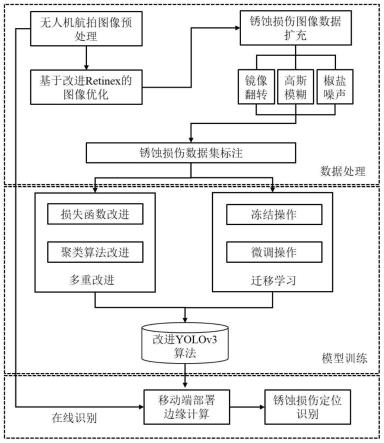
1.技术领域总体涉及基于捕获的图像数据生成虚拟视图。特别地,描述涉及虚拟视图视角改变。更具体地,描述涉及用于基于由捕获设备捕获的输入场景来生成虚拟相机的虚拟视图的系统和方法,该捕获设备包括物理相机与位于同一位置或在空间上分离的深度传感器。
背景技术:
2.现代车辆通常配备有一个或多个光学相机,其配置为向车辆乘员提供图像数据。例如,图像数据显示车辆周围环境的预定视角。
3.在某些条件下,可能希望将视角改变到由光学相机提供的图像数据上。为此,使用所谓的虚拟相机,并且修改由一个或多个物理相机捕获的图像数据,以从另一个期望的视角显示捕获的场景;修改后的图像数据可被称为虚拟场景或输出图像。虚拟场景上的期望视角可以根据乘员的愿望而改变。虚拟场景可以基于从不同视角捕获的多个图像来生成。然而,合并来自位于不同位置的图像源的图像数据可能会在虚拟图像中造成不期望的伪像。
4.因此,期望提供用于生成由物理相机捕获的场景的虚拟视图的系统和方法,具有虚拟场景的改进质量,保持捕获的场景的三维结构,并且能够改变观看虚拟场景的视角。
5.此外,结合附图和前述技术领域和背景技术,从随后的详细描述和所附权利要求中,本发明的其他期望特征和特性将变得显而易见。
技术实现要素:
6.提供了一种用于基于输入场景生成虚拟相机的虚拟视图的方法。在一实施例中,该方法包括:由捕获设备捕获输入场景;由控制器确定捕获设备的实际姿态;由控制器确定用于显示虚拟视图的虚拟相机的期望姿态;由控制器定义捕获设备的实际姿态和虚拟相机的期望姿态之间的极几何;由控制器基于捕获设备的实际姿态、输入场景和虚拟相机的期望姿态之间的极关系,为虚拟相机生成输出图像。
7.在一实施例中,该方法包括由物理相机与位于同一位置的深度传感器捕获输入场景。由捕获设备捕获输入场景包括由物理相机捕获输入图像;由深度传感器将深度信息分配给输入图像的像素;由控制器确定捕获设备的实际姿态包括由控制器确定物理相机的实际姿态;由控制器定义捕获设备的实际姿态和虚拟相机的期望姿态之间的极几何包括由控制器定义物理相机的实际姿态和虚拟相机的期望姿态之间的极几何;并且由控制器为虚拟相机生成输出图像包括:由控制器以极坐标对输入图像的像素的深度信息进行重采样;由控制器识别物理相机的输入极线上的目标像素;由控制器为虚拟相机的一条或多条输出极线生成视差图;以及由控制器基于一条或多条输出极线生成输出图像。
8.在一实施例中,由控制器识别物理相机的输入极线上的目标像素包括由控制器最小化方向成本函数以识别目标像素。
9.在另一实施例中,对于一条或多条输出极线中的每一条的每个输出像素执行由控制器最小化方向成本函数以识别目标像素。
10.在另一实施例中,该方法还包括由控制器通过最小化方向成本函数来为每个输出像素确定沿输出极线的视差。
11.在另一实施例中,由控制器基于一条或多条输出极线生成输出图像包括由控制器通过以确定的视差获取像素来生成输出图像。
12.在另一实施例中,方向成本函数被定义为:
[0013][0014]
并且根据以下来进行最小化方向成本函数:
[0015][0016]
其中:
[0017]
dc是方向成本函数;
[0018]
m是沿着物理相机的输入极线的像素;
[0019]
是从虚拟相机中心指向虚拟相机的输出极线上的像素方向的单位向量,对于该单位向量,沿着物理相机的输入极线上的对应物理像素m将被识别;
[0020]
是物理相机中心和虚拟相机中心之间的向量;
[0021]
是对应于像素m的3d点位置;
[0022]
是对于给定的对应于dc最小值的输入极线上的物理像素。
[0023]
