一种基于双耳效应的声源方位角客观评价方法
一、技术领域
1.本发明涉及一种在房间内评估声源方位角的客观评价方法,尤其是涉及利用回归决策树方法训练提取的客观参量建立声源方位角的评估模型。该模型的评价结果均方根误差相对于其它模型更低,能在室内混响的干扰下更准确地预测声源的方位角。
二、
背景技术:
2.人类听觉系统可以对声音的空间属性产生一系列主观感觉,包括声源的位置、距离、宽度,混响度等等。本专利发明主要涉及在室内环境下,声源位置的方向定位评价问题。研究表明,在自由场情况下,对单一声源的方向定位因素主要包括双耳效应、耳廓效应等,其中前者主要用于水平方向的定位,后者用于垂直方向定位,在这些效应背后是一些可以测量的客观描述指标。对声源方位角的客观评估方法主要是通过由物理可测量的声压级提取例如itd(interaural time difference,双耳时间差),ild(interaural level difference,双耳声压差)等是由于双耳效应的存在而形成的客观评价指标,在水平面的方位角定位中表现出较优的评价效果。
3.现有的声源方位角评估参量主要有:双耳时间差(itd)和双耳声级差(ild),用于描述左右耳信号之间的相位差和振幅差;双耳互相关(iacc)、双耳群时延(igd)、声像宽度(asw),由左右耳信号互相关分析(ccf)提取得到,用于描述左右耳信号的相关性、信号包络群时延和主观感知声像宽度。在室内,由于有混响的存在,左右耳原始信号互相关分析提取的参量往往会失效,有工作者提出了9频带平均双耳互相关(iacc_9band)和它的指数变换式(iacc_9band),可用于描述与iacc和asw类似的物理意义,抗混响干扰能力更强(jackson,et al.estimates of perceived spatial quality across the listening area,audio engineering society conference:38th international conference:sound quality evaluation.audio engineering society,2010.).
4.现有的声源方位角评估方法主要将不同频率处的双耳时间差和双耳声压差作为输入,通过cnn和随机森林等深度学习算法训练评估模型,该类方法存在极大数据量冗余,且对服务器算力要求高,难以满足在高精度条件下,快速、便利地评估声源方位角需求,且容易受到评估环境的噪声和室内混响的干扰,对声源定位精度影响较大。
三、
技术实现要素:
5.1、发明目的:本发明提出一种用于预测声源方位角的客观评价方法。该方法性能好,预测方位角误差低,且具有较高的运算效率。
6.2、技术方案:为实现以上发明目的,本发明所述的基于双耳效应声源方位角客观评价方法是通过以下技术方案实现的:
7.(1)在声源位于不同方位角处,计算12种客观参量值:双耳时间差(itd)、双耳声压差(ild)、双耳互相关(iacc)、双耳群延时(igd)、声像宽度(asw)、双耳时间差频域方差(var_itd)、双耳声压差频域方差(var_ild)、9频带平均双耳互相关(iacc_9band)、iacc_
9band指数变换参量(iacc_9band)、9频带平均双耳群延时(igd_9band)、双耳信号均方根(rms)、双耳信号均方根误差(rmse)。参量具体计算公式和方法如下:
[0008][0009][0010]
式(1)(2)中ω为角频率,和分别代表左右耳输入信号在第n帧的短时傅里叶变换。取伽马通(gammatone)滤波器——模拟人耳耳蜗频率分解特点的滤波器模型——在150-8000hz的频率范围内生成22个频带的中心频率,并提取这些频率对应的itd、ild值,根据定位能力分配加权系数并求加权平均,得到第n帧的ild和itd值。var_itd和var_ild均由itd和ild对频域直接求方差得到。
[0011]
iacc、igd和asw由双耳信号的互相关函数(ccf)提取得到,iacc为ccf的峰值,igd为ccf峰值时刻点时延,asw以ccf的主峰达峰值95%处峰宽wiacc近似。考虑到小空间声波强反射的干扰,评估参量还引入了iacc_9band、iacc_9band和igd_9band。将左右耳信号分别通过9个中心频率跨越560-2160hz频带的滤波器组,对每组左右耳信号滤波后求互相关,提取的参量取平均得到结果,计算公式见式(3)(4)(5),式中t为时间,m标记频带:
[0012][0013]
iacc_9band=exp(-3.13iacc
9band
)(4)
[0014][0015]
双耳信号均方根(rms)和双耳信号均方根误差(rmse)计算公式:
[0016][0017][0018]
(2)构建声源方位角变化时的参量数据集,该数据集具有12个特征量,将该数据集作为训练集输入回归学习器训练模型,预测响应为理论方位角,回归决策树训练将最小叶大小设为4,同时采用交叉验证方式来防止过拟合,设置交叉验证折数为5折。
[0019]
