1.本发明总体上涉及控制车辆,更具体地,涉及控制自主或半自主车辆。
背景技术:
2.自主车辆是复杂的决策系统,其需要集成高级且互连的感测和控制组件。在最高级,由路线规划器通过道路网络来计算目的地序列。离散决策层负责确定车辆的局部驾驶目标。各个决定可以是右转、停留在车道中、左转、或者在交叉路口的特定车道中完全停止中的任一者。感测和映射模块使用各种传感器信息(诸如雷达、激光雷达(lidar)、摄像机、以及全球定位系统(gps)信息)连同在前的地图信息,来估计与驾驶场景相关的周围环境的部分。
3.运动规划的输出是车辆控制器的输入。运动规划器负责基于来自感测和映射模块的输出,来确定车辆应遵循的安全的、希望的且动态可行的轨线(trajectory)。然后,车辆控制算法旨在通过发出命令(例如,转向角度、车轮转矩以及制动力),以相对高的采样频率来跟踪该参考运动。最后,致动器控制层调整致动器以实现这些请求的命令。
4.自主车辆中的运动规划问题与标准的机器人技术设置共有许多相似性,并且由于问题的非凸性(non-convexity),最优解决方案在大多数情况下是很棘手的。已经针对专门的场景开发了依赖于直接动态优化的方法。然而,由于非凸性,这仅导致局部最优解,其可能明显远离全局最优解,并且可能以相对大的计算负荷和时间为代价。通常使用诸如快速探索随机树(rrt)之类的基于采样的方法、或诸如a*、d*以及其它变型例之类的图形搜索方法来执行运动规划。
5.一些方法确定性地执行采样,而其它方法(诸如美国专利9,568,915中描述的方法)使用概率采样。采样技术适合于快速的机器计算,但是对于自主或半自主车辆中的乘客而言,由采样方法生成的路径可能感觉不太自然。因此,仍然需要改进自主或半自主车辆的路径规划和控制。
技术实现要素:
6.一些实施方式公开了一种用于(半)自主驾驶系统的集成架构,其涉及低速率、基于长期采样的运动规划算法以及高速率、基于高反应性优化的预测车辆控制器。这种集成使得能够系统且有效的分担(sharing)在通过运动规划和车辆控制层来实现多个竞争目标(例如,确保安全要求的满足,以及确保在相对复杂的高速公路和城市驾驶场景中可靠且舒适的驾驶行为)的负担。
7.运动规划器计算要跟踪的参考轨线的一阶矩,并且它计算定义了经规划的轨线的对应置信界限的高阶矩。由于我们的规划算法例如根据协方差矩阵来生成目标轨线及其置信度,而不是仅使用该协方差矩阵作为要由控制器跟踪的目标,在此我们还使用该控制器,具体地用于调谐预测控制器的最优控制问题公式中的时变跟踪成本函数。这导致用于在多个竞争目标之间折衷的自动调谐机制。实际上,与轨线相关联的置信度指示路径规划器相
信其所计算的轨线有效到什么程度。通过使用置信度信息来自动调谐预测控制器的成本函数,我们在这样的置信度低时允许更多的偏差,而在这样的置信度相对高时允许更少的偏差。
8.本发明的一些实施方式基于用于运动规划的概率方法,其使用粒子滤波来近似所涉及的概率密度函数(pdf)。由于基于粒子滤波器的运动规划器计算状态轨线的pdf,因此,可以确定比加权平均更高阶的矩。例如,通过计算沿着加权平均的协方差矩阵(即,二阶矩),我们可以确定希望参考轨线的高斯近似,其被直接用于在预测控制器中公式化和适配(adapt)跟踪成本函数。
9.本发明的一些实施方式使用基于线性或非线性模型预测控制(mpc)的自适应实现的车辆控制层的实现,该线性或非线性mpc具有阶段式最小二乘成本函数的时变公式。特别地,可以使用时变跟踪权重矩阵来定义mpc成本函数。因为路径规划器提供所规划的运动轨线的一阶矩和高阶矩两者,所以该信息可以被直接用于调谐阶段式最小二乘跟踪成本函数中的参考值和加权矩阵两者。
10.一些实施方式基于运动规划器的不确定性与mpc问题中的跟踪成本之间的反比例关系,从而导致加权矩阵的时变序列。更具体地,预期到参考运动规划的不确定性在车辆被预测为变得相对接近车辆的安全相关约束时增加,使得偏离参考轨线的惩罚将减小,反之亦然。这又分别允许mpc预测状态和/或控制轨线与其参考(即,运动规划轨线)的较大或较小的偏差。
11.对于自主车辆,使用诸如方差的简单矩对于车辆的安全操作是不够的。例如,考虑在自主车辆的前方存在车辆的情况,并且可能停留在车辆后方或者通过改变车道而超车。如果运动规划器已经确定了可能轨线的分布,则确定该分布的方差将导致过度保守并导致较差的性能。
12.因此,一个实施方式通过从分布确定不同模式来解决这种保守性。例如,一种模式是对应于车道保持的可能轨线的分布,而另一模式是对应于改变车道的可能轨线的分布。基于这些不同的模式,可以计算各个单独模式的方差,从而降低保守性。
13.一些实施方式基于这样的认识,即,运动规划器可以利用关于车辆控制算法的特定当前状况的信息。例如,mpc基于包括避障不等式约束的约束优化方法。如果从运动规划器传播至mpc的方差相对较小,则mpc控制器可能不必要地激活避障约束,从而导致不平稳的轨线。为此,在本发明的一个实施方式中,mpc通知运动规划器关于mpc的预测状态和控制轨线中的约束激活和/或约束违反的最新量,该预测状态和控制轨线可以被用于调节置信度,即,增大或减小运动规划器中的轨线分布的方差。这导致增加的安全性以及改进的经规划参考轨线的平稳度。
14.不同的实施方式使用不同的时间尺度以用于运动规划和车辆控制层的实时操作。例如,在一个实施方式中,运动规划器计算长期的、高度预测的参考轨线,但是它通常需要以相对低的采样频率运行,即,它具有相对慢的更新速率(例如,每1秒)并因此具有相当低的反应性。相反地,mpc通常使用短得多的预测范围(prediction horizon),但是它以高得多的采样频率(例如,每25毫秒)运行,使得控制器可以对例如由于自我车辆的姿势估计以及周围障碍物的不确定性导致的局部偏差高度反应。因此,在规划与控制层之间分担责任以确保安全和可靠的驾驶行为是重要的,尤其是为了满足实时以及在不确定下性的安全要
求。
15.因此,一个实施方式公开了一种用于控制车辆的系统,该系统包括:输入接口,其被配置为接受车辆的当前状态、接近车辆的当前状态的环境的图像、以及车辆的目的地;存储器,其被配置成存储概率运动规划器和自适应预测控制器,其中,该概率运动规划器被配置成接受车辆的当前状态、车辆的目的地、以及环境的图像,以生成关于定义车辆的运动规划的目标状态序列的参数概率分布序列,其中,各个参数概率分布的参数定义了概率分布的一阶矩(first order moment)以及至少一个高阶矩,其中,该自适应预测控制器被配置成优化预测范围内的成本函数,以生成对车辆的一个或多个致动器的控制命令序列,其中,该成本函数的优化对由一阶矩定义的目标状态序列中的不同状态变量的跟踪成本进行平衡,其中,在跟踪成本的平衡中,使用概率分布的所述高阶矩中的一个或多个高阶矩来对不同状态变量进行加权;处理器,其被配置成通过向概率运动规划器提交车辆的当前状态、车辆的目的地、以及环境的图像,来执行概率运动规划器,并且该处理器被配置成通过向自适应预测控制器提交由概率运动规划器生成的参数概率分布序列来执行自适应预测控制器,以生成控制命令序列;以及输出接口,该输出接口被配置成向车辆的至少一个致动器输出由自适应预测控制器确定的至少一个控制命令。
16.另一实施方式公开了一种用于控制车辆的方法,其中,所述方法使用被联接至存储器的处理器,该存储器存储概率运动规划器和自适应预测控制器,其中,该概率运动规划器被配置成接受车辆的当前状态、车辆的目的地、以及环境的图像,以生成关于定义车辆的运动规划的目标状态序列的参数概率分布序列,其中,各个参数概率分布的参数定义概率分布的一阶矩以及至少一个高阶矩,其中,该自适应预测控制器被配置成优化预测范围内的成本函数,以生成对车辆的一个或多个致动器的控制命令序列,其中,该成本函数的优化对由一阶矩定义的目标状态序列中的不同状态变量的跟踪成本进行平衡,其中,在跟踪成本的平衡中,使用概率分布的所述高阶矩中的一个或多个高阶矩来对不同状态变量进行加权,其中,处理器与执行所述方法的存储指令联接,其中,所述指令在由处理器执行时,执行所述方法的步骤,所述方法包括以下步骤:接受车辆的当前状态、接近车辆的当前状态的环境的图像、以及车辆的目的地;通过向概率运动规划器提交车辆的当前状态、车辆的目的地、以及环境的图像,来执行概率运动规划器;通过向自适应预测控制器提交由概率运动规划器生成的参数概率分布序列来执行自适应预测控制器,以生成控制命令序列;以及向车辆的至少一个致动器提交由自适应预测控制器确定的至少一个控制命令。
