1.本发明涉及大数据和媒体数据处理领域,尤其涉及一种基于大数据分析的媒体数据处理方法。
背景技术:
2.大数据分析是指针对庞大多样的数据集使用高级分析技术,这些数据集包括结构化、半结构化和非结构化数据,它们来自不同的来源,大小从数tb到数zb不等。大数据适用于其大小或类型超出传统关系数据库以低延迟捕获、管理和处理数据的能力范围的数据集。
3.在舞台表演的现场,声音信号在传输过程中不可避免的会受到周围环境,传输介质等因素带来的噪声干扰。例如,演奏现场的实时声音录制的环境较为复杂,将导致干扰噪声严重影响录制音频的质量,使得现场录制效果不佳。传统的针对现场表演的媒体数据处理方法难以降低噪声强度较大的声源方向上产生的干扰噪声对音频质量的影响,常常会出现普通人声和环境噪声盖过演唱人声的问题。
技术实现要素:
4.为了解决上述问题,本发明提供了一种基于大数据分析的媒体数据处理方法,包括:
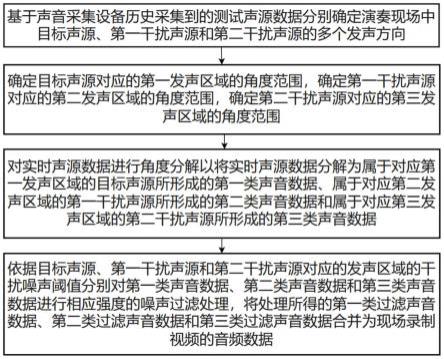
5.基于声音采集设备历史采集到的测试声源数据分别确定演奏现场中目标声源、第一干扰声源和第二干扰声源的多个发声方向,其中,所述目标声源为演奏现场中的演唱者,第一干扰声源为演奏现场中的观众,第二干扰声源为演奏现场中的乐队;
6.基于目标声源的多个发声方向确定目标声源对应的第一发声区域的角度范围,基于第一干扰声源的多个发声方向确定第一干扰声源对应的第二发声区域的角度范围,基于第二干扰声源对应的多个发声方向确定第二干扰声源对应的第三发声区域的角度范围,将第一发声区域对应的角度范围、第二发声区域对应的角度范围和第三发声区域对应的角度范围存储至数据库中;
7.接收声音采集设备从演奏现场中采集到的实时声源数据,对实时声源数据进行角度分解以将实时声源数据分解为属于对应第一发声区域的目标声源所形成的第一类声音数据、属于对应第二发声区域的第一干扰声源所形成的第二类声音数据和属于对应第三发声区域的第二干扰声源所形成的第三类声音数据;
8.依据目标声源、第一干扰声源和第二干扰声源对应的发声区域的干扰噪声阈值分别对第一类声音数据、第二类声音数据和第三类声音数据进行相应强度的噪声过滤处理,将处理所得的第一类过滤声音数据、第二类过滤声音数据和第三类过滤声音数据合并为现场录制视频的音频数据。
9.根据一个优选实施方式,所述基于声音采集设备历史采集到的测试声源数据分别确定演奏现场中目标声源、第一干扰声源和第二干扰声源的多个发声方向包括:
10.根据预训练的声音特征识别并确定各个方向上接收到的测试声源数据中包含的普通人声、演唱人声以及音乐伴奏的声音强度,分别对各个方向上的普通人声、演唱人声以及音乐伴奏的声音强度进行比较;
11.将包含最大强度的演唱人声的测试声源数据的接收方向作为目标声源的发声方向,将包含最大强度的普通人声的测试声源数据的接收方向作为第一干扰声源的发声方向,将包含最大强度的音乐伴奏的测试声源数据的接收方向作为第二干扰声源的发声方向。
12.根据一个优选实施方式,所述将处理所得的第一类过滤声音数据、第二类过滤声音数据和第三类过滤声音数据合并为现场录制视频的音频数据包括:
13.利用实时声源数据的合并权重矩阵对处理后的第一类过滤声音数据、第二类过滤声音数据和第三类过滤声音数据进行合并,其中,所述实时声源数据的合并权重矩阵包括第一类过滤声音数据对应的第一合并权重,第二类过滤声音数据对应的第二合并权重和第三类过滤声音数据对应的第三合并权重。
14.根据一个优选实施方式,所述利用合并权重矩阵对处理后的第一类过滤声音数据、第二类过滤声音数据和第三类过滤声音数据进行合并的步骤包括:
15.初始化实时声源数据的合并权重矩阵,根据所述初始化合并权重矩阵对第一类过滤声音数据、第二类过滤声音数据和第三类过滤声音数据的特征矢量序列进行合并以得到目标收录声音合并后的合并声音矩阵,根据所述初始化合并权重矩阵对第一类声音数据中的干扰噪声、第二类声音数据中的干扰噪声和第三类声音数据中的干扰噪声进行合并以得到干扰噪声合并后的合并噪声矩阵;
16.利用所述合并声音矩阵和所述合并噪声矩阵对合并后的目标收录声音与合并后的干扰噪声在各个时刻下的噪声比值进行调节以得到合并权重矩阵的最优矩阵参数,其中,所述噪声比值为合并后的目标收录声音与合并后的干扰噪声在对应时刻下的协方差比值;
17.将具有最优矩阵参数的合并权重矩阵作为最优合并权重矩阵,利用所述最优合并权重矩阵将第一类过滤声音数据、第二类过滤声音数据和第三类过滤声音数据合并为现场录制视频的音频数据。
18.根据一个优选实施方式,所述利用所述合并声音矩阵和所述合并噪声矩阵对合并后的目标收录声音与合并后的干扰噪声在各个时刻下的噪声比值进行调节以得到合并权重矩阵的最优矩阵参数还包括:
19.对目标收录声音的合并声音矩阵进行归一化处理,并对归一化后的合并声音矩阵对应的协方差矩阵进行特征值分解,利用分解得到的特征向量对目标收录声音的合并声音矩阵进行重构以得到目标收录声音的合并声音增强矩阵;
20.利用合并声音增强矩阵对应的协方差矩阵和合并噪声矩阵对应的协方差矩阵确定合并后的目标收录声音与合并后的干扰噪声在各个时刻下的噪声比值,对合并权重矩阵中的第一合并权重、第二合并权重和第三合并权重的数值分别进行调节以对合并后的目标收录声音与合并后的干扰噪声在各个时刻下的噪声比值进行调整;
21.当合并后的目标收录声音与合并后的干扰噪声在各个时刻下的噪声比值均为最大时,将第一合并权重对应的参数数值、第二合并权重对应的参数数值和第三合并权重对
应的参数数值分别作为第一合并权重的最优参数数值、第二合并权重的最优参数数值和第三合并权重的最优参数数值。
22.根据一个优选实施方式,所述对实时声源数据进行角度分解还包括:
23.对实时声源数据进行角度分解前,判断声音采集设备的采集位置是否发生变化,若是,根据声音采集设备采集测试声源数据时所处的采集位置与声音采集设备当前所处的采集位置之间的坐标差值对第一发声区域、第二发声区域和第三发声区域的角度范围进行修正。
24.根据一个优选实施方式,所述依据目标声源、第一干扰声源和第二干扰声源对应的发声区域的干扰噪声阈值分别对第一类声音数据、第二类声音数据和第三类声音数据进行相应强度的噪声过滤处理还包括:
25.提取第一类声音数据的声学特征,并根据第一类声音数据的声学特征判断所述第一类声音数据是否为目标处理音频数据,若是,则对第一类声音数据、第二类声音数据和第三类声音数据进行对应程度的噪声过滤处理,其中,所述目标处理音频数据为包含演唱人声的音频数据。
26.根据一个优选实施方式,所述依据目标声源、第一干扰声源和第二干扰声源对应的发声区域的干扰噪声阈值分别对第一类声音数据、第二类声音数据和第三类声音数据进行相应强度的噪声过滤处理包括:
27.根据测试声源数据确定第一发声区域对应的第一干扰噪声阈值、第二发声区域对应的第二干扰噪声阈值和第三发声区域对应的第三干扰噪声阈值,确定第一类声音数据对应的第一噪声强度、第二类声音数据对应的第二噪声强度和第三类声音数据对应的第三噪声强度;
28.分别将第一噪声强度、第二噪声强度和第三噪声强度与第一干扰噪声阈值、第二干扰噪声阈值和第三噪声强度阈值进行比较,分别对第一噪声强度大于或等于第一干扰噪声阈值的第一类声音数据、第二噪声强度大于或等于第二干扰噪声阈值的第二类声音数据和第三噪声强度大于或等于第三干扰噪声阈值的第三类声音数据进行对应噪声强度的噪声过滤处理。
29.所述目标收录声音包括演唱人声和音乐伴奏,所述干扰噪声包括自然环境噪声、观众和乐队发出的普通人声。
