1.本发明属于试验设计技术领域,特别是涉及一种响应曲面实验的变量筛选及扩充的方法、介质及电子设备。
背景技术:
2.试验设计(doe:design of experiments)是一门统计学学科分支。试验设计是这样的一种方法:它对各个参与试验的输入因子的众多可能的水平组合进行科学的选取,帮助实验者从众多的自变量中筛选出少数不多的重要自变量,然后对它们追加可以用于建模预告的响应曲面设计,最终以最少的试验次数和最短的时间获得实验者期望的结果。
3.doe已经有近百年的发展历史。变量筛选方法有许多种类[dean 2006]。它们都各自有一定的假定前提条件。其中重要的筛选方法的历史演变是从经典的两水平部分析因筛选设计[box 1961]发展到三水平确定性筛选设计(dsd:definitive screening design)[jones 2011]。响应曲面设计也从经典的响应曲面设计[box 2005]发展到响应曲面的最优设计[goos 2011]和均匀设计[方开泰2019]。
[0004]
两水平部分析因筛选设计有多种选择。目前的两水平部分析因筛选设计的最佳选择是分辨度iv的筛选设计因为其主效应与众多的二阶交互作用(简称交互作用)不混淆。在三阶交互作用常常可以忽略时该筛选设计是一个最佳的选择。然而它的问题是两水平析因设计无法检测估计存在的平方项(也称二次项)。图1演示了一个变量例子,其主效应很弱(响应变量y从x=-1变化到x= 1时的增量2的一半,即2/2=1,为主效应参数的系数大小。),与其他变量的主效应比较很有可能会在筛选试验中被淘汰掉即使它是统计上显著的。但是其二阶多项式在该范围内对响应变量是有显著效应的(其在这范围内的最大值为11)。按理说该变量在变量筛选试验中应该被保留下来。由于两水平部分析因筛选设计无法估计出这很有价值的二次项,就会因为其主效应弱而在变量筛选过程中被淘汰。
[0005]
图1中,该变量的二次多项式公式为:y=-10x2 x 11,后来的三水平确定性筛选设计(dsd)弥补了两水平析因筛选设计的这个缺点,三水平的设计可以将二次项同时纳入检测估计范围。然而当效应稀疏程度不够高(即可能活跃的模型项数量比较高)时,二次项的检测估计效果会大打折扣,常常会给出面目全非的二次项的估计结果。
[0006]
两水平部分析因筛选设计和三水平确定性筛选设计还有一个共同的问题,就是它们在筛选出重要性排在前面的少数自变量后续的相应这些重要变量的响应曲面的设计时无法回收利用前面的筛选设计的试验数据,即无法将原有的筛选设计扩充成一个新的响应曲面设计来实现二阶多项式建模,它们只能重新设计一个全新的响应曲面设计来完成后续的建模优化来找到实验者所期望的结果及试验条件。
技术实现要素:
[0007]
鉴于以上所述现有技术的缺点,本发明的目的在于提供一种响应曲面实验的变量筛选及扩充的方法、介质及电子设备,用于解决现有技术中变量筛选方法无法有效为响应
曲面实验筛选有效变量的技术问题。
[0008]
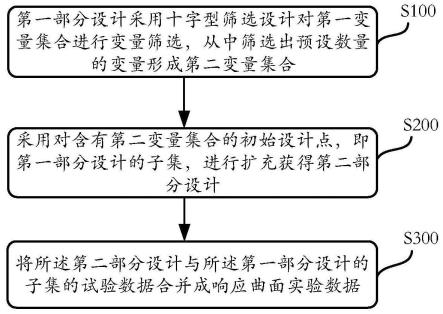
为实现上述目的及其他相关目的,本发明的实施例提供一种响应曲面实验的变量筛选及扩充的方法,包括:第一部分设计采用十字型筛选设计对第一变量集合进行变量筛选,从中筛选出预设数量的变量形成第二变量集合;采用对含有第二变量集合的初始设计点,即第一部分设计的子集,进行扩充获得第二部分设计;将所述第二部分设计与所述第一部分设计的子集的试验数据合并成响应曲面实验数据。