17.又一实施方式公开了一种非暂时性计算机可读存储介质,其上实施有可通过处理器执行以执行方法的程序,其中,该介质存储概率运动规划器和自适应预测控制器,其中,该概率运动规划器被配置成接受车辆的当前状态、车辆的目的地、以及环境的图像,以生成关于定义车辆的运动规划的目标状态序列的参数概率分布序列,其中,各个参数概率分布的参数定义了概率分布的一阶矩以及至少一个高阶矩,其中,该自适应预测控制器被配置成优化预测范围内的成本函数,以生成对车辆的一个或多个致动器的控制命令序列,其中,该成本函数的优化对由一阶矩定义的目标状态序列中的不同状态变量的跟踪成本进行平衡,其中,在跟踪成本的平衡中,使用概率分布的所述高阶矩中的一个或多个高阶矩来对不同状态变量进行加权。
18.所述方法包括以下步骤:接受车辆的当前状态、接近车辆的当前状态的环境的图
像、以及车辆的目的地;通过向概率运动规划器提交车辆的当前状态、车辆的目的地、以及环境的图像,来执行概率运动规划器;通过向自适应预测控制器提交由概率运动规划器生成的参数概率分布序列来执行自适应预测控制器,以生成控制命令序列;以及向车辆的至少一个致动器提交由自适应预测控制器确定的至少一个控制命令。
附图说明
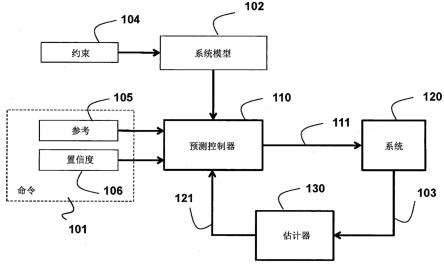
19.图1是根据一些实施方式的预测控制器和反馈系统的框图。
20.图2a是包括采用一些实施方式的原理的控制器的车辆的示意图;以及
21.图2b是采用一些实施方式的原理的控制器与根据一些实施方式的车辆201的控制器之间的交互的示意图。
22.图3a示出了包括决策器、运动规划器、车辆控制器以及致动器控制器的多层控制结构和这些层之间的信息交换的示意图。
23.图3b示出了包括决策器、概率运动规划器、模型预测控制器以及致动器控制器的多层控制结构和这些层之间的信息交换的示意图。
24.图3c例示了基于来自概率运动规划器的命令信息,对多层控制结构中的模型预测控制器的成本函数中的一项或多项进行自动调谐。
25.图4a例示了根据一些实施方式的针对在道路上驾驶的车辆行为的可能控制目标与其在运动规划器中的对应控制函数的示例性列表。
26.图4b示出了在一些实施方式中由运动规划器采用的概率控制函数的结构的示意图。
27.图4c示出了根据一些实施方式的运动规划器的概率输出对车辆控制器的性能的影响的示例。
28.图4d示出了根据一些实施方式的运动规划器的概率输出对车辆控制器的性能的影响的示例。
29.图4e示出了根据一些实施方式的如何平衡不同控制函数的重要性的方法的例示图。
30.图5a示出了根据一些实施方式的自适应模型预测控制(mpc)方法的框图,该方法在各个时间步解决不等式约束优化问题以实现车辆控制器。
31.图5b示出了根据一些实施方式的自适应模型预测控制(mpc)方法的框图,该方法在各个时间步解决不等式约束优化问题以实现车辆控制器。
32.图6a是根据一些实施方式的求解最优控制结构化二次规划(qp)的自适应mpc方法的框图。
33.图6b是根据一些实施方式的求解最优控制结构化非线性规划(nlp)的自适应mpc方法的框图。
34.图7a是自适应针对自适应线性或非线性mpc控制器中的时变参考跟踪成本的特定实施方式的参考和加权矩阵的方法的框图。
35.图7b是自适应针对自适应线性或非线性mpc控制器中的时变参考跟踪成本的特定实施方式的参考和对角加权矩阵的方法的框图。
36.图7c是使用来自概率运动规划器的参考值序列和协方差矩阵,自动调谐自适应
mpc控制器的时变参考跟踪成本的算法描述。
37.图8示出了根据本发明的一些实施方式的定义车辆运动的状态转变树的示意图。
38.图9a示出了根据本发明的一些实施方式的用于确定车辆状态序列和概率分布的概率运动规划器的流程图。
39.图9b示出了确定各个状态与概率控制函数一致的概率的方法的流程图。
40.图9c示出了其中自主车辆的位置的预测与障碍物的不确定区域相交并且其中障碍物处于该位置的概率高于特定碰撞阈值的示例。
41.图9d示出了用于生成与概率控制函数一致的状态的步骤的三次迭代的结果的简化示意图。
42.图9e示出了在图9d中的第一次迭代的五种状态的可能指派的概率。
43.图10a示出了与将车辆保持在道路上的控制目标相对应的控制函数的例示图。
44.图10b示出了与缩短道路上的车辆行进时间的控制目标相对应的控制函数的例示图。
45.图10c示出了用于表达安全超过障碍物的驾驶目标的控制函数的例示图。
46.图10d示出了根据一些实施方式描述维持当前速度的目标的控制函数的可能方式的例示图。
具体实施方式
47.本发明的一些实施方式提供了用于使用预测控制器来控制系统的操作或系统的系统和方法。预测控制器的示例是基于受控系统的模型来确定控制输入的模型预测控制(mpc)。
48.图1示出了根据一些实施方式的经由状态估计器130连接至预测控制器110的示例系统120。在一些实现中,预测控制器是根据系统的动态模型102编程的mpc控制器。该模型可以是表示系统120的状态和输出103根据当前和先前输入111以及先前输出103随时间变化的一组方程。该模型可以包括表示系统的物理和操作限制的约束104。在操作期间,控制器接收指示系统的希望行为的命令101。该命令例如可以是运动命令。响应于接收到命令101,控制器生成用作系统的输入的控制信号111。响应该输入,系统更新系统的输出103。基于系统103的输出的测量结果,估计器更新系统的估计状态121。系统的该估计状态121向控制器110提供状态反馈。
49.如本文所引用的,系统120可以是由某些操纵输入信号111(输入)控制并且返回一些受控输出信号103(输出)的任何机器或装置,该操纵输入信号可能与诸如电压、压力、力、转矩的物理量相关联,该受控输出信号可能与指示系统的状态从先前状态到当前状态的转变的诸如电流、流量、速度、位置的物理量相关联。输出值部分地与系统的先前输出值相关,部分地与先前输入值和当前输入值相关。关于先前输入和先前输出的依赖性在系统的状态下进行编码。系统的操作(例如,系统的组件的运动)可以包括在应用某些输入值之后由系统生成的输出值序列。
50.系统的模型102可以包括一组数学方程,其描述系统输出根据当前和先前输入以及先前输出而随时间如何变化。系统的状态是通常随时间变化的任何信息集,例如,当前和先前的输入和输出的恰当子集,系统的状态与系统的模型以及未来输入一起可以唯一地定
义系统的未来运动。
51.系统可以经受物理限制和规范约束104,该物理限制和规范约束限制了系统的输出、输入、以及可能的状态被允许操作的范围。
52.控制器110可以以硬件实现或者作为在处理器(例如,微处理器)中执行的软件程序来实现,控制器110以固定或可变的控制时段采样间隔接收系统的估计状态121以及希望的运动命令101,并且使用该信息来确定用于操作系统的输入(例如,控制信号111)。
53.命令101可以包括参考命令105以及该参考命令105的置信度106的表示。例如,命令101可以包括参考运动105以及围绕该参考运动的置信界限106。在本发明的一些实施方式中,参考运动105可以由状态和/或输出值的参考轨线来表示,并且置信界限可以由定义状态和/或输出值的参考轨线周围的不确定性的协方差矩阵来表示。在本发明的一些实施方式中,命令101是由概率运动规划器来计算的,并且参考运动105对应于运动规划的统计的一阶矩,置信度106对应于该运动规划的统计的二阶矩或高阶矩。
54.估计器130可以以硬件实现或者作为在与控制器110的处理器相同或不同的处理器中执行的软件程序来实现,估计器130以固定或可变的控制时段采样间隔接收系统的输出103,并且使用新的和先前的输出测量结果来确定系统120的估计状态121。
55.图2a示出了包括采用一些实施方式的原理的预测控制器202的车辆201的示意图。如本文所使用的,车辆201可以是任何类型的轮式车辆,诸如客车、公共汽车,或越野车(rover)。而且,车辆201可以是自主或半自主车辆。例如,一些实施方式控制车辆201的运动。运动的示例包括由车辆201的转向系统203控制的车辆的横向运动。在一个实施方式中,转向系统203是由控制器202控制的。附加地或者另选地,转向系统203可以由车辆201的驾驶员控制。
56.车辆还可以包括发动机206,该发动机可以由控制器202或者车辆201的其它组件来控制。车辆还可以包括用于感测周围环境的一个或更多个传感器204。传感器204的示例包括测距仪、雷达、激光雷达、以及摄像机。车辆201还可以包括用于感测其当前运动量和内部状态的一个或更多个传感器205。传感器205的示例包括:全球定位系统(gps)、加速度计、惯性测量单元、陀螺仪、轴旋转传感器、转矩传感器、偏转传感器、压力传感器、以及流量传感器。这些传感器向控制器202提供信息。车辆可以配备有收发器207,其能够通过有线或无线通信信道实现控制器202的通信能力。
