基于多尺度损失函数的改进型u-net云图分割方法
技术领域
1.本发明属于深度学习领域,特别涉及了基于多尺度损失函数的改进型u-net云图分割方法。
背景技术:
2.随着遥感图像处理技术的发展,云作为一种重要的气象要素,在短时天气预报、降水量预测、卫星通信连接等方面得到广泛应用,云图分割作为云图分析的第一步骤,具有非常重要的研究意义。云层的光谱信息由粒子大小、水汽、高度、光学厚度等因素决定,影像上云的光谱特征存在多种表现形式,云本身的亮度、透明度以及纹理形状等特征的表现形式存在差异性,在高分辨率的遥感卫星图像中,部分区域会被云团污染,甚至会被完全遮盖,进而影响遥感图像的分类、分割、变化检测以及图像匹配等。
3.专家学者做了大量的研究,基于阈值法如long等人通过计算rgb颜色空间中的r通道与b通道的比值,然后根据比值选取合适的阈值来确定云与非云的区域;随着机器学习的发展taravat等人拓展了机器学习算法——支持向量机和神经网络在云图领域的自动分割算法;随着深度学习的发展,ronneberger等人提出用于图像分割的u-net,通过跳跃连接将编码解码的特征图进行拼接,有效融合浅层细节信息和深层语义信息。但是传统的基于阈值法和机器学习方法的云图分割对算法的参数选取非常敏感,而且依赖研究人员做大量的特征提取,用于图像分割的u-net会等权重地分配特征张量上所有空间位置和通道上的信息,而产生大量的计算冗余,导致模型训练速度变慢,分割精度变低。
技术实现要素:
4.发明目的:针对背景技术中云图分割存在的问题,提出一种基于改进损失函数的改进型u-net的遥感云图分割方法,准确率更高、泛化效果更好,具有非常重要的研究和应用价值。
5.技术方案:基于多尺度损失函数的改进型u-net云图分割方法,包括以下步骤:
6.(1)获取全天空图像分割数据库,对全天空图像分割数据库包含的云图以及与其对应的二值标签进行预处理获得数据集;
7.(2)利用改变卷积方式、添加高效通道注意力机制、修改归一化和添加多尺度特征融合的方法构建改进型u-net模型;
8.(3)提出改进型u-net模型的改进复合损失函数,表达式为:
9.l
improve
=βl
improve2
(1-β)lb10.其中,lb表示边界损失函数,边界损失函数的公式如下:
[0011][0012]
其中,δs=|s|-|s∩g| |g|-|s∩g|,s为预测结果边界上的像素点,g为真实标签边界上的像素点,p为标签边界上的任一像素点,q为
△
s内
的任一像素点,dg(q)为两个像素点之间的距离;
[0013]
β初始值设置为1,每一轮训练减小0.01;
[0014]
l
improve2
为结合dice损失函数和交叉熵损失函数的函数,表达式为:
[0015]
l
improve2
=αl
improve1
(1-α)l
ce
[0016]
其中α为超参数,l
ce
为交叉熵损失函数,公式如下:
[0017][0018]
其中,n为特征图中像素点的个数,pi∈[0,1]为模型预测的分割图中第i个像素点的值,gi∈{0,1}为二值标签中第i个像素点的值;
[0019]
l
improve1
为结合dice损失函数与log_cosh损失函数的函数,表达式为:
[0020]
l
improve1
=log(cosh(l
dice
))
[0021]
所述log_cosh损失函数的公式如下:
[0022]
l
log_cosh
=log(cosh(x))
[0023]
其中,l
dice
为dice损失函数,表达式如下:
[0024][0025]
其中,a、b分别指模型预测结果与真实标签结果,smooth是平滑因子,n为特征图中像素点的个数,pi∈[0,1]为模型预测的分割图中第i个像素点的值,gi∈{0,1}为二值标签中第i个像素点的值。
[0026]
(4)将步骤(1)得到的数据集输入改进型u-net模型进行训练、测试,获得最佳参数模型,输出预测效果图。
[0027]
所述步骤(1)的具体过程如下:
[0028]
(1.1)获取全天空图像分割数据库包含的天空—云图以及与其对应的二值标签;
[0029]
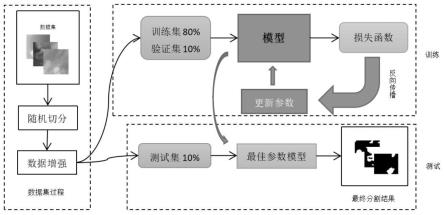