[0009]
于本技术的一实施例中,所述十字型筛选方式为在编码后的每个变量的设计水平为-1和 1,再加上两个重复的中心点。
[0010]
于本技术的一实施例中,编码后的变量的表达形式为:于本技术的一实施例中,编码后的变量的表达形式为:其中,zi为第i个编码后的变量,xi为第i个变量,average为第i个变量范围均值,lli为第i个变量范围的最小值,hli为第i个变量范围的最大值。
[0011]
于本技术的一实施例中,所述采用十字型筛选方式筛选变量的筛选次数为2k 2;其中,k为待筛选变量总数。
[0012]
于本技术的一实施例中,从所述第一变量集合中根据主效应大小或二次效应大小来筛选出预设数量的变量形成第二变量集合;对含有第二变量集合的初始试验进行扩充,所述扩充采用只含有所有交互作用模型项的最优设计;所述响应曲面实验的总次数大于等于2m 2 m(m-1)/2 1,m为预设数量的第二变量集合的变量个数。
[0013]
于本技术的一实施例中,还包括:在采用十字型筛选方式筛选变量中,若某变量可能的次数大于2,小于等于4,则在该变量编码后添加-0.5与 0.5两个水平。
[0014]
于本技术的一实施例中,还包括:在采用十字型筛选方式筛选变量中,若变量存在分类变量,则先筛选分类变量,再筛选连续变量。
[0015]
于本技术的一实施例中,在所述曲面实验中,采用最小二乘法对数据进行回归分析建模。
[0016]
本技术的实施例还提供一种存储介质,存储有程序指令,所述程序指令被执行时实现如上所述的响应曲面实验的变量筛选及扩充的方法的步骤。
[0017]
本技术的实施例还提供一种电子设备,包括处理器和存储器,所述存储器存储有程序指令,所述处理器运行程序指令实现如上所述的响应曲面实验的变量筛选及扩充的方法的步骤。
[0018]
如上所述,本发明的响应曲面实验的变量筛选及扩充的方法、介质及电子设备,具有以下有益效果:
[0019]
本发明使用十字型筛选方式来做变量筛选,结合后续的利用扩充设计来生成响应曲面设计,该十字型筛选设计不但可以侦测主效应而且可以同时侦测估计二次项,完全不受效应稀疏程度的约束,而且在完成精确的变量筛选之后还可以利用已有的筛选设计数据对之进行扩充设计形成一个响应曲面实验设计。
附图说明
[0020]
图1显示为现有技术的方法根据主效应大小或者二次效应大小来筛选变量的原理
示例图。
[0021]
图2显示为本发明的响应曲面实验的变量筛选及扩充的方法的流程示意图。
[0022]
图3显示为本发明的响应曲面实验的变量筛选及扩充的方法中两个变量的十字型筛选方式示意图。
[0023]
图4显示为本发明的响应曲面实验的变量筛选及扩充的方法中三个变量的十字型筛选方式示意图。
[0024]
图5显示为本发明的电子设备的原理框图。
具体实施方式
[0025]
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
[0026]
需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,遂图式中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。
[0027]
本实施例的目的在于提供一种响应曲面实验的变量筛选及扩充的方法、介质及电子设备,用于解决现有技术中变量筛选方法无法有效为响应曲面实验筛选有效变量的技术问题。
[0028]
