1.本发明涉及智能游戏技术领域,尤其涉及一种基于深度学习的游戏漏洞智能修复方法。
背景技术:
2.游戏运行时的逻辑和数据十分复杂,因此也很容易出现各种漏洞。及时有效地修复漏洞,能给玩家带来良好的体验。目前修复游戏漏洞主要有patch和hotfix两种方式,大部分游戏都会将两种方式结合使用。
3.上述两种方式,均在进行漏洞修复时,消耗大量的时间,从而导致玩家长时间处于不良好的体验中。
4.中国专利公开号:cn109646958a公开了一种基于webgl的3d网页游戏的开发方法,包括如下步骤:素材收集:根据游戏的人物、场景、情节进行相关素材的收集,并分类打包;模型构建:根据游戏内的人物形象并利用webgl进行相关人物3d模型的构建;场景搭建:根据游戏的场景内容并利用un ity软件进行场景的渲染搭建;动画创建:根据游戏的情节并利用骨骼动画对相应的3d人物模型创建动画;脚本编写:根据游戏情节以及相关人物模型的动作编写相应的控制脚本;运行调试:在网页环境中运行该游戏,并根据运行过程中的漏洞进行修复。本发明结构设计合理,本发明在游戏运行过程中无需借助插件,避免了电脑感染病毒的风险,另外游戏运行流畅,提升了游戏体验;由此可见,所述基于webgl的3d网页游戏的开发方法在进行漏洞修复时,会对游戏运行形成影响,导致用户体验不佳,并且对于游戏和漏洞修复同时运行,存在控制不精准,导致修复过程效率低。
技术实现要素:
5.为此,本发明提供一种基于深度学习的游戏漏洞智能修复方法,用以克服现有技术中在进行漏洞修复时,会对游戏运行形成影响,导致用户体验不佳,并且对于游戏和漏洞修复同时运行,存在控制不精准,导致修复过程效率低的问题。
6.为实现上述目的,本发明提供一种基于深度学习的游戏漏洞智能修复方法,包括:
7.步骤s1、数据采集模块采集游戏中出现的漏洞,数据分析模块对该漏洞进行分析,确定漏洞对应损坏的代码数量;
8.步骤s2、修复指令确定模块根据所述数据分析模块分析的漏洞及对应损坏的代码数量确定修复指令;
9.步骤s3、代码确定模块根据所述修复指令确定模块确定的所述修复指令确定所述漏洞对应的修复补丁;
10.步骤s4、数据比对模块在所述代码确定模块确定所述修复补丁完成时,将所述修复补丁中对应的代码与所述漏洞对应的代码进行比对,并确定修复补丁中代码与所述漏洞对应的原始代码的吻合度;
11.步骤s5、建模模块在所述数据比对模块确定所述吻合度达到预设阈值时,建立深
度学习模型,并将若干所述漏洞、对应的损坏代码数量和修复补丁划分为训练数据集和验证数据集;
12.步骤s6、训练模块将所述训练数据集中所述漏洞和损坏的代码数据量作为深度学习模型输入,将确定所述修复指令和所述吻合度比对作为所述深度学习模型的隐层,将所述修复补丁作为深度学习模型的输出,进行模型训练;
13.步骤s7、验证模块将所述验证模块中的所述漏洞和损坏的代码数据量作为深度学习模型输入,将所述深度学习模型的输出与所述验证模块中的所述修复补丁进行比对,并根据所述验证数据集中的合格率确定所述深度学习模型是否训练完成;
14.步骤s8、调整模块在所述验证模块判定所述训练未完成时,对所述深度学习模型进行调参,植入模块在所述验证模块确定所述深度学习模型训练完成时,将所述深度学习模型植入该游戏对应的终端或游戏后台。
15.进一步地,在所述步骤s6中,当训练所述深度学习模型时,所述训练模块根据所述训练数据集的数据量确定所述深度学习模型的迭代次数c,所述训练模型根据所述吻合度确定所述深度学习模型的学习率p。