在另一实施例中,由深度传感器将深度信息分配给输入图像的像素包括由深度传感器将深度信息分配给由物理相机捕获的每个像素。
[0024]
在另一实施例中,由深度传感器将深度信息分配给输入图像的像素包括由深度传感器基于输入图像确定由物理相机捕获的每个像素的深度信息。
[0025]
在另一实施例中,该方法包括由物理相机和与物理相机空间分离的深度传感器捕获输入场景。由捕获设备捕获输入场景包括由物理相机捕获输入图像,以及由深度传感器捕获与输入图像相关的深度数据。由控制器确定捕获设备的实际姿态包括由控制器确定物理相机的实际姿态,以及由控制器确定深度传感器的实际姿态;由控制器定义捕获设备的实际姿态和虚拟相机的期望姿态之间的极几何包括由控制器定义深度传感器的实际姿态和虚拟相机的期望姿态之间的极几何;并且由控制器为虚拟相机生成输出图像包括:由控制器为虚拟相机的期望姿态生成密集深度数据;由控制器将对于虚拟相机的期望姿态的密集深度数据投影到输入图像上;以及由控制器基于投影到输入图像上的密集深度数据生成虚拟相机的输出图像。
[0026]
在一实施例中,由控制器为虚拟相机的期望姿态生成密集深度数据包括由控制器最小化方向成本函数以估计像素的深度。
[0027]
在另一实施例中,对于输出图像的一条或多条输出极线中的每一条的每个输出像素执行由控制器最小化方向成本函数以估计像素的深度。
[0028]
在另一实施例中,该方法还包括,当深度传感器是密集深度传感器时,由深度传感器将深度信息分配给输入图像的像素,并且由控制器以极坐标对输入图像的像素的深度信息进行重采样。
[0029]
在另一实施例中,该方法还包括,当深度传感器是稀疏深度传感器时,建立查找表并将输出图像的极线映射到深度传感器的相应极线附近的点云集。
[0030]
在另一实施例中,该方法还包括由控制器最小化点云的一组相关点上的方向成本函数。优选地,通过三角测量或voronoi镶嵌将点云转换成密集深度图。
[0031]
在另一实施例中,方向成本函数被定义为:
[0032][0033]
并且根据以下来进行最小化方向成本函数:
[0034][0035]
其中:
[0036]
dc是方向成本函数;
[0037]
m是沿着物理相机的输入极线的像素;
[0038]
是从虚拟相机中心指向虚拟相机的输出极线上的像素方向的单位向量,对于该单位向量,沿着物理相机的输入极线上的对应物理像素m将被识别;
[0039]
是物理相机中心和虚拟相机中心之间的向量;
[0040]
是对应于像素m的3d点位置;
[0041]
是对于给定的对应于dc最小值的输入极线上的物理像素。
[0042]
提供了一种用于基于输入场景生成虚拟相机的虚拟视图的系统。该系统包括具有物理相机和深度传感器的捕获设备以及控制器。捕获设备配置为捕获输入场景。控制器配置为确定捕获设备的实际姿态,确定用于显示虚拟视图的虚拟相机的期望姿态,定义捕获设备的实际姿态和虚拟相机的期望姿态之间的极几何,以及基于捕获设备的实际姿态、输入场景和虚拟相机的期望姿态之间的极关系为虚拟相机生成输出图像。
[0043]
优选地,该系统配置为实现上面参考该方法的实施例描述的功能。特别地,该系统配置为实现关于物理相机和深度传感器位于同一位置的实施例描述的步骤,以及关于物理相机和深度传感器在空间上分离的实施例描述的步骤。
[0044]
在一实施例中,物理相机和捕获设备的深度传感器位于同一位置。
[0045]
在一实施例中,物理相机和深度传感器在空间上分离,例如彼此隔开。
[0046]
提供了一种车辆,其包括用于基于输入场景生成虚拟相机的虚拟视图的系统。该系统包括具有物理相机和深度传感器的捕获设备以及控制器。捕获设备配置为捕获输入场景。控制器配置为确定捕获设备的实际姿态,确定用于显示虚拟视图的虚拟相机的期望姿态,定义捕获设备的实际姿态和虚拟相机的期望姿态之间的极几何,以及基于捕获设备的实际姿态、输入场景和虚拟相机的期望姿态之间的极关系为虚拟相机生成输出图像。