本实施例使用十字型筛选方式来做变量筛选,结合后续的利用扩充设计来生成响应曲面设计。与背景技术中的两水平部分析因筛选设计和三水平确定性筛选设计相比它有独特的优势,即它不但可以侦测主效应而且可以同时侦测估计二次项,完全不受效应稀疏程度的约束。在完成精确的变量筛选之后还可以利用已有的筛选设计数据对之进行扩充设计形成一个响应曲面设计。
[0029]
以下将详细阐述本实施例的响应曲面实验的变量筛选及扩充的方法、介质及电子设备的原理及实施方式,使本领域技术人员不需要创造性劳动即可理解本发明的响应曲面实验的变量筛选及扩充的方法、介质及电子设备。
[0030]
实施例1
[0031]
如图2所示,本实施例提供一种响应曲面实验的变量筛选及扩充的方法,是一种用于响应曲面实验序贯设计中的变量筛选及扩充的方法,包括:
[0032]
步骤s100,第一部分设计采用十字型筛选设计对第一变量集合进行变量筛选,从中筛选出预设数量的变量形成第二变量集合;
[0033]
步骤s200,采用对含有第二变量集合的初始设计点,即第一部分设计的子集,进行扩充获得第二部分设计;
[0034]
步骤s300,将所述第二部分设计与所述第一部分设计的子集的试验数据合并成响应曲面实验数据。
[0035]
本实施例提供的响应曲面实验的变量筛选及扩充的方法是一种全新型的变量筛
选设计方法,以及一种新型的后续扩充设计来获得响应曲面试验设计的方法。以下对本实施例的用于响应曲面实验的变量筛选及扩充的方法的步骤s100至步骤s300进行详细说明。
[0036]
步骤s100,第一部分设计采用十字型筛选设计对第一变量集合进行变量筛选,从中筛选出预设数量的变量形成第二变量集合。
[0037]
本实施例中的十字型筛选方式是一个全新型的筛选设计,可以精准的确定所有的主效应和二次效应,变量筛选效果高效、可靠,而且完全不受效应稀疏程度的约束。
[0038]
于本实施例中,编码后的变量的表达形式为:其中,zi为第i个编码后的变量,xi为第i个变量,average为第i个变量范围均值,lli为第i个变量范围的最小值,hli为第i个变量范围的最大值。
[0039]
假设有k个自变量(xi,i=1,2,3,
…
,k)需要从中筛选出少部分重要变量。k个变量各自的范围分别为为lli,hli。
[0040]
于本实施例中,所述十字型筛选方式为在编码后的每个变量的设计水平为-1和 1,再加上两个重复的中心点。图3和图4分别为两个变量和三个变量的十字型筛选方式。图3中为两个变量(编码后的z1和z2)的十字型筛选方式(含重复两次的中心点),图3中为三个变量(编码后的z1,z2和z3)的十字型筛选方式(共享重复两次的中心点)。
[0041]
于本实施例中,所述采用十字型筛选方式筛选变量的筛选次数为2k 2;其中,k为待筛选变量总数。
[0042]
也就是说,由于所有的变量都共享同样的两次重复的中心点,总的十字型筛选的次数为2k 2。
[0043]
这种设计在析因设计的历史中被遗弃是因为与析因设计相比它完全无法侦测交互作用,换句话说任何可能存在的二阶交互作用对十字型筛选方式点的数据没有任何影响。这是因为改变zi时其他zj(j≠i)都处在0的水平,于是zi与其他变量zj(j≠i)之间的交互作用在实验中的读值都为0。表1以k=4为例演示十字型筛选方式中的主效应、二次项与交互作用没有任何混淆关系(别名矩阵中元素全为零)。
[0044]
表1:4个变量的十字型筛选方式的主效应、二次项与所有交互作用的别名矩阵
[0045][0046]
