编码或解码视频数据的方法和装置
1.本技术是申请号为201880035761.7、申请日为2018年6月22日、发明名称为“存储器访问减少的fruc模式下编码或解码视频数据的方法和装置”的发明专利申请的分案申请。
技术领域
2.本公开涉及用于编码或解码视频数据的方法和设备。其尤其涉及根据使用解码器侧运动矢量推导模式的特定编码模式的编码,该解码器侧运动矢量推导模式被称为帧速率上转换模式或fruc模式。
背景技术:
3.视频数据的预测编码基于帧划分为多个像素块。对于每个像素块,在可用数据中搜索预测块。预测块可以是在inter编码模式下不同于当前帧的参考帧中的块,或者可以在intra编码模式下从当前帧中的相邻像素生成。根据确定预测块的不同方式来定义不同的编码模式。编码的结果是预测块和残差块的指示,该残差块在于待编码的块与预测块之间的差。
4.关于inter编码模式,预测块的指示是如下运动矢量,该运动矢量给出了相对于待编码的块的位置的预测块在参考图像中的位置。运动矢量本身基于运动矢量预测值被预测编码。hevc(高效视频编码)标准定义了数种已知的用于运动矢量的预测编码的编码模式,即amvp(高级运动矢量预测)模式、合并推导过程。这些模式基于运动矢量预测值的候选列表的构建以及该列表中要用于编码的运动矢量预测值的索引的信号通知。通常,还用信号通知残差运动矢量。
5.近来,已经引入了关于运动矢量预测的被称为fruc的新编码模式,其定义了根本没有信号通知的运动矢量预测值的解码器侧推导过程。推导过程的结果将用作运动矢量预测值,而无需解码器传输任何索引或残差运动矢量。
6.与已知的编码模式相比,fruc模式编码和解码的当前实现产生了大量的存储器访问,显著增加了解码器必须考虑的存储器访问最坏情况。
技术实现要素:
7.已经构思出本发明以解决前述问题中的一个或多个。本发明涉及编码和解码的改进,其减少了在使用如下编码模式时对存储器访问的需求,在该编码模式中使用解码器侧运动矢量推导方法来预测运动信息。
8.根据本发明的第一方面,提供了一种用于解码包括帧的视频数据的方法,每个帧被分成多个像素块,该方法包括,对于一个像素块:
[0009]-使用编码模式推导运动矢量预测值的运动矢量列表,在该编码模式中通过解码器侧运动矢量推导方法获得运动信息,该推导基于定义运动矢量的可能位置的模板;其中:
[0010]-如果像素块的大小是4
×
4、4
×
8或8
×
4个像素,则以像素为单位的模板大小小于
或等于以像素为单位的块大小。
[0011]
在一个实施例中,模板由大小与该像素块相同且位于该像素块左侧的像素块构成。
[0012]
在一个实施例中,模板由大小与该像素块相同且位于该像素块上方的像素块构成。
[0013]
根据本发明的另一方面,提供了一种用于解码包括帧的视频数据的方法,每个帧被分成多个像素块,该方法包括,对于一个像素块:
[0014]-使用通过解码器侧运动矢量推导方法获得运动信息的模式来推导运动矢量预测值的运动矢量列表,该推导基于定义运动矢量的可能位置的模板;其中,该方法还包括:
[0015]-去除该列表中的一些运动矢量,以将运动矢量的数量限制为预定义数量。
[0016]
在一个实施例中,被去除的运动矢量是列表中的前几个运动矢量。
[0017]
在一个实施例中,被去除的运动矢量是列表中的后几个运动矢量。
[0018]
在一个实施例中,运动矢量列表被限制为预定义数量3。
[0019]
根据本发明的另一方面,提供了一种用于解码包括帧的视频数据的方法,每个帧被分成多个像素块,该方法包括,对于一个像素块:
[0020]-使用通过解码器侧运动矢量推导方法获得运动信息的模式来推导运动矢量预测值的运动矢量列表,该推导基于定义运动矢量的可能位置的模板;
[0021]-运动矢量列表的推导包括:在块层级推导第一候选列表,以及在子块层级推导第二候选列表;
[0022]-推导第一候选列表包括运动矢量合并候选的评估、atmvp运动矢量候选的评估、单边(unilateral)预测值的评估以及相邻预测值的评估;
[0023]
其中,在评估运动矢量合并候选之前先评估单边预测值。
[0024]
根据本发明的另一方面,提供了一种用于解码包括帧的视频数据的方法,每个帧被分成多个像素块,该方法包括,对于一个像素块:
[0025]-使用通过解码器侧运动矢量推导方法获得运动信息的模式来推导运动矢量预测值的运动矢量列表,该推导基于定义运动矢量的可能位置的模板;
[0026]-运动矢量列表的推导包括:在块层级推导第一候选列表,以及在子块层级推导第二候选列表;
[0027]-推导第一候选列表包括atmvp候选的评估和经缩放时间预测值的评估;其中
[0028]-在评估经缩放时间预测值之前,对atmvp候选进行评估。
[0029]
根据本发明的另一方面,提供一种用于解码包括帧的视频数据的方法,每个帧被分成多个像素块,该方法包括,对于一个像素块:
[0030]-使用通过解码器侧运动矢量推导方法获得运动信息的模式来推导运动矢量预测值的运动矢量列表,该推导基于定义运动矢量的可能位置的模板;
[0031]-候选的运动矢量列表的推导包括对包括来自左侧像素块、上方像素块、右上像素块、右下像素块和左上像素块的预测值的空间预测值的评估,对atmvp预测值的评估以及对时间预测值的评估;
[0032]
其中,对左侧空间预测值的评估发生在对左上空间预测值的评估之后。
[0033]
根据本发明的另一方面,提供了一种用于解码包括帧的视频数据的方法,每个帧
被分成多个像素块,该方法包括,对于一个像素块:
[0034]-使用通过解码器侧运动矢量推导方法获得运动信息的编码模式来推导运动矢量预测值的运动矢量列表,该推导基于定义运动矢量的可能位置的模板;
[0035]-候选的运动矢量列表的推导包括对包括来自左侧像素块、上方像素块、右上像素块、右下像素块和左上像素块的预测值的空间预测值的评估,对atmvp预测值的评估以及对时间预测值的评估,其中
[0036]-在对空间预测值进行评估之前,先对atmvp预测值进行评估。
[0037]
根据本发明的另一方面,提供了一种用于解码包括帧的视频数据的方法,每个帧被分成多个像素块,该方法包括,对于一个像素块:
[0038]-使用通过解码器侧运动矢量推导方法获得运动信息的模式来推导运动矢量预测值的运动矢量列表,该推导基于定义运动矢量的可能位置的模板;
[0039]-候选的运动矢量列表的推导包括对包括来自左侧像素块、上方像素块、右上像素块、右下像素块和左上像素块的预测值的空间预测值的评估,对atmvp预测值的评估以及对时间预测值的评估,其中
[0040]-对预测值的评估按以下顺序进行,首先是左上空间预测值,然后是atmvp预测值,然后是左下空间预测值,然后是右上空间预测值,然后是上方空间预测值,然后是左侧空间预测值,然后是时间预测值。
