1.本发明涉及流数据处理技术领域,尤其涉及一种数据流规则引擎。
背景技术:
2.数据流(data stream)是一组有序,有起点和终点的字节的数据序列。包括输入流和输出流。数据流应用的产生的发展是以下两个因素的结果:细节数据。已经能够持续自动产生大量的细节数据。这类数据最早出现于传统的银行和股票交易领域,后来则也出现为地质测量、气象、天文观测等方面。尤其是互联网(网络流量监控,点击流)和无线通信网(通话记录)的出现,产生了大量的数据流类型的数据。我们注意到这类数据大都与地理信息有一定关联,这主要是因为地理信息的维度较大,容易产生这类大量的细节数据。
3.复杂分析。需要以近实时的方式对更新流进行复杂分析。对以上领域的数据进行复杂分析(如趋势分析,预测)以前往往是(在数据仓库中)脱机进行的,然而一些新的应用(尤其是在网络安全和国家安全领域)对时间都非常敏感,如检测互联网上的极端事件、欺诈、入侵、异常,复杂人群监控,趋势监控(track trend),探查性分析(exploratory analyses),和谐度分析(harmonic analysis)等,都需要进行联机的分析。
4.目前数据流主要涉及技术:1.apache flinkflink是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
5.其中flink检查点和容错:检查点是应用程序状态和源流中位置的自动异步快照。在发生故障的情况下,启用了检查点的flink程序将在恢复时从上一个完成的检查点恢复处理,确保flink在应用程序中保持一致性(exactly-once)状态语义。但是此项也有不足:一旦检查点依赖文件服务器异常,则原来保存的状态数据获取不到,就会导致整个系统异常。
6.2.drools规则引擎。
7.drools具有一个易于访问企业策略、易于调整以及易于管理的开源业务规则引擎,符合业内标准,速度快、效率高;也是一款基于 java 的开源规则引擎,以将复杂多变的规则从硬编码中解放出来,以规则脚本的形式存放在文件中,使得规则的变更不需要修正代码重启机器就可以立即在线上环境生效。但是有几点使用不足:1.版本兼容性:drools中的不同版本部分语法规则不能兼容;2.复杂性高:语法规则的多样性使得drools使用上对于规则的校验和格式要求非常严格。
技术实现要素:
8.本发明的目的在于克服现有技术的不足,提供一种数据流规则引擎,基于flink数据流引擎,对不同厂商结构做统一数据模型转换,并串联drools规则引擎,完成了规则数据
判定输出的效果,克服了现有物联网对大量设备数据分析处理效率低、延迟高、数据结构不适配等技术的不足。
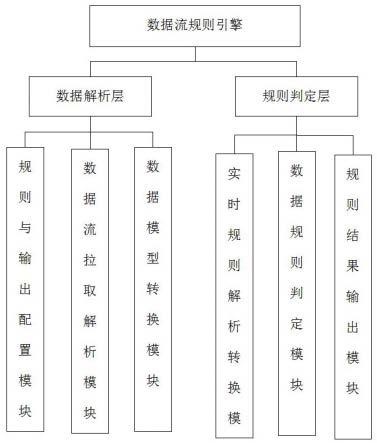
9.本发明的目的是通过以下技术方案来实现的:一种数据流规则引擎,包括数据解析层和规则判定层;数据解析层包括规则与输出配置模块、数据流拉取解析模块和数据模型转换模块;所述规则判定层包括实时规则解析转换模块、数据规则判定模块和规则结果输出模块;规则与输出配置模块用于根据具体的业务逻辑按照平台配置数据流规则和结果输出对象;数据流拉取解析模块用于基于flink近实时流处理框架拉取对应主题设备采集数据,并对采集数据进行解析;数据模型转换模块用于将获取的数据流模型转换规则数据模型,便于不同结构数据通用性的适配。
10.具体的,所述实时规则解析转换模块将平台管理端配置好的规则数据,结合drools相关api及其配置生成待触发的规则库rulebase,并生成kiesession规则会话。
11.具体的,所述数据规则判定模块通过drools中规则会话insert函数将物模型数据对象注入规则会话,同时通过规则会话fireallrules函数来触发启动规则引擎的执行。
12.具体的,所述将获取的数据流模型转换规则数据模型过程具体为:根据设备模型对象数据抽取设备基础信息;再通过将设备模型对象数据转为key与value的模式的map型通用结构;将抽取的基础信息和map数据统一成通用性的物模型数据对象。
