1.本发明涉及知识蒸馏技术领域,具体涉及一种样本级隐私保护的知识蒸馏方法。
背景技术:
2.随着知识蒸馏已成为一种可扩展且有效的隐私保护机器学习方法,它的一些弊端也逐渐的显露出来,例如在模型级的操作中会消耗隐私,并且每一个蒸馏查询都会消耗客户机的隐私。在当前已知的知识蒸馏范式中,有个常见的问题,如每一个被回答的查询都会导致一个客户机的所有记录的隐私损失,这是由于客户端本地训练的模型是根据这些原始记录构建的,查询的结果会受到所有单个记录的影响。这种粗劣的客户端级的隐私消耗浪费了隐私预算,且不能从每个记录中提取到有效的知识。
技术实现要素:
3.本发明的目的在于提供一种样本级隐私保护的知识蒸馏方法,通过一种改进后的局部差分隐私机制,解决背景技术中的问题。
4.为实现上述目的,本发明提供如下技术方案:
5.一种样本级隐私保护的知识蒸馏方法,包括以下步骤:
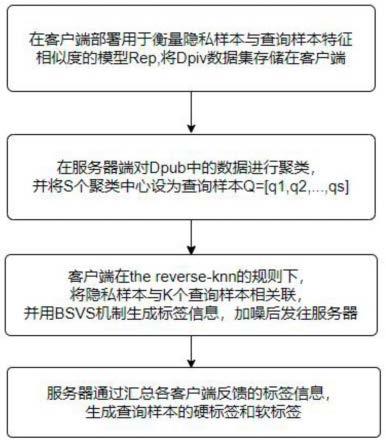
6.s1:在客户端部署用于衡量隐私样本与查询样本特征相似度的模型rep,将dpiv数据集存储在客户端;
7.s2:在服务器端对dpub中的数据进行聚类,并将s个聚类中心设为查询样本q=[q1,q2,...,qs];
[0008]
s3:客户端在the reverse-knn的规则下,将隐私样本与k个查询样本相关联,并用bsvs机制生成标签信息,加噪后发往服务器;
[0009]
s4:服务器通过汇总各客户端反馈的标签信息,生成查询样本的硬标签和软标签。
[0010]
优选的,数据集主要是训练数据集,训练数据集分为隐私数据集(dpiv)和公共数据集(dpub)两部分。
[0011]
优选的,隐私数据存储在各个客户端,使用rep模型通过隐私样本与查询样本的特征向量之间的欧式距离来衡量它们拥有同类标签的可能性。
[0012]
优选的,对公共数据集进行聚类,并将聚类中心作为查询样本发往客户端添加标签,由于公共数据集(dpub)中未被标记的样本数量庞大,若将其全部发送至客户端添加标签,在通信、计算、隐私保护方面都代价较大,在本发明中,将dpub集以非监督的方式聚为s个簇,并将聚簇中心q=[q1,q2,...,qs]设为查询样本。由于s《《number(dpub),标记公共样本的代价大大减小。
[0013]
优选的,将训练数据集以非监督的方式聚为s个簇,并将聚簇中心q=[q1,q2,...,qs]设为查询样本。
[0014]
优选的,将查询样本q=[q1,q2,...,qs]发送至各个客户端,客户端按照reverse k-nn的规则将单个隐私样本与距离最近的k个查询样本相关联,并将得到的标签信息用
添加拉普拉斯噪声后发往客户端。
[0015]
优选的,服务器将从各个客户端接受的标签信息进行聚合,并用公式得出硬标签,同时使用公式获得软标签。
[0016]
本发明提供的样本级隐私保护的知识蒸馏方法,具备以下有益效果:
[0017]
(1)、细粒度的privacy accountant:在当前大多数的联邦知识蒸馏方法中,每条私有数据的贡献和隐私损失不能在本地模型中单个表示,这种方式不仅增加了计算量,也造成了较大的隐私损失,在新方法中,把单条私有记录对查询样本的贡献限制到了k,且远小于查询样本的总量,由此获得了更细粒度privacy accountant,以及更好的知识获取;
[0018]
(2)、广泛的应用场景:与以往的联邦知识方法不同的是,在model-free reverse k-nn labeling方法中,无需数百条数据对本地模型进行训练,仅需要样本之间的距离度量,因此在cross-silo(每个客户端存储的数据量较少)和cross-device(客户端数据量充足)等场景中能够很好的应用。且在数据非独立同分布的情况下也能得到良好的训练结果;
[0019]
(3)、针对低隐私条件下的bsvs问题,本发明提供了一种改进后的局部差分隐私机制,且首次证明了在满足局部差分隐私的情况下,对于单个私有记录做知识提取的方法是可行的,并在实验过程中体现了显著的准确性。在局部隐私预算为0.4时,在cifar-10数据集上,测试精确度为85.5%,在mnist数据集上,测试精确度高达94.7%。
附图说明
[0020]
图1为本发明实施例知识蒸馏方法的流程示意图;
[0021]
图2为本发明实施例知识蒸馏方法在mnist数据集(∈=0.1)上,对于不同k,精确度随聚类数量变化示意图;
[0022]
图3为本发明实施例知识蒸馏方法在cifar-10数据集(∈=1)上,对于不同k,精确度随聚类数量变化示意图;
[0023]
图4为本发明实施例知识蒸馏方法在cifar-10数据集和mnist数据集上,使用randomized response(rr)和collision mechanism(collision)ldp机制,精确度随局部隐私预算(∈)变化示意图。
具体实施方式
[0024]
下面结合附图,对本发明的技术方案进行清楚、完整地描述。
[0025]
实施例
[0026]
如图1所示,本发明实施例提供的样本级隐私保护的知识蒸馏方法,包括以下步骤:
[0027]
s1:在客户端部署用于衡量隐私样本与查询样本特征相似度的模型rep,将dpiv数据集存储在客户端,数据集主要是训练数据集,训练数据集分为隐私数据集(dpiv)和公共数据集(dpub)两部分,隐私数据存储在各个客户端,使用rep模型通过隐私样本与查询样本的特征向量之间的欧式距离来衡量它们拥有同类标签的可能性,对公共数据集进行聚类,