[0041]
根据本发明的另一方面,提供了一种用于解码包括帧的视频数据的方法,每个帧被分成多个像素块,该方法包括,对于一个像素块:
[0042]-使用通过解码器侧运动矢量推导方法获得运动信息的模式来推导运动矢量预测值的运动矢量列表,该推导基于定义运动矢量的可能位置的模板;
[0043]-运动矢量列表的推导包括:在块层级推导第一候选列表,以及在子块层级推导第二候选列表;其中:
[0044]-当块大小为4
×
4、4
×
8或8
×
4个像素时,第二候选列表仅包含第一列表中的最佳候选。
[0045]
在一个实施例中,最佳候选是使得速率失真成本最小的候选。
[0046]
根据本发明的另一方面,提供一种用于解码包括帧的视频数据的方法,每个帧被分成多个像素块,该方法包括,对于一个像素块:
[0047]-使用通过解码器侧运动矢量推导方法获得运动信息的模式来推导运动矢量预测值的运动矢量列表,该推导基于定义运动矢量的可能位置的模板;
[0048]-评估列表中的运动矢量预测值以获得最佳候选;
[0049]-基于最佳候选,评估在子像素分辨率下细化的矢量预测值;其中
[0050]
细化的矢量预测值的评估仅限于使用最佳候选模板中的像素值。
[0051]
在一个实施例中,最佳候选是使速率失真成本最小的候选。
[0052]
根据本发明的另一方面,提供了一种用于可编程装置的计算机程序产品,该计算机程序产品包括用于在被加载到可编程装置中并由其执行时实现根据本发明的方法的指令序列。
[0053]
根据本发明的另一方面,提供了一种计算机可读存储介质,其存储用于实现根据本发明的方法的计算机程序的指令。
[0054]
根据本发明的方法的至少一部分可以是计算机实现的。因此,本发明可以采取完全硬件实施例,完全软件实施例(包括固件,常驻软件,微代码等)或组合了软件和硬件方面的实施例的形式,这些实施例在本文中通常都被统称为“电路”、“模块”或“系统”。此外,本发明可以采取体现在任何有形介质中的计算机程序产品的形式,该计算机程序产品表达为具有体现在该介质中的计算机可用程序代码。
[0055]
由于本发明可以用软件实现,因此本发明可以体现为用于在任何合适的载体介质上提供给可编程装置的计算机可读代码。有形的非暂时性载体介质可以包括存储介质,例如软盘,cd-rom,硬盘驱动器,磁带设备或固态存储设备等。瞬态载体介质可以包括诸如电信号、电子信号、光信号、声信号、磁信号或电磁信号之类的信号,例如微波或射频信号。
附图说明
[0056]
现在将仅作为示例并参考以下附图来描述本发明的实施例,其中:
[0057]
图1示出了hevc编码器架构;
[0058]
图2示出了解码器的原理。
[0059]
图3是合并模式的运动矢量推导过程的流程图。
[0060]
图4示出了合并候选列表的生成过程中包含新atmvp运动候选。
[0061]
图5示出了fruc合并模式下的模板匹配和双边匹配。
[0062]
图6示出了fruc合并信息的解码。
[0063]
图7示出了合并模式和合并fruc模式的编码器评估。
[0064]
图8示出了在jem的编码单元和子编码单元层级的合并fruc模式推导。
[0065]
图9示出了编码单元层级的运动矢量列表推导。
[0066]
图10示出了子编码单元层级的运动矢量列表推导。
[0067]
图11示出了用于jem模板匹配方法的当前块周围的模板;
[0068]
图12示出了在像素的1/4图素网格(pel grid)中一个块的存储器访问;
[0069]
图13示出了运动矢量细化。
[0070]
图14示出了在像素的1/4像素网格中用于运动矢量细化的像素;
[0071]
图15示出了在本发明的一个实施例中使用的示例性模板。
[0072]
图16示出了本发明的一个实施例中的运动矢量列表的修剪过程。
[0073]
图17示出了本发明的一个实施例中的编码单元层级的运动矢量列表推导。
[0074]
图18示出了本发明的一个实施例中的子编码单元层级的运动矢量列表推导。
[0075]
图19示出了本发明的一个实施例中的合并模式候选的推导。
[0076]
图20示出了本发明的一个实施例中的合并模式候选的推导。
[0077]
图21示出了本发明的一个实施例中在编码单元和子编码单元层级的合并fruc模式推导。
[0078]
图22示出了关于本发明的一个实施例的在像素网格中用于运动矢量细化的像素。
[0079]
图23示出了关于本发明的一个实施例的与图22的示例相比,在1/4像素分辨率的网格中用于运动矢量细化的像素。
具体实施方式
[0080]
图1示出了hevc编码器架构。在视频编码器中,原始序列101被分成被称为编码单元的像素块102。然后,编码模式将影响到每个块。hevc中通常使用两个编码模式族:基于空间预测的模式或intra模式103,以及基于运动估计104和运动补偿105的inter模式或基于时间预测的模式。intra编码单元通常通过被称为intra预测的过程从在其因果边界处的编码像素被预测。
[0081]
时间预测首先在于在运动估计步骤104中在被称为参考帧116的先前帧或将来帧中找到最接近编码单元的参考区域。此参考区域构成预测块。接下来,在运动补偿步骤105中,使用预测块来预测此编码单元以计算残差。
[0082]
在空间和时间预测这两种情况下,都通过从原始预测值中减去编码单元来计算残差。
[0083]
在intra预测中,对预测方向进行编码。在时间预测中,至少一个运动矢量被编码。然而,为了进一步减少与运动矢量编码有关的比特率成本,不直接对运动矢量进行编码。实际上,假设运动是均匀的,则将运动矢量编码为该运动矢量与其周围的运动矢量之间的差是特别有趣的。例如,在h.264/avc编码标准中,运动矢量相对于在当前块上方和左侧的3个块之间计算的中值矢量被编码。只有在中值矢量和当前块运动矢量之间计算出的差(也称为残差运动矢量)被编码在比特流中。这在模块“mv预测和编码”117中进行处理。每个编码矢量的值存储在运动矢量字段118中。从运动矢量字段118中提取用于预测的相邻运动矢量。
[0084]
然后,在模块106中选择优化速率失真性能的模式。为了进一步减少冗余,在模块107中将变换(通常为dct)应用于残差块,并在模块108中将量化应用于系数。然后,在模块109中对经量化的系数块进行熵编码,并将结果插入到比特流110中。
[0085]
然后,编码器在模块111至116中对编码帧执行解码,以用于将来运动估计。这些步骤允许编码器和解码器具有相同的参考帧。为了重构编码帧,对于残差在模块111中进行逆量化并在模块112中进行逆变换,以便在像素域中提供“重构”的残差。根据编码模式(inter或intra),此残差被添加到inter预测值114或intra预测值113。