(1.2)将训练样本被随机切分为小样本,并对样本集采用数据增强方法,将数据集扩充为原来的十倍,将其分为3部分,训练集占80%,验证集占10%,测试集占10%。
[0030]
所述步骤(1.2)中,数据增强方法包括随机修剪,平移变换和噪声扰动。
[0031]
所述步骤(2)的具体过程如下:
[0032]
(2.1)利用改变卷积方式的方法改进u-net具体为:以u-net分割模型为基础,将编码部分中前两层和第三层的第一个卷积换成可变形卷积;
[0033]
(2.2)利用添加高效通道注意力机制的方法改进u-net具体为:以(2.1)模型为基础,在编码部分前三层输出的特征图后添加通道注意力机制,编码部分输出的特征图经过高效通道注意力机制生成一维注意力向量后,与原特征图进行对应元素相乘,得到加权后的特征图,特征图大小不变,对前三层加权后的特征图进行下采样操作,将前三层加权后的特征图与解码部分的特征图进行拼接操作;
[0034]
(2.3)利用修改归一化的方法改进u-net具体为:以(2.2)模型为基础,将weight normalization加在u-net的卷积层和激活层中间,重写深度网络的权重,通过对网络参数进行标准化实现归一化操作;
[0035]
(2.4)利用添加多尺度特征融合的方法改进u-net具体为:以(2.3)模型为基础,对
编码部分最后一层输出的特征图和解码部分每一层输出的特征图进行多尺度特征融合。
[0036]
所述(2.1)中编码部分为5层:第一层包括2个相同的可变卷积块deform-conv11、deform-conv12,可变卷积块主要由两个卷积块组成,其中一个卷积块均由18个步长为1,padding为1,大小为3
×
3的偏移量卷积核组成,另一个卷积块分别由32个步长为1,padding为1,大小为3
×
3的标准卷积核conv11、conv12组成;第二层包括2个相同的可变卷积块deform-conv21、deform-conv22,可变卷积块主要由两个卷积块组成,其中一个卷积块均由18个步长为1,padding为1,大小为3
×
3的偏移量卷积核组成,另一个卷积块分别由64个步长为1,padding为1,大小为3
×
3的标准卷积核conv21、conv22组成;第三层包括2个卷积块deform-conv3和conv3,其中conv3由128个步长为1,padding为1,大小为3
×
3的标准卷积核组成,deform-conv3由18个步长为1,padding为1,大小为3
×
3的偏移量卷积和conv3组成;第四层包括2个相同的卷积块conv4,均由256个步长为1,padding为1,大小为3
×
3的标准卷积核组成;第五层包括2个相同的卷积块conv5,均由512个步长为1,padding为1,大小为3
×
3的标准卷积核组成;该模型中解码部分为4层:均由一个上采样模块、两个与编码部分相对应的相同的标准卷积模块组成,各层各模块中卷积核的个数分别为(512,256,256)、(256,128,128)、(128,64,64)、(64,32,32),且核的大小均为3
×
3,同时第四层包括一个卷积块,由2个步长1,padding为1,大小为1
×
1的卷积核组成。
[0037]
所述步骤(2.4)中编码部分最后一层输出的特征图经过上采样与解码部分第一层输出的特征图进行拼接,将拼接后的特征图经过上采样和一个3
×3×
256的卷积与解码部分第二层输出的特征图进行拼接,将拼接后的特征图经过上采样和一个3
×3×
128的卷积与解码部分第三层输出的特征图进行拼接,将拼接后的特征图经过上采样和一个3
×3×
64的卷积与解码部分第四层输出的特征图进行拼接,将拼接后的特征图经过3
×3×
32的卷积,再经过1
×
1的卷积核。
[0038]
步骤(4)的具体过程如下:
[0039]
(4.1)将步骤(1)中的数据集的80%作为训练集和10%作为验证集输入到改进的u-net模型中进行训练,通过带标签的数据监督学习,利用梯度下降算法微调整个网络参数,最小化复合损失函数,获得最佳参数模型;
[0040]
(4.2)将步骤(1)中的数据集的10%作为测试集输入到(4.1)中的最佳参数模型中进行测试,输出预测效果图;
[0041]
