1.本发明属于数据处理技术领域,特别是涉及一种基于域自适应迁移学习的放疗计划剂量分布预测方法。
背景技术:
2.为了取得临床可接受的疗效,医生往往需要通过反复的人工试错来设计符合临床要求的放疗计划,并生成满意的剂量分布图。这个过程不仅耗时费力,还严重依赖于医生的主观经验。
3.近年来深度学习的发展在一定程度上提高了放疗计划的效率和质量,但仍存在以下局限:(1)当前绝大多数基于深度学习的放疗计划自动设计方法都依赖于大规模数据驱动。对于某些低发病率的癌症而言,如单性别发病的宫颈癌,临床可获得的数据十分稀缺,难以保证深度学习模型具有良好的泛化性。(2)为了缓解这一问题,最近的剂量预测方法利用微调式迁移学习来减少模型训练所需的数据量,然而微调可能使目标模型过载并引入无关知识,从而误导目标模型的学习,即导致负迁移问题。
技术实现要素:
4.为了解决上述问题,本发明提出了一种基于域自适应迁移学习的放疗计划剂量分布预测方法,利用域自适应迁移学习减轻数据量的依赖和缓解负迁移问题,从而提高模型的性能和泛化性。
5.为达到上述目的,本发明采用的技术方案是:一种基于域自适应迁移学习的放疗计划剂量分布预测方法,包括步骤:
6.步骤1:预训练阶段,利用聚合域数据训练的聚合网络来存储来自源域的放疗计划剂量知识;
7.步骤2:迁移阶段,构建一个与聚合网络具有相同结构的目标网络,同时固定聚合网络的参数;分别从特征级别和图像级别约束目标网络的参数,即通过注意确定的过滤器和确定的样本来更新参数;
8.步骤3,利用目标网络对输入的采集图像进行学习获取放疗计划剂量分布预测。
9.进一步的是,利用聚合域数据训练的聚合网络来存储来自源域的知识,包括步骤:
10.将源域ds和目标域d
t
的输入分别表示为xs和x
t
,对应的标签表示为ys和y
t
,给定从ds和d
t
中随机采样的样本对(xs,ys)和(x
t
,y
t
),获得聚合样本对(xa,ya);
11.使用聚合域数据,通过损失函数预训练聚合网络。
12.进一步的是,步骤2:迁移阶段中:
13.在特征层面,将特征级加权知识迁移模块应用到聚合网络和目标网络的每个编码层的输出,通过一个特征级损失试图保留两个域之间共享知识的滤波器;
14.在图像层面,在两个网络的输出端采用了一个图像级加权知识迁移模块,为不同的目标域样本指定不同的权值,从而使得难迁移的样本对图像级损失的贡献更大。
15.进一步的是,在迁移阶段所述特征级加权知识迁移模块中,包括步骤:
16.提供一个特征级损失函数,为:
[0017][0018]
式中:ω和ω
*
分别表示目标网络和聚合网络的参数;ω/ω
*
是目标网络的解码器参数;β是一个平衡系数;
[0019]
第一项是特征级损失的主体部分它负责约束两个网络的特征一致性,实现特征级别知识迁移;
[0020]
第二项是正则化项ω(ω/ω
*
)来约束目标网络的参数。
[0021]
进一步的是,所述正则化项中采用损失来最小化参数:
[0022][0023]
进一步的是,所述特征级损失的主体部分为:
[0024][0025]
式中:和分别是聚合网络a和目标网络t的三个编码层中的n个滤波器中的第j个滤波器产生的向量化特征图;wj为滤波器的权重,屏蔽掉该滤波器带来的性能变化作为该滤波器的权重。
[0026]
进一步的是,设置滤波器的权重wj,包括步骤:
[0027]
先设置聚合网络中第j个滤波器的参数为零,输入目标域数据x
t
后,当前预测损失和原始预测损失之间的差距即为权重wj,权重越大意味着滤波器j包含的对目标任务更多有帮助的知识或者两域共有的知识;
[0028]
使用softmax函数对wj进行标准化,以确保所有权重wj的非负性:
[0029][0030]
式中:ω
*\j
表示移除聚合网络的第j个滤波器后网络的权重,l表示损失。
[0031]
进一步的是,在迁移阶段所述图像级加权知识迁移模块中,将目标域数据x
t
同时输入到聚合网络和目标网络,分别生成剂量图和通过计算剂量图和的差异来衡量难度,并将其作为该输入图像的权重。
[0032]
进一步的是,在迁移阶段所述图像级加权知识迁移模块中,包括步骤:
[0033]
计算概率图p
t
来衡量和y
t
之间的差异:
[0034][0035]
式中:和h和w分别表示剂量图的高和宽,表示和y
t
像素值的绝对差;
[0036]
对目标域中每个样本,计算其权重
[0037]
[0038]
式中:表示概率图p
t
中的逐个像素;通过应用sigmoid函数,被映射到(0,1);
[0039]
将权重与目标网络输出与真实剂量图y