[0086]
然后,此第一重构在模块115中通过一种或数种后置滤波被进行滤波。这些后置滤波器集成在编码和解码循环中。这意味着它们需要在编码器和解码器侧被应用在重构帧上,以便在编码器和解码器侧使用相同的参考帧。此后置滤波的目的是消除压缩伪影。
[0087]
在图2中已经表示了解码器的原理。首先在模块202中对视频流201进行熵解码。然后,残差数据在模块203中被逆量化并在模块204中被逆变换,以获得像素值。还根据执行intra类型解码或inter类型解码的模式对模式数据进行熵解码。在intra模式的情况下,根据在比特流中指定的intra预测模式205来确定intra预测值。如果模式是inter,则从比特流202提取运动信息。它由参考帧索引和运动矢量残差组成。将运动矢量预测值添加到运动矢量残差以获得运动矢量210。然后,使用运动矢量以在参考帧中定位参考区域206。注意,运动矢量字段数据211被解码的运动矢量更新,以便用于下一解码的运动矢量的预测。然后,使用与在编码器侧使用的后置滤波器完全相同的后置滤波器来对解码帧的第一重构进行后置滤波(207)。解码器的输出是解压缩的视频209。
[0088]
hevc标准使用3种不同的inter模式:帧间(inter)模式,合并(merge)模式和合并
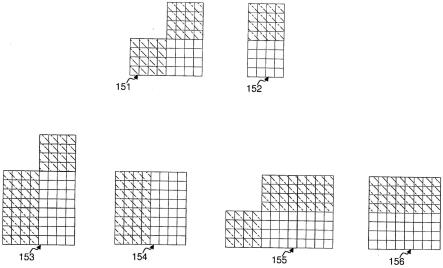
跳过(merge skip)模式。这些模式之间的主要区别是比特流中的数据信号通知(signalling)。对于运动矢量编码,当前的hevc标准与其前辈相比包括基于竞争性的运动矢量预测方案。这意味着,在编码器侧数个候选根据速率失真准则进行竞争,以便分别针对帧间或合并模式找到最佳运动矢量预测值或最佳运动信息。对应于运动信息的最佳候选或最佳预测值的索引被插入到比特流中。解码器可以得出相同的预测值或候选集合,并根据解码后的索引使用最佳的预测值或候选。
[0089]
预测值和候选的推导设计对于实现最佳编码效率而又不对复杂性产生重大影响是非常重要的。在hevc中,使用了两种运动矢量推导:一种用于帧间模式(高级运动矢量预测(amvp)),另一种用于合并模式(合并推导过程)。
[0090]
如已经提到的,合并模式(“经典”或“跳过”)的候选表示所有运动信息:方向、列表和参考帧索引以及运动矢量。通过以下描述的合并推导过程生成数个候选,每个候选都有一个索引。在当前的hevc设计中,两种合并模式的最大候选数等于5。
[0091]
图3是合并模式的运动矢量推导过程的流程图。在推导的第一步中,考虑了7个块位置301到307。模块308检查空间运动矢量的可用性并选择至多5个运动矢量。在此模块中,如果存在预测值且该块未被帧内(intra)编码,则可以使用预测值。在以下条件下描述这5个运动矢量的选择和检查。
[0092]
如果“左侧”a1运动矢量301可用,意味着它存在并且未进行帧内编码,则选择“左侧”块的运动矢量并将其用作空间候选列表310中的第一候选。a1运动矢量是紧接在当前编码单元左侧的块的运动矢量。
[0093]
如果“上方”b1运动矢量302可用,则在修剪模块309中将“上方”块的候选运动矢量与a1(如果存在)进行比较。如果b1等于a1,则不将b1添加在空间候选列表310中,否则将其添加。b1运动矢量是紧接在当前编码单元上方的块的运动矢量。修剪模块309所应用的一般原理是对照先前选择的候选检查任何新候选,并防止选择具有与先前选择的候选相同的值的新候选。
[0094]
如果“右上”b0运动矢量303可用,并且尚未在列表中选择,则也将其添加到空间候选列表310中。b0运动矢量是紧接在位于当前编码单元上方的块左侧的块的运动矢量。
[0095]
如果“左下”a0运动矢量304可用308,并且尚未在列表中选择,则也将其添加到空间候选列表310中。a0运动矢量是紧接在位于当前编码单元左侧的块下方的块的运动矢量。
[0096]
如果空间候选列表310在此阶段不包含4个候选,则测试“左上”b2运动矢量305的可用性,如果其可用且尚未在列表中选择,则也将其添加到空间候选名单310中。b2运动矢量是紧接在位于当前编码单元左侧的块上方的块的运动矢量。
[0097]
在该阶段结束时,空间候选列表310包含从0直到4个空间候选。
[0098]
对于时间候选,可以使用2个位置:被标记为h的位置306对应于并置(collocated)块的右下位置,被标记为中心的位置307对应于并置块。并置指的是块在时间帧中处于相同位置。这些位置在图3中被说明。
[0099]
作为amvp,首先由模块311检查在h位置306处的块的可用性。如果不可用,则模块311检查位于中心位置307的块。如果这些位置的至少一个运动矢量可用,则如果需要的话,可以通过缩放模块312将该时间运动矢量缩放到(如果需要的话)用于列表l0和l1两者的索引为0的参考帧,以便创建就在空间候选之后插入到合并候选列表中的时间候选313。
[0100]
如果在步骤314中测试到候选的数量(nb_cand)在严格意义上低于最大候选数量(max_cand),则由模块315生成组合的候选,否则建立合并候选的最终列表318。只有在当前帧用于b帧时才使用模块315,并且模块315基于当前合并列表中的可用候选生成数个候选。该生成在于将来自一个候选的列表l0的运动矢量与第二运动矢量候选的列表l1的运动矢量进行组合。
[0101]
如果在步骤316中测试到候选的数量(nb_cand)仍然在严格意义上小于最大候选数量(max_cand),则在模块317中生成零运动候选,以在候选合并列表318中达到最大候选数量。
[0102]
在该过程结束时,建立合并候选的最终列表318,其包含max_cand个候选。
[0103]
合并模式应用于与预测单元(pu)对应的像素块。在合并模式下(如在帧间模式下)的预测单位仍可以等于编码单位大小(2n
×
2n)。此外,合并跳过预测单元始终具有2n
×
2n的大小,在这种情况下,预测单元等于编码单元。对于合并模式预测单元,在编码器侧,选择一个候选并将索引插入比特流中。在hevc中,此索引使用一元最大代码(unary max code)进行编码,其中仅第一比特依赖于cabac上下文(cabac代表“上下文自适应二进制算术编码”,它是一种熵编码方法)。这意味着该第一比特将根据概率被二值化。其他比特以等概率被二值化。该一元最大值的最大值依赖于切片报头中的传输值。但是,该最大值不能超过5。一元代码对于较小的数量比对于较大的数量具有更少的比特数。
[0104]