下面的表2显示其主效应和二次项之间也没有任何混淆。
[0047]
表2:主效应和二次项之间别名矩阵
[0048][0049]
表2的矩阵元素(或称矩阵系数)中所有的1都是各效应的自己和自己的别名关系。而主效应和其他主效应,与所有的二次项的别名矩阵系数都为0。二次项与其他所有二次项的别名矩阵系数也都为0。
[0050]
然而变量筛选只要根据主效应(主效应足够大)或/和二次效应(试验范围内的最大值足够大)来挑选重要的自变量,交互作用的情况不去考虑。于是十字型筛选方式就是一种最佳的选择。
[0051]
十字型筛选方式的数据分析可以使用标准的最小二乘法对所有主效应和二次项,包括截距进行估计以及估计值显著性的统计检验,不需要使用像分析三水平确定性筛选设计数据那样复杂的分析方法。
[0052]
于本实施例中,还包括:在采用十字型筛选方式筛选变量中,若某变量可能的次数大于2,小于等于4,则在该变量编码后添加-0.5与 0.5水平数(或更多水平数)来精准确定其高阶的多项式,并不需要重新设计该十字型筛选方式。该五水平可以拟合高达四次多项式。后续也可以在这种十字型筛选方式基础上进行相应的扩充设计。
[0053]
于本实施例中,还包括:在采用十字型筛选方式筛选变量中,若变量存在分类变量,则先筛选分类变量,再筛选连续变量。
[0054]
即本实施例中,所述十字型筛选方式可适用于混有分类变量的变量筛选试验设计。在初始的变量筛选中先单独做分类变量(在分类变量的不同水平都做试验,与此同时所有其他的连续变量都固定在它们的中心点,其他的分类变量都固定在高或低水平)。分类变量筛选完后再为连续变量设计一个十字型筛选方式(此时所有的分类变量设置在响应变量所期望的水平。)。在筛选完成后的扩充设计中除了需要考虑原来的连续变量之间的交互作用,还需要考虑分类变量之间的交互作用,以及分类变量与连续变量的交互作用。
[0055]
步骤s200,采用对含有第二变量集合的初始设计点,即第一部分设计的子集,进行扩充获得第二部分设计。
[0056]
在采用第二变量集合设计响应曲面设计时传统的做法是设计一个全新的响应曲面设计。本发明采用对含有第二变量集合的初始试验(第一部分设计的子集)进行扩充的方法,扩充后新添的部分形成第二部分设计;将所述第二部分设计的实验数据与所述第一部分设计的子集的试验数据整合,以用于响应曲面实验。
[0057]
本实施例中在十字型筛选方式基础上使用扩充设计来生成响应曲面设计。扩充方法可以有多种。其中一个选择是使用只含有交互作用模型项的最优设计来进行扩充,生成一个性质优良同时非常经济的响应曲面设计。也可以选用超饱和均匀设计来进一步节省试验设计次数。如果效应稀疏程度不够,在rsm数据分析中失败时可以使用扩充均匀设计进行
下一个新的扩充设计以获得新的规模更大的响应曲面设计以及更高精度的建模。
[0058]
具体地,于本实施例中,所述从所述第一变量集合中根据主效应大小或二次效应大小来筛选出预设数量的变量形成第二变量集合。对含有第二变量集合的初始试验(第一部分设计的子集)进行扩充。扩充方法有多种,其中一种非常经济的扩充采用只含有所有交互作用模型项的最优设计;所述响应曲面实验的总次数(所述的第一部分设计的子集加上所述第二部分设计)大于等于2m 2 m(m-1)/2 1,m为预设数量的第二变量集合的变量个数。
[0059]