57.图2b示出了根据一些实施方式的车辆201的预测控制器202与控制器220之间的交互的示意图。例如,在一些实施方式中,车辆201的控制器220是控制车辆220的旋转和加速的转向控制器225和制动器/节气门控制器230。在这样的情况下,预测控制器202向控制器225和230输出控制输入以控制车辆的状态。控制器220还可以包括高级控制器,例如,进一步处理预测控制器202的控制输入的车道保持辅助控制器235。在两种情况下,控制器220使用预测控制器202的输出来控制车辆的诸如车辆的方向盘和/或制动器之类的至少一个致动器,以便控制车辆的运动。
58.图3a示出了用于自主或半自主车辆的多层控制和决策结构的示意图。自主车辆是需要集成高级且互连的感测和控制组件的复杂系统。本发明的实施方式包括运动规划层310和车辆控制器320。运动规划器310计算运动命令101并将该运动命令提供给车辆控制器320。基于运动命令101中的参考105和置信度106,车辆控制器320计算该系统的控制输入
111,以执行运动命令。本发明的一些实施方式另外包括决策层300和/或致动器控制器330。
59.在最高级,可以由路线规划器通过道路网络来计算目的地序列。给定路线,离散决策层300可以负责确定车辆的一个或多个局部驾驶目标以及对应的离散决定301。各个决定可以是右转、停留在车道中、左转、或者在交叉路口的特定车道中完全停止中的任一者。决策层300使用来自一个或多个传感器的信息(诸如雷达、激光雷达、惯性测量单元、摄像机、和/或全球定位系统(gps)信息)连同在前的地图信息,来估计系统的状态以及与用于特定驾驶场景的系统相关的周围环境的部分。来自感测和映射模块的估计信息能够可用于图3a的结构的控制和决策层中的一个、多个或全部。
60.基于一个或多个局部目的地目标301,运动规划器310负责确定提供给车辆控制器320的运动命令101。在一些实施方式中,运动命令包括参考命令105和置信界限106。在一些实施方式中,参考命令是基于来自决策层300的输出的车辆应当遵循的安全的、希望的且动态可行的轨线。本发明的一些实施方式基于这样的认识:重要的要求在于由运动规划器310所计算的参考轨线105是无碰撞的、动态可行的,并且可以由车辆控制器320进行跟踪。这意味着参考轨线在避免与环境的任何碰撞并且遵守可由一组数学方程表示的系统的动态模型102的同时实现了一个或多个局部驾驶目标。
61.本发明的一些实施方式是基于这样的认识的,即,运动规划任务中的典型限制因素是对应的受约束动态优化问题的非凸性质。这导致仅实现了可能显著远离全局最优解的局部最优解,并且可能需要非常大的计算负荷和时间,甚至仅找到可行解。例如,使用基于采样的方法(诸如快速探索随机树(rrt))、或图形搜索方法(诸如a*、d*以及其它变型例)来执行运动规划。
62.如图3b所示,本发明的一些实施方式使用用于运动规划311的概率方法,例如,使用粒子滤波来近似所涉及的概率密度函数(pdf)。驾驶要求(诸如停留在道路上、左行交通或右行交通、以及避障)可以被公式化为非线性滤波问题的测量。所得到的树扩展可以不同于标准rrt算法,因为基于粒子滤波的概率运动规划器311不是对状态空间进行采样,而是基于粒子滤波的概率运动规划器对输入空间进行采样,并且基于驾驶要求添加附加的校正项。
63.在本发明的一些实施方式中,概率运动规划器311接受车辆的当前状态、车辆的目的地、以及环境的图像,以生成关于定义车辆的运动命令的目标状态和/或输出值的序列的参数概率分布序列,其中,各个参数概率分布的参数定义概率分布的一阶矩316以及至少一个高阶矩317。在本发明的一些实施方式中,可以通过概率运动规划器311来最小化成本函数,使得在车辆的运动命令中实现希望的行为。
64.本发明的一些实施方式是基于这样的认识的,即,车辆的各个目标状态皆可以包括多个状态变量,使得概率运动规划器311中的各个参数概率分布为定义各个状态变量的分布的参数的多变量分布,在该情况下,各个参数概率分布的一阶矩是平均值,并且该参数概率分布的高阶矩是具有在空间和时间上变化的值的协方差矩阵。
65.在本发明的一些实施方式中,概率运动规划器311包括具有在时间上传播的一组粒子的基于粒子滤波的算法,以表示目标状态在时间实例处的一组似然,使得各个粒子包括目标状态在该时间实例处的值的高斯分布。在该情况下,时间实例的参数概率分布的一阶矩是粒子的加权平均,而时间实例的参数概率分布的高阶矩是粒子的加权协方差。
66.如图3a和图3b所例示的,考虑到对应的置信界限106,车辆控制器320和/或340旨在通过计算用于操作该系统的控制信号321来实现该参考运动105。控制信号可以包括一个或多个致动命令,举例来说,如转向角、车轮转矩以及制动力的值。在本发明的一些实施方式中,车辆控制器320向由一个或多个控制器330组成的附加层提供控制信号321,所述一个或多个控制器330直接调整致动器以实现所请求的车辆行为。
67.本发明的不同实施方式可以在车辆控制器320中使用不同的技术,来跟踪由运动规划器310的特定算法计算的参考运动105。在本发明的一些实施方式中,在车辆控制层中使用模型预测控制器340(mpc),使得可以在预测控制器中有效地使用长期运动规划中的未来信息来实现希望的车辆行为。
68.在本发明的一些实施方式中,线性动态模型是与线性约束和二次目标函数结合使用的,从而导致线性模型预测控制器(lmpc)跟踪由运动规划器计算的参考运动。在本发明的其它实施方式中,所述约束和/或目标函数中的一个或多个可以是非线性的,和/或描述车辆状态行为的动态模型方程可以是非线性的,从而导致非线性模型预测控制器(nmpc)跟踪由运动规划器计算的参考运动。
69.本发明的一些实施方式是基于这样的认识的,即,运动规划器可以计算相对长期的、高度预测性的运动规划,但是其通常需要以相对慢的采样频率来运行。例如,运动规划器可以计算5秒至50秒的将来时段的参考运动,同时它可以在一秒或多秒的每个采样时间内仅执行一次或多次,从而导致高度预测性的运动规划,但相对低的反应性。本发明的实施方式是基于这样的附加认识的,即,预测控制器可以通过在相对短的预测范围内计算控制信号,但是同时以相对高的采样频率运行,来跟踪参考运动规划。例如,车辆控制器可以使用1秒至10秒的预测范围,同时它可以每秒执行10次至100次。车辆控制器可以对由于车辆状态估计中的不确定性以及感测和映射模块中的其它不确定性(例如,与车辆周围环境中的障碍物相关的不确定性)而造成的局部偏差具有高度反应性。
70.在本发明的一些实施方式中,自适应模型预测控制器340的执行速率大于概率运动规划器311的执行速率,使得对于运动规划器的每次执行,处理器执行mpc至少一次。在本发明的一些实施方式中,运动规划将关于目标状态序列的参数概率分布序列定义为大于车辆控制器的预测范围长度的时段内的时间的函数。
71.在本发明的一些实施方式中,可以将车辆的不同动态模型用于自主或半自主车辆的多层控制和决策结构中的不同组件中。例如,在运动规划器中可以使用相对简单但计算上便宜的运动学模型,而在预测控制器中可以使用相对准确但计算上更昂贵的动态单轨迹(track)或双轨迹车辆模型。
72.如图3a和图3b所例示的,可以在自主或半自主车辆的多层控制和决策结构中的不同组件之间共享信息。例如,与地图和车辆周围环境相关的信息可以在决策器与运动规划器305之间、在运动规划器与车辆控制器315之间、或者在车辆控制器与致动器控制器之间共享。另外,本发明的一些实施方式是基于这样的认识的,即,通过使用诊断信息(举例来说,如多层控制和决策结构的一个组件中的算法的、可以与另一组件中的算法共享的成功和/或失败的性能度量)可以改善自主或半自主车辆的可靠性和安全性。
73.参照图3b,概率运动规划器311可以使用来自模型预测控制器340的信息315。例如,在本发明的一个实施方式中,mpc控制器在各个采样时间步求解受约束的动态优化问
题,并且它在各个采样时间步使用各个控制解决方案中的约束的活动集来向概率运动规划器提供反馈。该活动集中的所有约束在控制解决方案中保持相等,而所有其余约束在mpc控制器的解决方案中被认为是不活动的。在本发明的一些实施方式中,概率运动规划器311被配置成基于mpc控制器340中的活动约束的类型和/或数量来调节概率分布的高阶矩。这例如在运动规划器的行为需要被调节为没有或者尚未被运动规划器检测到的环境变化时可能是有益的,以便改善自主或半自主车辆的总体行为。
74.图3c例示了基于来自概率运动规划器311的参考命令105和对应置信度106,对多层控制结构中的模型预测控制器340的成本函数350中的一项或多项进行自动调谐。自适应mpc控制器340被配置为优化预测范围内的成本函数,以生成对车辆的一个或多个致动器的控制命令序列。在本发明的一些实施方式中,成本函数350的优化将由参数概率分布316的一阶矩定义的跟踪目标状态序列的成本355对照车辆的运动的至少一个其它度量的成本360进行平衡。