定义了hevc标准的itu-t vceg(q6/16)和iso/iec mpeg(jtc 1/sc 29/wg 1 1)这两个标准化组正在通过已知为联合视频探索小组(jvet)的联合协作努力为hevc的后继者研究未来的视频编码技术。联合探索模型(jem)包含hevc工具和由该jvet组选择的新添加的工具。特别地,该软件在解码器侧算法中包含运动信息推导以高效地对运动信息进行编码。在被称为jvet-f1001的文档中描述了其它工具的列表。
[0105]
为了提高编码效率,已将其他候选添加到图3所示的候选的经典合并模式推导中。主要变化是包含高级时间运动矢量预测(atmvp)预测值。高级时间运动矢量预测方法允许每个编码单元从并置参考图片中比当前编码单元小的多个块中获取多组运动信息。在空间-时间运动矢量预测(stmvp)方法中,通过使用时间运动矢量预测值和空间相邻运动矢量来递归地推导子编码单元的运动矢量。可以在文档jvet-f1001中找到更多细节。
[0106]
图4示出了在图3所示的合并候选列表的生成过程中包含新的atmvp运动候选。仅对差异进行描述。存在2种类型的atmvp候选,步骤419生成的预测单元层级候选420和步骤421生成的子编码单元层级候选422。两种类型的候选420和422都被添加到空间预测值列表423中。如果左上空间候选405存在并且如果它与其他空间候选相比不是重复的候选,则将其添加到列表的末尾。然后,将经典时间预测值添加到此列表中,并且如果列表中的候选数量尚未达到其最大值,则处理合并模式的经典推导。此外,与hevc标准相比,在被称为jem的示例性实现中,用于合并模式的候选的最大数量(max_cand)已从5增加到7。
[0107]
解码器侧的运动矢量推导在文档jvet-f1001中被表示为模式匹配运动矢量推导(pmmvd)。jem中的pmmvd模式是一种基于帧速率上转换(fruc)技术的特殊合并模式。通过这种模式,块的运动信息不被信号通知,而是在解码器侧被推导出。
[0108]
对于当前版本的jem,可以进行两种类型的搜索:模板匹配和双边匹配(bilateral matching)。图5说明了这两种方法。双边匹配501的原理是沿着当前编码单元的运动轨迹找
到两个块之间的最佳匹配。
[0109]
模板匹配502的原理是通过计算当前块周围的重构像素与所评估的运动矢量所指向的块周围的相邻像素之间的匹配成本来推导当前编码单元的运动信息。该模板对应于当前块周围的相邻像素的图案,并且对应于预测块周围的相邻像素的对应图案。
[0110]
对于两种匹配类型(模板匹配或双边匹配),将计算出的不同匹配成本进行比较,以找到最佳匹配成本。选择获得最佳匹配的运动矢量或运动矢量对作为推导出的运动信息。可以在jvet-f1001中找到更多细节。
[0111]
两种匹配方法都提供了推导全部运动信息、运动矢量、参考帧和预测类型的可能性。在解码器侧的运动信息推导(在jem中记为“fruc”)适用于所有hevc帧间模式:amvp、合并和合并跳过。
[0112]
对于amvp,用信号通知所有运动信息:单或双预测、参考帧索引、预测值索引运动矢量和残差运动矢量,应用fruc方法来确定被设定成预测值列表中的第一预测值的新预测值。因此它的索引为0。
[0113]
对于合并和合并跳过模式,对于cu发信号通知fruc标志。当fruc标志为假(“false”)时,发信号通知合并索引,并使用常规合并模式。当fruc标志为真(“true”)时,发信号通知附加fruc模式标志,以指示将使用哪种方法(双边匹配或模板匹配)来推导该块的运动信息。请注意,双边匹配仅适用于b帧而不适用于p帧。
[0114]
对于合并和合并跳过模式,为当前块定义了运动矢量字段。这意味着为小于当前编码单元的子编码单元定义了矢量。此外,关于经典合并,用于每个列表的一个运动矢量可以形成一个块的运动信息。
[0115]
图6是说明对于块的合并模式的fruc标志的此信令通知的流程图。根据hevc用语,块可以是编码单元或预测单元。
[0116]
在第一步骤601中,对跳过标志进行解码以了解编码单元是否根据跳过模式被编码。如果在步骤602中测试到此标志为假,然后在步骤603中对合并标志进行解码,并在步骤605中进行测试。当编码单元根据跳过或合并模式被编码时,在步骤604中对合并fruc标志进行解码。当编码单元没有根据跳过或合并模式被编码时,在步骤606中,对经典amvp帧间模式的帧内预测信息进行解码。当在步骤607中测试到当前编码单元的fruc标志为真时,并且如果当前切片是b切片,则在步骤608中对匹配模式标志进行解码。应注意,fruc中的双边匹配仅适用于b切片。如果切片不是b切片并且选择了fruc,则模式必须是模板匹配,并且不存在匹配模式标志。如果编码单元不是fruc,然后在步骤609中对经典合并索引进行解码。
[0117]
fruc合并模式在编码器侧在与经典合并模式(以及其他可能的合并模式)进行竞争。图7说明了jem中的当前编码模式评估方法。首先,在步骤701中评估hevc的经典合并模式。在步骤702中首先利用原始块与候选列表的每个候选之间的简单sad(绝对差之和)来评估候选列表。然后,评估受约束候选的列表中的每个候选的真实速率失真(rd)成本,由步骤704至708所示。在评估中,评估具有残差的速率失真(步骤705)和没有残差的速率失真(步骤706)。最后,在步骤709中确定最佳合并候选,该最佳合并候选可以具有或不具有残差。
[0118]
然后,在步骤710至716中评估fruc合并模式。对于步骤710的每种匹配方法(即,双边和模板匹配),在步骤711中获取当前块的运动矢量字段,并在步骤712和713中计算具有残差或没有残差的全速率失真成本评估。基于这些速率失真成本,在步骤715中确定具有或
没有残差的最佳运动矢量716。最后,在其他模式的可能评估之前,在步骤717中确定经典合并模式与fruc合并模式之间的最佳模式。
[0119]
图8说明了编码器侧的fruc合并评估方法。对于每个匹配类型(步骤801),即模板匹配类型和双边匹配类型,首先由模块81评估编码单元层级,然后由模块82评估子编码单元层级。目的是找到当前编码单元803中的每个子编码单元的运动信息。
[0120]
模块81处理编码单元层级评估。在步骤811中推导运动信息的列表。对于该列表的每个运动信息,在步骤812中计算失真成本并将之相互比较。用于模板的最佳运动矢量或用于双边的最佳运动矢量对813是使成本最小的矢量。然后,运动矢量细化步骤814被应用以提高所获得的运动矢量的精度。通过fruc方法,对于模板匹配估计,使用双线性插值,而不是经典的离散余弦变换插值滤波(dctif)插值滤波器。这将块周围的存储器访问减少到仅一个像素,而不是传统dctif的块周围的7个像素。实际上,双线性插值滤波器仅需要2个像素即可获得一个方向上的子像素值。