在对多个变量使用十字型筛选方式筛选出一部分重要变量之后,下一步是扩充已有的十字型筛选方式数据来获得响应曲面设计。如果从k个变量筛选出一半左右的有显著主效应或/和二次项的变量(例如m~k/2个变量),一种扩充方法是利用最优设计。它是为所有的这m个变量的二阶交互作用(一共m(m-1)/2个交互作用),加上一个截距参数的模型进行设计,试验次数建议为饱和的设计(m(m-1)/2 1)或者更多的试验次数。然后将这些设计点添加到原来十字型筛选方式中的m个变量的列中。
[0060]
在收集了扩充部分的试验数据之后,整体的数据(总的试验次数为(2k 2) m(m-1)/2 1)为二阶响应曲面设计的数据,同样可以使用标准的最小二乘法进行回归分析建模。
[0061]
假定初始的变量个数k=2m,经过十字型筛选方式后筛选出m个变量,然后进行扩充设计,添加(m(m-1)/2 1次试验。在完成响应曲面建模后总共用去的试验次数为2k 2 (m(m-1)/2 1=m2/2-7m/2 3.该序贯试验设计总的试验次数上要比背景技术中的两种相应的序贯设计方法要经济得多。表3显示了十字型筛选方式及其扩充响应曲面设计的序贯试验的试验次数与背景技术中的两种序贯试验总的试验次数的比较。为了比较方便,这里假定初始要做变量筛选的变量个数为k,筛选出k/2(k为偶数时)或(k 1)/2(k为奇数时)个变量用来设计后面的响应曲面设计。
[0062]
表3:三种方法的总试验次数的比较
[0063][0064]
十字型筛选方式,二水平筛选设计以及dsd设计都包含两个重复的中心点。这三种筛选设计的扩充设计中也都添加了2个额外的重复中心点。这样可以应对可能的区组效应的存在。
[0065]
注意表3中的背景技术中的两种序贯设计方法不仅总的设计次数高,而且变量筛选效果在许多情形下低效。两水平部分析因筛选设计只能侦探主效应,当二次项强但其主效应弱的变量会被错误地丢弃。三水平确定性筛选设计虽然有时可以同时估计二次项,但是它要求效应稀疏程度足够高,这在现实中常常不能满足,而且一旦不满足,二次项的估计就会完全失效。但是十字型筛选方式没有这些问题。它不要求效应稀疏,可以准确估计所有的显著的主效应和二次项。
[0066]
步骤s300,第一部分设计采用十字型筛选设计对第一变量集合进行变量筛选,从中筛选出预设数量的变量形成第二变量集合。这些先后的设计组合成为响应曲面实验的序贯设计。
[0067]
本实施例采用对含有第二变量集合的初始试验(第一部分设计的子集)进行扩充的方法,扩充后新添的部分形成第二部分设计;将所述第二部分设计的实验数据与所述第一部分设计的子集的试验数据整合,以用于响应曲面实验。
[0068]
于本实施例中,在所述响应曲面实验中,采用最小二乘法对数据进行回归分析建模。
[0069]
本实施例大大提高了变量筛选的能力,其序贯的扩充的响应曲面设计与背景技术的两种序贯设计比较可以大大节省总的试验次数。其数据分析方法也是最简单的最小二乘法,远比背景技术中的两种序贯设计的数据分析方法简单。
[0070]
本实施例的有益效果可以通过一个具体的示例来演示。
[0071]
假定要筛选的变量个数为k=10(编码后的z1,z2,z3,
…
,z
10
)目标是筛选出5个对响应变量y有重要影响的变量。假定一个模拟模型为:
[0072][0073]
其中random normal(0,1)是均值为0,方差为1的标准正态分布的随机误差。用来模拟实验中的重复性误差。模型中一共有4个交互作用项。z1只有主效应,没有二次项。z4这个变量没有主效应,只有二次项。z
6-z
10
都不活跃,它们的系数都为0.
