1.本发明涉及一种基于强化学习的地址映射策略设计方法。
背景技术:
2.在计算机体系结构中,处理器性能提升速度与内存性能提升速度一直失衡发展,使访存延迟成为限制系统性能提升的一个重要因素。从“存储墙”问题被提出以来,计算机系统中硬件加速器性能提升早已成为了计算机架构中的关键研究对象之一,而内存控制器是提升加速器性能关键之一。国内外学者从很多角度对内存控制器进行优化,降低系统延迟。而大多数地址映射策略存在针对性较强,不能广泛推广到其他应用,在领域专用加速器中实现高性能访存的灵活性不足的问题。
技术实现要素:
3.本发明的目的在于提供一种基于强化学习的地址映射策略设计方法,将二进制可逆矩阵用来表示主流的地址映射策略,并结合强化学习模型训练最佳行缓存命中率地址映射策略。
4.为实现上述目的,本发明的技术方案是:一种基于强化学习的地址映射策略设计方法,用二进制可逆矩阵bim表示地址映射策略,结合强化学习模型训练最佳行缓存命中率地址映射策略。实现方式为:将二进制可逆矩阵bim的一维展开作为强化学习模型的输入;将初始的bim行缓存命中率作为强化学习模型当前的最佳值h
best
;强化学习模型根据概率选择动作,得到候选bim;当候选bim计算得到的行缓存命中率比当前bim高时,强化学习模型就会用候选的bim替换当前的bim;紧接着,重新计算奖励值,同时更新强化学习模型的参数;强化学习模型根据上述过程不断迭代优化,依据预设的停止规则,收敛获得训练好的bim;同时获得行缓存命中率最高的地址映射策略。
5.相较于现有技术,本发明具有以下有益效果:本发明一种基于强化学习的地址映射策略设计方法,首次将二进制可逆矩阵bim和强化学习结合做内存控制器的地址映射策略设计。二进制可逆矩阵bim在地址映射策略的表达上具有极高的灵活性,能够正确表示目前所有的地址映射策略。并且,该发明结合基于策略梯度的强化学习模型,令bim针对神经网络加速器不同的访存模式学习到行缓存命中率最高的地址映射策略。将训练学习好的bim模型在内存控制器中硬件实现。
附图说明
6.图1为地址映射策略的表示图。
7.图2为用bim表示主流地址映射策略示意图。
8.图3为强化学习的策略网络优化bim示意图。
9.图4为优化迭代bim算法。
10.图5为mini-batch训练强化学习模型算法。
11.图6为强化学习模型系统工作流程示意图。
具体实施方式
12.下面结合附图,对本发明的技术方案进行具体说明。
13.本发明一种基于强化学习的地址映射策略设计方法,用二进制可逆矩阵bim表示地址映射策略,结合强化学习模型训练最佳行缓存命中率地址映射策略。实现方式为:将二进制可逆矩阵bim的一维展开作为强化学习模型的输入;将初始的bim行缓存命中率作为强化学习模型当前的最佳值h
best
;强化学习模型根据概率选择动作,得到候选bim;当候选bim计算得到的行缓存命中率比当前bim高时,强化学习模型就会用候选的bim替换当前的bim;紧接着,重新计算奖励值,同时更新强化学习模型的参数;强化学习模型根据上述过程不断迭代优化,依据预设的停止规则,收敛获得训练好的bim;同时获得行缓存命中率最高的地址映射策略。
14.以下为本发明具体实现过程。
15.内存地址映射策略的原理是地址与dram中存储单元位置按照一定规则映射到dram的具体位置中。图1展示的是目前主流的内存地址映射策略,本发明用简化的地址位来表示dram不同的地址映射策略,将其简化成8位物理地址。其中,前面2位是bank位,紧接着是4位行位,最后2位为列地址位。图1(a)表示的是brc,该策略访存地址按照bank、行、列的顺序排列与物理地址对应映射。图1(b)表示的是rbc,该策略将bank位和行位进行调换,把行位放在bank位之前,列坐标位不变。图1(c)表示的是位反转,即初始bank位与行位进行了倒序排列。而图1(d)表示的是permutation-based,该策略将bank位和部分行地址位进行异或来生成新的bank地址位。图1(e)是基于二进制可逆矩阵(binary invertible matrix,bim)的内存地址映射的策略,该策略将初始物理地址和二进制可逆矩阵相乘后得到对应bim地址映射的地址信息。