[0121]
在运动矢量细化之后,在步骤815中获得当前编码单元的更好的运动矢量。该运动矢量将用于子编码单元层级评估。
[0122]
在步骤802中,将当前编码单元细分为数个子编码单元。子编码单元是方形块,其取决于四叉树结构中的编码单元的划分深度。最小尺寸为4
×
4。
[0123]
对于每个子cu,子cu层级评估模块82评估最佳运动矢量。在步骤821中推导出运动矢量列表,包括在步骤815中在cu层级获得的最佳运动矢量。对于每个运动矢量,在步骤822中评估失真成本。但是,该成本还包括表示用以避免发散运动矢量场的在编码单位层级获得的最佳运动矢量与当前运动矢量之间的距离的成本。基于最小成本获得最佳运动矢量823。然后,以与步骤814中在cu层级相同的方式,通过mv细化过程824细化该矢量823。
[0124]
在过程结束时,对于一种匹配类型,获得每个子cu的运动信息。在编码器侧,比较两种匹配类型之间的最佳rd成本,以选择最佳的匹配类型。在解码器侧,该信息从比特流被解码(在图6的步骤608)。
[0125]
对于fruc合并模式或amvp,编码单位层级的运动矢量列表与子编码单元层级的列表不同。图9示出了图8的编码单元层级步骤811的运动矢量推导过程。
[0126]
可以针对每个列表l0或l1独立实现此过程。该过程取得对应于参考帧901的索引和指示编码模式是否为amvp的标志902的一些输入。然后,在测试步骤903中,检查当前模式是avmvp还是合并模式。如果是amvp,则在步骤904中将amvp预测值添加到列表中。这些预测值是在amvp过程中获得的左侧、上方和时间预测值。此步骤在列表中添加最多3个预测值。
[0127]
然后在步骤905中生成运动矢量合并候选。这些候选都添加到fruc列表中,除了在步骤906中添加的atmvp候选外。通过这些步骤,可以添加多达7个新预测值。
[0128]
然后,在步骤907中将单边预测值添加到列表中。对于每个参考帧在4
×
4块层级基于运动插值生成单边预测值。可以在jvet-f1001中找到更多细节。在4
×
4块层级插值的所有运动中,该过程仅采用一些预测值。如果块的高度(h)或宽度(w)大于4,则可以添加两个预测值。因此,对于大小为h
×
w的块,其中h和w都大于4,则可以添加2
×
2=4个预测值。如果h等于4并且w大于4,则预测值的数量为1
×
2=2个预测值。对于4
×
4块,仅添加1个预测值。
[0129]
最终,在步骤908中添加一些相邻的预测值。但是,添加最多2个预测值。
[0130]
对于添加到列表中的每个预测值,都会检查该预测值不是重复的预测值。因此,列
表909仅包含具有不同值的预测值。
[0131]
在过程结束时,下表中汇总了列表909中的最大预测值数量:
[0132][0133]
图10示出了对应于图8中的步骤821的用于fruc的子编码单元层级的运动矢量列表构建。对每个列表l0和l1执行该过程。
[0134]
首先,在步骤1002中,在第一位置将在编码单位层级获得的最佳运动矢量1001添加到列表中。
[0135]
其次,在步骤1004中,如果一些相邻运动矢量具有相同的参考帧索引和相同的列表l0或l1,则添加这些相邻运动矢量。在此过程中,添加最多4个运动矢量。该步骤需要对应于在编码单元层级的最佳运动矢量的参考帧的索引1003。
[0136]
然后,在步骤1005中,将来自列表的每个参考帧的所有时间运动矢量缩放到在编码单元层级获得的最佳运动矢量的参考帧,并将其添加到列表。如果我们认为一个列表可以包含16个参考帧,则可以将16个附加预测值添加到此列表中。
[0137]
最终,在步骤1006中可以将atmp预测值添加到列表中。添加2种类型的atmvp预测值。但是存在一个约束:对于4
×
4子编码单元,每种类型仅添加一个矢量,即2个预测值。对于较大的子编码单元,可以添加4个预测值。
[0138]
以与编码单位层级相同的方式,添加到列表中的每个预测值都不是重复的预测值。因此,列表1007仅包含具有不同值的预测值。另请注意,此过程不适用于amvp。
[0139]
在该过程结束时,下表中汇总了列表1007中的最大预测值数量:
[0140][0141]
对于最坏情况解码,对于4
×
4块测试的运动矢量的最大数量对应于编码单位层级的最大预测值数量,再加上子编码单位层级的最大预测值数量乘以2,这是因为可能有两个不同的列表。可以得到最多52个与相同数量的块位置相对应的预测值将根据速率失真准则
被测试。
[0142]
与仅访问2个块位置进行解码的hevc中的块解码相比,这是非常高的。
[0143]
对于模板fruc匹配模式,模板包括在该块上部的四行和在该块左侧的四行,用于估计速率失真成本,如图11中的灰色所示。为了评估fruc运动矢量列表的运动矢量预测值的速率失真,需要访问由被评估的运动矢量预测值所参考的块的相应模板。
[0144]
图12示出了4
×
4块的硬件实现所需的块存储器访问的一些示例。
[0145]
示图121示出了需要访问以评估fruc模板的像素。考虑由被评估的运动矢量所参考的块125,模板匹配需要访问以灰色示出的左侧块和上部块。用白色表示的左上块中的像素也被访问,这是因为对于某些实现,一次访问较高的块存储器大小并不比访问2个较小的块存储器大小复杂。此外,为了能够计算子像素位置和进行运动矢量细化,需要访问该块周围的一个以上的像素(如虚线像素所示)以生成像素的双线性插值。因此,对于4
×
4块的矢量位置,考虑到需要评估运动矢量细化,需要访问(4 4 2)
×
(4 4 2)=100个像素。或者,如果仅考虑对运动矢量列表估计的访问,则访问(4 4 1)
×
(4 4 1)=81个像素。因此,对于一个矢量的评估,对于当前块的一个像素访问100/(4
×
4)=6.25个像素(如果我们还考虑运动矢量细化),而关于图8的步骤812中的用于运动矢量列表评估,对于当前块的一个像素访问个像素。
[0146]
然而,可以访问较少数量的像素或如示图122所示的真正需要的像素,其中仅考虑了在严格意义上评估所需的像素。但这需要非常特定的硬件实现来设计这种缓冲器。
[0147]
另一种可能性是仅访问示图123中所示的模板。在这种情况下,可以通过2个不同的存储器访问来独立访问上部块和左侧块。在这种情况下,需要访问5
×5×
2=50个像素以进行运动矢量列表评估。如果考虑附加的运动矢量细化,则为6
×6×
2=72个像素。
[0148]