t
之间的距离相乘得到图像级损失:
[0040]
综上所述,迁移阶段的总损失为:
[0041]
式中:λ
fw
和λ
iw
是用于平衡这两个模块贡献的超参数。
[0042]
进一步的是,两个超参数随着训练次数的增加而减小,更新公式:
[0043][0044]
式中:λ
*
表示两个模块的超参数,是它们的初始值;一个epoch表示:所有的数据送入网络中,完成了一次前向计算和反向传播的过程,total_epoch是总epoch,current_epoch是当前epoch。
[0045]
采用本技术方案的有益效果:
[0046]
本发明利用迁移学习方法来减轻深度学习模型对数据量的依赖,从而提高了模型的泛化性。由于当前微调式迁移学习带来的负迁移问题,本发明进一步提出了一种新颖的域自适应迁移学习方法,即两阶段渐进式迁移学习,通过两阶段、多层面的迁移,本发明可以自然地缩小两个域之间的差距,有选择性地迁移从源域到目标域的知识。
附图说明
[0047]
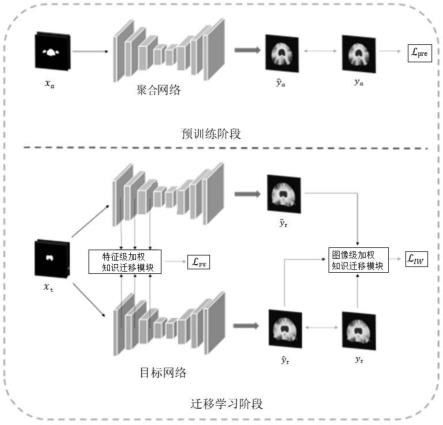
图1为本发明的一种基于域自适应迁移学习的放疗计划剂量分布预测方法的原理示意图;
[0048]
图2为本发明实施例中特征级加权知识迁移模块的原理图;
[0049]
图3为本发明实施例中图像级加权知识迁移模块的原理图;
[0050]
图4为本发明实施例中特征图权重wj的细节处理原理图。
具体实施方式
[0051]
为了使本发明的目的、技术方案和优点更加清楚,下面结合附图对本发明作进一步阐述。
[0052]
在本实施例中,参见图1所示,本发明提出了一种基于域自适应迁移学习的放疗计划剂量分布预测方法,包括步骤:
[0053]
步骤1:预训练阶段,利用聚合域数据训练的聚合网络来存储来自源域的放疗计划剂量知识;
[0054]
步骤2:迁移阶段,为了进一步将知识从聚合域迁移到目标域,本发明构建一个与聚合网络具有相同结构的目标网络,同时固定聚合网络的参数;分别从特征级别和图像级别约束目标网络的参数,即通过注意确定的过滤器和确定的样本来更新参数;
[0055]
步骤3,利用目标网络对输入的采集图像进行学习获取放疗计划剂量分布预测。
[0056]
作为上述实施例的优化方案,利用聚合域数据训练的聚合网络来存储来自源域的知识,包括步骤:
[0057]
将源域ds和目标域d
t
的输入分别表示为xs和x
t
,对应的标签表示为ys和y
t
,给定从ds和d
t
中随机采样的样本对(xs,ys)和(x
t
,y
t
),获得聚合样本对(xa,ya);
[0058]
公式为:
[0059]
xa=λxs (1-λ)x
t
;
[0060]
ya=λys (1-λ)y
t
;
[0061]
式中:λ~beta(α,α),用于平衡源域和目标域的贡献,α∈(0, ∞)。
[0062]
使用聚合域数据,通过损失函数预训练聚合网络。
[0063]
所述损失函数为:
[0064][0065]
式中:是以xa作为输入的聚合网络预测的剂量图。
[0066]
通过这种方式,本发明将知识从源域迁移到聚合域,从而使后续到目标域的知识迁移过程更加顺畅。
[0067]
作为上述实施例的优化方案,步骤2:迁移阶段中:
[0068]
在特征层面,将特征级加权知识迁移模块应用到聚合网络和目标网络的每个编码层的输出,通过一个特征级损失试图保留两个域之间共享知识的滤波器;
[0069]
在图像层面,在两个网络的输出端采用了一个图像级加权知识迁移模块,为不同的目标域样本指定不同的权值,从而使得难迁移的样本对图像级损失的贡献更大。
[0070]
具体的,如图2所示,在迁移阶段所述特征级加权知识迁移模块中,包括步骤:
[0071]
由于源域和目标域之间存在分布差距,并不是所有的源域知识对目标域任务都是有帮助的。因此,本发明提供一个特征级损失函数,为:
[0072][0073]
式中:ω和ω
*
分别表示目标网络和聚合网络的参数;ω/ω
*
是目标网络的解码器参数;β是一个平衡系数;
[0074]
第一项是特征级损失的主体部分它负责约束两个网络的特征一致性,实现特征级别知识迁移;
[0075]
为了保证目标网络的参数不会偏离聚合网络的参数太远,本发明添加了第二项是正则化项ω(ω/ω
*
)来约束目标网络的参数。
[0076]
其中,所述正则化项中采用损失来最小化参数:
[0077][0078]
其中,所述特征级损失的主体部分为:
[0079][0080]
