料文本内容进行第一文本切分处理之后,会得到一些材料文本字段,例如原文中出现的“甲状腺结节”、“甲状腺超声异常”,经过第一文本切分处理后,随即生成“甲状腺”、“结节”、“超声”、“异常”等材料文本字段。进一步,将材料文本字段向量化,即可获取与材料文本字段对应的材料文本向量,例如将“甲状腺”、“结节”、“超声”、“异常”等材料文本字段向量化,生成{甲状腺,结节}、{甲状腺,超声,异常}等形式的材料文本向量。
106.步骤s603,基于预设规范文集获取预设规范向量,预设规范文集为符合通用医学规范的医学词汇文集;
107.需要说明的是,预设规范文集为符合通用医学规范的医学词汇文集,典型的预设规范文集可以是涵盖2步骤s6000 种疾病的国际疾病分类(international classification of diseases,icd),也可以是医学用语词典,还可以是其他类型的医学词汇文集。其中,icd是世界卫生组织(world health organization,who)制定的国际统一的疾病分类方法,它根据疾病的病因、病理、临床表现和解剖位置等特性,将疾病分门别类,使其成为一个有序的组合,并用编码的方法来表示的系统。系统收录了疾病记录近2步骤s6000多条,内容全面准确,涵盖医院所有科别的各种疾病,是国内目前最完备的。因此一些较为优选的实施例中,选用icd作为本发明实施例中的预设规范文集。本发明一些实施例中,预设规范向量的形式与材料文本向量的形式对应
108.应理解,之所以基于预设规范文集获取预设规范向量,是为了在后续步骤中,将预设规范文集提取出来的预设规范向量与材料文本字段中提取出来的材料文本向量进行匹配,得到健康评定字段。需要强调,步骤s603与步骤s601、步骤s602并无严格的逻辑从属关系,因此步骤s603可以在步骤s601之前执行、也步骤s601与步骤s602之间执行、还可以在步骤s602之后执行。
109.步骤s604,将材料文本向量与预设规范向量进行匹配,并计算材料文本向量与预设规范向量之间的欧氏距离;
110.步骤s605,当欧氏距离小于预设阈值,获取预设规范向量在预设规范文集中对应的预设规范字段;
111.步骤s606,将预设规范字段确定为健康评定字段。
112.根据本发明提供的一些实施例,医学中的疾病名称、疾病症状等词汇,差一个字就可能代表两个不同的疾病,并且预设规范文集中规定的医学词汇是有限集,所以一些较为
优选的实施例中,将材料文本内容与预设规范文集的内容进行较为精准的匹配,通过采用将材料文本向量与预设规范向量进行匹配的方式,计算材料文本向量与预设规范向量之间的欧氏距离,当某一个材料文本向量与某一个预设规范向量之间的欧氏距离小于预设阈值,即可获取预设规范向量在预设规范文集中对应的预设规范字段,从而将预设规范字段确定为健康评定字段。
113.需要说明的是,一些较为具体的实施例中,预设规范文集中规定的医学词汇是按照顺序进行编号的,例如甲状腺=10、结节=11、超声=12、异常=14。因此,将材料文本向量{甲状腺,结节}与预设规范向量{甲状腺,超声,异常}进行匹配,即可转换为计算{10,11}与{10,12,14}之间欧氏距离。一些实施例中,当材料文本向量与预设规范向量之间的欧氏距离小于预设阈值,即可判定材料文本向量与预设规范向量之间的语义差异较小,从而获取预设规范向量在预设规范文集中对应的预设规范字段,进一步将预设规范字段确定为健康评定字段。若材料文本向量无法匹配到欧氏距离小于预设阈值的预设规范向量,则将材料文本向量所指代的材料文本字段判定为未知新词汇或者非医学词汇,直接跳过。应理解,之所以基于预设规范文集获取预设规范向量,将预设规范文集提取出来的预设规范向量与材料文本字段中提取出来的材料文本向量进行匹配,得到健康评定字段,其原因在于,在体检报告、病例、住院报告、检查诊断报告等众多健康评定材料中,关于核保目标患病症状的表述通常存在不够规范的问题,从而影响核保过程中对核保目标健康状况的判断,进而影响核保方法的效率。因此,通过步骤s601至步骤s606可以基于预设规范文集中的预设规范向量,将材料文本字段进一步规范化、剔除无效字段,从而得到健康评定字段,可以以更高的效率基于自然语言识别模型从健康评定字段中提取核保目标的异常健康信息,最终从预设核保数据库中筛选出与异常健康信息对应的核保结论。
114.参照图7,根据本发明的一些实施例,基于预设规范文集获取预设规范向量,包括:
115.步骤s701,对预设规范文集进行第二文本切分处理,获取预设规范字段;