30.本发明提供的实施例具有以下有益效果:
31.本发明通过识别并记录演奏现场中演唱者、观众和乐队所在的多个不同发声方向以及每个发声方向的噪声强度,实现对来自不同方向上的现场声音数据进行不同程度的噪声过滤并合成最终的音频数据,本发明能够提高演奏现场录制音频中目标收录声音的清晰度,最大幅度的降低来自干扰声源方向上的干扰噪声对音频质量的影响,解决传统现场录制音频中普通人声和环境噪声盖过演唱人声的问题。
附图说明
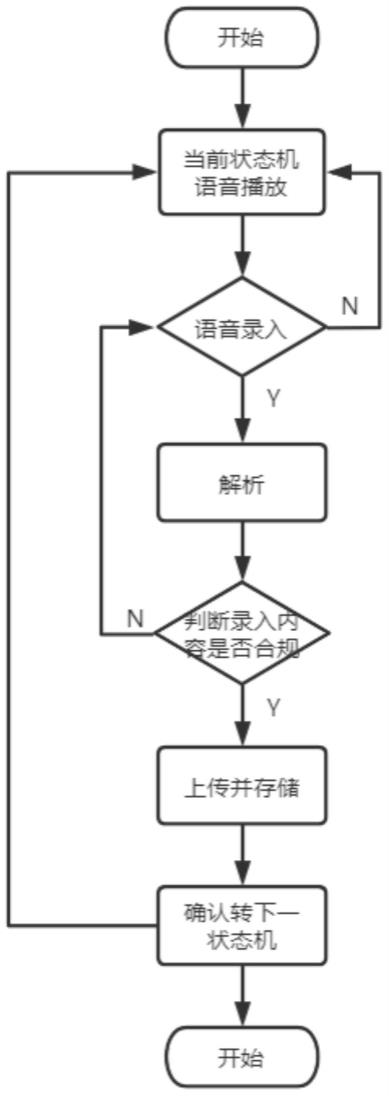
32.图1为一示例性实施例提供的基于大数据分析的媒体数据处理方法的流程图。
具体实施方式
33.为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定。
34.在本发明使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本发明。在本发明和所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。还应当理解,本文中使用的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。
35.参见图1,在一个实施例中,本发明的基于大数据分析的媒体数据处理方法可以包括:
36.s101、基于声音采集设备历史采集到的测试声源数据分别确定演奏现场中目标声源、第一干扰声源和第二干扰声源的多个发声方向,其中,所述目标声源为演奏现场中的演唱者,第一干扰声源为演奏现场中的观众,第二干扰声源为演奏现场中的乐队。
37.在本实施例中,步骤“基于声音采集设备历史采集到的测试声源数据分别确定演奏现场中目标声源、第一干扰声源和第二干扰声源的多个发声方向”具体包括:根据预训练的声音特征识别并确定各个方向上接收到的测试声源数据中包含的普通人声、演唱人声以及音乐伴奏的声音强度。分别对各个方向上的普通人声、演唱人声以及音乐伴奏的声音强度进行比较。将包含最大强度的演唱人声的测试声源数据的接收方向作为目标声源的发声方向。将包含最大强度的普通人声的测试声源数据的接收方向作为第一干扰声源的发声方向。将包含最大强度的音乐伴奏的测试声源数据的接收方向作为第二干扰声源的发声方向。
38.在本实施例中预训练的声音特征为系统预先训练的用于进行声音匹配的演唱人声的声学特征、音乐伴奏的声音特征和普通人声的声学特征,声学特征包括声音的韵律特征、频谱特征和质量特征,例如音调、音色和音高等。
39.s102、基于目标声源的多个发声方向确定目标声源对应的第一发声区域的角度范围,基于第一干扰声源的多个发声方向确定第一干扰声源对应的第二发声区域的角度范围,基于第二干扰声源对应的多个发声方向确定第二干扰声源对应的第三发声区域的角度范围,将第一发声区域对应的角度范围、第二发声区域对应的角度范围和第三发声区域对应的角度范围存储至数据库中。
40.在实际实施过程中,第一发声区域、第二发声区域和第三发声区域的角度范围均为一个以声音采集设备为中心的相对角度范围。
41.s103、接收声音采集设备从演奏现场中采集到的实时声源数据,对实时声源数据进行角度分解以将实时声源数据分解为属于对应第一发声区域的目标声源所形成的第一类声音数据、属于对应第二发声区域的第一干扰声源所形成的第二类声音数据和属于对应第三发声区域的第二干扰声源所形成的第三类声音数据。
42.在实际实施过程中,测试声源数据为从单个方向上接收的包含自然环境噪声、普通人声、音乐伴奏和演唱人声的音频数据。实时声源数据为从多个方向上接收到的包含自然环境噪声、普通人声、音乐伴奏和演唱人声的混合音频数据。因此,根据数据库中第一发声区域、第二发声区域和第三发声区域对应的角度范围对实时声源数据进行角度分解以得