16.上述的所有策略都可以用二进制可逆矩阵bim表示。该策略实现过程为将原始地址和bim相乘得到需要的地址映射。二进制可逆矩阵bim由1或0组成,所以,其内存地址映射的实现,只需与门和异或门就可以硬件实现。其中,与门和异或门分别用来作乘法和加法运算,该过程能够有效降低内存地址映射的硬件开销。二进制可逆矩阵的可逆性使得物理地址与内存存储单元的地址能够有效映射。如图2所示,图2(a)-(d)表示的主流地址映射策略均能够用bim表示出来。由于bim存在上述的性能和低硬件开销等不可替代的优势,所以,基于强化学习的内存控制器选取bim作为系统中内存地址映射策略的载体具有明显的优势。
17.1、强化学习优化bim
18.本发明中bim的优化主要是将二进制单位矩阵在策略梯度算法模型中做初等矩阵变换。增强学习模型的动作空间是由二进制可逆矩阵所有可能的行/列交换动作组成。
19.(1)策略网络设计
20.本发明中使用策略网络π来学习优化访存效率更高的bim地址映射策略的动作。其中,策略网络设计成两层级联的全连接层,在策略网络中第一层由relu作为激活函数,引入了非线性因素。本发明在网络第二层的输出以全连接的方式接softmax函数。如图3所示,是bim优化的实例。该设计将二进制可逆矩阵bim一行一行按顺序展开成一个一维数据作为策略网络的输入。根据概率分布,模型会在动作空间中选择一个动作作为二进制可逆bim当前
的优化动作。bim根据上一个动作进行了变换,变成新的二进制可逆矩阵bim,此时的二进制可逆矩阵bim就作为下一刻策略网络的输入。在下面实例中,bim简化成6
×
6的二进制可逆矩阵bim作为地址映射策略,bim的优化能够根据模型的输出选择对应的行/列变换进行优化,如此循环往复迭代优化。
21.(2)动作空间优化
22.在上述的二进制可逆矩阵bim模型中,强化学习模型的动作空间数为其中b是二进制可逆矩阵的行/列数。假设bim为32
×
32的二进制可逆矩阵,那么总的动作空间为992,也就是说,bim变换一次有992种变换选择。当强化学习模型训练的过程需要多次迭代学习,因此,优化bim的动作空间将是一个非常大的搜索空间,这种情况下,学习过程可逆会因为搜索动作过久而导致强化学习模型性能下降。为了解决动作空间过大的问题,本小节中进行bim优化过程中动作空间压缩。
23.由线性代数知识可知,将二进制可逆矩阵进行无数次的行/列交换都可以用多次行交换实现。如公式(1)所示,对bim进行行交换可以通过在bim左侧乘上一个转置矩阵m
pre
;对bim进行列交换可以通过在bim右侧乘上一个转置矩阵m
post
。
[0024][0025]
二进制可逆矩阵满足交换律和结合律,一系列的行/列变换均可以用行变换来等价实现。因此,本研究将动作空间压缩成只有行变换动作的集合。变换表达式如下:
[0026][0027]
在上述动作空间压缩后,动作空间已经减少了一半。为了更大程度优化动作搜索空间,本研究将bim的变换强制成第一行和其他行的交换,可能动作总共是b-1个。这样设计的可行性基础是无论bim的哪两行进行交换都可以通过第一行和另外两行的交换完成,这样才能保证bim的优化结果不被影响。同时,该设计在动作空间中还加入保持的动作nop。综上所述,bim模型优化的动作空间最终被优化成b个动作,如果b=32的话,动作空间数为32。
[0028]
(3)迭代优化
[0029]