116.步骤s702,将预设规范字段向量化,获取与预设规范字段对应的预设规范向量。
117.根据本发明提供的一些实施例,基于预设规范文集获取预设规范向量,需要先对预设规范文集进行第二文本切分处理,获取预设规范字段,在对预设规范文集进行第二文本切分处理之后,会得到一些预设规范字段,例如预设规范文集中出现的“流感性肺炎”、“肺部呈斑点状阴影”,经过第二文本切分处理后,随即生成“流感性”、“肺炎”、“肺部”、“斑点状阴影”等预设规范字段。进一步,将材料文本字段向量化,即可获取与预设规范字段对应的材料文本向量,例如将“流感性”、“肺炎”、“肺部”、“斑点状阴影”等材料文本字段向量化,生成{流感性,肺炎}、{肺部,斑点状阴影}等形式的预设规范向量。应理解,基于预设规范文集获取预设规范向量不限于上述举出的具体实施例。
118.参照图8,根据本发明的一些实施例,将材料文本向量与预设规范向量进行匹配,并计算材料文本向量与预设规范向量之间的欧氏距离,包括:
119.步骤s801,对材料文本字段进行词性识别,并将名词性质的材料文本向量与预设规范向量进行匹配;
120.步骤s802,计算名词性质的材料文本向量与预设规范向量之间的欧氏距离。
121.根据本发明提供的一些实施例,在计算名词性质的材料文本向量与预设规范向量之间的欧氏距离之前,还需要对材料文本字段进行词性识别,并将名词性质的材料文本向
量与预设规范向量进行匹配。需要说明的是,在经过第一文本切分处理得到材料文本字段之后,进一步,对材料文本字段进行词性识别,应理解,此处的词性识别指的是对材料文本字段的用词形状作出界定,例如:将“肺炎”、“肺部”、“斑点状阴影”等材料文本字段界定为名词(noun),将“传染性”、“良性”、“恶性”界定为形容词(adjective),将“和”、“以及”、“而且”界定为连词(conjunction)。应理解,疾病名称、病症等医学词汇的词性,主要集中于名词与形容词,因此,相较之下无需或者较少需要对连词、副词等不表明实质含义的材料文本字段进行匹配,以提升材料文本向量与预设规范向量的匹配效率,便于准确计算名词性质的材料文本向量或者形容词性质的材料文本向量与预设规范向量之间的欧氏距离。
122.参照图9,根据本发明的一些实施例,基于自然语言识别模型从健康评定字段中提取核保目标的异常健康信息之前,还包括:
123.步骤s901,将带有医学词汇语义标签的训练数据集输入基础识别模型进行迭代训练;
124.步骤s902,每一轮迭代训练后,计算基础识别模型的语义识别准确率并对基础识别模型进行更新;
125.步骤s903,统计语义识别准确率在每一轮迭代训练中的变化情况,当语义识别准确率收敛于定值,停止迭代训练并得到训练好的自然语言识别模型。
126.需要说明的是,迭代训练的目的,是为了经过的数轮语义识别训练,逐渐提升语义识别准确率。根据本发明提供的一些实施例,自然语言识别模型的训练过程包括:将带有医学词汇语义标签的训练数据集输入基础识别模型进行迭代训练,每一轮迭代训练后,计算基础识别模型的语义识别准确率并对基础识别模型进行更新。其中,基础识别模型可以由无语义识别能力的原始预设模型经过预训练得到,也可以选用具备初步语义识别能力的预设模型。需要说明的是,迭代训练的目的是为了不断优化基础识别模型的医学词汇语义识别能力。每一轮迭代训练后,都需要计算基础识别模型的语义识别准确率,以明确优化训练过程中基础识别模型的识别准确率在逐渐提升。需要说明的是,在优化训练的过程中,每经过一轮迭代训练,都需要对基础识别模型进行一次更新,以使得基础识别模型能在下一轮迭代训练中对医学词汇语义的识别有更好的表现。迭代训练中,对基础识别模型进行更新主要通过调整基础识别模型的参数来完成,基础识别模型的参数即基础识别模型内部与语义识别准确率相关的内部参数。
127.需要说明的是,当垃圾识别准确率收敛于定值,停止迭代训练并得到训练好的自然语言识别模型,其中定值指的是:在对基础识别模型的内部参数进行数轮调整后,基础识别模型的语义识别准确率收敛值。本发明提供的一些实施例中,基础识别模型的语义识别准确率将会稳定在某一误差区间内,例如语义识别准确率在84%到86%区间内波动,则可以认为定值为85%。应理解,定值不是一个确切不变的值,而是一个会随训练条件发生变化的值。当语义识别准确率收敛于定值,判定优化训练已达较佳效果,即可停止迭代训练,其中,停止迭代训练后得到的医学词汇语义识别模型即自然语言识别模型,通过优化训练得到的自然语言识别模型将具备更加精确的语义识别准确率。
