技术特征:
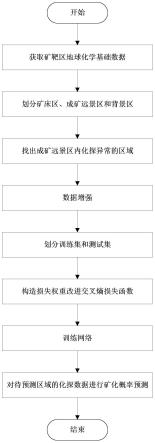
1.一种基于样本失衡的深度学习矿产资源分类预测方法,其特征在于,包括如下步骤:步骤1:经由地理位置信息和地球化学元素信息形成矿靶区地质图像数据;步骤2:将研究区域分为矿床区、成矿远景区和背景区;步骤3:通过变分自编码器分析成矿远景区内化探数据的特征分布并确定成矿远景区内化探数据异常的区域,若成矿远景区中存在化探数据异常的区域,则将该区域的类别标记为与其距离最近的矿床区类别相同;步骤4:将矿床区和所得化探异常区的样本进行数据增强;步骤5:构造卷积神经网络模型,用于学习化探数据与矿化之间的规律,为防止神经网络模型对背景区的空间数据特征产生过拟合以及优化网络模型学习化探数据的成矿特征,引入损失权重和惩罚损失改进传统交叉熵损失函数;步骤6:将训练样本数据输入到神经网络模型中进行迭代,然后更新神经网络的参数;步骤7:将训练好的网络模型对待预测区域的化探数据进行矿化概率预测,生成该区域矿产资源的概率预测分布图。2.根据权利要求1所述的一种基于样本失衡的深度学习矿产资源分类预测方法,其特征在于,所述步骤1中的地理位置信息包括已知矿靶区的经纬度坐标,地球化学元素信息包括已知矿靶区的各种地球化学元素的含量;在arcgis软件中输入地理位置信息和地球化学元素信息,经过基于地学统计的克里金插值法,最终得到已知矿靶区域的地质图像。3.根据权利要求1所述的一种基于样本失衡的深度学习矿产资源分类预测方法,其特征在于,所述步骤2中利用arcgis软件对化探数据进行迭代自组织聚类,选取已知矿床区为聚类中心,将研究区域分为成矿远景区和背景区,成矿远景区占研究面积的a%,成矿远景区中包含已知矿床区;背景区占研究面积的(100-a)%,a为预设的占比。4.根据权利要求1所述的一种基于样本失衡的深度学习矿产资源分类预测方法,其特征在于,所述步骤3包括如下步骤:步骤31:将成矿远景区拆分为若干个正方形区域,每个区域的化探数据x从矩阵格式展开为n维向量[x1,x2,
…
,x
n
],x
a
∈(0,1),a=1,2,
…
,n,假定成矿远景区化探数据的各种属性特征满足隐藏空间的概率分布z;步骤32:用神经网络构造一个编码器q
φ
,φ为训练参数,编码器以变分推断的方式产生i维的均值向量m=[μ1,μ2,...,μ
i
]和i维的标准差向量n=[σ1,σ2,...,σ
i
],由这两个向量可表示一个混合高斯分布q
φ
(z|x)用于逼近隐藏空间的概率分布z;然后在分布q
φ
(z|x)上随机采样,生成化探数据的隐含特征向量eps为满足均值为0方差为1的i维随机数向量;步骤33:用神经网络构造一个解码器p
θ
,θ为训练参数,解码器的作用是用隐含特征向量γ生成数据并且使得尽可能的与x相似;步骤34:为了使编码器q
φ
所得的分布q
φ
(z|x)逼近概率分布z和提高解码器p
θ
重构隐含特征向量γ为化探数据x的几率,构建损失函数步骤35:使用成矿远景区的数据以最小化损失函数为目标训练编码器q
φ
和解码器p
θ
;步骤36:训练结束后,依次排查成矿远景区各区域的化探数据,若某个区域的重构交叉
熵的值低于平均值,表示该区域的数据被重构的几率较小,空间数据特征也和周围区域相异,视为化探异常区域;步骤37:将化探异常区与其距离最近的已知矿床区视为具有高度相似的空间数据特征。5.根据权利要求1所述的一种基于样本失衡的深度学习矿产资源分类预测方法,其特征在于,所述步骤4包括如下步骤:步骤41:将地质图像转为数字矩阵x0;步骤42:创建一个与地质图像宽高尺寸、通道数和数据类型相同的数字矩阵x1,矩阵x1的每一个元素为随机数值且服从正态分布;步骤43:令y1=x0 x1,将数字矩阵y1转为图像数据格式即得到新的地质图像。6.根据权利要求1所述的一种基于样本失衡的深度学习矿产资源分类预测方法,其特征在于,所述步骤5包括如下步骤:步骤51:构造卷积神经网络模型,模型的数据输入格式为c
×
h