[0074]
表4为该10个变量的含试验数据的十字型筛选设计表。
[0075]
表4:编码后的十个变量的十字型筛选方式
[0076][0077]
表4中当一个变量从-1变化到 1时其他变量都在中心位置0.第一、第二行为十个变量共享的重复两次的中心点。相对每个变量,这是一个三水平的设计,也可以分别对其进行回归分析获得二次多项式的系数估计。表中y为前面的含随机变量的模拟模型产生的模拟实验数据。
[0078]
以下表5为该十字型筛选方式的别名矩阵。
[0079]
表5:10个连续变量的十字型筛选方式的别名矩阵
[0080][0081]
从表5可见,主效应与其他主效应没有混淆,主效应与二次效应没有混淆,二次项与其他二次项也没有任何混淆。
[0082]
本实施例使用的分析模型只有该十个变量的主效应和二次项。表4的数据使用最小二乘法分析的结果如表6所示:
[0083]
表6:使用标准最小二乘法估计的主效应与二次项的估计值
[0084][0085]
z4的主效应系数为0,该主效应被剔除,但是它的二次项被准确的估计出而且是很强的二次项,变量z4需要保留下来。与模拟模型比较,可以看到虽然不能估计任何交互作用(也不需要估计任何交互作用)但是精确地估计出了所有主效应和二次项的系数,可靠地完成了变量筛选的任务。
[0086]
如果使用背景技术中的两水平部分析因筛选设计,下面会看到它会错过变量z1和z4。这里使用分辨度iv的试验次数为24,再加2个重复的中心点的部分析因筛选设计。如表7所示。
[0087]
表7:编码后的十个变量的两水平部分筛选设计
[0088][0089]
表7中,第14行和第16行为两次重复的中心点。其中y为前面的含随机变量的模拟模型产生的模拟实验数据。
[0090]
筛选后的参数估计值如表8所示。
[0091]
表8:筛选后的参数估计值
[0092][0093]
筛选出的效应的参数估计值列在表8中。表8里估计出的5个交互作用会与其他交互作用混淆,需要进一步分析,因为别名的关系,其分析结果也不能保证以上5个交互作用是正确的(实际上它们的估计在变量筛选中并不需要)。然而筛选出的变量只留下z2,z3和z5。
[0094]
z1的对比值虽然比z2小,但是很相近。由于误差相对较大的关系,z1的效应在统计上不够显著被剔除了。
[0095]
另外,在获得以上简化模型之后再把两个重复的中心点放回去进行失拟检验时的结果竟然是没有失拟现象(其p值=0.8527,远远大于0.05!)。见表9。
[0096]
表9:添加两个重复的中心点后的失拟检验
[0097][0098]
表9中,其p值0.8627指示没有失拟现象。
[0099]
然而真实模型(即所述模拟模型)中却有好几个很强的二次项。变量筛选结果是筛选出z2,z3和z5漏掉了z1和z4。从这里可以看到这种筛选设计远比十字型筛选方式低效。
[0100]
下面来看背景技术中的第二个筛选方法,三水平确定性筛选设计(dsd)。
[0101]
表9:10个变量的三水平确定性筛选设计
[0102][0103]
表9中y为前面的含随机变量的模拟模型产生的模拟实验数据。
[0104]
表10:使用这个设计特有的“有效模型选择法”分析试验数据的结果
[0105][0106]
可以看出它只筛选出z1,z2,z3和z5这四个变量。真实模型中的4个二次项竟然一个都没有侦探到,更别谈精确的估计值!估计出的交互作用也与真实模型中的交互作用竟然没有一个是相同的。其最后变量筛选的结果是找到了z1,z2,z3和z5这四个变量,缺失了z4。在效应稀疏程度比这里假设的模拟模型更低时,这种dsd筛选设计的变量筛选效果会变得更加低效。
[0107]
以上示例显示,与背景技术中的两个序贯方法相比,本实施例的十字型筛选方式是一个非常强而高效的筛选设计,它完全不受效应稀疏程度的影响。它可以侦探和准确估计所有变量的主效应和二次项。它是目前文献中的任何变量筛选方法无法比拟的。
[0108]
下面开始展示如何回收利用这些十字型筛选方式筛选出的5个变量的已有的数据进行扩充设计来得到高质量的响应曲面设计。
[0109]
本实施例中提到扩充设计的一个选择是使用只含有交互作用模型项的最优设计来进行扩充。本示例演示使用已知的最优设计方法指定只有所有二阶交互作用(5*(5-1)/2 1=11)的模型(含截距)进行扩充设计。所获得的设计添加至原设计表的第23行到第33行,再添加两个重复的中心点到第34和35行,同时添加一个区组变量在第二列,将新添加的扩充设计的区组水平设置为2。如表11所示。
