1.本发明涉及风力发电技术领域,尤其涉及一种基于时序匹配和双向四分位算法的异常数据清洗方法。
背景技术:
2.受风电机组停机、限电、通信噪声和设备故障等多种因素的影响,采集的风电机组实测数据通常含有大量复杂的异常运行数据,无法直接用于风电场运维效能评价、风电功率预测、风电机组发电能力评估及运行状态监测,通常需要先进行风电机组异常运行数据清洗。但是,现有风电机组异常运行数据清洗算法通常是基于离散数据的空间分布特征展开,忽略了运行数据的时序特性,无法有效辨识与正常数据空间分布特征相似的异常运行数据;且对于存在大量堆积型限电数据样本,传统的数据清洗方法无法有效识别过渡区域数据类别,容易造成正常数据的错删和异常数据的漏删问题。针对现有技术的不足,本发明提供一种基于时序匹配和双向四分位算法的异常数据清洗方法,同时适用于堆积型异常数据和分散型异常数据清洗,且能够有效辨识过渡区域内与正常数据空间分布特征相似的异常运行数据。
技术实现要素:
3.本发明的目的是提出一种基于时序匹配和双向四分位算法的异常数据清洗方法,其特征在于,包括以下步骤:
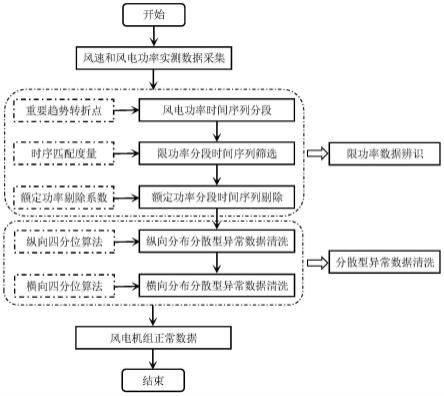
4.步骤1:采集风电机组的实测风速和风电功率数据;
5.步骤2:利用风速-风电功率时序匹配算法辨识风电机组限功率异常数据;具体包括:
6.步骤21:采用基本趋势转折点和重要趋势转折点确定算法对风电功率时间序列进行分段划分;
7.步骤22:基于风速-风电功率时序匹配度量对限功率分段时间序列进行筛选;
8.步骤23:基于额定功率剔除系数对额定功率分段时间序列进行剔除;
9.步骤3:利用双向四分位算法清洗风电功率分散型异常数据。
10.所述步骤21中的基本趋势转折点定义如下:
11.基本趋势转折点分为上升趋势转折点和下降趋势转折点;设风电功率的时间序列为p=《p1,p2,
…
,pn》,若第t时刻的风电功率p
t
满足p
t-1
≥p
t
<p
t 1
或p
t-1
>p
t
≤p
t 1
,则风电功率p
t
为上升趋势转折点;若第t时刻的风电功率p
t
满足p
t-1
≤p
t
>p
t 1
或p
t-1
<p
t
≥p
t 1
,则风电功率p
t
为下降趋势转折点。
12.所述步骤21中的重要趋势转折点定义如下:
13.对于风电功率时间序列基本转折点序列一个重要趋势转折点p
it
与两个连续的基本趋势转折点和构成的最小模式序列中,是否为重要趋势转
折点,取决于到p
it
和线段的垂直距离d,垂直距离d越大,越有可能是重要趋势转折点。
14.所述垂直距离d的大小受数值本身大小的影响,利用相对垂直距离rd和绝对波动量相结合的方式确定风电功率时间序列的重要趋势转折点;所述相对垂直距离rd和绝对波动量的计算分别如公式(1)和公式(2)所示:
[0015][0016][0017]
式中,rd为的相对垂直距离;t1为风电功率p
it
所对应的时刻;t2为风电功率所对应的时刻;t3为风电功率所对应的时刻;δp为风电功率绝对波动量;α为相对垂直距离阈值;β为绝对波动量阈值。
[0018]
所述步骤22具体包括如下子步骤:
[0019]
步骤221:采用数据时间对标法,提取不同风电功率分段时间序列所对应的风速分段时间序列;
[0020]
步骤222:计算不同分段时间序列的长度l;所述分段时间序列的长度l应满足l≥γ,γ为时长阈值;
[0021]
步骤223:计算不同分段时间序列的风速-风电功率时序匹配度,提取时序不匹配的风电功率分段时间序列。
[0022]
所述步骤223具体如下:
[0023]
根据风电机组限功率数据在风速-风电功率散点图中的横向堆积分布特征,采用线性拟合法求取不同分段时间序列中风速和风电功率的线性函数;再根据线性函数的斜率提取风电机组限功率数据,线性函数的斜率越接近0,该分段时间序列的数据是限功率数据的可能性越大;所述线性函数和斜率阈值如公式(3)和公式(4)所示:
[0024]
p=aiv biꢀꢀꢀ
(3)
[0025]ai
≤δ
ꢀꢀꢀ
(4)
[0026]