[0047]
优选地,车辆中包括的系统是参照上述实施例之一描述的系统。
附图说明
[0048]
下文将结合以下附图描述示例性实施例,其中相同的附图标记表示相同的元件,并且其中:
[0049]
图1是具有实现用于生成虚拟视图的功能的控制器的车辆的示意图;
[0050]
图2是参照两个相机的极几何原理的示意图;
[0051]
图3是根据第一实施例的像素的极重投影的示意图;
[0052]
图4是根据第一实施例的用于生成虚拟视图的方法的示意图;
[0053]
图5是根据第二实施例的用于生成虚拟视图的方法的示意图;
[0054]
图6是根据第二实施例的像素的极重投影的示意图;
[0055]
图7是根据第二实施例的像素的极重投影的示意图。
具体实施方式
[0056]
以下详细描述本质上仅是示例性的,并不旨在限制应用和使用。此外,无意受在前述技术领域、背景技术、发明内容或以下详细描述中提出的任何明示或暗示的理论约束。如本文所用,术语模块是指单独或以任何组合的任何硬件、软件、固件、电子控制部件、处理逻辑和/或处理器设备,包括但不限于:专用集成电路(asic)、电子电路、处理器(共享的、专用的或成组的)和执行一个或多个软件或固件程序的存储器、组合逻辑电路和/或提供所描述功能的其他合适部件。
[0057]
这里可以根据功能和/或逻辑块部件以及各种处理步骤来描述本公开的实施例。应当理解,可以通过配置为执行指定功能的任何数量的硬件、软件和/或固件部件来实现这样的块部件。例如,本公开的实施例可以采用各种集成电路部件,例如存储器元件、数字信号处理元件、逻辑元件、查找表等,其可以在一个或多个微处理器或其他控制设备的控制下执行各种功能。另外,本领域技术人员将理解,可以结合任何数量的系统来实践本公开的实施例,并且本文描述的系统仅仅是本公开的示例性实施例。
[0058]
为了简洁起见,与信号处理、数据传输、信令、控制和系统的其他功能方面(以及系统的各个操作部件)有关的常规技术在此处可能不会详细描述。此外,本文包含的各个附图中所示的连接线旨在表示各个元件之间的示例功能关系和/或物理联接。应当注意,在本公开的实施例中可以存在许多替代或附加的功能关系或物理连接。
[0059]
参考图1,示出了根据各种实施例的车辆10。车辆10通常包括底盘12、车身14、前轮16和后轮18。车身14布置在底盘12上,并且基本封闭车辆10的部件。车身14和底盘12可以共同形成框架。车轮16和18各自在车身14的相应角部附近旋转地联接至底盘12。
[0060]
在各个实施例中,车辆10是自主车辆。自主车辆例如是被自动控制以将乘客从一个位置运送到另一个位置的车辆。车辆10在所示实施例中描述为乘用车,但应当理解,也可以使用任何其他交通工具,包括摩托车、卡车、运动型多用途车(suv)、休闲车(rv)、轮船、飞机等。在示例性实施例中,自主车辆是二级或更高级别的自动化系统。二级自动化系统表示“部分自动化”。然而,在其他实施例中,自主车辆可以是所谓的三级、四级或五级自动化系统。三级自动化系统表示条件自动化。四级系统表示“高度自动化”,是指自动驾驶系统对动态驾驶任务的所有方面的驾驶模式特定性能,即使人类驾驶员没有适当地响应干预要求。五级系统表示“完全自动化”,是指自动驾驶系统在可由人类驾驶员管理的所有道路和环境
条件下对动态驾驶任务的所有方面的全时性能。
[0061]
然而,应当理解,车辆10也可以是没有任何自主驾驶功能的传统车辆。车辆10可以实现如本文所述的用于生成虚拟视图并使用极重投影进行虚拟视图视角改变的功能和方法,以帮助车辆10的驾驶员。