16.进一步地,在所述步骤s7中,当对所述深度学习进行验证时,比对所述深度学习模型的输出与所述验证模块中的所述修复补丁是否一致,若输出与所述修复补丁一致,则所述验证模块判定此次验证合格;若输出与所述修复补丁不一致,则所述验证模块判定此次验证不合格。
17.进一步地,在所述步骤s7中,当所述验证模块根据所述验证数据集中的合格率确定所述深度学习模型是否训练完成,计算验证合格次数r与总验证次数rz的比值ba,设定ba=r/rz,并根据该比值与预设比值ba0的比对结果确定所述深度学习模型是否训练完成,
18.若ba<ba0,则所述验证模块判定所述深度学习模型训练未完成;
19.若ba≥ba0,则所述验证模块判定所述深度学习模型训练完成。
20.进一步地,在所述步骤s8中,当所述验证模块判定所述深度学习模型训练未完成时,所述调整模块根据所述验证合格次数和验证总次数的次数差值d与预设验证次数差值的比对结果确定调整的所述深度学习模型的参数,
21.其中,所述调整模块设置有第一预设验证次数差值d1和第二预设验证次数差值d2,
22.当d≤d1时,所述调整模块判定对所述深度学习模型的学习率进行补偿;
23.当d1<d≤d2时,所述调整模块判定对所述深度学习模型的学习率进行调节;
24.当d>d2时,所述调整模块判定对所述深度学习模型的迭代次数进行修正。
25.进一步地,在所述步骤s8中,当所述调整模块判定对所述深度学习模型的学习率进行补偿时,计算所述次数差值和第一预设验证次数的第一次数比值bb,设定bb=d1/d,并根据该第一次数比值与预设次数比值的比对结果选取对应的补偿系数对所述学习率进行补偿,
26.其中,所述调整模块设有第一预设次数比值b1、第二预设次数比值b2、第一学习率补偿系数f1、第二学习率补偿系数f2以及第三学习率补偿系数f3,其中b1<b2,设定1<f1<f2<f3<1.5,
27.当bb≤b1时,所述调整模块选取第一学习率补偿系数f1对所述学习率进行补偿;
28.当b1<bb≤b2时,所述调整模块选取第二学习率补偿系数f2对所述学习率进行补偿
29.当bb>b2时,所述调整模块选取第三学习率补偿系数f3对所述学习率进行补偿
30.当所述调整模块选取第r学习率补偿系数fr对所述学习率进行补偿时,设定r=1,2,3,所述调整模块将补偿后的学习率设置为p1,设定p1=p
×
fr,所述训练模块以调节后的学习率进行模型训练。
31.进一步地,在所述步骤s8中,当所述调整模块判定对所述深度学习模型的学习率进行调节时,计算所述计算所述次数差值和第二预设验证次数的第二次数比值bc,设定bc=d2/d,并根据该第二次数比值和预设次数比值的比对结果选取对应的调节系数对所述学习率进行调节,
32.其中,所述调整模块还设有第一学习率调节系数ka1、第二学习率调节系数ka2以及第三学习率调节系数ka3,设定0.7<ka3<ka2<ka3<1,
33.当bc≤b1时,所述调整模块选取第一学习率调节系数ka1对所述学习率进行调节;
34.当b1<bc≤b2时,所述调整模块选取第二学习率调节系数ka2对所述学习率进行调节;
35.当bc>b2时,所述调整模块选取第三学习率调节系数ka3对所述学习率进行调节;
36.当所述调整模块选取第s学习率调节系数kas对所述学习率进行调节时,设定s=1,2,3,所述调整模块将调节后的学习率设置为p2,设定p2=p
×
kas,所述训练模块以调节后的学习率进行模型训练。
37.进一步地,在所述步骤s8中,当所述调整模块判定对所述深度学习模型的迭代次数进行修正时,计算所述计算所述次数差值和第二预设验证次数的第三次数比值bd,设定bd=d/d2,并根据该第二次数比值和预设次数比值的比对结果选取对应的修正系数对所述迭代次数进行修正,