强化学习模型是通过迭代来优化地址映射策略bim。首先,将bim各行展开成为一维矩阵作为输入,同时测试初始bim地址映射策略的行缓存命中率h,并将其作为模型当前的最佳值h
best
。设定k次迭代完成bim的优化,每一次迭代优化结果会进行新的行命中率测试,如果行命中率比h
best
高的话,会将该bim作为最佳的地址映射策略。如此将bim迭代优化。而行命中率h
best
也会随着迭代而不断提高。地址映射策略bim迭代优化过程伪代码如图4所示。
[0030]
2、模型训练
[0031]
模型训练过程中,策略网络当前时刻会生成下一个动作a
t
,当前时刻的bim会根据动作进行变换成下一时刻的bim。在k个周期过后,策略网络获得奖励值rk=hk。通过强化学习可以获得最大累积奖励值。同时也可以获得行命中率最高的基于bim的地址映射策略。
[0032]
本发明使用上文中提到策略梯度算法来迭代优化模型。累积奖励值的公式为:
[0033]rt
=γ
k 1rk
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式(3)
[0034]
其中,γ是折损因子。价值函数v
φ
(bim
t
)主要用来预测累积奖励值,通过策略梯度的方法来更新包含参数φ的神经网络。
[0035]
价值网络和策略网络中间结构一样,都是由两层全连接层组成的。差别在于,价值网络的输出是一个用来描述预测累积奖励值的数值。动作的优势的公式是用来表示智能体在当前环境选取这一动作的奖励值相对于策略网络随机选择动作的优势。具体公式如下:
[0036]at
=r
t-v
t
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式(4)
[0037]
最大化的目标函数为:
[0038][0039]
策略梯度为:
[0040][0041]
价值网络的损失函数为:
[0042][0043]
价值网络的梯度为:
[0044][0045]
在网络模型中,使用的是反向传播算法计算参数的梯度值,lr
π
和lrv分为为策略网络和价值网络的学习率(具体公式参见图5),在本次项目中都被设为0.001。
[0046]
本发明将模型参数按照mini-batch的方法更新。在实验中,将batch设置为64,这表示在一个batch中,策略网络会进行64次迭代更新。这64次迭代获得经验池(动作,奖励等)是用来更新模型中的参数的。但是,mini-batch的方法把输入数据和计算结果等数据全部保存下来,导致严重的存储开销。为了解决这个问题,实验中将一个batch的梯度累加起来作为参数梯度,策略网络和价值网络的累积梯度为g
θ
和g
φ
(具体公式参见图5)。使用mini-batch方法训练强化学习模型的算法如图5。
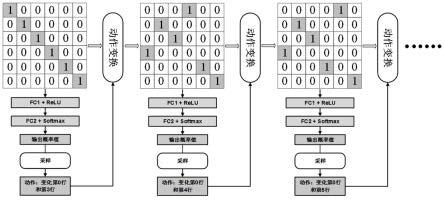
[0047]
3、工作流程
[0048]
本发明的迭代优化训练的整个过程如图6所示。将32*32的二进制可逆矩阵bim一维展开作为策略网络与价值网络输入,并在策略网络和价值网络上进行前项推导。策略网络训练推导过程会判定行命中率情况选择是否更新bim。模型根据概率选择动作,得到候选bim。当这个bim计算得到的行缓存命中率比当前bim高时,强化学习模型系统就会用候选的bim替换当前的bim。紧接着,会重新计算新的bim的行缓存命中率,即计算奖励值,同时更新上述两个网络的参数。系统根据上述过程不断迭代优化,依据设定的停止规则,可以收敛获得训练好的bim策略。同时也可以获得行命中率最高的地址映射策略,可以将其移植到fpga mig ip中硬件实现。
[0049]
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