[0062]
如图所示,车辆10通常包括推进系统20、传动系统22、转向系统24、制动系统26、传感器系统28、致动器系统30、至少一个数据存储设备32、至少一个控制器34和通信系统36。在各个实施例中,推进系统20可以包括内燃机、诸如牵引马达的电机和/或燃料电池推进系统。传动系统22配置成根据可选择的速比将动力从推进系统20传递至车轮16和18。根据各个实施例,传动系统22可以包括有级传动比自动变速器、无级变速器或其他合适的变速器。制动系统26配置成向车轮16和18提供制动扭矩。在各个实施例中,制动系统26可以包括摩擦制动器、线制动器、诸如电机的再生制动系统和/或其他合适的制动系统。转向系统24影响车轮16和18的位置。尽管出于说明性目的示出为包括方向盘,但在本公开范围内预期的一些实施例中,转向系统24可以不包括方向盘。
[0063]
传感器系统28包括一个或多个感测设备40a-40n,其感测车辆10的外部环境和/或内部环境的可观察到的状况。感测设备40a-40n可以包括但不限于雷达、激光雷达、全球定位系统、光学相机、热相机、超声波传感器和/或其他传感器。致动器系统30包括一个或多个致动器设备42a-42n,其控制一个或多个车辆特征,比如但不限于推进系统20、传动系统22、转向系统24和制动系统26。在各个实施例中,车辆特征还可以包括内部和/或外部车辆特征,比如但不限于门、行李箱和舱室特征,比如通风、音乐、照明等(未编号)。
[0064]
通信系统36配置为与其他实体48进行无线通信,比如但不限于其他车辆(“v2v”通信)、基础设施(“v2i”通信)、远程系统和/或个人设备(关于图2更详细地描述)。在示例性实施例中,通信系统36是无线通信系统,其配置为使用ieee 802.11标准或通过使用蜂窝数据通信经由无线局域网(wlan)进行通信。然而,在本公开的范围内还考虑了附加或替代通信方法,比如专用短程通信(dsrc)信道。dsrc信道是指专门为汽车使用而设计的单向或双向短程到中程无线通信信道以及一组相应的协议和标准。
[0065]
数据存储设备32存储用于自动控制车辆10的功能的数据。在各个实施例中,数据存储设备32存储可导航环境的所定义的地图。在各个实施例中,所定义的地图可由远程系统预先定义并从远程系统获得(参考图2更详细地描述)。例如,所定义的地图可以由远程系统组装并传送到自主车辆10(无线和/或以有线的方式)并且存储在数据存储设备32中。可以理解,数据存储设备32可以是控制器34的一部分,与控制器34分离,或者是控制器34的一部分和分离系统的一部分。
[0066]
控制器34包括至少一个处理器44和计算机可读存储设备或介质46。处理器44可以是任何定制的或可商购的处理器、中央处理单元(cpu)、图形处理单元(gpu)、与控制器34相关的多个处理器中的辅助处理器、基于半导体的微处理器(形式为微芯片或芯片组)、宏处理器、其任何组合或通常用于执行指令的任何设备。例如,计算机可读存储设备或介质46可以包括只读存储器(rom)、随机存取存储器(ram)和保持活动存储器(kam)中的易失性和非易失性存储。kam是持久性或非易失性存储器,其可以在处理器44掉电时用于存储各种操作变量。可以使用许多已知的存储设备中的任何一种来实现计算机可读存储设备或介质46,比如prom(可编程只读存储器)、eprom(电prom)、eeprom(电可擦除prom)、闪存或能够存储
数据的任何其他电、磁、光或组合存储设备,其中一些表示可执行指令,由控制器34在控制和执行车辆10的功能时使用。
[0067]