(4.3)将(4.2)中的预测效果图与标签图进行比较,得到改进的u-net比较输出结果。
[0042]
有益效果:通过改变u-net的卷积方式、添加高效通道注意力机制、添加多尺度特征融合的方法,能够提取更加丰富且准确的特征信息,使得分割结果和泛化效果更加准确;将weight normalization加在u-net的卷积层和激活层中间代替batch normalization实现归一化,引入更少噪声的同时,处理速度更快;提出改进的复合损失函数使网络训练时,加强对云图边界的检测,有效提升了云图分割的准确率。
附图说明
[0043]
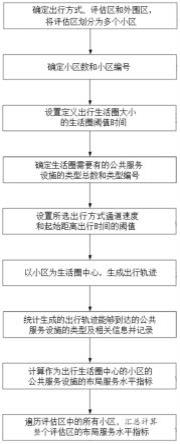
图1为实施例提供的云图分割流程图;
[0044]
图2为实施例提供的基于多尺度特征融合的改进型u-net结构图;
[0045]
图3为实施例提供的泛化实验比较图。
具体实施方式
[0046]
为使本发明的目的、技术方案及优点更加清楚明白,以下结合附图和实施例对本发明进行进一步的详细说明。
[0047]
图1为实施例提供的云图分割流程图,包括以下步骤:
[0048]
(1)获取新加坡全天空图像分割数据库,对新加坡全天空图像分割数据库包含的1013张天空—云图以及与其对应的二值标签进行预处理获得数据集;
[0049]
(2)利用改变卷积方式、添加高效通道注意力机制、修改归一化、添加多尺度特征融合的方法构建改进u-net框架;
[0050]
(3)结合dice损失函数、交叉熵损失函数、边界损失函数和log_cosh损失函数的优点,提出改进的复合损失函数;
[0051]
(4)将步骤(1)得到的数据集输入改进型u-net模型进行训练、测试,获得最佳参数模型,输出预测分割图;
[0052]
步骤(1)中获取新加坡全天空图像分割数据库包含的1013张天空——云图以及其对应的二值标签,尺寸大小为600
×
600
×
3,将云图随机切分为224
×
224
×
3大小的样本,并对样本集采用如随机修剪、平移变换、噪声扰动等数据增强的方法,将数据集扩充为原来的十倍,扩充现有数据的多样性。
[0053]
步骤(2)中本实施例将编码部分前两层和第三层的第一个卷积用可变形卷积代替,即在编码部分的浅层神经网络使用可变形卷积,可变形卷积根据当前需要识别的云图内容进行动态调整,更加精准的捕获浅层特征的细节信息。可变形卷积主要由偏移量卷积和标准卷积组成,实施例使用的标准卷积核大小为3
×
3,对于输入的一张特征图,为了学习偏移量offset,定义了另外一个偏移量卷积核大小为3
×
3,输出与原特征图大小相同,通道数为2n,这两个卷积核通过双线性插值后向传播算法同时学习。
[0054]
本实施例在编码部分前三层输出的特征图后添加高效通道注意力机制,使模型自动学习浅层特征图中重要的细节信息。编码部分输出的特征图经过高效通道注意力机制生成一维注意力向量后,与原特征图进行对应元素相乘,即显著的特征得到增强,非显著的特征就会相应得被抑制,输出完成特征重标定的特征图,特征图大小不变,对前三层加权后的特征图进行下采样操作,将前三层加权后的特征图与解码部分的特征图进行拼接操作。
[0055]
本实施例将weight normalization加在u-net的卷积层和激活层中间进行归一化处理,对网络的参数进行标准化,通过重写深度网络的权重来进行加上,引入更少的噪声,不需要额外的空间进行存储minibatch的均值和方差,对时间的开销小,所以速度更快。对于网络中一神经元,输入为x,输出为y,计算过程为y=φ(ω*x b),其中ω为与该神经元连接的权重,通过损失函数与梯度下降对网络进行优化的过程就是求解最优ω的过程。将ω的长度与方向解耦,可以表示为其中g为标量,大小等于ω的模长,为与ω同方向的单位向量,于是将训练过程中ω的学习转化为g和v的学习,损失函数l对g和v的梯度分别表示为:
[0056][0057][0058]
图2为实施例提供的基于多尺度特征融合的改进型u-net结构图。图2所示,输入网络的数据集尺寸为224
×
224
×
3,编码部分共有五层,前两层均由两个可变卷积块deform-conv11、deform-conv12、高效通道注意力机制和最大池化模块组成,可变卷积块包括偏移量卷积核和卷积块,卷积块包括3
