技术特征:
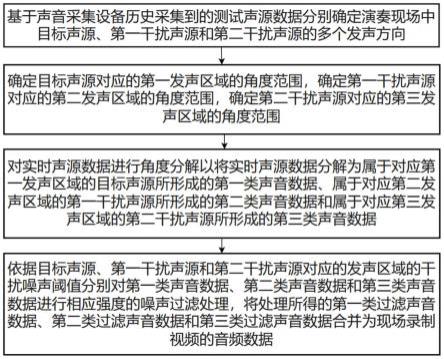
1.一种基于大数据分析的媒体数据处理方法,其特征在于,所述方法包括:基于声音采集设备历史采集到的测试声源数据分别确定演奏现场中目标声源、第一干扰声源和第二干扰声源的多个发声方向,其中,所述目标声源为演奏现场中的演唱者,第一干扰声源为演奏现场中的观众,第二干扰声源为演奏现场中的乐队;基于目标声源的多个发声方向确定目标声源对应的第一发声区域的角度范围,基于第一干扰声源的多个发声方向确定第一干扰声源对应的第二发声区域的角度范围,基于第二干扰声源对应的多个发声方向确定第二干扰声源对应的第三发声区域的角度范围,将第一发声区域对应的角度范围、第二发声区域对应的角度范围和第三发声区域对应的角度范围存储至数据库中;接收声音采集设备从演奏现场中采集到的实时声源数据,对实时声源数据进行角度分解以将实时声源数据分解为属于对应第一发声区域的目标声源所形成的第一类声音数据、属于对应第二发声区域的第一干扰声源所形成的第二类声音数据和属于对应第三发声区域的第二干扰声源所形成的第三类声音数据;依据目标声源、第一干扰声源和第二干扰声源对应的发声区域的干扰噪声阈值分别对第一类声音数据、第二类声音数据和第三类声音数据进行相应强度的噪声过滤处理,将处理所得的第一类过滤声音数据、第二类过滤声音数据和第三类过滤声音数据合并为现场录制视频的音频数据。2.根据权利要求1所述的方法,其特征在于,所述基于声音采集设备历史采集到的测试声源数据分别确定演奏现场中目标声源、第一干扰声源和第二干扰声源的多个发声方向包括:根据预训练的声音特征识别并确定各个方向上接收到的测试声源数据中包含的普通人声、演唱人声以及音乐伴奏的声音强度,分别对各个方向上的普通人声、演唱人声以及音乐伴奏的声音强度进行比较;将包含最大强度的演唱人声的测试声源数据的接收方向作为目标声源的发声方向,将包含最大强度的普通人声的测试声源数据的接收方向作为第一干扰声源的发声方向,将包含最大强度的音乐伴奏的测试声源数据的接收方向作为第二干扰声源的发声方向。3.根据权利要求2所述的方法,其特征在于,所述将处理所得的第一类过滤声音数据、第二类过滤声音数据和第三类过滤声音数据合并为现场录制视频的音频数据包括:利用实时声源数据的合并权重矩阵对处理后的第一类过滤声音数据、第二类过滤声音数据和第三类过滤声音数据进行合并,其中,所述实时声源数据的合并权重矩阵包括第一类过滤声音数据对应的第一合并权重,第二类过滤声音数据对应的第二合并权重和第三类过滤声音数据对应的第三合并权重。4.根据权利要求3所述的方法,其特征在于,所述利用合并权重矩阵对处理后的第一类过滤声音数据、第二类过滤声音数据和第三类过滤声音数据进行合并的步骤包括:初始化实时声源数据的合并权重矩阵,根据所述初始化合并权重矩阵对第一类过滤声音数据、第二类过滤声音数据和第三类过滤声音数据的特征矢量序列进行合并以得到目标收录声音合并后的合并声音矩阵,根据所述初始化合并权重矩阵对第一类声音数据中的干扰噪声、第二类声音数据中的干扰噪声和第三类声音数据中的干扰噪声进行合并以得到干扰噪声合并后的合并噪声矩阵;
利用所述合并声音矩阵和所述合并噪声矩阵对合并后的目标收录声音与合并后的干扰噪声在各个时刻下的噪声比值进行调节以得到合并权重矩阵的最优矩阵参数,其中,所述噪声比值为合并后的目标收录声音与合并后的干扰噪声在对应时刻下的协方差比值;将具有最优矩阵参数的合并权重矩阵作为最优合并权重矩阵,利用所述最优合并权重矩阵将第一类过滤声音数据、第二类过滤声音数据和第三类过滤声音数据合并为现场录制视频的音频数据。5.