75.本发明的实施方式是基于这样的认识的,即,跟踪成本的重要性可以使用参数概率分布的高阶矩317中的一个或多个高阶矩的函数来进行加权。基于概率运动规划器311中的参数概率分布对高阶矩317对自适应预测控制器340中的成本函数350进行这种自动调谐允许在实现控制目标方面(例如,确保安全避障、停留在特定车道中、以希望的参考速度驾驶和/或在相对复杂的场景中实现可靠的、舒适的驾驶行为)在运动规划器与车辆控制器之间分摊负担。
76.概率分布的高阶矩317指示概率运动规划器关于车辆的运动规划的置信度。在本发明的一些实施方式中,自适应预测控制器随着置信度的增大而增大平衡优化中的跟踪的权重,从而允许预测车辆状态值与目标状态的参考序列的较低偏差。在本发明的一些实施方式中,自适应预测控制器随着置信度的减小而减小平衡优化中的跟踪的权重,从而允许预测车辆状态值与参考轨线的较大偏差。
77.在本发明的一些实施方式中,将协方差矩阵pk306用于表示概率运动规划器中的概率分布的二阶矩。可以将该协方差矩阵pk306的时变序列用于在自适应mpc控制器的目标函数中相对地关于其它性能度量360,自动地调谐时变参考跟踪项355的加权。本发明的一些实施方式是基于这样的认识的,即,这导致用于在多个竞争控制目标之间折衷的自动调谐机制。在协方差矩阵pk306的项中,与目标状态和/或输出值105的参考轨线相关联的置信度106指示运动规划器相信其所计算的轨线是有效的程度。通过使用用于自动调谐mpc成本函数350的置信度信息,当运动规划器的这种相信较低时,我们允许与参考轨线的更多偏差,而在这种相信相对高时,我们允许更少偏差。
78.图4a示出了根据一些实施方式的针对在道路上驾驶的车辆行为的可能控制目标与其在概率运动规划器中的对应控制函数的示例性列表。控制函数根据对应的目标将车辆的当前状态转变成车辆的目标状态。可以以分析方式设计和/或从数据中学习该控制函数。例如,一个驾驶目标是要求车辆停留在道路400上,并且其对应的停留在道路上的函数被配置成维持车辆的位置在道路边界内。可能的附加驾驶目标可以要求车辆应当以标称速度420在车道的中间410行驶。它们对应的控制函数可以包括:被配置成将车辆的位置维持在车道中间的车道中间函数,和/或被配置成维持车辆的希望速度的维持速度函数。
79.在另一示例中,驾驶目标还可以要求车辆使用其对应的安全裕度函数来维持距周
围障碍物的安全裕度430,该安全裕度函数被配置成维持车辆与道路上的障碍物之间的最小距离。另一可能的驾驶目标是维持距同一车道中的车辆的安全距离440。这可以利用对应的最小车头间距(minimum-headway)函数来实现,该最小车头间距函数被配置成维持车辆与前行车辆之间的最小车头间距。出于乘客舒适度、燃料消耗、磨损的理由或者其它的理由,本发明的一些实施方式旨在要求车辆的平稳驾驶行为450。一些实施方式通过使用被配置成维持车辆运动的平稳度的平稳驾驶函数在运动规划器中实现该目标。
80.概率运动规划器中的驾驶目标的其它示例可以包括:使用被配置成将车辆的速度维持在速度极限的速度极限函数来将速度增加至速度极限460;使用被配置成将车辆的当前位置从当前车道改变至相邻车道的改变车道函数来改变车道470;以及通过使用被配置成减少车辆在交叉路口处的怠速运转时间的交叉路口-横穿函数来最小化交叉路口处的怠速运转以减少燃料消耗。
81.本发明的一些实施方式是基于这样的认识的,即,运动规划器可能具有相抵消的驾驶目标。例如,在保持对周围障碍物的安全裕度430的同时维持恒定速度420是不可能的。一些实施方式通过使控制函数中的至少一个控制函数是概率性的来平衡相抵消的驾驶目标。
82.具体地,一些实施方式基于这样的认识,即,不是所有的驾驶目标都可以精确地实现。例如,加速至速度极限460的目标有时可能与维持对周围障碍物的安全裕度430的驾驶目标不兼容。而且,驾驶员可能不时地以不同的方式决定什么驾驶目标最重要。而且,对于自动驾驶(self-driving)车辆的情况,存在导致驾驶目标无法精确实现的附加不确定性。因此,本发明的一些实施方式是基于这样的认识的,即,在实现驾驶目标方面存在不精确性,并且这种驾驶目标的实现程度可以经常改变。
83.图4b示出了由运动规划器的一些实施方式采用的概率控制函数415的结构的示意图。每个控制函数415被配置成基于该控制函数的对应控制目标,以概率的方式将车辆的当前状态转变成目标状态。为此,概率控制函数415包括确定性分量425和概率性分量435,该确定性分量用于将当前状态转变成目标状态455,该概率性分量用于确定由确定性分量确定的目标状态周围的值的概率分布465。确定性分量可生成目标状态的单个值445或者多个值的序列455。附加地或者另选地,确定性分量可以被执行多次以生成序列455。然而,在一些实现中,对于该目标状态序列的各个值445,存在概率分布465,使得概率控制函数的输出是关于由一阶矩以及至少一个高阶矩定义的目标状态的参数概率分布475。
84.图4c示出了根据一些实施方式的运动规划器310的概率输出对车辆控制器320的性能的影响的示例。在该示例中,图4c示出了车辆的当前状态410c以及车辆旨在达到的目标状态420c。目标状态420c可以是笛卡尔位置、速度、或者与车辆相关联的另一实体。目标状态420c可以是特定状态、或状态区域。例如,目标状态420c可以是允许速度的间隔或者笛卡尔空间中可能位置的区域。合适的控制输入是将车辆从其初始状态410c带至目标状态420c,同时实现诸如图4a中的那些驾驶目标的驾驶目标(例如,驾驶目标可以是停留在道路上的区域431c内)的输入。来自输入的最终所得状态430c可以对应于导致将控制输入应用于一次步骤(one-time step)的状态转变,或者最终所得状态430c可以利用轨线411c与初始状态410c连接,即,状态转变序列。
85.在自主或半自主车辆的情况下,可以通过测试用于车辆运动的动态模型的控制输
入,来执行从当前状态到目标状态的转变。运动的模型根据向该模型提交的控制输入来转变车辆的状态。在各种实施方式中,车辆的运动的数学模型包括不确定性。为此,车辆的运动的模型是概率运动模型,以便说明该模型是车辆的实际运动的简化描述的事实,而且说明车辆的真实状态的感测中的不确定性、障碍物状态的感测中的不确定性、以及环境的感测中的不确定性。
86.图4c示出了由控制输入的特定选择产生的目标状态区域431c,其中,431c是非零概率性分量,430c是被包括在区域431c中的确定性分量。驾驶目标区域420c不与目标状态区域431c重叠,即,区域431c不包括驾驶目标区域420c。因此,参照图4c,驾驶目标420c很可能无法实现,并且控制器可以更改其操作以更好地实现一个或多个驾驶目标。
87.图4d示出了由控制输入的特定选择产生的目标状态区域431d,其中,431d是非零概率性分量,并且430d是被包括在区域431d中的确定性分量。驾驶目标区域420d小于目标状态区域431d并且被全部包含在431d中,即,区域431d包括区域420d。因此,参照图4d,驾驶目标420d很可能通过控制输入的选择而得以实现。
88.图4e示出了根据一些实施方式的如何平衡不同控制函数的重要性的方法的例示图。图4e示出了具有被表达为控制函数的两个驾驶目标的情形,维持标称速度420和维持安全距离430。速度要求是被表达为速度与标称速度的偏差的函数,并且安全距离被表达为从自主车辆到道路上的障碍物的欧几里德距离。速度控制函数的确定性分量是零,而概率性分量是以确定性分量为中心的窄形状410e。另一方面,安全距离要求具有非零的确定性分量420e、以及允许确定性分量周围的大变化的概率性分量430e。而且,在该例示性示例中,确定性分量420e不以概率性分量430e的均值为中心。由于速度与距离不相同,因此将速度和安全距离控制函数变换440e成公共状态,在该公共状态中,可以对控制函数进行比较。然后,将控制函数组合450e成联合分布,该联合分布将控制函数加权在一起。在本发明的一些实施方式中,使用不同控制目标的相对缩放来组合和平衡控制函数的相对重要性。
89.例如,在图4e中,联合分布将重要性平衡450e到公共确定性分量470e和概率性分量460e中,由于速度控制函数的概率分布具有比安全距离控制函数的概率性分量430e小得多的变化410e,因此该公共确定性分量470e和概率性分量460e都更接近速度控制函数的相应分量。
90.联合分布可以以多种方式进行选择。例如,如果序列中各个步骤(step)的各个控制函数的概率性分量是高斯分布的,则可以将联合分布选择为多变量高斯分布,其中,各个控制函数的重要性加权是通过各个分量的协方差的倒数来加权的。
91.确定性分量可以以多种方式进行选择。例如,一个实施方式通过将确定性分量在向量上堆叠使得它们构成高斯分布的平均来组合这些确定性分量。