指令可以包括一个或多个单独的程序,每个程序包括用于实现逻辑功能的可执行指令的有序列表。当由处理器44执行时,指令从传感器系统28接收并处理信号,执行用于自动控制车辆10的部件的逻辑、计算、方法和/或算法,并且基于逻辑、计算、方法和/或算法生成至致动器系统30的控制信号以自动控制车辆10的部件。尽管在图1中仅示出了一个控制器34,但车辆10的实施例可以包括任意数量的控制器34,它们通过任何合适的通信介质或通信介质的组合进行通信,并且配合以处理传感器信号,执行逻辑、计算、方法和/或算法,并且生成控制信号以自动控制车辆10的特征。
[0068]
通常,根据实施例,车辆10包括控制器34,其实现用于基于由捕获设备捕获的输入场景来生成虚拟相机的虚拟视图的方法。捕获设备包括例如物理相机和深度传感器。感测设备40a至40n中的一个是光学相机,并且这些感测设备40a至40n中的另一个是物理深度传感器(如激光雷达、雷达、超声波传感器等)。
[0069]
车辆10设计成执行一种方法,该方法用于生成由物理相机40a与处于同一位置或空间分离的深度传感器40b捕获的场景的虚拟视图。
[0070]
在一实施例中,用于基于输入场景生成虚拟相机的虚拟视图的方法包括以下步骤:由包括物理相机40a和深度传感器40b的捕获设备捕获输入场景;由控制器34确定捕获设备的实际姿态;由控制器34确定用于显示虚拟视图的虚拟相机的期望姿态;由控制器34定义捕获设备的实际姿态和虚拟相机的期望姿态之间的极几何;由控制器34基于捕获设备的实际姿态、输入场景和虚拟相机的期望姿态之间的极关系生成虚拟相机的输出图像。
[0071]
在一实施例中,该方法包括以下步骤:由物理相机40a与位于同一位置的深度传感器40b捕获输入场景;其中由捕获设备捕获输入场景包括由物理相机40a捕获输入图像;由深度传感器40b将深度信息分配给输入图像的像素;其中由控制器34确定捕获设备的实际姿态包括由控制器34确定物理相机40a的实际姿态;其中由控制器34定义捕获设备的实际姿态和虚拟相机的期望姿态之间的极几何包括由控制器34定义物理相机40a的实际姿态和虚拟相机的期望姿态之间的极几何;并且其中由控制器为虚拟相机生成输出图像包括:由控制器34以极坐标对输入图像的像素的深度信息进行重采样;由控制器34识别物理相机的输入极线上的目标像素;由控制器34为虚拟相机的一条或多条输出极线生成视差图;以及由控制器34基于一条或多条输出极线生成输出图像。车辆10包括显示器50,用于向车辆10的用户或乘员显示输出图像。注意,传感器的姿态可以通过特定的姿态测量装置或姿态估计模块来测量或估计。本文所述的控制器34从这些姿态测量装置或姿态估计模块获得物理相机和/或深度传感器的姿态,即通过读取或获得特定姿态值来确定姿态,并将所确定的姿态值用于本文所述方法的步骤。
[0072]
输入图像由物理相机40a捕获,例如配置为捕获环境的彩色图片的光学相机。物理相机40a布置在车辆10处,使得它可以覆盖车辆周围的特定视野。深度信息被分配给输入图像的像素,以便获得或估计物理相机40a和由输入图像的像素表示的物体之间的距离。深度信息可以由密集或稀疏深度传感器或配置为基于图像信息确定深度的模块分配给输入图像的每个像素。
[0073]
虚拟相机40a的期望观看位置和观看方向可被称为虚拟相机的期望视角。除此之
外,可以给出虚拟相机的固有校准参数,以确定虚拟相机的视场、分辨率以及可选地或附加地其他参数。期望视角可以是由车辆用户定义的视角。因此,车辆的用户或乘员可以选择虚拟相机对车辆周围环境的视角。
[0074]