128.图10示出了本发明实施例提供的电子设备1000。电子设备1000包括:处理器1001、存储器1002及存储在存储器1002上并可在处理器1001上运行的计算机程序,计算机程序运行时用于执行上述的核保方法。
129.处理器1001和存储器1002可以通过总线或者其他方式连接。
130.存储器1002作为一种非暂态计算机可读存储介质,可用于存储非暂态软件程序以及非暂态性计算机可执行程序,如本发明实施例描述的核保方法。处理器1001通过运行存储在存储器1002中的非暂态软件程序以及指令,从而实现上述的核保方法。
131.存储器1002可以包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需要的应用程序。存储数据区可存储执行上述的核保方法。此外,存储器1002可以包括高速随机存取存储器1002,还可以包括非暂态存储器1002,例如至少一个储存设备存储器件、闪存器件或其他非暂态固态存储器件。在一些实施方式中,存储器1002可选包括相对于处理器1001远程设置的存储器1002,这些远程存储器1002可以通过网络连接至该电子设备1000。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
132.实现上述的核保方法所需的非暂态软件程序以及指令存储在存储器1002中,当被一个或者多个处理器1001执行时,执行上述的核保方法,例如,执行图1中的方法步骤s101至步骤s104、图2中的方法步骤s201至步骤s203、图3中的方法步骤s301至步骤s304、图4中的方法步骤s401至步骤s402、图5中的方法步骤s501至步骤s502、图6中的方法步骤s601至步骤s606、图7中的方法步骤s701至步骤s702、图8中的方法步骤s801至步骤s802、图9中的方法步骤s901至步骤s903。
133.本发明实施例还提供了计算机可读存储介质,存储有计算机可执行指令,计算机可执行指令用于执行上述的核保方法。
134.在一实施例中,该计算机可读存储介质存储有计算机可执行指令,该计算机可执行指令被一个或多个控制处理器执行,例如,执行图1中的方法步骤s101至步骤s104、图2中的方法步骤s201至步骤s203、图3中的方法步骤s301至步骤s304、图4中的方法步骤s401至步骤s402、图5中的方法步骤s501至步骤s502、图6中的方法步骤s601至步骤s606、图7中的方法步骤s701至步骤s702、图8中的方法步骤s801至步骤s802、图9中的方法步骤s901至步骤s903。
135.以上所描述的装置实施例仅仅是示意性的,其中作为分离部件说明的单元可以是或者也可以不是物理上分开的,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。
136.本领域普通技术人员可以理解,上文中所公开方法中的全部或某些步骤、系统可以被实施为软件、固件、硬件及其适当的组合。某些物理组件或所有物理组件可以被实施为由处理器,如中央处理器、数字信号处理器或微处理器执行的软件,或者被实施为硬件,或者被实施为集成电路,如专用集成电路。这样的软件可以分布在计算机可读介质上,计算机可读介质可以包括计算机存储介质(或非暂时性介质)和通信介质(或暂时性介质)。如本领域普通技术人员公知的,术语计算机存储介质包括在用于存储信息(诸如计算机可读指令、数据结构、程序模块或其他数据)的任何方法或技术中实施的易失性和非易失性、可移除和不可移除介质。计算机存储介质包括但不限于ram、rom、eeprom、闪存或其他存储器技术、cd-rom、数字多功能盘(dvd)或其他光盘存储、磁盒、磁带、储存设备存储或其他磁存储装置、或者可以用于存储期望的信息并且可以被计算机访问的任何其他的介质。此外,本领域普通技术人员公知的是,通信介质通常包括计算机可读指令、数据结构、程序模块或者诸如
载波或其他传输机制之类的调制数据信号中的其他数据,并且可包括任何信息递送介质。还应了解,本发明实施例提供的各种实施方式可以任意进行组合,以实现不同的技术效果。
137.以上是对本发明的较佳实施进行了具体说明,但本发明并不局限于上述实施方式,熟悉本领域的技术人员在不违背本发明精神的共享条件下还可作出种种等同的变形或替换,这些等同的变形或替换均包括在本发明权利要求所限定的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。