式中,ai为第i个分段时间序列对应线性函数的斜率;bi为第i个分段时间序列对应线性函数的截距;δ为用于确定风电机组限功率数据的斜率阈值。
[0027]
所述步骤23中基于额定功率剔除系数对额定功率分段时间序列进行剔除的公式为:
[0028][0029]
式中,为额定功率剔除系数,pn为风电机组额定功率。
[0030]
所述步骤3具体包括以下子步骤:
[0031]
步骤31:采用纵向四分位算法清洗纵向分布的风电机组分散型异常数据;将风速按照0.25m/s的区间间隔划分为若干个风速区间,并计算各风速区间内风电功率的异常值内限,内限以外的数据为异常数据;其中,第i个风速区间内,风电功率的异常值内限计算方
法如公式(6)所示:
[0032][0033]
式中,为第i个风速区间风电功率的异常值内限下限;为第i个风速区间风电功率的异常值内限上限;为第i个风速区间风电功率的第一分位数;为第i个风速区间风电功率的第三分位数;为第i个风速区间风电功率的四分位距,
[0034]
步骤32:采用横向四分位算法清洗横向分布的风电机组分散型异常数据;将风电功率按照25kw的区间间隔划分为若干个风电功率区间,并计算各风电功率区间内风速的异常值内限,内限以外的数据为异常数据;其中,第i个风电功率区间内,风速的异常值内限计算方法如公式(7)所示:
[0035][0036]
式中,为第i个风电功率区间风速的异常值内限下限;为第i个风电功率区间风速的异常值内限上限;为第i个风电功率区间风速的第一分位数;为第i个风电功率区间风速的第三分位数;为第i个风速区间风电功率的四分位距,
[0037]
本发明的有益效果在于:
[0038]
本发明能够同时有效地清洗堆积型异常数据和分散型异常数据,且可以有效辨识过渡区域内与正常数据空间分布特征相似的异常运行数据,解决了堆积型限电数据与正常数据过渡区域的数据类别难以有效辨识的问题。
附图说明
[0039]
图1为基于时序匹配和双向四分位算法的异常数据清洗方法的流程图;
[0040]
图2为基于双向四分位算法的异常数据清洗结果图;
[0041]
图3为基于时序匹配和双向四分位算法的异常数据清洗结果图。
具体实施方式
[0042]
本发明提出一种基于时序匹配和双向四分位算法的异常数据清洗方法,下面结合附图和具体实施例对本发明做进一步说明。
[0043]
图1为基于时序匹配和双向四分位算法的异常数据清洗方法的流程图;具体实施步骤如下:
[0044]
(1)采集风电机组的实测风速和风电功率数据,本案例采用1.5mw风电机组的实测风速和风电功率数据,数据长度约为3个月,数据时间分辨率为10min;
[0045]
(2)利用风速-风电功率时序匹配算法辨识风电机组限功率异常数据,具体步骤如下:
[0046]
1)采用基本趋势转折点和重要趋势转折点确定算法对风电功率时间序列进行分段划分,基本趋势转折点和重要趋势转折点的定义如下:
[0047]
a.基本趋势转折点:根据时间序列相邻三个时间点的基本变化趋势,基本趋势转折点主要分为上升趋势转折点和下降趋势转折点;设风电功率的时间序列为p=《p1,p2,
…
,
pn〉,若第t时刻的风电功率p
t
满足p
t-1
≥p
t
<p
t 1
或p
t-1
>p
t
≤p
t 1
,则风电功率p
t
为上升趋势转折点;若第t时刻的风电功率p
t
满足p
t-1
≤p
t
>p
t 1
或p
t-1
<p
t
≥p
t 1
,则风电功率p
t
为下降趋势转折点;
[0048]
b.重要趋势转折点:重要趋势转折点的确定是为了降低风电功率时间序列噪声点的影响;对于风电功率时间序列基本转折点序列一个重要趋势转折点p
it
与两个连续的基本趋势转折点和构成的最小模式序列中,是否为重要趋势转折点,取决于到p
it
和线段的垂直距离d,垂直距离d越大,越有可能是重要趋势转折点,垂直距离的大小受数值本身大小的影响,因此,本发明提出了相对垂直距离rd和绝对波动量相结合的方式,用于风电功率时间序列重要趋势转折点确定,相对垂直距离和绝对波动量的计算方法如公式(1)和公式(2)所示:
[0049][0050][0051]
式中,rd为的相对垂直距离;t1为风电功率p
it