根据权利要求4所述的方法,其特征在于,所述利用所述合并声音矩阵和所述合并噪声矩阵对合并后的目标收录声音与合并后的干扰噪声在各个时刻下的噪声比值进行调节以得到合并权重矩阵的最优矩阵参数还包括:对目标收录声音的合并声音矩阵进行归一化处理,并对归一化后的合并声音矩阵对应的协方差矩阵进行特征值分解,利用分解得到的特征向量对目标收录声音的合并声音矩阵进行重构以对目标收录声音的特征进行增强得到目标收录声音的合并声音增强矩阵;利用合并声音增强矩阵对应的协方差矩阵和合并噪声矩阵对应的协方差矩阵确定合并后的目标收录声音与合并后的干扰噪声在各个时刻下的噪声比值,对合并权重矩阵中的第一合并权重、第二合并权重和第三合并权重的数值分别进行调节以对合并后的目标收录声音与合并后的干扰噪声在各个时刻下的噪声比值进行调整;当合并后的目标收录声音与合并后的干扰噪声在各个时刻下的噪声比值均为最大时,将第一合并权重对应的参数数值、第二合并权重对应的参数数值和第三合并权重对应的参数数值分别作为第一合并权重的最优参数数值、第二合并权重的最优参数数值和第三合并权重的最优参数数值。6.根据权利要求5所述的方法,其特征在于,所述对实时声源数据进行角度分解还包括:对实时声源数据进行角度分解前,判断声音采集设备的采集位置是否发生变化,若是,根据声音采集设备采集测试声源数据时所处的采集位置与声音采集设备当前所处的采集位置之间的坐标差值对第一发声区域、第二发声区域和第三发声区域的角度范围进行修正。7.根据权利要求6所述的方法,其特征在于,所述依据目标声源、第一干扰声源和第二干扰声源对应的发声区域的干扰噪声阈值分别对第一类声音数据、第二类声音数据和第三类声音数据进行相应强度的噪声过滤处理还包括:提取第一类声音数据的声学特征,并根据第一类声音数据的声学特征判断所述第一类声音数据是否为目标处理音频数据,若是,则对第一类声音数据、第二类声音数据和第三类声音数据进行对应程度的噪声过滤处理,其中,所述目标处理音频数据为包含演唱人声的音频数据。8.根据权利要求7所述的方法,其特征在于,所述依据目标声源、第一干扰声源和第二干扰声源对应的发声区域的干扰噪声阈值分别对第一类声音数据、第二类声音数据和第三类声音数据进行相应强度的噪声过滤处理包括:根据测试声源数据确定第一发声区域对应的第一干扰噪声阈值、第二发声区域对应的第二干扰噪声阈值和第三发声区域对应的第三干扰噪声阈值,确定第一类声音数据对应的第一噪声强度、第二类声音数据对应的第二噪声强度和第三类声音数据对应的第三噪声强
度;分别将第一噪声强度、第二噪声强度和第三噪声强度与第一干扰噪声阈值、第二干扰噪声阈值和第三噪声强度阈值进行比较,分别对第一噪声强度大于或等于第一干扰噪声阈值的第一类声音数据、第二噪声强度大于或等于第二干扰噪声阈值的第二类声音数据和第三噪声强度大于或等于第三干扰噪声阈值的第三类声音数据进行对应噪声强度的噪声过滤处理。9.根据权利要求8所述的方法,其特征在于,所述目标收录声音包括演唱人声和音乐伴奏,所述干扰噪声包括自然环境噪声、观众和乐队发出的普通人声。
技术总结
本发明涉及一种基于大数据分析的媒体数据处理方法,包括:确定并记录第一发声区域、第二发声区域和第三区域发声区域的角度范围,接收声音采集设备从演奏现场中采集到的实时声源数据。对实时声源数据进行角度分解以将实时声源数据分解为属于对应第一发声区域的目标声源所形成的第一类声音数据、属于对应第二发声区域的第一干扰声源所形成的第二类声音数据和属于对应第三发声区域的第二干扰声源所形成的第三类声音数据。分别对第一类声音数据、第二类声音数据和第三类声音数据进行相应强度的噪声过滤处理,将处理所得的第一类过滤声音数据、第二类过滤声音数据和第三类过滤声音数据合并为现场录制视频的音频数据。音数据合并为现场录制视频的音频数据。音数据合并为现场录制视频的音频数据。
技术研发人员:张斌
受保护的技术使用者:张斌
技术研发日:2022.06.06
技术公布日:2022/9/2
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。