对于双边fruc匹配模式,模板是由运动矢量参考的块。因此,对于列表中的一个矢量预测值,考虑2个块位置,如图12的示图123所示。因此,如果仅考虑运动矢量列表评估,则需要访问5
×5×
2=50个像素,如果考虑附加的运动矢量细化,则需要6
×6×
2=72个像素。
[0149]
对于采用双预测的传统运动补偿,需要访问2个块位置,每个列表一个块位置。由于dctif是比双线性更长的滤波器,因此需要访问更多像素,如示图124所示。在此情况下,对于4
×
4块,需要为4
×
4块访问(4 7)
×
(4 7)
×
2=242个像素。
[0150]
下表列出了关于对于4
×
4块的对于传统合并模式和用于各匹配模式的fruc合并模式的最坏情况复杂性所访问的存储器的一些数字。如所报道的,与传统的运动补偿相比,fruc合并模式大大增加了解码器侧所需的最坏情况存储器访问。
[0151][0152]
图8中的步骤814和824的运动矢量细化通过在识别出的最佳预测值周围的附加搜索(813或823)而提高了运动矢量预测值的精度。
[0153]
图13说明了这种运动矢量细化。
[0154]
该方法以在列表中识别(812或822)的最佳运动矢量预测值1301作为输入。
[0155]
在步骤1302中,以对应于1/4像素位置的分辨率应用菱形搜索。菱形搜索由以最佳矢量运动为中心的在1/4像素分辨率下的示图131示出。该步骤得到在1/4像素分辨率下的新的最佳运动矢量1303。
[0156]
该菱形搜索所获得的最佳运动矢量位置1303成为步骤1304中在1/4像素分辨率下的十字搜索的中心。此十字搜索由以最佳矢量运动1303为中心的在1/4像素分辨率下的示图132示出。该步骤得到在1/4像素分辨率下的新的最佳运动矢量1305。
[0157]
通过该搜索步骤1304获得的新的最佳运动矢量位置1305成为在步骤1306中在1/8像素分辨率下的十字搜索的中心。该步骤得到在1/8像素分辨率下的新的最佳运动矢量1307。示图133以1/8分辨率说明了这三个搜索步骤以及所有被测试的位置。
[0158]
图14示出了1/4子像素网格中的4
×
4块。
[0159]
在此图上,在块141中,橙色像素142表示像素分辨率下的像素位置。红色像素143是缓冲器中的像素。蓝色像素144表示由运动矢量参考的块的内插像素。灰色位置145代表经细化的运动矢量的所有潜在位置。
[0160]
作为由运动矢量引用为子像素位置的插值块,用于插值的放入缓冲区中的像素块的大小为在像素分辨率下(4 1)
×
(4 1)=25个像素的像素块。对于运动矢量细化(步骤814或824),可能的子像素位置用灰色表示。
[0161]
视频解码器的硬件设计必须考虑最坏情况复杂性。否则,在这种最坏情况发生时,
它将无法及时解码。fruc方法显著增加了存储器访问最坏情况。但是,减少存储器访问最坏情况的简单方法(在于防止使用4
×
4、4
×
8或8
×
4块)大大降低了编码效率。
[0162]
本发明的目的是减少关于存储器访问的最坏情况复杂性且减少编码效率劣化。现在将描述解决该问题的数个实施例。
[0163]
在图15所示的本发明的第一实施例中,减小模板形状以减少存储器访问。白色像素代表所考虑的像素块,而灰色像素代表用于评估fruc合并模式的模板匹配的模板。示图151示出了现有技术,而示图152至156示出了第一实施例的不同变型或不同情况。
[0164]
示图151示出了用于4
×
4块的现有技术模板,其中上部4
×
4块和左侧4
×
4块用于构成模板。
[0165]
在此实施例中,如示图152所示,当上部块是4
×
4块时,仅选择上部块来构成模板。如果不存在上部4
×
4块,则可以类似地由左侧块构成模板。在该实施例中,模板大小不超过当前块的大小。而且,由于仅一个4
×
4块需要存储在用于模板的存储器中,因此4
×
4块的存储器访问最坏情况从图12的示图121所示的情况下的81个像素的缓冲器大大减少到此实施例的(4 1)
×
(4 1)=25个像素。
[0166]
当允许该实施例用于4
×
4块时,8
×
4和4
×
8块成为最坏情况。使用与用于4
×
4块的思路相同的思路,可以将与示图154中所示的模板类似的模板用于4
×
8块,而不是使用示图153中所示的模板。类似地,可将与示图156中所示的模板类似的模板用于8
×
4块,而不是使用示图155中所示的模板。对于4
×
8块,模板减小为左侧模板,如示图154所示,并且对于8
×
4块,模板减小为上部块,如示图156所示。以与关于4
×
4块的方式相同的方式,模板大小不会超过当前块的大小。对于4
×
4块,如果不存在用于4
×
8块的左侧模板或用于8
×
4块的上部模板,则可以切换到其他模板,分别是上部和左侧4
×
4块。
[0167]
该实施例可以被认为是模板不能超过当前块的大小的约束。
[0168]
下表总结了本实施例的存储器最坏情况的结果。
[0169]
[0170]
因此,通过此实施例,最坏情况的存储器访问减少了2.5。与导致了相同的最坏情况减少的避开所有4
×
4、8
×
4和4
×
8块的显而易见的解决方案相比,所提出的实施例给出了更好的编码效率。
[0171]
为了限制存储器访问,在本发明的另一实施例中采用的解决方案是限制在图8的步骤811和821中在预测值列表中生成的预测值的数量。
[0172]
在一个实施例中,列表中的由步骤811生成的编码单元层级的和由步骤821生成的子编码单元层级的预测值的数量被限制为数量n,其低于现有技术中使用的最大候选数量。预测值列表照常生成,可以通过去除所生成的列表中的一些预测值来得到限制。列表中实际去除的预测值根据模式或匹配类型而改变。
[0173]
图16说明了所提出的过程。首先,与现有技术一样,在步骤1601中推导fruc运动矢量列表。
[0174]
如果在步骤1602中测试到模式是amvp,则在步骤1605中保留列表的前n个运动矢量,并去除随后的运动矢量。
[0175]
如果模式不是amvp,并且在步骤1603中测试到fruc匹配类型是模板匹配,则在步骤1604中保持列表的最后n个运动矢量,去除前面的运动矢量。
[0176]
否则,在步骤1605中,保留列表的前n个运动矢量,并去除随后的运动矢量。
[0177]
请注意,该实施例可以进行修改。特别地,可以省略测试步骤1603或1602之一。在替代实施例中,每个测试的存在取决于编码单元层级或子编码单元层级过程。例如,在cu层级仅应用测试1602,而在子cu层级仅应用测试1603。
[0178]