所对应的时刻;t2为风电功率所对应的时刻;t3为风电功率所对应的时刻;δp为风电功率绝对波动量;α为相对垂直距离阈值,目的是剔除噪声点对重要趋势转折点的影响,本实施例取值为0.18;β为绝对波动量阈值,目的是剔除零值附近噪声点对重要趋势转折点的影响,本实施例取值为0.01。
[0052]
2)基于风速-风电功率时序匹配度量的限功率分段时间序列筛选,具体步骤如下:
[0053]
a.首先,采用数据时间对标法,提取不同风电功率分段时间序列所对应的风速分段时间序列;
[0054]
b.然后,计算不同分段时间序列的长度l;由于风电机组限功率运行通常会持续一定的时间,分段时间序列时间的长度应满足l≥γ,时长阈值γ受数据时间分辨率和风电机组实际限功率运行状态的影响,需要根据不同风电机组实际情况确定,本实施例取值为6;
[0055]
c.最后,计算不同分段时间序列的风速-风电功率时序匹配度,提取时序不匹配的风电功率分段时间序列;本发明中根据风电机组限功率数据在风速-风电功率散点图中的横向堆积分布特征,提出采用线性拟合的方法,求取不同分段时间序列中风速和风电功率的线性函数,根据线性函数的斜率提取风电机组限功率数据,线性函数的斜率越接近0,该分段时间序列的数据是限功率数据的可能性越大;线性函数计算公式和斜率阈值如公式(3)和公式(4)所示:
[0056]
p=aiv biꢀꢀꢀ
(3)
[0057]ai
≤δ
ꢀꢀꢀ
(4)
[0058]
式中,ai为第i个分段时间序列对应线性函数的斜率;bi为第i个分段时间序列对应线性函数的截距;δ为用于确定风电机组限功率数据的斜率阈值,根据不同风电机组确定,通常接近于0。
[0059]
3)基于额定功率剔除系数的额定功率分段时间序列剔除;由于风电机组额定功率
的空间分布特征与限功率数据相似,容易造成错误辨识,需要在不匹配分段时间序列中剔除,额定功率剔除方法如公式(5)所示:
[0060][0061]
式中,为额定功率剔除系数,根据《gbt19960.1-2005风力发电机组第1部分:通用技术条件》中的描述:“在正常工作状态下,风电机组功率输出与理论值的偏差应不超过10%”,本章中取pn为风电机组额定功率。
[0062]
(3)利用双向四分位算法清洗风电功率分散型异常数据,具体步骤如下:
[0063]
1)首先,采用纵向四分位算法清洗纵向分布的风电机组分散型异常数据;将风速按照0.25m/s的区间间隔划分为若干个风速区间(风速区间内数据的个数不少于总数据量的千分之一),并计算各风速区间内风电功率的异常值内限,内限以外的数据为异常数据。其中,第i个风速区间内,风电功率的异常值内限计算方法如公式(6)所示;
[0064][0065]
式中,为第i个风速区间风电功率的异常值内限下限;为第i个风速区间风电功率的异常值内限上限;为第i个风速区间风电功率的第一分位数;为第i个风速区间风电功率的第三分位数;为第i个风速区间风电功率的四分位距,
[0066]
2)然后,采用横向四分位算法清洗横向分布的风电机组分散型异常数据;将风电功率按照25kw的区间间隔划分为若干个风电功率区间(风电功率区间内数据的个数不少于总数据量的千分之一),并计算各风电功率区间内风速的异常值内限,内限以外的数据为异常数据。其中,第i个风电功率区间内,风速的异常值内限计算方法如公式(7)所示;
[0067][0068]
式中,为第i个风电功率区间风速的异常值内限下限;为第i个风电功率区间风速的异常值内限上限;为第i个风电功率区间风速的第一分位数;为第i个风电功率区间风速的第三分位数;为第i个风速区间风电功率的四分位距,图2为基于双向四分位算法的异常数据清洗结果图。
[0069]
图3为基于时序匹配和双向四分位算法的异常数据清洗结果图。通过具体实施例分析可以看出:本发明提供的基于时序匹配和双向四分位算法的异常数据清洗方法能够同时有效地清洗堆积型异常数据和分散型异常数据,且可以有效辨识过渡区域内与正常数据空间分布特征相似的异常运行数据。
[0070]
此实施例仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