虚拟相机的期望姿态可以包括相对于参考点或参考框架的观看位置和观看方向,例如虚拟相机相对于车辆的观看位置和观看方向。期望姿态是用户希望虚拟相机位于的虚拟点,包括虚拟相机指向的方向。车辆用户可以改变期望姿态,以从不同的观看位置和不同的观看方向生成车辆及其环境的虚拟视图。
[0075]
物理相机的实际姿态被确定为具有关于从其捕获输入图像的视角的信息。
[0076]
深度传感器40b可以是物理深度传感器或基于图像信息向输入图像的像素或物体分配深度信息的模块(可以称为虚拟深度传感器)。物理深度传感器的示例是超声波传感器、雷达传感器、激光雷达传感器等。这些传感器配置成确定到物理物体的距离。由物理深度传感器确定的距离信息然后被分配给输入图像的像素。所谓的虚拟深度传感器基于图像信息确定或估计深度信息。为了为虚拟相机的姿态生成适当的输出图像,如果虚拟深度传感器提供的深度信息一致,这可能就足够了。不一定要求深度信息绝对准确。
[0077]
在另一实施例中,该方法包括由物理相机和与物理相机空间分离的深度传感器捕获输入场景。由捕获设备捕获输入场景包括由物理相机40a捕获输入图像,以及由深度传感器40b捕获与输入图像相关的深度数据;由控制器确定捕获设备的实际姿态包括由控制器34确定物理相机40a的实际姿态,以及由控制器34确定深度传感器40b的实际姿态;由控制器定义捕获设备的实际姿态和虚拟相机的期望姿态之间的极几何包括由控制器34定义深度传感器40b的实际姿态和虚拟相机的期望姿态之间的极几何;并且由控制器为虚拟相机生成输出图像包括:由控制器34为虚拟相机的期望姿态生成密集深度数据;由控制器34将对于虚拟相机的期望姿态的密集深度数据投影到输入图像上;以及由控制器34基于投影到输入图像上的密集深度数据生成虚拟相机的输出图像。
[0078]
在该实施例中,输入图像由物理相机40a捕获,例如配置为捕获环境的彩色图片的光学相机。深度数据由与物理相机40a间隔开的物理深度传感器40b捕获,即输入图像和深度数据由位于不同位置并对场景具有不同视角的传感器捕获。由控制器为虚拟相机的姿态生成密集深度数据,即从虚拟相机的期望位置可见的物体被分配有深度信息,以获得物理相机从虚拟相机捕获的物体的距离。密集深度数据被应用于输入图像,使得输入图像中示出的物体被分配关于虚拟相机的深度信息。
[0079]
通常,深度传感器40b可以是稀疏深度传感器或密集深度传感器。稀疏深度传感器为输入图像的一些像素和区域提供深度信息,但不是所有像素。稀疏深度传感器不能提供连续的深度图。密集深度传感器为输入图像的每个像素提供深度信息。当深度传感器是密集深度传感器时,深度值到虚拟相机的图像上的重投影被执行,如在具有位于同一位置的深度传感器的实施例中。
[0080]
图1总体示出了车辆10,其包括用于基于输入场景生成虚拟相机的虚拟视图的系统。该系统包括物理相机40a、深度传感器40b(或者与物理相机位于同一位置,或者在空间上与其分离)和控制器34。该系统配置为执行这里描述的两种方法的步骤。
[0081]
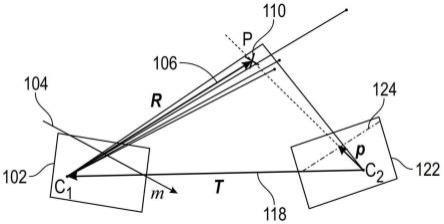
图2示例性地示出了关于具有相机中心c1的第一相机102和具有相机中心c2的第二相机112的极几何原理。第一极线104被限定在第一相机102中。光线106定义像素p(用110
表示)在极线104上的位置。同一像素p 110的位置也由从第二相机112的相机中心c2延伸到像素p的光线116在极线114上定义。参考符号118是两个相机中心c1和c2之间的向量。给定向量118和像素p在极线104上的已知位置以及相机中心c1和像素p之间的距离,可以确定像素p在极线114上的位置。利用这一基本原理,由第一相机102捕获的场景可被用来计算场景,如同它将被第二相机112观察一样。第二相机112的虚拟位置可以变化。因此,当第二相机112的位置改变时,极线114上的像素的位置也改变。在本文描述的各种实施例中,启用虚拟视图视角改变。这种虚拟视图视角改变可以有利地用于生成环绕视图和用于拖车应用。使用极几何来生成虚拟视图考虑了车辆环境的三维特性,特别是在生成第二相机112的虚拟视图时,通过考虑像素p的深度(像素p和第一相机102的相机中心c1之间的距离)。