该实施例是高效的,因为它对于合并模式候选的经典推导提供了补充。这对于模板匹配fruc模式特别有趣。对于amvp,保留最先预测值是重要,因为它们是amvp运动矢量预测值列表的预测值。而当前在amvp模式中使用fruc是一种确定最可能的预测值的方式。对于fruc合并模式,这是不同的。因此,在一个实施例中,如果存在与经典amvp模式竞争的amvp fruc模式,则在选择了amvp模式的情况下,将最后n个预测值保留在列表中,而对于amvp fruc模式则保留前n个运动矢量预测值。
[0179]
通过该实施例,可以使用相同的过程来推导运动矢量列表,这对于硬件实现可能是有趣的,但是当运动矢量的列表很长时,这可能不是很高效。在另一个实施例中,始终保持前n个运动矢量。可以根据一些参数来改变运动矢量列表推导过程,以直接生成局限于n个矢量的矢量列表。例如,这些参数可以是作为图16的限制过程中使用的参数的模式和匹配类型。
[0180]
图17和图18示出了这样的实施例。
[0181]
与图9所示的相应过程相比,图17所示的编码单元层级的矢量列表推导方法改变了矢量在列表中的插入顺序。单边预测值被评估,并因此在步骤1707中首先被插入。接下来,在步骤1705和1706中插入合并预测值。
[0182]
与图10所示的相应过程相比,图18所示的子编码单元层级的矢量列表推导方法也改变了矢量在列表中的插入顺序。在步骤1805中插入缩放时间预测值之前以及在步骤1804中插入相邻预测值之前,在步骤1806中插入2种类型的atmvp预测值。
[0183]
在另一个和/或另外的实施例中,缩放运动矢量时间预测值按相反顺序生成。实际上,它们是从具有最高索引的参考帧到最低参考帧索引进行添加。当仅前n个预测值被保留
在存储器中时,优选地使用具有最低参考帧索引的缩放时间预测值。实际上,通常,最低参考帧索引代表最接近的参考帧,因此运动应该更相关。在替代实施例中,缩放时间预测值从最近的参考帧到最远的参考帧进行添加。
[0184]
当应用本实施例时,如下表所述,对于编码单元和子编码单元层级的4
×
4块以及n=3个预测值,它大大减少了最坏情况:
[0185][0186]
值得注意的是,对于模板匹配和双边匹配两者都减少了最坏情况。
[0187]
在优选实施例中,将每个预测值集合的预测值的数量设置为n等于3。
[0188]
在一个附加实施例中,当列表中的预测值的数量未达到大小n时,添加了一些虚拟预测值。一些已知的虚拟预测值是偏移预测值。通过将偏移值添加到另一个预测值的水平和/或垂直矢量分量(通常添加到列表中的第一预测值)来获得偏移预测值。
[0189]
在一个实施例中,以不同的顺序生成用于合并和合并fruc的运动矢量列表。合并候选列表已被设置以在hevc中获得最佳编码效率。因此,可以认为运动矢量候选被排序为使得最可能的预测值被设置在列表的第一位置。在运动信息非常可预测的情况下,主要选择“合并fruc”模式。因此,对于hevc通常选择“合并”列表的第一预测值。当启用合并fruc模式时,较少选择第一合并候选。因此,考虑到合并fruc经常能够找到最可能的模式,具有顺序与经典合并推导不同的特定列表可能会是有趣的。请注意,该实施例提高了编码效率,但不一定增大最坏情况的问题。该实施例不需要固定的运动矢量列表大小。
[0190]
图19示出了该实施例,它对应于图4所示的运动矢量推导过程的变型。在这种情况下,左侧预测值1901的评估已移至左下1905之后进行。因此,将其评估添加到空间列表末尾而就在时间预测值之前。
[0191]
图20示出了此实施例的另一种可能性。在这种情况下,与图4所示的运动矢量推导
过程相比,atmvp候选2019和2021的评估已被移位至在推导过程中首先进行。因此,在图9的步骤906中在合并fruc模式的推导中不存在的这些预测值在列表中处于第一位置。因此,它们更有机会在第一位置被选中。因此,这些未出现在fruc合并列表中的候选与合并fruc具有更好的互补性,以较低的比特来编码其索引。
[0192]
在另一替代实施例中,在时间之前评估的所有候选被以相反的顺序进行评估。空间预测值的典型评估如下:左上、编码单元层级的atmvp、子编码单元层级的atmvp、左下、右上、上方和左侧。当然,如果存在amvp fruc模式,则该实施例可以进行修改。
[0193]
对于子编码单元推导过程使用新的运动矢量列表会在最坏情况下生成块位置的存储器访问。因此,优选地不在子编码单元层级构建新的运动信息列表。
[0194]
图21结合图8示出了此实施例。在这种情况下,与图8中的模块821相对应的模块2121仅在于将在编码单元层级获得的最佳运动矢量包括在运动矢量列表的第一位置处。但是与编码单元层级情况相比,没有推导新的运动矢量。因此,对于每个子编码单元,仅评估编码单元层级的最佳运动矢量。该实施例的优点是存储器访问的最坏情况显著减小,而对编码效率的影响小。实际上,与步骤821相比,步骤2121不需要新的存储器访问。
[0195]
当该实施例与先前的实施例相结合时,并且当通过运动矢量细化改变了在编码单元层级获得的最佳运动矢量时,需要去除一个预测值而不增加预测值的数量,并保持预测值的数量被局限为n。实际上,与列表2111相比,mv细化2114或814可以生成新的矢量。因此,需要去除一个矢量以具有相同数量的矢量。
[0196]
在一个实施例中,此约束仅适用于典型地为4
×
4、4
×
8和8
×
4块的小的块大小(cu大小),以减少最坏情况下的存储器访问,而不降低对于其他编码单元大小的编码效率。
[0197]
下表给出了在启用此实施例时关于对于4
×
4块的对于传统合并模式和用于各匹配模式的fruc合并模式的最坏情况复杂性所访问的存储器的一些数字:
[0198]
[0199]
如图14所示的对运动矢量最佳候选的细化会生成额外的存储器访问。在另一个实施例中,运动矢量细化的潜在位置被限于已经在缓冲器中的像素。
[0200]
图22示出了该实施例。该图基于图14。与图14相比,通过本实施例,运动矢量细化的潜在位置被限于缓冲器225中的像素。这意味着,除对于最佳运动矢量815的模板被访问的像素位置外,无权访问新的像素位置。当然,根据实现,缓冲器可以包含不同的像素。因此,在该实施例中,运动矢量被限于仅使用初始运动矢量位置的双线性内插所需的像素。
[0201]
为了识别运动矢量位置在缓冲区之外,可以使用以下条件:
[0202]
if((mvcandx>>mvres!=mvcurcenterx>>mvres)or((mvcandy>>mvres!=mvcurcenterx>>mvres))
[0203]
其中(mvcandx,mvcandy)是运动矢量被测试位置,而(mvcurcenterx,mvcurcentery)是初始块的运动矢量或前一细化步骤的初始位置。“>>”是右移运算符。mvres表示当前子像素分辨率的比特数。例如,在当前分辨率为1/16-图素时,mvres等于4。