38.其中,所述调整模块还设有第一迭代次数修正系数kn1、第二迭代次数修正系数kn1以及第三迭代次数修正系数kn3,设定1<kn1<kn2<kn3<2,
39.当bd≤b1时,所述调整模块选取第一迭代次数修正系数kn1对所述迭代次数进行修正;
40.当b1<bd≤b2时,所述调整模块元选取第二迭代次数修正系数kn2对所述迭代次数进行修正;
41.当b>b2时,所述调整模块选取第三迭代次数修正系数kn3对所述迭代次数进行修正;
42.当所述调整模块选取第j迭代次数修正系数knj对所述迭代次数进行调节时,设定j=1,2,3,所述调整模块将修正后的迭代次数设置为c1,设定c1=c
×
knj。
43.与现有技术相比,本发明的有益效果在于,本发明通过获取大量游戏内存在的漏洞及修复补丁相关数据,并通过建立深度学习模型将相关数据输入建立的模型中,训练一个可以自主修复游戏漏洞的深度学习模型,从而将该模型植入游戏后台或者计算机终端中,对游戏漏洞进行修复,从而实现无论是游戏未运行或运行过程,都能够对游戏漏洞进行自主修复,从而提高修复过程的效率。
44.进一步地,本发明通过验证模块将训练完成的模型进行验证,并计算验证模块对
该模型进行验证时的验证合格率,从而保证训练的模型是符合游戏漏洞修复的深度学习模型,提高了对漏洞修复过程的控制精准性,从而进一步提高了修复效率。
45.进一步地,本发明通过调整模块在验证模块验证训练后的模型为不合格模型时,通过设置预设验证次数差值,并根据计算的验证合格次数和验证总次数的差值与预设验证次数差值的比对结果确定对调整的该模型的参数,进一步提高了对漏洞修复过程的控制精准性,从而进一步提高了修复效率。
46.进一步地,本发明通过设置多个预设次数比值和学习率补偿系数,并根据计算的验证次数差值和预设验证次数差值的比值与多个预设比值的比对结果选取对应的补偿系数对模型超参的学习率进行补偿,进一步提高了对漏洞修复过程的控制精准性,从而进一步提高了修复效率。
47.进一步地,本发明通过设置多个预设次数比值和学习率调节系数,并根据计算的验证次数差值和预设验证次数差值的比值与多个预设比值的比对结果选取对应的调节系数对模型超参的学习率进行调节,进一步提高了对漏洞修复过程的控制精准性,从而进一步提高了修复效率。
48.进一步地,本发明通过设置多个预设次数比值和迭代次数修正系数,并根据计算的验证次数差值和预设验证次数差值的比值与多个预设比值的比对结果选取对应的修正系数对训练模型的迭代次数进行修正,进一步提高了对漏洞修复过程的控制精准性,从而进一步提高了修复效率。
附图说明
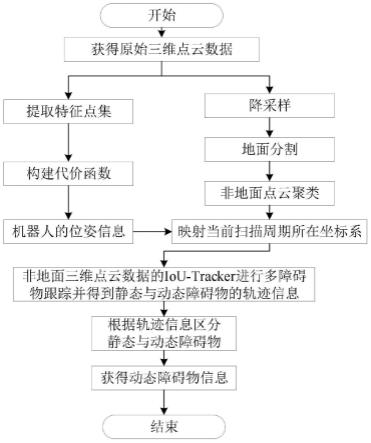
49.图1为本发明所述基于深度学习的游戏漏洞智能修复方法的流程图;
50.图2为本发明所述基于深度学习的游戏漏洞智能修复方法中模块的结构框图。
具体实施方式
51.为了使本发明的目的和优点更加清楚明白,下面结合实施例对本发明作进一步描述;应当理解,此处所描述的具体实施例仅仅用于解释本发明,并不用于限定本发明。
52.下面参照附图来描述本发明的优选实施方式。本领域技术人员应当理解的是,这些实施方式仅仅用于解释本发明的技术原理,并非在限制本发明的保护范围。
53.需要说明的是,在本发明的描述中,术语“上”、“下”、“左”、“右”、“内”、“外”等指示的方向或位置关系的术语是基于附图所示的方向或位置关系,这仅仅是为了便于描述,而不是指示或暗示所述装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