13.具体的,所述数据流拉取解析模块具体用于创建运行环境并加载运行配置,并在程序启动后获取数据流并将数据解析成对应的设备模型对象数据。
14.具体的,所述根据具体的业务逻辑按照平台配置数据流规则和结果输出对象过程具体为:根据具体场景配置触发器、执行条件和执行动作实现数据流条件规则和输出动作的配置,并根据业务内容设置数据流条件规则名称和规则描述。
15.本发明的有益效果:1.通过flink数据流引擎,使得近实时、高吞吐、低延迟进行无边界数据流的分析处理;2.通过统一数据模型转换,使得平台可对不同厂商设备数据的完美接入。
16.3.通过drools规则引擎,使得规则与代码分离并服务不重启即可随时对规则变更扩展。
附图说明
17.图1是本发明的规则引擎系统功能模块图;图2是规则与输出配置示意图;图3是数据流规则引擎的工作流程图。
具体实施方式
18.为了对本发明的技术特征、目的和有益效果有更加清楚的理解,现对本发明的技术方案精选以下详细说明。显然,所描述的实施案例是本发明一部分实施例,而不是全部实施例,不能理解为对本发明可实施范围的限定。基于本发明的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的其他所有实施例,都属于本发明的保护范围。
19.实施例一:
本实施例中,如图1所示,一种数据流规则引擎,包括数据解析层和规则判定层;数据解析层包括规则与输出配置模块、数据流拉取解析模块和数据模型转换模块;所述规则判定层包括实时规则解析转换模块、数据规则判定模块和规则结果输出模块;规则与输出配置模块用于根据具体的业务逻辑按照平台配置数据流规则和结果输出对象;数据流拉取解析模块用于基于flink近实时流处理框架拉取对应主题设备采集数据,并对采集数据进行解析;数据模型转换模块用于将获取的数据流模型转换规则数据模型,便于不同结构数据通用性的适配。
20.本实施例中,数据流分为输入流(inputstream)和输出流(outputstream)两类。输入流只能读不能写,而输出流只能写不能读。通常程序中使用输入流读出数据,输出流写入数据,就好像数据流入到程序并从程序中流出。采用数据流使程序的输入输出操作独立与相关设备。
21.输入流可从键盘或文件中获得数据,输出流可向显示器、打印机或文件中传输数据。
22.为了提高数据的传输效率,通常使用缓冲流(buffered stream),即为一个流配有一个缓冲区(buffer),一个缓冲区就是专门用于传输数据的内存块。当向一个缓冲流写入数据时,系统不直接发送到外部设备,而是将数据发送到缓冲区。缓冲区自动记录数据,当缓冲区满时,系统将数据全部发送到相应的设备。
23.当从一个缓冲流中读取数据时,系统实际是从缓冲区中读取数据。当缓冲区空时,系统就会从相关设备自动读取数据,并读取尽可能多的数据充满缓冲区。
24.本实施例中,规则引擎软件系统模块可以分成6个部分:1、规则与输出配置模块,用于根据具体的业务逻辑按照平台配置相应的规则和结果输出对象。
25.该模块的具体实现过程如下:(1)如图2所示,根据具体场景配置触发器、执行条件、执行动作来达到相应条件规则和输出动作的配置。
26.2、数据流拉取解析模块,用于基于flink近实时流处理框架拉取对应主题设备采集数据,并做基本的数据解析。
27.数据流拉取解析模块具体实现过程为:(1)创建运行环境并加载运行配置,如:中配置数据源地址和主题、检查点地址等;(2)程序启动后会获取数据流并将数据解析成对应的设备模型对象数据。
28.3、数据模型转换模块,用于将获取的数据流模型转换规则数据模型,便于不同结构数据通用性的适配。
29.数据模型转换模块具体实现过程为:(1)根据设备模型对象数据抽取设备基础信息,如设备编码、设备采集时间;(2)再通过将设备模型对象数据转为key与value的模式的map型通用结构;(3)将抽取的基础信息和map数据统一成通用性的物模型数据对象。