到属于对应第一发声区域的目标声源所形成的第一类声音数据、属于对应第二发声区域的第一干扰声源所形成的第二类声音数据和属于对应第三发声区域的第二干扰声源所形成的第三类声音数据。
43.在一些可能的实施例中,在对实时声源数据进行角度分解时还包括判断声音采集设备的采集位置是否发生变化。若是,根据声音采集设备采集测试声源数据时所处的采集位置与声音采集设备当前所处的采集位置之间的坐标差值对第一发声区域、第二发声区域和第三发声区域的角度范围进行修正。
44.s104、依据目标声源、第一干扰声源和第二干扰声源对应的发声区域的干扰噪声阈值分别对第一类声音数据、第二类声音数据和第三类声音数据进行相应强度的噪声过滤处理,将处理所得的第一类过滤声音数据、第二类过滤声音数据和第三类过滤声音数据合并为现场录制视频的音频数据。
45.在一些可能的实施例中,依据目标声源、第一干扰声源和第二干扰声源对应的发声区域的干扰噪声阈值分别对第一类声音数据、第二类声音数据和第三类声音数据进行相应强度的噪声过滤处理的前置处理步骤还包括提取第一类声音数据的声学特征,并根据第一类声音数据的声学特征判断所述第一类声音数据是否为目标处理音频数据(即通过对第一类声音数据的音调、音高等声学特征进行分析,确定实时接收到的第一类声音数据中是否包含演唱人声,若不包含演唱人声则第一类声音数据不为目标处理音频数据)。若是,则执行以下步骤:
46.根据测试声源数据确定第一发声区域对应的第一干扰噪声阈值、第二发声区域对应的第二干扰噪声阈值和第三发声区域对应的第三干扰噪声阈值。确定第一类声音数据对应的第一噪声强度、第二类声音数据对应的第二噪声强度和第三类声音数据对应的第三噪声强度。
47.分别将第一噪声强度、第二噪声强度和第三噪声强度与第一干扰噪声阈值、第二干扰噪声阈值和第三噪声强度阈值进行比较。分别对第一噪声强度大于或等于第一干扰噪声阈值的第一类声音数据、第二噪声强度大于或等于第二干扰噪声阈值的第二类声音数据和第三噪声强度大于或等于第三干扰噪声阈值的第三类声音数据进行对应噪声强度的噪声过滤处理。
48.在本实施例中,第一类声音数据对应的第一噪声强度的确定步骤为:对第一类声音数据进行语音特征分析以得到第一类声音数据中包含的自然环境噪声的频谱分布图以及观众和乐队发出的普通人声的频谱分布图,根据自然环境噪声的频谱分布图对应的频谱能量和普通人声的频谱分布图对应的频谱能量分析得到第一噪声强度。第二噪声强度和第三噪声强度的分析步骤也如此。
49.在实际实施过程中,第一发声区域的第一干扰噪声阈值由多个采集周期内从第一发声区域方向上接收到的测试声源数据的平均最小噪声强度确定。第二发声区域的第二干扰噪声阈值由多个采集周期内从第二发声区域方向上接收到的测试声源数据的平均最小噪声强度确定。第三发声区域的第三干扰噪声阈值由多个采集周期内从第三发声区域方向上接收到的测试声源数据的平均最小噪声强度确定。前述采集周期可以设置为一个演唱会的标准演唱时长。
50.在本实施例中,步骤s104中“将处理所得的第一类过滤声音数据、第二类过滤声音
数据和第三类过滤声音数据合并为现场录制视频的音频数据”包括:利用实时声源数据的合并权重矩阵对处理后的第一类过滤声音数据、第二类过滤声音数据和第三类过滤声音数据进行合并。其中,所述实时声源数据的合并权重矩阵包括第一类过滤声音数据对应的第一合并权重,第二类过滤声音数据对应的第二合并权重和第三类过滤声音数据对应的第三合并权重。
51.在本实施例中,根据具有最优矩阵参数的合并权重矩阵对处理后的第一类过滤声音数据、第二类过滤声音数据和第三类过滤声音数据进行合并能够最大幅度的降低来自干扰声源(第一干扰声源和第二干扰声源)方向上的干扰噪声对合并数据的影响。