并将聚类中心作为查询样本发往客户端添加标签,将训练数据集以非监督的方式聚为s个簇,并将聚簇中心q=[q1,q2,...,qs]设为查询样本;
[0028]
s2:在服务器端对dpub中的数据进行聚类,并将s个聚类中心设为查询样本q=[q1,q2,...,qs],将查询样本q=[q1,q2,...,qs]发送至各个客户端,客户端按照reverse k-nn的规则将单个隐私样本与距离最近的k个查询样本相关联,并将得到的标签信息用添加拉普拉斯噪声后发往客户端;
[0029]
s3:客户端在the reverse-knn的规则下,将隐私样本与k个查询样本相关联,并用bsvs机制生成标签信息,加噪后发往服务器;
[0030]
s4:服务器通过汇总各客户端反馈的标签信息,生成查询样本的硬标签和软标签,服务器将从各个客户端接受的标签信息进行聚合,并用公式得出硬标签,同时使用公式获得软标签。
[0031]
以上仅为在对公共数据进行标记的一轮操作,在实际训练过程中往往要重复多轮才能达到良好的训练效果。
[0032]
参见附图2-4,在隐私保护方面,本发明提供了三种隐私保护措施(中心差分隐私、局部差分隐私和置乱模型)以适应不同场景下的隐私保护需求,并以局部差分隐私保护方法为例,做了相关的实验证明。
[0033]
本发明的突出点是在非监督学习的条件下,提出了model-free reverse k-nn labeling的方法,以实现每个私有样本的有界贡献和恒定隐私预算。对于每一个私有样本来说,都与距离该样本最近的k个查询样本相关联,因此该条记录的隐私预算仅用k来衡量而并非全部的查询样本。并且在这种情况下,每一条记录对最终的结果的贡献都是相等的。与以往的联邦知识蒸馏方法相比,优势主要体现在以下两方面:
[0034]
(1)细粒度的privacy accountant
[0035]
在当前大多数的联邦知识蒸馏方法中,每条私有数据的贡献和隐私损失不能在本地模型中单个表示,这种方式不仅增加了计算量,也造成了较大的隐私损失。在新方法中,把单条私有记录对查询样本的贡献限制到了k,且远小于查询样本的总量,由此获得了更细粒度privacy accountant,以及更好的知识获取。
[0036]
(2)广泛的应用场景
[0037]
与以往的联邦知识方法不同的是,在model-free reverse k-nn labeling方法中,无需数百条数据对本地模型进行训练,仅需要样本之间的距离度量,因此在cross-silo(每个客户端存储的数据量较少)和cross-device(客户端数据量充足)等场景中能够很好的应用。且在数据非独立同分布的情况下也能得到良好的训练结果。
[0038]
在本发明中,将the model-free reverse k-nn labeling问题描述为bsvs问题(若将每个查询样本看做一个桶,则是分桶的稀疏向量求和问题),并在集中式/本地式/置乱式等隐私保护场景下提供了相应的解决方案,并提供了标签错误率对比实验数据。综上所述,本发明的关键点如下所示:
[0039]
(1)通过对在联邦知识蒸馏技术中样本级隐私保护问题的研究,在满足样本级差
分隐私的前提下,提出了the model-free reverse k-nn query labeling方法。
[0040]
(2)将the model-free reverse k-nn query labeling问题描述为分桶的稀疏向量求和问题(bsvs)并在中心差分隐私、局部差分隐私和置乱模型的情境下提供了具体的实现机制和相关的理论证明。
[0041]
(3)针对低隐私条件下的bsvs问题,本发明提供了一种改进后的局部差分隐私机制,且首次证明了在满足局部差分隐私的情况下,对于单个私有记录做知识提取的方法是可行的,并在实验过程中体现了显著的准确性。在局部隐私预算为0.4时,在cifar-10数据集上,测试精确度为85.5%,在mnist数据集上,测试精确度高达94.7%。
[0042]
实验结果表明,本发明与现有的联邦知识蒸馏方法相比,在隐私预算更小的情况下实现了实验精确度的显著提升。
[0043]
该样本级隐私保护的知识蒸馏方法,包括以下步骤:训练数据集分为隐私数据集和公共数据集两部分,隐私数据集分别存储在各个客户端,通过本地模型rep为公共数据集添加标签;对公共数据集进行聚类,并将聚类中心作为查询样本发往客户端添加标签;在客户端,通过rep模型判断单个隐私样本距离最近的k个隐私样本,用向量n表示,并将生成的标签信息,做隐私保护处理后发往服务器;服务器端接收到各个客户端发送的标签信息后,将其聚合,最终得出查询样本的硬标签,同时生成查询样本的软标签。
[0044]
本发明通过一种改进后的局部差分隐私机制,首次证明了在满足局部差分隐私的情况下,对于单个私有记录做知识提取的方法是可行的,并在实验过程中体现了显著的准确性。
[0045]
显然,所描述的上述实施例仅仅是本发明一部分实施例,而不是全部的实施例。对上述示例性实施例的描述实际上仅仅是说明性的,决不作为对本发明及其应用或使用的任何限制。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。