30.4、实时规则解析转换模块,用于获取最新的drools规则配置模型数据,创建并生成对应规则库。
31.实时规则解析转换模块具体实现过程为:
(1)将平台管理端配置好的规则数据结合drools相关api及其配置生成待触发的规则库rulebase,并生成kiesession规则会话。
32.5、数据规则判定模块,用于将规则数据流模型数据注入规则库,并触发规则,进行规则判定。
33.数据规则判定模块具体实现过程为:(1)通过drools中规则会话insert函数【kiesession.insert(value)】将物模型数据对象注入规则会话;(2)同时通过规则会话fireallrules函数【kiesession.fireallrules()】来触发启动规则引擎的执行。
34.6、规则结果输出模块,用于在规则判定结束后,将判定结果根据实际配置设计输出。
35.规则结果输出模块具体实现过程为:根据具体规则结果和输出配置判断输出,如:消息输出【短信、邮件、web消息推送】、告警输出、设备指令下行输出。
36.规则引擎是一种嵌套在应用程序中的组件,实现将业务规则从应用程序代码中分离出来。规则引擎使用特定的语法编写业务规则。引入规则引擎后端带来的好处:(1)实现业务逻辑与业务规则的分离,实现业务规则的集中管理。
37.(2)可以动态修改业务规则,从而快速响应需求变更。
38.(3)使业务分析人员可以参与编辑、维护系统的业务规则。
39.(4)使用规则引擎提供的规则编辑工具,使复杂的业务规则实现变得简单。
40.本实施例中,还进行了规则引擎选型比较,目前的规则引擎系统中,使用较多的开源规则引擎是drools,另外还有商用的规则管理系统brms是ilog jrules。这两款规则引擎设计和实现都比较复杂,学习成本高,适用于大型应用系统。
41.一、drools:drools 是用 java 语言编写的开放源码规则引擎,基于apache协议和rete算法实现。drools就是为了解决业务代码和业务规则分离的引擎。drools 规则是在 java 应用程序上运行的,其要执行的步骤顺序由代码确定,为了实现这一点,drools 规则引擎将业务规则转换成执行树。drools优点:1、简化系统架构,优化应用。2、提高系统的可维护性和维护成本。3、方便系统的整合。4、减少编写“硬代码”业务规则的成本和风险。
42.drools的被分成两个主要部分:编写和运行系统。制作: 制作过程涉及创建规则文件(.drl文件)。运行时: 它涉及到创建工作存储器和处理活化。
43.drools优点在于策略规则和执行逻辑解耦方便维护,其调用方式可以分为以下两种:(1)创建好服务后提供api直接调用;(2)二次开发。与前端配合(通过蚂蚁g6组件实现规则编辑,传递json格式的drl脚本),后端解析json并集成quartz或akka任务调度,使用spring kafka组件接收来自集群的数据流。
44.二、ilog jrules:ibm websphere ilog jrules 是目前业界领先的业务规则管理平台。与传统的由 it 人员用硬代码来维护规则的做法不同,ilog jrules 让业务用户能够在不依赖或者有限依赖于 it 人员的情况下,快速创建、修改、测试和部署业务规则,以满足经常变化的业
务需求。ilog jrules 提供了一整套的工具,帮助开发人员和业务人员进行规则的全生命周期管理。
45.ilog jrules主要组件包括:1、rule studio(rs) 面向开发人员使用的开发环境,用于规则的建模和编写。
46.2、rule scenario manager 规则测试工具。
47.3、rule team server(rts) 基于web的管理环境,面向业务人员使用,用于规则发布、管理、存储。