54.此外,还需要说明的是,在本发明的描述中,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域技术人员而言,可根据具体情况理解上述术语在本发明中的具体含义。
55.请参阅图1和2所示,图1为本发明所述基于深度学习的游戏漏洞智能修复方法的流程图;图2为本发明所述基于深度学习的游戏漏洞智能修复方法中模块的结构框图。
56.本发明实施例所述基于深度学习的游戏漏洞智能修复方法,包括:
57.步骤s1、数据采集模块采集游戏中出现的漏洞,数据分析模块对该漏洞进行分析,确定漏洞对应损坏的代码数量;
58.步骤s2、修复指令确定模块根据所述数据分析模块分析的漏洞及对应损坏的代码数量确定修复指令;
59.步骤s3、代码确定模块根据所述修复指令确定模块确定的所述修复指令确定所述漏洞对应的修复补丁;
60.步骤s4、数据比对模块在所述代码确定模块确定所述修复补丁完成时,将所述修复补丁中对应的代码与所述漏洞对应的代码进行比对,并确定修复补丁中代码与所述漏洞对应的原始代码的吻合度;
61.步骤s5、建模模块在所述数据比对模块确定所述吻合度达到预设阈值时,建立深度学习模型,并将若干所述漏洞、对应的损坏代码数量和修复补丁划分为训练数据集和验证数据集;
62.步骤s6、训练模块将所述训练数据集中所述漏洞和损坏的代码数据量作为深度学习模型输入,将确定所述修复指令和所述吻合度比对作为所述深度学习模型的隐层,将所述修复补丁作为深度学习模型的输出,进行模型训练;
63.步骤s7、验证模块将所述验证模块中的所述漏洞和损坏的代码数据量作为深度学习模型输入,将所述深度学习模型的输出与所述验证模块中的所述修复补丁进行比对,并根据所述验证数据集中的合格率确定所述深度学习模型是否训练完成;
64.步骤s8、调整模块在所述验证模块判定所述训练未完成时,对所述深度学习模型进行调参,植入模块在所述验证模块确定所述深度学习模型训练完成时,将所述深度学习模型植入该游戏对应的终端或游戏后台。
65.具体而言,在所述步骤s6中,当训练所述深度学习模型时,所述训练模块根据所述训练数据集的数据量确定所述深度学习模型的迭代次数c,所述训练模型根据所述吻合度确定所述深度学习模型的学习率p。
66.具体而言,在所述步骤s7中,当对所述深度学习进行验证时,比对所述深度学习模型的输出与所述验证模块中的所述修复补丁是否一致,若输出与所述修复补丁一致,则所述验证模块判定此次验证合格;若输出与所述修复补丁不一致,则所述验证模块判定此次验证不合格。
67.具体而言,在所述步骤s7中,当所述验证模块根据所述验证数据集中的合格率确定所述深度学习模型是否训练完成,计算验证合格次数r与总验证次数rz的比值ba,设定ba=r/rz,并根据该比值与预设比值ba0的比对结果确定所述深度学习模型是否训练完成,
68.若ba<ba0,则所述验证模块判定所述深度学习模型训练未完成;
69.若ba≥ba0,则所述验证模块判定所述深度学习模型训练完成。
70.具体而言,在所述步骤s8中,当所述验证模块判定所述深度学习模型训练未完成时,所述调整模块根据所述验证合格次数和验证总次数的次数差值d与预设验证次数差值的比对结果确定调整的所述深度学习模型的参数,
71.其中,所述调整模块设置有第一预设验证次数差值d1和第二预设验证次数差值d2,
72.当d≤d1时,所述调整模块判定对所述深度学习模型的学习率进行补偿;
73.当d1<d≤d2时,所述调整模块判定对所述深度学习模型的学习率进行调节;
74.当d>d2时,所述调整模块判定对所述深度学习模型的迭代次数进行修正。