×
3卷积核、wn和激活函数relu;第三层由可变卷积块、卷积块、高效通道注意力机制和最大池化模块组成;第四层由两个卷积块和最大池化模块组成;第五层由两个卷积块组成。解码部分共有四层,均由上采样模块、拼接模块、两个卷积块组成。在改进的u-net上添加多尺度特征融合模块,对编码部分最后一层输出的特征图和解码部分每一层输出的特征图进行多尺度特征融合。编码部分最后一层输出的特征图经过上采样与解码部分第一层输出的特征图进行拼接,将拼接后的特征图经过上采样和一个3
×3×
256的卷积与解码部分第二层输出的特征图进行拼接,将拼接后的特征图经过上采样和一个3
×3×
128的卷积与解码部分第三层输出的特征图进行拼接,将拼接后的特征图经过上采样和一个3
×3×
64的卷积与解码部分第四层输出的特征图进行拼接,将拼接后的特征图经过3
×3×
32的卷积,再经过1
×
1的卷积核对云图进行分类。
[0059]
将224
×
224
×
3的特征图输入到编码部分的第一层,经过两次可变卷积块deform-conv11输出224
×
224
×
32的特征图,经过高效通道注意力机制进行特征重标定输出224
×
224
×
32的特征图,经过池化层down1输出112
×
112
×
32的特征图;将112
×
112
×
32的特征图输入到编码部分的第二层,经过两次可变卷积块deform-conv12输出112
×
112
×
64的特征图,经过高效通道注意力机制进行特征重标定输出112
×
112
×
64的特征图,经过池化层down2输出56
×
56
×
64的特征图;将56
×
56
×
64的特征图输入到编码部分的第三层,经过可变卷积块deform-conv13输出56
×
56
×
128的特征图,经过卷积块conv13输出56
×
56
×
128的特征图,经过高效通道注意力机制进行特征重标定输出56
×
56
×
128的特征图,经过池化层down3输出28
×
28
×
128的特征图;将28
×
28
×
128的特征图输入到编码部分的第四层,经过两次卷积块conv14输出28
×
28
×
256的特征图,经过池化层down4输出14
×
14
×
256的特征图;将14
×
14
×
256的特征图输入到编码部分的第五层,经过两次卷积块conv15输出14
×
14
×
512的特征图;将14
×
14
×
512的特征图输入到解码部分的第一层,经过上采样up14输出28
×
28
×
512的特征图,经过拼接操作concat14连接up14和conv14输出的特征图得到28
×
28
×
768的特征图,经过两次卷积块conv24输出28
×
28
×
256的特征图;将28
×
28
×
256的特征图输入到解码部分的第二层,经过上采样up13输出56
×
56
×
256的特征图,经过拼接操作concat13连接up13和conv13经过高效通道注意力机制输出的特征图得到56
×
56
×
384的特征图,经过两次卷积块conv23输出56
×
56
×
128的特征图;将56
×
56
×
128的特征图输入到解码部分的第三层,经过上采样up12输出112
×
112
×
128的特征图,经过拼接操作concat12连接up12和conv12经过高效通道注意力输出的特征图得到112
×
112
×
192的特征图,经过两次卷积块conv22输出112
×
112
×
64的特征图;将112
×
112
×
64的特征图输入到解码部分的第四层,经过上采样up11输出224
×
224
×
64的特征图,经过拼接操作concat11
连接up11和conv11经过高效通道注意力输出的特征图得到224
×
224
×
96的特征图,经过两次卷积块conv21输出224
×
224
×
32的特征图;将编码部分最后一层输出的特征图经过上采样up21输出28
×
28
×
512的特征图,经过拼接操作concat21和解码部分第一层输出的特征图连接得到28
×
28
×
768的特征图,经过上采样up22和卷积conv31得到56
×
56
×
256的特征图,经过拼接操作concat22和解码部分第二层输出的特征图连接得到56
×
56
×