[0110]
表11:将原有十字型筛选方式的筛选出的5个变量进行扩充后并添加区组因子后的设计表格(含y列中收集的新添加的设计的试验数据)
[0111][0112]
表11:将原有十字型筛选方式的筛选出的5个变量进行扩充后并添加区组因子后的设计表格(含y列中收集的新添加的设计的试验数据)。行13至行22是被剔除的5个变量z
6-z
10
所对应的十字型筛选设计,在这里已被排除和隐藏,不影响后面的分析。
[0113]
下面的表12是表十一的扩充设计(除去第13行到第22行)的别名矩阵。它显示了非常好的性质。矩阵元素除对角的自身关系系数为1之外,其他元素全为0,表示没有任何混淆。
[0114]
表12:扩充后的rsm设计的别名矩阵(含区组)
[0115][0116]
在对表11的数据使用标准最小二乘法回归建模后得到的参数估计值(见表13)显示它抓住了模拟模型的所有模型项,而且系数估计值很靠近真实模型中的系数。
[0117]
表13:表十一数据分析后的参数估计值
[0118][0119]
相形之下,背景技术中的两水平部分析因筛选设计与三水平确定性筛选设计因为筛选效果不好,缺失了一些重要的变量,即使后续使用新的响应曲面设计,其结局会有可能是找到的最佳结果离目标还有一段距离,需要添加前面漏掉的重要变量z1和z4进来重新做响应曲面设计。这样的成本与时间的代价太大了。就算第一次新的响应曲面设计找到的最佳结果满足了目标,但是因为它无法基于原有筛选设计进行扩充,所使用的新的响应曲面设计无疑是大大增加了成本(见表3)。
[0120]
在混合有分类变量的筛选设计,可以照样扩展只含连续变量的十字型筛选方式(见发明点三)。这样的新设计方法保证了普适性。
[0121]
此十字型筛选方式后续的扩充设计在变量数较高(例如筛选后要使用8个或者8个变量做响应曲面设计建模)时,总的交互作用的数目将会随着变量的个数指数般地快速上升。这时可以有一个选项,就是采用超饱和均匀设计来设计一个试验次数不是很高的扩充设计。如果这个超饱和均匀设计的实验数据分析结果表明试验次数过低,可以对该设计采用扩充均匀设计法进行进一步扩充,以达到最终目的。
[0122]
随着科学与工程的迅速发展,科学、经济的试验设计正在被越来越多的广大领域的科技工程人员所采用。本发明中的这个新型的精确的变量筛选及其后续扩充响应曲面设计的一个非常精准而经济的序贯设计势必将成为他们在众多的试验设计方法中的首选。
[0123]
实施例2
[0124]
如图5所示,本实施例提供一种电子设备101,所述电子设备101包括:处理器1001及存储器1002;所述存储器1002用于存储计算机程序;所述处理器1001用于执行所述存储器1002存储的计算机程序,以使所述电子设备101执行如实施例1中响应曲面实验的变量筛选及扩充的方法的步骤。由于响应曲面实验的变量筛选及扩充的方法的步骤的具体实施过程已经在实施例1中进行了详细说明,在此不再赘述。
[0125]
处理器1001为(central processing unit,中央处理器)。存储器1002通过系统总线与处理器1001连接并完成相互间的通信,存储器1002用于存储计算机程序,处理器1001用于运行计算机程序,以使所述处理器1001执行所述的响应曲面实验的变量筛选及扩充的方法。存储器1002可能包含随机存取存储器(random access memory,简称ram),也可能还包括非易失性存储器(non-volatile memory),例如至少一个磁盘存储器。
[0126]
此外,本实施例还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器1001执行时实现实施例1中所述的响应曲面实验的变量筛选及扩充的方法中的步骤。实施例1已经对所述响应曲面实验的变量筛选及扩充的方法进行了详细说明,在此不再赘述。
[0127]
综上所述,本发明使用十字型筛选方式来做变量筛选,结合后续的利用扩充设计来生成响应曲面设计,不但可以侦测主效应而且可以同时侦测估计二次项,完全不受效应稀疏程度的约束,而且在完成精确的变量筛选之后还可以利用已有的筛选设计数据对之进行扩充设计形成一个响应曲面实验的曲面设计。所以,本发明有效克服了现有技术中的种种缺点而具高度产业利用价值。
[0128]
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。