×
w的矩阵,c代表地球化学数据的图像通道个数,每个通道包含一种化探元素的信息,总共c个化探信息,h、w代表图像的高和宽,卷积神经网络的数据输出格式为代表着各个矿型或背景区的概率向量;步骤52:数据集的各类样本标签分别为i,共有i类样本,各类训练样本总数量分别为n
i
,训练样本总数量为每一类样本在训练过程中的损失权重样本数量较多的类别对应的权重较小,使得网络在推断时不会对该类样本过拟合;步骤53:样本x
i
,i为其对应的标签,通过神经网络输出得到的向量为p=[p1,p2,...,p
i
],取出其标签i对应的概率p
i
,p
i
∈(0,1],令该项表示交叉熵,交叉熵越小则神经网络的输出结果越靠近对应标签i的分布,令该项表示信息熵,信息熵越小则数据p的分布不确定性就越低,令该项表示样本x
i
的惩罚损失;步骤54:神经网络的损失函数为m个样本的平均惩罚损失,m为同一批次的训练样本数,以最小化损失函数为目标训练神经网络可有效防止网络模型对背景区的空间数据特征产生过拟合以及优化网络模型学习复杂化探数据的成矿特征。7.根据权利要求1所述的一种基于样本失衡的深度学习矿产资源分类预测方法,其特征在于,所述步骤7中得到训练好的网络模型后,将需要预测的矿区化探数据输入到系统中,通过滑动窗口算法,得到每个窗口区的成矿概率,最终形成整个矿区的成矿概率预测分布图。8.一种基于样本失衡的深度学习矿产资源分类预测系统,其特征在于,包括:预处理模块,用于经由地理位置信息和地球化学元素信息形成矿靶区地质图像数据;分区模块,用于将研究区域分为矿床区、成矿远景区和背景区;化探异常区识别模块,用于通过变分自编码器分析成矿远景区内化探数据的特征分布并确定成矿远景区内化探数据异常的区域,若成矿远景区中存在化探数据异常的区域,则将该区域的类别标记为与其距离最近的矿床区类别相同;数据增强模块,用于将矿床区和所得化探异常区的样本进行数据增强;
分类模型模块,用于构造卷积神经网络模型,用于学习化探数据与矿化之间的规律,为防止神经网络模型对背景区的空间数据特征产生过拟合以及优化网络模型学习化探数据的成矿特征,引入损失权重和惩罚损失改进传统交叉熵损失函数;模型训练模块,用于将训练样本数据输入到神经网络模型中进行迭代,然后更新神经网络的参数;分类预测模块,用于将训练好的网络模型对待预测区域的化探数据进行矿化概率预测,生成该区域矿产资源的概率预测分布图。9.一种计算机系统,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述计算机程序被加载至处理器时实现根据权利要求1-7任一项所述的基于样本失衡的深度学习矿产资源分类预测方法的步骤。10.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现根据权利要求1-7任一项所述的基于样本失衡的深度学习矿产资源分类预测方法的步骤。
技术总结
本发明提出了一种基于样本失衡的深度学习矿产资源分类预测方法及系统,本发明将研究区分为矿床区、成矿远景区和背景区,若成矿远景区中存在化探数据异常的区域,则能够间接说明该区域具有较高的矿化概率且表现出与已知矿床的化探数据特征相似性更高。利用深度学习的方式来分析并确定成矿远景区内化探数据异常的区域,然后将已知矿床区和所得化探异常区两者的空间数据特征视为神经网络的学习对象,用于习得化探数据与矿化之间的客观规律。为了防止神经网络对背景区的空间数据特征过拟合等问题,引入损失权重和惩罚损失对传统的交叉熵损失函数做出改进。本发明能够在较少的矿靶区地球化学数据中找出矿化规律以在新的地球化学数据中预测矿化概率。化学数据中预测矿化概率。化学数据中预测矿化概率。
技术研发人员:张鹏程 陈豪 丁亮 张婧玉 邓继
受保护的技术使用者:河海大学
技术研发日:2022.06.08
技术公布日:2022/9/2
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。