75.具体而言,在所述步骤s8中,当所述调整模块判定对所述深度学习模型的学习率进行补偿时,计算所述次数差值和第一预设验证次数的第一次数比值bb,设定bb=d1/d,并根据该第一次数比值与预设次数比值的比对结果选取对应的补偿系数对所述学习率进行补偿,
76.其中,所述调整模块设有第一预设次数比值b1、第二预设次数比值b2、第一学习率补偿系数f1、第二学习率补偿系数f2以及第三学习率补偿系数f3,其中b1<b2,设定1<f1<f2<f3<1.5,
77.当bb≤b1时,所述调整模块选取第一学习率补偿系数f1对所述学习率进行补偿;
78.当b1<bb≤b2时,所述调整模块选取第二学习率补偿系数f2对所述学习率进行补偿
79.当bb>b2时,所述调整模块选取第三学习率补偿系数f3对所述学习率进行补偿
80.当所述调整模块选取第r学习率补偿系数fr对所述学习率进行补偿时,设定r=1,2,3,所述调整模块将补偿后的学习率设置为p1,设定p1=p
×
fr,所述训练模块以调节后的学习率进行模型训练。
81.具体而言,在所述步骤s8中,当所述调整模块判定对所述深度学习模型的学习率进行调节时,计算所述计算所述次数差值和第二预设验证次数的第二次数比值bc,设定bc=d2/d,并根据该第二次数比值和预设次数比值的比对结果选取对应的调节系数对所述学习率进行调节,
82.其中,所述调整模块还设有第一学习率调节系数ka1、第二学习率调节系数ka2以及第三学习率调节系数ka3,设定0.7<ka3<ka2<ka3<1,
83.当bc≤b1时,所述调整模块选取第一学习率调节系数ka1对所述学习率进行调节;
84.当b1<bc≤b2时,所述调整模块选取第二学习率调节系数ka2对所述学习率进行调节;
85.当bc>b2时,所述调整模块选取第三学习率调节系数ka3对所述学习率进行调节;
86.当所述调整模块选取第s学习率调节系数kas对所述学习率进行调节时,设定s=1,2,3,所述调整模块将调节后的学习率设置为p2,设定p2=p
×
kas,所述训练模块以调节后的学习率进行模型训练。
87.具体而言,在所述步骤s8中,当所述调整模块判定对所述深度学习模型的迭代次数进行修正时,计算所述计算所述次数差值和第二预设验证次数的第三次数比值bd,设定bd=d/d2,并根据该第二次数比值和预设次数比值的比对结果选取对应的修正系数对所述迭代次数进行修正,
88.其中,所述调整模块还设有第一迭代次数修正系数kn1、第二迭代次数修正系数kn1以及第三迭代次数修正系数kn3,设定1<kn1<kn2<kn3<2,
89.当bd≤b1时,所述调整模块选取第一迭代次数修正系数kn1对所述迭代次数进行修正;
90.当b1<bd≤b2时,所述调整模块元选取第二迭代次数修正系数kn2对所述迭代次
数进行修正;
91.当b>b2时,所述调整模块选取第三迭代次数修正系数kn3对所述迭代次数进行修正;
92.当所述调整模块选取第j迭代次数修正系数knj对所述迭代次数进行调节时,设定j=1,2,3,所述调整模块将修正后的迭代次数设置为c1,设定c1=c
×
knj。
93.至此,已经结合附图所示的优选实施方式描述了本发明的技术方案,但是,本领域技术人员容易理解的是,本发明的保护范围显然不局限于这些具体实施方式。在不偏离本发明的原理的前提下,本领域技术人员可以对相关技术特征做出等同的更改或替换,这些更改或替换之后的技术方案都将落入本发明的保护范围之内。
94.以上所述仅为本发明的优选实施例,并不用于限制本发明;对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。