384的特征图,经过上采样up23和卷积conv32得到112
×
112
×
128的特征图,经过拼接操作concat23和解码部分第三层输出的特征图连接得到112
×
112
×
192的特征图,经过上采样up24和卷积conv33得到224
×
224
×
64的特征图,经过拼接操作concat24和解码部分第四层输出的特征图连接得到224
×
224
×
96的特征图,经过卷积conv34得到224
×
224
×
32的特征图,最后经过1
×
1的卷积对云图进行分类。
[0060]
步骤(3)具体为以下内容,dice损失函数的公式如下:
[0061][0062]
其中,a、b分别指模型预测结果与真实标签结果,smooth是平滑因子,该实施例中取值为0.00001,n为特征图中像素点的个数,pi∈[0,1]为模型预测的分割图中第i个像素点的值,gi∈{0,1}为二值标签中第i个像素点的值。dice损失函数是从特征图中所有像素点考虑,包括了需要分割的云以及背景区域,即dice损失函数只关注了全局信息,对于部分云图中背景区域较多的情况,会造成分割出的云定位不准或缺失严重,并且dice损失函数为非凸函数,会导致模型训练不稳定,且可能陷入局部最优而非全局最优。
[0063]
针对dice损失函数是非凸函数,加入平滑因子smooth来使函数相对平滑这种手段只能缓解而不能彻底解决非凸损失函数的问题,提出与log_cosh损失函数结合。log_cosh损失函数的公式如下:
[0064]
l
log_cosh
=log(cosh(x))
[0065]
其中,双曲余弦函数可用于平滑曲线,且在基于回归的损失函数中,常对cosh函数取对数,其导数为由此可知,l
log_cosh
损失函数是连续的且二阶可微。结合dice损失函数与log_cosh损失函数,函数表达式为:
[0066]
l
improve1
=log(cosh(l
dice
))
[0067]
针对dice损失函数只关注全局信息,提出与交叉熵损失函数结合。交叉熵损失函数的公式如下:
[0068][0069]
其中,n为特征图中像素点的个数,pi∈[0,1]为模型预测的分割图中第i个像素点的值,gi∈{0,1}为二值标签中第i个像素点的值。交叉熵损失函数对云和天空都有相同的权重,因此对于类别不平衡十分敏感,但是可以使得函数曲线平滑,而且交叉熵损失函数关注了局部信息。结合两者有效提升了分割准确性,函数表达式为:
[0070]
l
improve2
=αl
improve1
(1-α)l
ce
[0071]
其中,本实施例中α取值为0.5。
[0072]
针对l
improve2
结合的dice损失函数和交叉熵损失函数关注全局信息和局部信息,提出与边界损失函数结合。边界损失函数的公式如下:
[0073][0074]
其中,δs=|s|-|s∩g| |g|-|s∩g|,s为预测结果边界上的像素点,g为真实标签边界上的像素点,p为标签边界上的任一像素点,q为
△
s内的任一像素点,dg(q)为两个像素点之间的距离。边界损失函数的目的是最小化分割边界和标签边界之间的距离,关注了边界信息。结合三者有效提升了分割准确性,得到最终改进的损失函数表达式为:
[0075]
l
improve
=βl
improve2
(1-β)lb[0076]
其中,lb表示边界损失函数,本实施例中β初始值设置为1,每过一轮减小0.01。
[0077]
步骤(4)具体为将训练的数据输入到模型中进行训练,通过带标签的数据监督学习,利用梯度下降算法微调整个网络参数,将训练最佳的模型权重用测试数据进行测试,直接输出最终预测效果图。图3为实施例提供的泛化实验比较图。图3所示,实验选取了数据集中四种天空——云图不同分布的图像,实验1中云大多分布左下方,背景区域较大;实验2中云大多分布在右上方,背景区域较大;实验3中云分布较疏散,薄云较多;实验4中云分布较密集,背景区域较小。通过对四种不同分布的遥感图像进行分割对比可知,改进型u-net的泛化效果最好,云图中的细节部分和边缘部分相比于其他模型的泛化效果更加清晰,能够较好的完成云图分割任务。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。