[0204]
此外,需要考虑指向缓冲器内部的全像素位置的搜索位置。因此,第一个条件变为:
[0205]
if(((mvcandx>>mvres!=mvcurcenterx>>mvres)and(mvcandx%16!=0))
[0206]
or((mvcandy>>mvres!=mvcurcenterx>>mvres)and(mvcandy%16!=0)))
[0207]
其中“%”是取模运算符。
[0208]
如果最大子像素分辨率不是16分之一子像素,则数字16可以改变。
[0209]
对于mvcurcenterx或mvcurcentery处于全像素分辨率的特殊情况,需要确定附加行缓冲器在mvcurcenterx%16等于0时是在左侧还是在右侧,或者在mvcurcentery%16时是在上方还是在下方。实际上,如果先前条件用于全像素分辨率的块,则无法进行任何细化。
[0210]
因此,当mvcurcenterx%16等于0时,将添加以下条件以检查被测试位置是否仅需要左侧行而不需要右侧行:
[0211]
((mvcandx>>mvres)-(mvcurcenterx>>mvres))<0
[0212]
图23示出了在该实施例中使用的不同的示例性搜索示图。
[0213]
对于图22的示例,示图231示出了与由示图131示出的菱形搜索图案位置相比的受本实施例约束的菱形搜索图案位置。
[0214]
此实施例的优点在于,在执行图8的步骤814和824时不需要新的存储器访问。
[0215]
由于该约束减少了被测试位置的数量,因此编码效率会轻微地劣化。为了减少劣化,可以添加一些位置来替换被避开的位置。
[0216]
生成这些位置的一种可能方法是将反偏移量除以2以添加到中心位置。为新的mvcandx获取此值的一个可能的式子可以是:
[0217]
mvcandx=mvcurcenterx-(mvcandx-mvcurcenterx)/2;
[0218]
示图232示出了用于此实施例的菱形搜索的结果。与示图231相比,添加了两个新的像素位置。
[0219]
生成位置的另一种可能方法是添加在菱形内部的四分之一像素位置处的所有位置,如示图233中所示,或者添加可能的存储缓冲器234内部的四分之一像素处的所有位置。在此情况下,运动矢量细化的3个步骤1302、1304和1306可以被这些实施例替换。还请注意,
在拐角处表示的全像素位置也被测试,如示图234所示。
[0220]
与示图231相比,生成位置的另一种可能的方法生成示图235中表示的附加位置。
[0221]
生成位置的另一种可能的方法是当如示图236所示,被指向的块位于缓冲器外部时,将mvcandx或mvcandy设置为等于缓冲器的最大全像素位置。
[0222]
在附加实施例中,将运动矢量细化应用于列表的每个运动矢量预测值,并选择最佳的一者。实际上,通过此实施例,对于运动矢量细化过程,不需要访问新的像素。此附加实施例提供了比当前运动矢量fruc推导更好的编码效率。
[0223]
在一个实施例中,将运动矢量细化应用于具有运动矢量的其他编码模式,并且施加对mv细化的约束。如果例如使用双边匹配,则此实施例提高了编码效率,而没有任何新的存储器访问。
[0224]
所描述的实施例的所有可能的组合都是可能的。
[0225]
下表列出了在启用所有建议的最坏情况减少方法时,关于对于4
×
4块的对于传统合并模式和用于各匹配模式的fruc合并模式的最坏情况复杂性所访问的存储器的一些数字。
[0226][0227]
当在仅n=3个预测值的情况下启用所有这些实施例时,最坏情况小于经典运动补偿的当前最坏情况的两倍。
[0228]
本发明的一个或多个实施例可以在计算设备中实现。计算设备可以是诸如微型计算机、工作站或轻便便携式设备之类的设备。计算设备包括通信总线,其连接到:
[0229]-中央处理单元,例如微处理器,表示为cpu;
[0230]-随机存取存储器,表示为ram,用于存储本发明实施例的方法的可执行代码,以及适于记录用于实现根据本发明的实施例的用于对图像的至少一部分进行编码或解码的方法所必需的变量和参数的寄存器,其存储容量可以通过例如连接到扩展端口的可选ram来扩展;
[0231]-只读存储器,表示为rom,用于存储用于实现本发明的实施例的计算机程序;
[0232]-网络接口通常连接到通信网络,通过该通信网络发送或接收要处理的数字数据。网络接口可以是单个网络接口,或者由一组不同的网络接口(例如,有线和无线接口,或者不同种类的有线或无线接口)组成。在cpu中运行的软件应用程序的控制下,数据分组被写入网络接口以进行发送或被从网络接口读取以进行接收。
[0233]-用户界面可用于接收来自用户的输入或向用户显示信息;
[0234]-表示为hd的硬盘可被提供为大容量存储设备;
[0235]-i/o模块可以用于从诸如视频源或显示器的外部设备接收数据/向该外部设备发送数据。
[0236]
可执行代码可以存储在只读存储器中、硬盘上或可拆装数字介质(例如磁盘)上。根据变型,可以经由网络接口通过通信网络来接收程序的可执行代码,以便将其存储在通信设备的存储装置之一中,例如硬盘中,然后再执行。
[0237]
中央处理单元适于控制和引导根据本发明实施例的一个或多个程序的指令或软件代码的各部分的执行,这些指令被存储在上述存储装置之一中。在加电之后,cpu能够在例如已经从程序rom或硬盘(hd)加载了来自主ram存储器的与软件应用有关的指令之后,执行那些指令。这种软件应用程序在由cpu执行时使得执行附图所示的流程图的步骤。
[0238]
附图所示算法的任何步骤都可以通过可编程计算机(例如pc(“个人计算机”),dsp(“数字信号处理器”)或微控制器执行一组指令或程序而以软件实现;或者通过机器或专用组件(例如fpga(“现场可编程门阵列”)或asic(“专用集成电路”))以硬件实现。
[0239]
尽管以上已经参考特定实施例描述了本发明,但是本发明不限于特定实施例,并且对于本领域技术人员而言,在本发明的范围内的修改将是显而易见的。
[0240]
在参考前述说明性实施例时,许多进一步的修改和变型将向本领域技术人员给出启示,前述说明性实施例仅以示例的方式给出并且不预期限制本发明的范围,本发明的范围仅由所附权利要求确定。特别地,在适当的情况下,来自不同实施例的不同特征可以互换。
[0241]
在权利要求中,词语“包括”不排除其他元件或步骤,并且不定冠词“一”或“一个”不排除多个。在互不相同的从属权利要求中记载不同特征这一事实并非指示不能有利地使用这些特征的组合。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。