92.即使序列中各个步骤的概率性分量是高斯分布的,该序列分布尤其是在被组合成联合分布序列时将是非高斯的。例如,确定性分量可以是将当前状态映射至控制函数输出的非线性函数,这使该序列成为非高斯分布的。为了确定这种情况下的组合状态和分布序列,例如,通过采样可以使用数值近似。
93.本发明的一些实施方式是基于这样的认识的,即,可以将不同控制目标的类似平衡用于自适应预测控制器中,该自适应预测控制器旨在跟踪由概率运动规划器计算的参考运动。例如,可以将不同状态变量的跟踪组合成联合跟踪成本函数,其中,使用加权矩阵来
平衡跟踪所述状态变量中的一个状态变量的重要性相对于跟踪一个或多个其它状态变量的重要性。在本发明的一些实施方式中,加权矩阵被计算为缩放矩阵以及关于目标状态和/或输出值的序列的参数概率分布序列的一个或多个高阶矩217的函数,该目标状态和/或输出值的序列定义了由概率运动规划器311计算的车辆的运动命令。一些实施方式包括饱和函数,其将所述加权矩阵中的每个加权矩阵定界在联合成本函数中的所述控制目标中的各个控制目标的加权的下界与上界之间。
94.除了跟踪不同的状态变量之外,本发明的一些实施方式还包括要由预测控制器考虑的一个或多个附加目标项。这些附加项的示例可以涉及驾驶舒适度、速度限制、能量消耗、污染等。这些实施方式利用这些附加的目标项来平衡跟踪不同状态变量的参考值的成本。
95.图5a示出了根据一些实施方式的用于模型预测控制(mpc)以实现控制器110的系统和方法的框图,该系统和方法在给定系统的当前状态121和控制命令101的情况下计算控制信号111。具体地,mpc通过在各个控制时间步以最优控制结构化规划的形式求解不等式约束优化问题550,来计算关于系统的预测时间范围(prediction time horizon)的包含未来最优控制输入的序列的控制解560,例如,解向量555。该优化问题550中的目标函数540、等式和不等式约束530的最优控制数据545取决于动态模型525、系统约束520、系统的当前状态121以及由参考105和置信度106组成的控制命令101。
96.在一些实施方式中,该不等式约束优化问题的解550使用来自先前控制时间步的预测时间范围内的状态和控制值510,其可以从存储器读取。这个构思被称为优化算法的温启动或热启动,并且在一些实施方式中它可以显著地减少mpc控制器所需的计算工作量。按类似方式,可以将对应的解向量555用于更新和存储下一控制时间步的最优或次最优状态和控制值的序列560。
97.在本发明的一些实施方式中,mpc控制器340使最优控制成本函数540中的一项或多项自适应由概率运动规划器311计算的参考轨线105和对应的置信界限106。如图5b所示,可以将最小二乘型成本函数用于跟踪具有特定加权矩阵的参考轨线。在本发明的一些实施方式中,参考轨线是由一阶矩216定义的,并且加权矩阵被计算为协方差矩阵306的函数或者关于目标状态和/或输出值的序列的参数概率分布序列的一个或多个高阶矩217的函数,该目标状态和/或输出值的序列定义了由概率运动规划器311计算的车辆的运动命令。
98.图6a示出了根据一些实施方式的用于自适应mpc 340以实现车辆控制器110的系统和方法的框图,该系统和方法在给定系统的当前状态121和控制命令101的情况下,通过求解最优控制结构化二次规划(qp)650来计算控制信号111。在本发明的一些实施方式中,自适应mpc控制器结合线性动态模型使用线性二次目标函数,来预测车辆的行为和线性不等式约束,从而得到可作为下式的最优控制结构化qp问题公式:
[0099][0100][0101]
x
k 1
=ak akxk bkuk,k=0,...,n-1,
[0102][0103][0104][0105]
在自适应线性mpc控制器的预测范围在时间上离散化的情况下,使用由离散时间点tk(其中,k=0,...,n)的对应序列划分的n个等距或非等距控制间隔序列。最优控制结构化qp 650中的优化变量由状态变量xk和控制输入变量uk(其中,k=0,...,n)组成。在本发明的一些实施方式中,对于各个离散时间点tk(其中,k=0,...,n),状态和控制变量的维数不需要彼此相等。在自适应mpc控制器的各个采样时间,使用qp矩阵630和qp向量635来公式化最优控制结构化qp 650,并且随后求解qp,以便计算解向量555来更新状态和控制轨线560并且生成新的控制信号111。
[0106]
由自适应mpc控制器340求解的约束qp 650中的目标函数包括一个或多个最小二乘参考跟踪项652,其惩罚预测状态和/或输出值的序列656与由运动规划器计算的参考状态和/或输出值的序列105之间的差异。参考状态和/或输出值105定义概率分布的一阶矩316。
[0107]
在本发明的一些实施方式中,将加权矩阵wk的序列用于最小二乘参考跟踪项652中(其中,k=0,...,n),并且基于由概率运动规划器在各个采样时刻计算的参考105和置信度106,在控制成本函数640中自适应各个加权矩阵wk。加权矩阵wk被计算为概率分布的高阶矩317的函数或者由该高阶矩表示。
[0108]
在参考跟踪目标项652中使用的输出变量yk(其中,k=0,...,n)可以被定义为状态和/或控制输入变量656的任何线性函数。例如,输出函数可以包括:车辆的纵向或横向速度和/或加速度、滑移率或滑移角、取向角或角速度、车轮速度、力和/或转矩中的一个或多个的一个或多个组合。参考跟踪目标项652是由qp矩阵630中的加权矩阵wk和qp向量635中的参考值来定义的。在本发明的一些实施方式中,加权矩阵是正定wk>0或者正半定wk≥0,即,矩阵wk的所有特征值大于零,或者矩阵wk的所有特征值大于或等于零。
[0109]
在各种实施方式中,由运动规划器确定的参考值与由预测控制器确定的值之间的惩罚由加权矩阵来进行加权,该加权矩阵将不同的权重指派给目标状态的不同状态变量。附加地或者另选地,一些实施方式增加了预测控制器要考虑的附加目标项。这些附加项的示例可以涉及驾驶舒适度、速度限制、能量消耗、污染等。这些实施方式利用这些附加的目标项来平衡参考跟踪的成本。
[0110]
例如,一些实施方式以线性二次阶段成本651和/或线性二次终端成本项653的形式来定义mpc成本函数的附加目标项。这些包括阶段成本651和终端成本653的附加的线性二次目标项可以包括一个或多个状态和/或控制输入变量的一个或多个组合的线性和/或二次惩罚。例如,约束qp 650中的目标函数可以包括:车辆的纵向或横向速度和/或加速度的线性或二次惩罚、滑移率或滑移角、取向角或角速度、车轮速度、力、转矩、或者这些量的任何组合。阶段成本651和终端成本653中的线性二次目标项是由qp矩阵630中的矩阵qk、sk和rk以及qp向量635中的梯度值qk、rk来定义的。在本发明的一些实施方式中,hessian矩阵是正定hk>0或者正半定hk≥,即,hessian矩阵hk的所有特征值大于零,或者矩阵hk的所有特征值大于或等于零。
[0111]
由自适应线性mpc控制器340求解的受约束的最优控制结构化qp 650定义了线性动态模型655,该线性动态模型描述了在给定先前时间步tk下的状态和控制变量的情况下,在一个时间步t
k 1
处的车辆状态。线性动态模型是由qp矩阵630中的矩阵ak和bk的时不变序列或时变序列以及qp向量635中的向量ak(其中,k=0,...,n-1)来定义的。给出针对初始状态值654的等式约束中的当前状态估计121以及控制输入值uk的序列,可以将线性动态模型方程655用于计算状态值xk(其中,k=0,...,n)。
[0112]
除了包括初始值条件654、动态方程655以及输出方程656的等式约束之外,受约束的最优控制结构化qp 650还可以包括一个或多个不等式约束,以施加系统的物理限制、安全约束和/或对自主或半自主车辆的行为施加希望的性能相关约束。更具体地,qp可以包括在预测范围结束时的路径不等式约束657(其中,k=0,...,n-1)和/或终端不等式约束658。该不等式约束是由qp矩阵630中的矩阵和的时不变序列或时变序列以及qp向量635中的向量dk(其中,k=0,...,n)来定义的。
[0113]
该不等式约束可以包括对车辆的纵向或横向速度和/或加速度、车辆相对于其周围环境的位置和/或取向、滑移率或滑移角、取向角或角速度、车轮速度、力和/或转矩中的一个或多个的一个或多个组合的约束。例如,可以通过在车辆的预测位置、速度和取向相对于车辆的周围环境中的一个或多个障碍物的预测位置、速度和取向的线性函数上定义一组一个或多个不等式约束来在自适应mpc控制器中实现避障约束。
[0114]