[0082]
在各种实施例中,该方法包括:通过定义期望的观看方位和位置(第二相机112)与第一相机102的深度传感器姿态之间的极几何,使用深度辅助的极重投影,通过最小化方向成本函数为要由虚拟相机生成的图像的每个输出像素找到沿极线的视差,以及通过以计算的视差获取像素来生成输出图像。注意,视差涉及位于不同位置的相机上的像素位置之间的差异。视差与不同位置的物体和相机之间的距离有关。该距离越大,物体或代表该物体的像素的视差越小。
[0083]
图3示意性地示出了应用于具有虚拟相机122的特定用例的图2的基本关系。具有第一极线104的第一相机102用于捕获环境。由第一相机102捕获多个像素p及其沿极线104的位置以及像素距相机中心c1的距离。光线r 106指示像素p 110沿着极线104的位置。利用相机中心c1和像素p之间的已知距离以及物理相机的中心c1和虚拟相机122的中心c2之间的向量t118,可以确定像素p 110在虚拟相机122的极线124上的位置。
[0084]
在图3中,是来自虚拟相机112中心c2的单位向量,其指向极线124上的像素110的方向,对于该单位向量,物理相机的极线104上的对应像素m将被识别。是相机中心c1和c2之间的向量。是对应于像素m的3d点位置。是对于给定的对应于方向成本函数的最小值的极线104上的物理像素,其中方向成本函数被定义为:
[0085][0086]
并且其最小值被确定为:
[0087][0088]
图4示意性地示出了用于生成由物理相机与位于同一位置的深度传感器捕获的场景的虚拟视图的方法的第一实施例。在141,捕获视点姿态数据(虚拟相机122的位置和方向)。该信息可以由车辆10的用户或乘员选择,并且对应于用于观看周围场景的虚拟相机的期望位置。在142,获取输入相机102姿态数据。注意,在141和142,可以优选地获取视点姿态数据和/或输入相机姿态数据的固有校准参数。例如,视角相机的固有参数通常包括焦距、主点、失真模型等。在143,使用输入相机102姿态数据和虚拟相机122的期望姿态数据来定义物理相机(即输入相机)102和虚拟相机122之间的极几何。为了定义极几何,可以使用视点姿态数据和/或输入相机的固有校准参数。在144,接收包括输入图像(从物理相机接收)的深度信息的输入深度图,并且在145,接收输入图像。基于在143生成的极几何,在146,以
极坐标对144的输入深度图和145的输入图像进行重采样。在147,对于每个输出像素和(虚拟相机的输出图像的)每个输出极线,方向成本被最小化,以在相应的输入极线上找到目标像素。然后,在148,创建视差图,其是在149生成要由虚拟相机显示的输出图像的基础。图4所示的步骤优选地用于基于物理相机与位于同一位置的深度传感器或基于输入图像提供深度信息的单深度模块(depth-from-mono-module)的输入图像生成虚拟相机的输出图像。
[0089]
图3和相关描述指出了如何对与物理(输入)相机位于同一位置的深度传感器进行极重投影。极几何以期望的位置和观看方向定义在输入物理相机102和虚拟相机122之间,并且对于每个输出像素最小化方向成本以找到输出像素视差。
[0090]