48.4、rule execution server(res) 面向运维人员使用,用于规则执行、监控。
49.jrules 规则引擎提供了 reteplus、sequential 和 fastpath 三种运行模式,以适应不同的应用需求,获得最优性能。在基于业务规则引擎的应用中,需要根据不同应用的特点,合理地组织和编排业务规则,选择合适的运行模式,有助于更好的发挥规则引擎的效能,但同时复杂度较高。
50.三、easy rules:easy rules 是一款 java 规则引擎,它的诞生启发自有martin fowler 一篇名为
ꢀ“
should i use a rules engine
”ꢀ
文章。easy rules 提供了规则抽象来创建带有条件和操作的规则,以及运行一组规则来评估条件和执行操作的rulesengine api。
51.easy rules特性包括:1、轻量级框架和易于学习的api。2、基于pojo的开发。3、通过高效的抽象来定义业务规则并轻松应用它们。4、支持创建复合规则。5、使用表达式语言定义规则的能力。
52.四、visual rules:旗正visualrules是由国家科技部和财政部的创新基金支持,专门针对国内规则引擎市场空白的情况,结合国内项目的特点而开发的一款业务规则管理系统(brms)产品。
53.visual rules是在规则引擎基础上发展出来的一款产品,其秉承了规则引擎可以使业务逻辑的变化可以独立于程序之外的特点,同时结合国内软件项目的特点,为数据库层和界面层也提供了独立于程序之外配置的特点,因此本产品不光是一个业务规则管理系统,还是一个基于规则引擎的web快速开发平台。
54.五、urule规则引擎:urule是一款纯java规则引擎,它以rete算法为基础,提供了向导式规则集、脚本式规则集、决策表、交叉决策表(pro版提供)、决策树、评分卡及决策流共六种类型的规则定义方式,配合基于web的设计器,可快速实现规则的定义、维护与发布。
55.本实施例中,使用drools工具进行引擎系统的设计开发,以flink数据流引擎和drools规则引擎为基础技术支撑可接入大量的设备数据,分析处理可达毫秒级,实现了高吞吐、低延迟的高效率数据规则处理;并可对不同厂商结构做统一数据模型转换,这样就可兼容很大部分厂商设备结构数据模型的功能。本实施例中,如图3所示,数据流规则引擎系统的工作流程包括:(1)基于flink近实时流处理框架,利用中间件拉取对应主题设备采集数据,并对采集数据进行基本解析。
56.(2)采集数据转换规则数据模型,将获取的数据流模型转换规则数据模型,获取最新的drools规则配置模型数据,创建并生成对应规则库;
(3)通过drools中规则会话insert函数【kiesession.insert(value)】将物模型数据对象注入规则会话;同时通过规则会话fireallrules函数【kiesession.fireallrules()】来触发启动规则引擎的执行;(4)在规则判定结束后,将判定结果根据实际配置设计输出。
57.本实施例具有以下技术优势:1.通过flink数据流引擎,使得近实时、高吞吐、低延迟进行无边界数据流的分析处理;2.通过统一数据模型转换,使得平台可对不同厂商设备数据的完美接入。
58.3.通过drools规则引擎,使得规则与代码分离并服务不重启即可随时对规则变更扩展。
59.本发明创造主要基于flink数据流引擎,对不同厂商结构做统一数据模型转换,并串联drools规则引擎,完成了规则数据判定输出的效果,克服了现有物联网对大量设备数据分析处理效率低、延迟高、数据结构不适配等技术的不足。
60.以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护的范围由所附的权利要求书及其等效物界定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