式中:和分别是聚合网络a和目标网络t的三个编码层中的n个滤波器中的第j个滤波器产生的向量化特征图;wj为滤波器的权重,屏蔽掉该滤波器带来的性能变化作为该滤波器的权重,设置滤波器的权重wj,包括步骤:
[0081]
如图4所示,先设置聚合网络中第j个滤波器的参数为零,输入目标域数据x
t
后,当前预测损失和原始预测损失之间的差距即为权重wj,权重越大意味着滤波器j包含的对目标任务更多有帮助的知识或者两域共有的知识;
[0082]
使用softmax函数对wj进行标准化,以确保所有权重wj的非负性:
[0083][0084]
式中:ω
*\j
表示移除聚合网络的第j个滤波器后网络的权重,l表示损失。
[0085]
具体的,如图3所示,在迁移阶段所述图像级加权知识迁移模块中,由于目标域和源域存在差异,在聚合网络上表现较差的目标域数据实际上包含更多目标域特定的知识,因此本方法设计了此模块来更好地利用这些难例样本,实现迁移过程中目标域特有知识的挖掘。将目标域数据x
t
同时输入到聚合网络和目标网络,分别生成剂量图和通过计算剂量图和的差异来衡量难度,并将其作为该输入图像的权重。这样,目标域中与源域分布相似的图像具有较小的权重,相反地,与源域差异较大的目标域图像会被赋予较大的权重。基于这一难例挖掘的思想,目标网络将更倾向于关注权重较大的图像,从而捕获目标域特有的特征。
[0086]
在迁移阶段所述图像级加权知识迁移模块中,包括步骤:
[0087]
计算概率图p
t
来衡量和y
t
之间的差异:
[0088][0089]
式中:和h和w分别表示剂量图的高和宽,表示和y
t
像素值的绝对差,通过额外的对数操作使差异更显著;
[0090]
对目标域中每个样本,计算其权重
[0091][0092]
式中:表示概率图p
t
中的逐个像素;通过应用sigmoid函数,被映射到(0,1);
[0093]
将权重与目标网络输出与真实剂量图y
t
之间的距离相乘得到图像级损失:
[0094]
综上所述,迁移阶段的总损失为:
[0095]
式中:λ
fw
和λ
iw
是用于平衡这两个模块贡献的超参数。
[0096]
在训练早期,聚合网络有利于将知识转移到目标网络,而随着训练的进行,这些与直肠癌相关的知识可能是一种噪音,并且会阻碍对宫颈癌目标网络的学习。所以两个超参数随着训练次数的增加而减小,更新公式:
[0097][0098]
式中:λ
*
表示两个模块的超参数,是它们的初始值;一个epoch表示:所有的数据送入网络中,完成了一次前向计算和反向传播的过程,total_epoch是总epoch,current_
epoch是当前epoch。
[0099]
本发明实现了一种基于两阶段渐进式深度迁移学习的剂量分布预测方法。考虑到:(1)临床上直肠癌的发病率远高于宫颈癌,具有丰富的临床数据;(2)直肠癌和宫颈癌放疗计划数据有相同的ct(电子计算机断层扫描)扫描区域和危及器官,且二者的ptv处方剂量也相同,于是本发明以直肠癌为源域,宫颈癌为目标域构建域自适应迁移学习方法来提高模型在宫颈癌剂量预测任务中的性能。本发明主要创新点是:(1)提出了一种渐进式的迁移学习策略,可以在一定程度上缩小源直肠癌域和目标宫颈癌域之间的巨大差距,缓解负迁移问题;(2)与传统的微调式策略不同,本方法在生成的聚合域中预训练聚合网络,使聚合网络提前感知目标域,同时加速网络的收敛;(3)设计了一个特征级加权知识迁移模块和一个图像级加权知识迁移模块,分别在特征级和图像级选择性地迁移对目标任务更有帮助的知识,并且分别更加关注域共享的知识和域特定的知识;(4)评估了本发明对130名直肠癌患者和42名宫颈癌患者的有效性,实验结果表明本发明的性能目前是最先进的。
[0100]
将本发明与目前6个表现最好的剂量分布预测方法进行对比,实验结果证明本发明在计划靶区(ptv)和危及器官(oars)的绝大多数指标上都取得了最好的预测结果,比如在ptv的hi(异质性指数)和ci(适形指数)指标上,本发明的方法分别得到了0.008和0.017的平均预测误差,且t检验后的12个p值中有9个小于0.05,说明了本发明在实验样本少的情况下仍具有显著性改进;在oars的d
mean
(平均剂量)和v
40
(接受大于等于40gy的体积分数)指标上,分别得到了0.003和0.005的平均预测误差;指标psnr(峰值信噪比)为43.636db。此外,本发明还与对比方法进行了dvh曲线(剂量体积直方图)和可视化图的对比,显示了本发明的预测结果总与真实结果最接近。
[0101]
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。