本发明的一些实施方式是基于这样的认识的,即,如果hessian矩阵hk651、终端成本矩阵qn653以及加权矩阵wk652是正定的或正半定的,则最优控制结构化qp 650是凸的。本发明的实施方式可以使用迭代优化算法来求解最优控制结构化qp 650以找到解向量555,该解向量相对于约束是可行的并且是全局最优的、或者是可行但次最优的、或者算法可以找到既不可行也不是最优的低精度近似控制解。作为自适应mpc控制器的部分,优化算法可以以硬件来实现或者作为在处理器中执行的软件程序来实现。
[0115]
用于求解qp 650的迭代优化算法的示例包括:基于原始或双重梯度的方法、投影或近似梯度方法、向前-向后分割方法、乘法器的交替方向方法、原始、双重或原始-双重活动集方法、原始或原始-双重内部点方法或者这些优化算法的变体。在本发明的一些实施方式中,可以在优化算法的线性代数运算中的一个或多运算中利用qp矩阵630中的块稀疏最优控制结构,以便降低计算复杂度,并因此降低qp优化算法的执行时间和存储器占用空间(footprint)。
[0116]
本发明的其它实施方式可以使用用于非线性规划(举例来说,如顺序二次规划(sqp)或内部点方法(ipm))的优化算法来求解非凸最优控制结构化qp 650,优化算法可以在自适应mpc控制器340的各个采样时间找到针对不等式约束优化问题的次优、局部最优或全局最优控制解。
[0117]
图6b示出了用于自适应mpc 340以实现车辆控制器110的系统和方法的框图,该系统和方法在给定系统的当前状态121和控制命令101的情况下,通过求解最优控制结构化非线性规划(nlp)660来计算控制信号111。在本发明的一些实施方式中,自适应mpc控制器结合线性或非线性动态模型使用线性二次或非线性目标函数,来预测车辆的行为以及线性和非线性不等式约束的组合,从而得到可作为下式的最优控制结构化nlp问题公式:
[0118][0119][0120]
x
k 1
=fk(xk,uk),k=0,...,n-1,
[0121][0122]
0≥hk(xk,uk),k=0,...,n-1,
[0123]
0≥hn(xn),
[0124]
在自适应非线性mpc控制器的预测范围在时间上离散化的情况下,使用由离散时间点tk(其中,k=0,...,n)的序列划分的n个等距或非等距控制间隔的序列。最优控制结构化nlp 660中的优化变量由状态变量xk和控制输入变量uk(其中,k=0,...,n)组成。在本发明的一些实施方式中,对于各个离散时间点tk(其中,k=0,...,n),状态和控制变量的维数不需要彼此相等。在自适应mpc控制器的各个采样时间,使用参考跟踪成本641中的参考和加权矩阵以及nlp目标和约束函数645来公式化最优控制结构化nlp 660,并且求解nlp,以便计算解向量555来更新状态和控制轨线560并且生成新的控制信号111。
[0125]
由自适应mpc控制器340求解的约束nlp 660中的目标函数包括一个或多个线性和/或非线性最小二乘参考跟踪项662,其惩罚预测状态和/或输出值的序列与由运动规划器计算的参考状态和/或输出值的序列105之间的差异。在本发明的一些实施方式中,将加权矩阵wk的序列用于最小二乘参考跟踪项662中(其中,k=0,...,n),并且基于由概率运动规划器在各个采样时刻计算的参考105和置信度106,在控制成本函数640中自适应各个加权矩阵wk。在参考跟踪目标项662中使用的输出值yk(xk,uk)(其中,k=0,...,n)可以被定义为状态和/或控制输入变量的任何线性或非线性函数。例如,输出函数可以包括:车辆的纵向或横向速度和/或加速度、滑移率或滑移角、取向角或角速度、车轮速度、力和/或转矩中的一个或多个的一个或多个组合。参考跟踪目标项662是由加权矩阵wk和参考值来定义的。在本发明的一些实施方式中,加权矩阵是正定wk>0或者正半定wk≥0,即,矩阵wk的所有特征值大于零,或者矩阵wk的所有特征值大于或等于零。
[0126]
本发明的实施方式可以以阶段成本和/或终端成本项663的形式来定义mpc成本函数的附加目标项,阶段成本和终端成本项663二者可以由线性、线性二次或非线性函数的任何组合来组成。这些附加的目标项可以包括状态和/或控制输入变量的一个或多个线性或非线性函数的一个或多个组合的惩罚。例如,约束nlp 660中的目标函数645可以包括:车辆的纵向或横向速度和/或加速度、滑移率或滑移角、取向角或角速度、车轮速度、力、转矩、或者这些量的任何组合的线性、二次或非线性惩罚。
[0127]
由自适应非线性mpc控制器340求解的受约束的最优控制结构化nlp 660可以定义非线性动态模型665,该非线性动态模型描述了在给定先前时间步tk下的状态和控制变量的情况下,在一个时间步t
k 1
处的车辆状态。该非线性动态模型是由时不变或时变函数x
k 1
=fk(xk,uk)(其中,k=0,...,n-1)来定义的。在给出初始状态值664的等式约束中的当前状态估计121以及控制输入值uk的序列的情况下,可以将非线性动态模型方程665用于计算状态值xk(其中,k=0,...,n)。
[0128]
本发明的一些实施方式是基于这样的认识的,即,可以通过执行一组连续时间微分或微分代数方程的时间离散化来获得预测车辆行为的离散时间动态模型665。这种时间离散化有时可以以分析方式执行,但是通常需要使用数值模拟例程来计算状态轨线的离散时间演变的数值近似。近似地模拟一组连续时间微分或微分代数方程的数值例程的示例包括:显式或隐式runge-kutta方法、显式或隐式euler、后向微分公式以及其它单步或多步方法。
[0129]
除了包括初始值条件664以及动态方程665的等式约束之外,受约束的最优控制结构化nlp 660还可以包括施加系统的物理限制的一个或多个线性和/或非线性不等式约束、安全约束和/或对自主或半自主车辆的行为施加希望的性能相关约束。更具体地,nlp可以包括的线性路径不等式约束666或非线性路径不等式约束667(其中,k=0,...,n-1),以及在预测范围结束时施加的线性和/或非线性终端不等式约束668。不等式约束是由矩阵的时不变或时变序列、向量dk和/或非线性函数hk(xk,uk)(其中,k=0,...,n)来定义的。
[0130]
该不等式约束可以包括对车辆的纵向或横向速度和/或加速度、车辆相对于其周围环境的位置和/或取向、滑移率或滑移角、取向角或角速度、车轮速度、力和/或转矩中的一个或多个的一个或多个组合的约束。例如,可以通过在车辆的预测位置、速度和取向相对于车辆的周围环境中的一个或多个障碍物的预测位置、速度和取向的线性或非线性函数上定义一组一个或多个不等式约束来在自适应非线性mpc控制器中实现避障约束。
[0131]
在本发明的一些实施方式中,自适应非线性mpc控制器包括避障约束,该避障约束是使用一个或多个椭圆不等式约束的时变序列来实现的,该椭圆不等式约束可以被读作:
[0132][0133]
其中,是估计或预测的车辆位置(p
x
,py)到车辆周围环境中的潜在的多个障碍物之一的估计和/或预测的位置的旋转距离。各个障碍物的位置和取向是由(e
x,j
,e
y,j
,e
ψ,j
)来表示的,矩阵r(e
ψ,j
)
t
表示与表示障碍物的取向的角度e
ψ,j
相对
应的旋转矩阵的转置,并且(a
x,j
,a
y,j
)表示定义围绕m个(其中,j=1,...,m)最近的所检测到的障碍物中的各个障碍物的安全裕度的椭圆体的主半轴的长度,该安全裕度包括围绕估计形状的空间范围的不确定性。可以由感测模块执行实时障碍物检测和对应的姿势估计,并且该信息是由多层车辆控制架构中的不同组件来共享的。
[0134]
本发明的一些实施方式基于定制的优化算法,以在非线性自适应mpc控制器的各个采样时刻高效地求解受约束的最优控制结构化nlp 660。这样的优化算法可以找到解向量555,该解向量相对于约束是可行的并且是全局最优的、或者是可行的但局部最优的、或者是可行但次最优的、或者迭代优化算法可以找到既不可行也不是局部最优的低精度近似控制解。nlp优化算法的示例包括内部点方法的变体以及顺序二次规划(sqp)方法的变体。
[0135]
特别地,本发明的一些实施方式使用实时迭代(rti)算法,该算法是与拟牛顿或广义高斯-牛顿型半正定hessian近似相结合的顺序二次规划的在线变体,使得在非线性mpc控制器的各个采样时刻需要求解至少一个凸块稀疏qp近似。各个rti迭代由两个步骤组成:
[0136]
(1)制备阶段:对系统动态进行离散化和线性化,对剩余的约束函数进行线性化,以及对二次目标近似进行评估,以构建最优控制结构qp子问题。
[0137]
(2)反馈阶段:求解qp以更新所有优化变量的当前值,并且获得下一控制输入以向系统应用反馈。
[0138]