52.在实际实施过程中,利用合并权重矩阵对处理后的第一类过滤声音数据、第二类过滤声音数据和第三类过滤声音数据进行合并的步骤包括:
53.s2.1、初始化第一类过滤声音数据、第二类过滤声音数据和第三类过滤声音数据分别对应的合并权重得到初始化的第一合并权重、第二合并权重和第三合并权重。分别对第一类过滤声音数据、第二类过滤声音数据和第三类过滤声音数据进行语音特征分析得到一组随时间变化的第一特征矢量序列、第二特征矢量序列和第三特征矢量序列。
54.s2.2、将初始化的第一合并权重、第二合并权重和第三合并权重顺序排列以生成实时声源数据的初始化合并权重矩阵。根据所述初始化合并权重矩阵、第一类过滤声音数据对应的第一特征矢量序列、第二类过滤声音数据对应的第二特征矢量序列和第三类过滤声音数据对应的第三特征矢量序列生成目标收录声音合并后的合并声音矩阵。根据所述初始化合并权重矩阵、第一类声音数据对应的噪声特征序列、第二类声音数据对应的噪声特征序列和第三类声音数据对应的噪声特征序列生成干扰噪声合并后的合并噪声矩阵。
55.s2.3、利用所述合并声音矩阵和所述合并噪声矩阵对合并后的目标收录声音与合并后的干扰噪声在各个时刻下的噪声比值进行调节以得到合并权重矩阵中第一合并权重、第二合并权重和第三合并权重分别对应的最优参数数值。利用第一类过滤声音数据对应的最优第一合并权重、第二类过滤声音数据对应的最优第二合并权重和第三类过滤声音数据对应的最优第三合并权重对第一类过滤声音数据、第二类过滤声音数据和第三类过滤声音数据进行合并。其中,所述噪声比值为合并后的目标收录声音与合并后的干扰噪声在对应时刻下的协方差比值,最优第一合并权重即为拥有最优参数数值的第一合并权重,第一合并权重、第二合并权重和第三合并权重的最优参数数值不为零和负值。
56.在本实施例中,目标收录声音包括演唱人声和音乐伴奏,干扰噪声包括自然环境噪声、观众和乐队发出的普通人声。
57.在实际实施过程中,利用合并声音矩阵和所述合并噪声矩阵对合并后的目标收录声音与合并后的干扰噪声在各个时刻下的噪声比值进行调节的步骤还包括:
58.步骤一、对目标收录声音的合并声音矩阵进行归一化处理。并对归一化后的合并声音矩阵对应的协方差矩阵进行特征值分解。利用分解得到的特征向量对目标收录声音的合并声音矩阵进行重构以对目标收录声音的特征进行增强得到目标收录声音的合并声音增强矩阵。
59.步骤二、利用合并声音增强矩阵对应的协方差矩阵和合并噪声矩阵对应的协方差矩阵确定合并后的目标收录声音与合并后的干扰噪声在各个时刻下的协方差比值,将所述协方差比值作为合并后的目标收录声音与合并后的干扰噪声在对应时刻下的噪声比值。对
合并权重矩阵中的第一合并权重、第二合并权重和第三合并权重的数值分别进行调节以对合并后的目标收录声音与合并后的干扰噪声在各个时刻下的噪声比值进行调整。
60.步骤三、在合并后的目标收录声音与合并后的干扰噪声在各个时刻下的噪声比值均为最大时。将第一合并权重对应的参数数值、第二合并权重对应的参数数值和第三合并权重对应的参数数值分别作为第一合并权重的最优参数数值、第二合并权重的最优参数数值和第三合并权重的最优参数数值。
61.本发明通过识别演奏现场中演唱者、观众和乐队所在的多个不同发声方向以及每个发声方向的噪声强度,实现对来自不同方向上的现场声音数据进行不同程度的噪声过滤并合成最终的音频数据。此外,能够提高演奏现场录制音频中目标收录声音的清晰度,最大幅度的降低来自干扰声源方向上的干扰噪声对音频质量的影响,解决传统现场录制音频中普通人声和环境噪声盖过演唱人声的问题。
62.以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。