图5示意性地示出了用于生成由物理相机与空间分离的深度传感器捕获的场景的虚拟视图的方法的第二实施例。在153,基于在151检索的虚拟相机的视点姿态数据(如用户所期望或选择的)和在156从与物理相机在空间上分离的物理深度传感器检索的深度传感器姿态数据来定义极几何。在151和156,可以优选地获取视点姿态数据和/或深度传感器姿态数据的固有校准参数。视点姿态数据和/或深度传感器姿态数据的固有校准参数然后可以用于定义极几何。在153定义的极几何和在154从深度传感器检索的输入深度数据用于在157最小化每个输出极线的每个输出像素的方向成本,以估计输出像素的深度。基于最小化的方向成本,在158生成虚拟相机的观看点的密集深度数据。在158生成的密集深度数据、在152检索的输入相机姿态数据(物理相机的位置和方向)以及在155检索的输入图像155在159被用来将密集深度数据投影到输入相机上,并找到在160用于生成虚拟相机的输出图像的目标像素。在152,可以优选地获取输入相机姿态数据的固有校准参数。例如,视角相机的固有参数通常包括焦距、主点、失真模型等。
[0091]
图6和图7参考输入物理相机102(具有中心cp)、虚拟相机122(具有中心cv)和深度传感器130(具有中心cd)来描述图5的过程,深度传感器130与物理相机102在空间上分离且位于不同的位置并与物理相机102间隔开。
[0092]
最初,极几何定义在深度传感器130和虚拟相机122之间。深度传感器130确定深度传感器130的视野中不同点的深度数据136(针对一组点云点示出)。极几何被定义为参考图3所述。然而,在图6中,深度传感器的极线134、虚拟相机的极线124以及深度传感器130的中心cd和虚拟相机122的中心cv之间的向量128被用于定义极几何。如果深度传感器130是密集的,则如参考图3和图4所述,执行深度值在虚拟相机上的极重投影。如果深度传感器是稀疏的,则建立查找表,将虚拟相机极线映射到深度传感器的相应极线附近的点云点集。对于每个输出像素,方向成本在一组相关点云点上最小化。密集虚拟相机深度图被投影到物理相机的输入图像上,以找到相应的输入像素,并将深度信息分配给输入像素,如图7所示。为了加快程序,稀疏点云可以通过三角测量或voronoi镶嵌转换成密集深度图。然后,密集深度图可用于深度值在虚拟相机上的极重投影,如上所述。
[0093]
应当理解,车辆10的控制器34实现参照图3至图7描述的功能,而车辆10的传感器提供所需的信息,即物理相机提供输入图像,深度传感器,无论是位于同一位置还是空间分离的深度传感器,都提供深度信息。深度信息可以通过所谓的单深度技术从输入图像中获得。
[0094]
由于场景的三维结构的真实表示,在视角改变之后,可能会发生捕获场景中的物体遮挡。通常,遮挡检测不是极重投影的一部分。然而,被遮挡区域的典型特征是方向成本
函数值非常高,因此可被检测到。除了纯方向项之外,可以通过包括所谓的数据平滑项来正则化成本函数,所述数据平滑项包括例如输出图像中相邻像素的色差之和。优选地,使用最近邻插值(相当于最佳视差的整数值)来避免在大的深度差上产生错误的斜率。然而,对于稀疏数据,根据深度差异,可以使用更复杂的插值模块。
[0095]
虽然在前面的详细描述中已经呈现了至少一个示例性实施例,但应当理解,存在大量的变化。还应当理解,一个或多个示例性实施例仅是示例,并不旨在以任何方式限制本公开的范围、适用性或配置。相反,前述详细描述将为本领域技术人员提供用于实现一个或多个示例性实施例的便利路线图。应当理解,在不脱离所附权利要求及其法律等同物中阐述的本公开的范围的情况下,可以对元件的功能和布置进行各种改变。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。