在本发明的一些实施方式中,可以在优化算法的线性代数运算中的一个或多个中利用hessian矩阵和约束jacobian矩阵中的块稀疏最优控制结构,以便降低计算复杂度,并因此降低nlp优化算法的执行时间和存储器占用空间。
[0139]
图7a示出了在自适应线性或非线性mpc控制器340中的时变参考跟踪成本720的特定实施方式中自适应参考和加权矩阵640的方法的框图。利用时变正定或半正定加权矩阵710对mpc跟踪成本720进行加权,并且基于与围绕参考的时变不确定性的反比例关系来计算所述加权矩阵中的各个矩阵,该参考是由概率运动规划器计算的、由参数概率分布的高阶矩317中的一个或多个高阶矩的组合来表示的。
[0140]
在本发明的一些实施方式中,mpc在跟踪成本中使用时变正定或正半定加权矩阵,该时变正定或半正定加权矩阵被计算为来自概率运动规划器的参数概率分布的协方差矩阵705的序列的阶段式缩放的逆。该协方差矩阵705的序列表示或者包括由运动规划器确定的概率分布的高阶矩。运动规划器将不同的控制目标相对于它们相应的重要性进行加权,以生成用于mpc控制车辆状态和/或输出值的合适序列以及概率分布。给定与各个参考状态和/或输出值相对应的协方差矩阵pk>0,自适应线性或非线性mpc控制器中的加权矩阵可以计算如下:
[0141][0142]
其中,wk表示mpc参考跟踪成本720中的加权矩阵,矩阵pk表示协方差矩阵705,以及qk>0是对称和正定缩放矩阵701。可以将缩放矩阵qk选择为对称和正定矩阵的时不变或时变序列,其中,各个缩放矩阵是密集的或者对角矩阵。在本发明的一些实施方式中,缩放矩阵由概率运动规划器根据不同控制目标相对于其相应的重要性的相对缩放来选择。
[0143]
在图7a中,使用协方差矩阵的逆的平方根来计算各个控制间隔k=0,...,n的加权矩阵。在本发明的一些实施方式中,自适应线性或非线性mpc控制器中的加权矩阵可
以另选地计算如下:
[0144][0145]
其中,lk表示正定协方差矩阵pk>0的cholesky因子,使得并且一些实施方式基于这样的认识,即,加权矩阵可以基于正定协方差矩阵的cholesky因子分解和正定缩放矩阵的cholesky因子分解来进行高效计算,使得中间矩阵可以使用前向或后向替换来进行高效计算,并且可以随后将对称加权矩阵计算为
[0146]
图7b示出了基于对角正定加权矩阵wk>0715,在自适应线性或非线性mpc控制器340中的时变参考跟踪成本720的特定实施方式中自适应参考和加权矩阵640的方法的框图,其中,所述对角条目中的各个对角条目
[0147]
其中,i=1,...,n
x
。
[0148]
是仅使用正定缩放矩阵qk>0701的对应对角条目以及各个参考协方差矩阵pk>0705的对应对角条目来进行单独计算的。在本发明的一些实施方式中,可以使用一个或多个饱和函数来改进由mpc例如,基于正则化参数∈>0解决的受约束的优化问题的数值调节,以便能够为自适应mpc控制器的参考跟踪成本中的所述时变正定加权矩阵中的各个矩阵提供下界和上界。这样将加权矩阵表示为对角矩阵在计算上更便宜。
[0149]
图7c示出了使用来自概率运动规划器的高阶矩,自动调谐自适应mpc控制器540的时变参考跟踪成本的算法描述。基于参考状态和/或输出值的序列以及对应的协方差矩阵740,可以将参考运动743的平稳近似用在mpc控制器的最小二乘型目标项中,并且所述加权矩阵中的各个加权矩阵可以基于与来自概率运动规划器的对应的协方差矩阵730中的各个协方差矩阵的反比例关系来进行单独计算,这在mpc控制器744的各个采样时刻重复。如果由概率运动规划器(包括参数概率分布的一阶矩316和高阶矩317)计算741新的参考运动规划,则可以重置742该参考状态和/或输出值的序列以及对应的协方差矩阵。如果新的参考运动规划尚不可用,则参考状态和/或输出值的最新数据序列以及对应的协方差矩阵可以从一个控制时间步移至下一控制时间步。
[0150]
本发明的一些实施方式是基于这样的认识的,即,运动规划器在比mpc更长的时间尺度上起作用,而mpc控制器可以以比运动规划器更高的采样率来执行,使得与运动规划器的相对低的反应性相比,mpc可以更快地调节环境变化并且调节车辆状态以及车辆周围环境的感测和估计中的不确定性。
[0151]
在本发明的一些实施方式中,将概率运动规划器中对组合的状态的序列和概率分布的计算实现为扩展的树,直到已经找到达到驾驶决定的状态序列。
[0152]
图8示出了根据本发明的一些实施方式的定义车辆运动的状态转变树的示意图。示出了可驾驶空间830中的当前树,其中根节点800指示车辆的当前状态,并且该树包括作为节点的状态以及作为状态空间中的边的状态转变,这是由根据本发明的其它实施方式选择的控制输入产生的。例如,边821是通过在从根节点800到状态820的预定义时间内施加控制输入而生成的运动。该树可以包括车辆的目标状态810和目标区域840。在本发明的一些
实施方式中,可以有多个目标状态810和目标区域840。可以将概率与生成边821的控制输入相关联,并因此也与状态820相关联,该概率可以说明车辆的动态模型中的不确定性以及障碍物和车辆周围环境的感测和估计中的不确定性。
[0153]
在一些实施方式中,边821是通过评估多个时刻内的控制输入来创建的。而其它实施方式针对各个时刻确定新的控制输入,其中,控制输入的确定是根据本发明的其它实施方式来描述的。在其它的实施方式中,边821是通过聚集一个或多个时刻内的多个控制输入来创建的。在将该树朝着目标区域840扩展时,选择初始状态、确定控制输入、以及确定对应的状态序列和最终状态。例如,880可以是所选择的状态,881可以是轨线(其是作为边添加至树的),以及860是最终状态(其是作为节点添加至运动规划树的)。
[0154]
图9a示出了根据本发明的一些实施方式的用于确定状态的序列和分布的概率运动规划器899的流程图。在一些实施方式中,概率运动规划器899是粒子滤波器,该粒子滤波器在时间上传播一组粒子,以表示目标状态在时间实例处的一组似然。各个粒子包括目标状态在时间实例处的值的高斯分布,其中,该时间实例的参数概率分布的一阶矩是粒子的加权平均,而该时间实例的参数概率分布的高阶矩是粒子的加权协方差。该方法迭代地确定指定车辆的、从该车辆的初始状态到该车辆的目标状态的运动的控制输入的序列。在不同的实施方式中,初始状态是车辆的当前状态和/或其中,初始状态是与在方法的先前迭代期间确定的控制输入相对应的状态。
[0155]
该运动是由连接车辆状态的状态转变来定义的,举例来说,如图8所示。各个状态皆包括车辆的位置、速度、以及车向。迭代地确定该运动直到满足终止条件,例如,持续一定时段或预定次数的迭代。图9a的方法的迭代包括以下步骤。
[0156]
该方法确定900初始状态、一组采样状态以及对应的一组状态转变,使得具有对应的高概率的特定状态转变与控制目标函数的子集相对一致。例如,该方法确定图8中的状态880、状态转变881、以及状态860。
[0157]
在本发明的一些实施方式中,通过使用概率控制函数生成采样状态900,即,根据与控制函数子集相对应的概率密度函数来对状态进行采样。例如,给定在时间索引k的状态和在时间索引k 1的控制函数,可以使用概率函数q(x
k 1
|xk,y
k 1
)来生成状态,其中,q是在时间索引k 1的状态的函数。
[0158]
作为特定示例,如果运动模型上的噪声和控制函数是高斯型的,则可以将高斯型密度函数q选择为其中,并且即,可以将状态生成为来自动态系统的噪声源和概率控制函数的组合的随机样本。
[0159]
在本发明的一个实施方式中,按循环执行经采样状态900的生成,其中,迭代次数是事先确定的。在另一实施方式中,状态900的生成是基于时间上提前t个时间步的要求来完成的。例如,可以将迭代次数t确定为固定数量的步骤,或者迭代次数可以被确定为感测系统的传感器的分辨率的函数。当900被执行t个时间步时,根据从时间索引k 1到时间索引k t,的所有概率控制函数(即,q(x
k 1
|xk,y
k 1
,...,y
k t
))来生成输入。
[0160]
图9b示出了确定各个状态与概率控制函数一致的概率的方法910的流程图。在确
定各个状态的概率时,对该状态首先检查碰撞911。如果下一状态和引发该状态的状态转变是无碰撞的,则确定912该状态与控制函数子集的一致性,并且计算913各个状态的概率。
[0161]
在一个实施方式中,如果碰撞检查911确定下一状态与障碍物碰撞,则可以将该特定状态的概率设定成零。碰撞检查可以是确定性的,或者它可以是概率性的,其中,如果碰撞的概率高于某一阈值,则可以假定发生碰撞,其中,根据障碍物的概率运动模型来进行障碍物的预测。
[0162]