(3)为了获得最优的预测性能:在建模过程中可以对12个特征进行挑选匹配成最优组合,基本参量选定为itd、ild、var_itd、var_ild、rms、rmse,另6个参量分为两组:a.iacc、igd、asw和b.iacc_9band、igd_9band和iacc_9band,这是由于a和b描述的物理特征是近似的;另外,在回归决策树预测误差较大情况下,说明声源方位角和客观参量的相关性不够强,此时可选用集成算法训练预测模型,集成决策树最小叶大小设为8,学习器数量为30。
[0020]
本发明在不同环境下的训练均方根误差和测试准确度(容错角设为10
°
)如表1、2、3所示。表中除本发明中采用模型外,另设对照组只选用基本特征itd和ild预测模型,对比
可看出本发明对声源方位角的预测性能在不同环境中相对于传统方法均有提升:
[0021]
表1 本发明于仿真试听室数据集训练不同模型的均方根误差和测试准确度
[0022][0023][0024]
表2 本发明于实测试听室数据集训练不同模型的均方根误差和测试准确度
[0025][0026]
表3 本发明于实测车内数据集训练不同模型的均方根误差和测试准确度
[0027][0028]
其中表1的数据集为由镜像源模型和相关hrtf数据库构建的brir室内混响仿真数据集得到,表2、表3的brir数据为实际测量得到,表2的brir数据在长宽高分别为(7.467m,5.499m,3.220m)、平均混响时间0.3s是长方体形试听室实际测得,方位角取值
±
90
°
、
±
60
°
、
±
40
°
、
±
30
°
、
±
20
°
、
±
10
°
、0
°
;表3 brir数据在汽车座舱内实际测得,方位角取值-30
°
、0
°
、30
°
、60
°
、90
°
。实验主要使用仿真人工头、音箱、蓝牙音箱和专业数据采集系统进行数据采集。
[0029]
3、有益效果:本发明与现有技术相比,其显著优点在于:(1)利用决策树和装袋集成算法训练模型,可调节灵活度很高,计算速度快、效率高;(2)对不同环境的适应性强,在不同大小的房间内评估声源方位角均有优良的预测效果;(3)对噪音抗干扰能力强,有优良
的鲁棒性。
四、附图说明
[0030]
图1是本发明模型预测方位角性能直观图
[0031]
图2是本发明模型在不同容错角区间预测准确率变化图,图中mymodel标识为本发明提出的模型
[0032]
图3是本发明模型在不同信噪比区间预测准确率变化图,图中mymodel标识为本发明提出的模型
[0033]
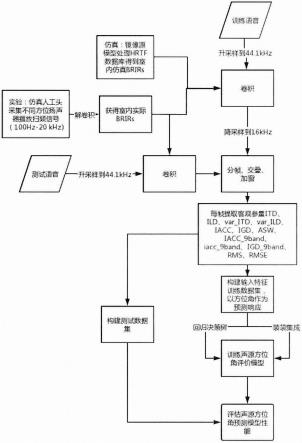
图4是本发明模型的训练-测试流程图
[0034]
五、具体实施方法
[0035]
下面以试听室采集数据并由其提取客观参量训练模型来评估方位角的流程对本发明的具体实施方法进行说明。
[0036]
首先通过专业工具驱动音箱扬声器发出扫频信号,100hz-20khz的扫频信号在1/12倍频程每个频点进行扫频,设定每个频点到达预定数值时即跳入下一个频点信号,每个频点的最长扫描时间不超过800ms,共记录60s长,仿真人头采集得双耳信号数据对原信号求解卷积(频域相除后求逆傅里叶变换)可以得到双耳房间脉冲响应(brir),brir采样率fs为44.1khz。
[0037]
下一步取标准语音库中的纯净语音升采样到44.1khz,并与左右耳brir分别卷积,对卷积后语音信号降采样到16khz作为训练语音,并对另一段纯净语音作同样处理作为测试语音。
[0038]
进一步的,对训练语音进行分帧处理,分帧帧长取512点,时长32ms,帧移设为128点,重叠率3/4,为了防止分帧导致的频谱泄露,需对每帧汉宁窗加权。除iacc和与iacc相关的asw(声源宽度)、igd(双耳群延时)需要用较长信号(512点)得到更为准确的相关性分析量,其余客观量的提取采用子帧操作并平均平滑处理的方式,子帧的长度为128点,时长为8ms,帧移63点,每帧被分为7个子帧提取相应参量后平滑,采用这种处理方式是因为语音的随机性较强,平滑处理可以在一定程度上避免这种随机性。
[0039]
对每帧语音信号提取前述客观评价参量,构建训练数据集和理论响应数据集作为输入和输出导入回归学习器中训练模型,已验证决策精细树和装袋集成具有较好的预测效果,且运算效率高,模型训练时间可控制在5s以内。导出模型。
[0040]
下一步用测试语音卷积模型环境的双耳房间脉冲响应,类似地,分帧处理后构建测试数据集,将模型用于预测测试数据集,绘制其对方位角预测性能的散点图见附图1。
[0041]
选用不同特征训练模型,并在容错角1-20
°
变化区间下考察模型预测的准确率变化情况,附图2说明了本发明提出的预测模型相对于其他模型预测的优良性。另外,附加纯净语音不同大小的白噪信号,并用模型对不同信噪比下的信号预测方位角,取容错角为5
°
,附图3可看出本发明在不同信噪比位置的预测正确率比较稳定。
[0042]
结果分析:
[0043]
采用本发明提供的提取语音信号的12种客观参量构建数据集,由其训练得到对声源方位角的预测模型在不同环境中的预测准确率均可达80%以上(容错角10
°
),因此,采用本发明提供的方法对不同混响环境提取客观参量建立模型,从而预测声源方位角是完全可
行的。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。