图9c示出了其中自动驾驶车辆位置910c的预测与障碍物920c的不确定性区域921c相交,并且障碍物920c位于位置910c的概率高于碰撞阈值930c的实例。例如,车辆传感器可将障碍物的位置确定为时间的函数。运动规划系统确定下一个状态与障碍物的不确定性区域相交的概率,并且当下一个状态与障碍物的不确定性区域相交的概率高于碰撞阈值时,将零概率分配给采样状态。
[0163]
在方法910的另一个实施方式中,如果聚集概率低于阈值914,其中阈值可以预先确定,则状态具有低概率与控制函数一致,因此该方法退出915并重新运动规划算法899。
[0164]
在本发明的一些实施方式中,确定912是作为概率控制函数的概率密度函数(pdf)下一状态、以及在前一循环960期间确定的状态的概率的组合来完成的。例如,如果根据车辆的动态模型生成状态,则概率与控制函数的pdf成比例,即,作为另一个示例,如果状态的采样是根据来完成的,则如上说明的,概率是与概率控制函数的pdf的预测成正比例的,即,在本发明的一些实施方式中,概率以表示pdf的方式归一化。
[0165]
在本发明的一个实施方式中,具有非零但低的概率的状态在某些时间步中被替换成具有较高概率的状态。例如,一个实施方式以这样的方式来生成新的一组状态,即,生成的概率为在另一实施方式中,每当概率的平方和倒数低于某一预定义阈值时,就执行替换。以这种方式进行确保仅使用可能良好的状态。
[0166]
可以以多种方式来完成状态的确定920。例如,一个实施方式通过使用加权平均函数确定控制输入,以将状态生成为另一实施方式将状态确定为具有最高概率的状态,即,附加地或者另选地,一个实施方式通过对固定数量m<n个的采样状态求平均来确定状态。
[0167]
图9d示出了当每次迭代生成五个采样状态时步骤900、910和920的三次迭代结果的简化示意图。使用车辆运动的动态模型和概率控制函数,在时间911d中向前预测初始状态910d,接下来的五个状态是921d、922d、923d、924d和925d。概率被确定为概率控制函数926d和控制函数926d的概率允许偏差927d的函数。在每一时间步,即在每一次迭代中,概率的集合被用于产生集合的控制输入和相应的状态920d。在一些实现中,概率函数起作用以在时间上传播表示目标状态的似然的粒子。在这些实现中,各个状态(例如,921d、922d、923d、924d、以及925d)是粒子。
[0168]
图9e示出了图9d中第一次迭代时五种状态的可能分配概率。这些概率921e、922e、923e、924e和925e的值反映在选择说明状态921d、922d、923d、924d和925d的点的相对尺寸
中。
[0169]
确定概率分布的序列意味着确定概率的分布,如对序列中的每个时间步长的图9e中的概率分布。例如,分布可以表示为图9e中的离散分布,或者与概率相关的离散状态可以使用例如核密度平滑器使其连续。
[0170]
返回参照图9d,状态920d成为下一次迭代的初始状态,其再次产生五个采样状态931d、932d、933d、934d和935d。根据该迭代的采样状态的概率选择状态930d。状态930d是下一次迭代的初始状态。
[0171]
一些实施方式如下更新节点和边的树g=(v,e)930。如果是方法900的第一次迭代,则树以当前状态初始化,且边为空。否则,在900-920中确定的聚集状态序列和控制输入序列被添加为节点,连接状态的轨迹被添加为边。例如,图8中的860是添加的节点,对应的边是881。作为选择,在一个实施方式中,所有生成的状态都被添加到树中,在这种情况下,可以回避确定920。
[0172]
图10a至图10d示出了根据本发明的一些实施方式的可能的控制函数的子集及其相应的确定性分量和概率性分量的图示。
[0173]
图10a示出了与将车辆1010a保持在道路400上的控制目标相对应的控制函数的例示图,其中,道路边界是由1020来定义的。控制函数是由确定性分量1030a和概率性分量1040a来定义的。例如,可以通过记录人类驾驶员的数据并优化拟合(例如,通过最小化针对数据的平均欧几里德距离或者通过最大化作为良好拟合的概率)来确定确定性分量。可以通过确定所记录的数据在确定性分量1030a周围的变化来确定概率性分量1040a。例如,可以通过最大化将所有记录的数据包括在概率性分量1040a的变化内的概率来确定概率性分量1040a,或者可以通过在给定有限量的所记录的数据的情况下估计无限量的数据的实际变化来确定概率性分量。
[0174]
一些实施方式基于这样的认识,即,虽然可以将控制函数建模为由道路边界1020a限制的控制函数,但是这并非人类驾驶的方式。而相反,人类可以决定轮流抄近路以提供更短的乘车旅行。图10b示出了与缩短道路上的车辆1010b行进时间的控制目标相对应的控制函数的例示图,其中,道路边界是由1020b来定义的。控制函数是由确定性分量1030b和概率性分量1040b来定义的。根据本发明的一些实施方式,可以基于由概率运动规划器使用确定性分量1030b和概率性分量1040b为所述控制目标中的各个控制目标计算的概率分布的时变一阶矩和高阶矩,来自动地自适应线性或非线性mpc控制器中的参考跟踪成本。
[0175]
图10c示出了用于表达安全超过障碍物1060c的驾驶目标的控制函数的例示图,其中,车辆1010c行驶在具有车道边界1070c的双车道道路上。图10c例示了其中自主或半自主车辆需要执行用于避障的操纵的场景。当由于在当前车道的边侧上的静态或者动态障碍物(例如,行人、自行车以及停止或停放的车辆)而很可能无法安全地停留在该车道的中间时,执行避障的操纵可能是必要的,以及例如,由于交通规则或者在另一车道当前变阻塞时,不可能或者不希望改变到另一车道。例如,可以根据在类似情形下从人类驾驶员收集的数据来确定该确定性分量1020c。概率性分量1040c指示不是每种情形都是相同的,并且该驾驶员通常根据障碍物1060c如何表现而表现得稍微不同。
[0176]
因此,概率性分量1040c指示执行超车的区域中的较大变化。在本发明的一些实施方式中,执行超车的区域中的这种较大变化可以导致自适应mpc控制器的参考跟踪成本项
中的对应权重的减小。这允许mpc参考跟踪算法自动地自适应存在于竞争控制目标之间的折衷,举例来说,如在满足安全避障要求的同时实现高跟踪性能。更具体地,可以预期到参考运动规划的不确定性在车辆被预测为变得相对接近周围障碍物时增加,使得偏离参考轨线的惩罚将减小,反之亦然。这又允许nmpc轨线与其参考(即,运动规划轨线)的更大或更小的偏差。
[0177]
图10d示出了根据一些实施方式描述维持当前速度420的目标的控制函数的可能方式的例示图。图10d示出了其中速度根据道路曲率(即,道路的转弯半径的测度(measure))来建模的情况。对于小曲率,即,几乎笔直的道路,控制函数具有等于当前速度1010d的确定性分量1020d。然而,随着曲率增加,当前速度更难以维持,并且确定性分量减小到零。而且,如图10d所示,对于小曲率,概率性分量1030d是以具有小变化的标称速度为中心的。然而,随着曲率增加,存在较大的非对称变化以反映驾驶员施加的速度的较大变化。在本发明的一些实施方式中,对于道路的大曲率,希望速度的这种较大变化可以导致自适应mpc控制器的参考跟踪成本项中的对应权重的减小。对于道路的小曲率,希望速度的较小变化可以导致mpc参考跟踪成本项中的对应权重的增大。
[0178]
本发明的上述实施方式可以以多种方式中的任何一种来实现。例如,实施方式可以使用硬件、软件或其组合来实现。当在软件中实现时,软件代码可以在任何合适的处理器或处理器集合上执行,无论是在一台计算机中提供还是分布在多台计算机之间。这种处理器可以实现为集成电路,在集成电路组件中有一个或多个处理器。然而,处理器可以使用任何合适格式的电路来实现。
[0179]
此外,本文概述的各种方法或过程可以被编码为可在采用多个各种操作系统或平台中的任何一种的一个或多个处理器上执行的软件。另外,这种软件可以使用多种合适的编程语言和/或编程或脚本工具中的任何一种编写,也可以编译为在框架或虚拟机上执行的可执行机器语言代码或中间代码。通常,在各种实施方式中,程序模块的功能可以根据需要进行组合或分布。
[0180]
此外,本发明的实施方式可以作为方法实施,已经提供了该方法的实例。作为方法的一部分执行的动作可以以任何合适的方式进行排序。因此,尽管在图示实施方式中示出为顺序动作,可以构造以不同于图示的顺序执行动作的实施方式,其可以包括同时执行一些动作。
[0181]
尽管已经通过优选实施方式的实例描述了本发明,但是应当理解,可以在本发明的精神和范围内进行各种其它调整和修改。因此,所附权利要求书的目的是涵盖本发明真正精神和范围内的所有此类变化和修改。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。