1.本发明涉及语音识别技术领域,特别涉及一种基于自监督学习的语音情感识别方法和计算机设备。
背景技术:
2.人类的语音包含着丰富内容,除语言内容外,还包含着自身的情感信息。想要准确理解说话者的意图,深度解析语音中的情感信息是一种有效手段。语音情感识别(speech emotion recognition,ser)通过识别语音中的情感信息来帮助深度理解用户真实意图,语音情感识别技术在安全、教育、金融等领域已经得到了广泛应用。
3.现有技术中语音情感识别方法的训练方式决定了需要从大量带标注样本中学习语音特征和情感规律,如果带标注样本数量不足、质量低,则只能学习到不完整或错误的语音特征和情感类别,识别效果不理想,准确率低且泛化性差。而大规模、高质量的语音情感识别带标注数据集获取困难,人工标注成本很高,因此当前语音情感识别方法效果不够理想。
技术实现要素:
4.鉴于上述的分析,本发明旨在提供一种基于自监督学习的语音情感识别方法和计算机设备;解决了现有技术中语音情感识别方法高度依赖于带标注训练数据集的规模和质量,识别准确率低且泛化性差的问题。
5.本发明的目的主要是通过以下技术方案实现的:
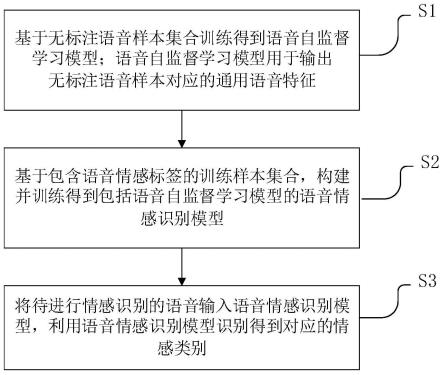
6.一方面,本发明公开了一种基于自监督学习的语音情感识别方法,包括以下步骤:
7.基于无标注语音样本集合训练得到语音自监督学习模型;所述语音自监督学习模型用于输出所述无标注语音样本对应的通用语音特征;
8.基于包含语音情感标签的训练样本集合,构建并训练得到包括所述语音自监督学习模型的语音情感识别模型;
9.将待进行情感识别的语音输入所述语音情感识别模型,利用所述语音情感识别模型识别得到对应的情感类别。
10.进一步的,所述语音自监督学习模型包括特征编码器、量化模块、掩蔽模块和上下文网络;
11.所述特征编码器用于根据输入的所述无标注语音样本获取所述无标注语音样本的隐层语音表示;
12.所述量化模块用于根据所述隐层语音表示,通过乘积量化得到量化隐层语音表示;
13.所述掩蔽模块用于对特征编码器获取到的所述隐层语音表示进行随机时间步掩蔽,得到掩蔽结果;
14.所述上下文网络用于根据所述掩蔽结果,利用自注意力机制,得到包括每个时间
步的序列表征的所述无标注语音样本的整体序列表征;
15.训练所述语音自监督学习模型时,基于所述量化隐层语音表示和整体序列表征进行损失迭代更新。
16.进一步的,所述基于所述量化隐层语音表示和整体序列表征进行损失迭代更新,包括:
17.构建包含干扰项和所述量化隐层语音表示的量化候选表示集合;
18.根据掩蔽时间步t的所述序列表征c
t
,基于所述量化候选表示集合对时间步t对应的量化隐层语音表示q
t
进行预测;
19.基于所述序列表征c
t
和量化候选表示集合中的量化候选表示的对比误差进行损失迭代更新,得到所述语音自监督学习模型。
20.进一步的,所述干扰项为k个,k个所述干扰项为在当前输入的无标注语音的除时间步t以外的时间步中均匀取样的k个时间步所对应的所述序列表征;其中,k为大于1的整数。
21.进一步的,所述对比误差表示为:
[0022][0023]
其中,sim(a,b)=a
t
b/‖a‖‖b‖表示上下文表示和量化隐层语音表示之间的余弦相似性,a代表c
t
,b代表q
t
;为量化候选表示集合;c
t
为上下文网络输出的时间步t对应的序列表征;q
t
为时间步t的量化隐层语音表示。
[0024]
进一步的,所述通过乘积量化得到量化隐层语音表示,包括:将所述特征编码器输出的每个时间步的隐层语音表示分为n组子向量,n为大于1的整数,对每组子向量进行聚类,得到n个码本;从时间步t的n个码本中各随机选择一个中心点进行拼接,得到时间步t的量化隐层语音表示q
t
。
[0025]
进一步的,所述对所述隐层语音表示进行随机掩蔽,包括:随机选择时间步t作为起始索引,将所述起始索引及随后的m个连续时间步替换为静音,m为大于1的整数,得到时间步t的掩蔽结果;按照预先设定的比例对所述隐层语音表示进行随机掩蔽,得到输入的无标注语音的掩蔽结果。
[0026]
进一步的,所述语音情感识别模型还包括softmax层,用于接收所述语音自监督学习模型输出的所述通用语音特征,进行情感多分类任务,输出待识别语音对应的情感类别。
[0027]
进一步的,所述包含标注标签的训练样本集合采用ravdess数据集,包含冷静、快乐、悲伤、愤怒、恐惧、厌恶和惊讶七个情感类型。
[0028]
另一方面,本发明还提供了一种计算机设备,包括至少一个处理器,以及至少一个与所述处理器通信连接的存储器;
[0029]
所述存储器存储有可被所述处理器执行的指令,所述指令用于被所述处理器执行以实现前述的语音情感识别方法。
[0030]
本发明至少可实现以下有益效果之一:
[0031]
1、本发明采用两次训练的方式,将第一次基于无标注语音样本集合训练得到的模型作为语音情感识别模型的初始模型,得到通用语音特征,在通用语音特征基础上进行第
二次训练时,仅使用少量带情感标签的数据进行微调,使得本方法的情感识别效果更好训练时间短。
[0032]
2、本发明使用少量的情感标签标注数据作为训练样本,减少了获取大量标记数据耗费的人力成本、时间成本;
[0033]
3、本发明引入自监督学习技术,首先通过大规模无标注数据集训练学习通用语音特征,然后使用少量语音情感标注数据进行微调,实现语音情感识别方法,提高了语音识别的泛化能力,解决了传统语音情感识别方法高度依赖大规模、高质量语音情感识别带标注数据集的问题。本发明的语音情感识别方法在使用原始语音情感识别方法百分之一数据量的情况下,情感识别准确率和泛化性均优于传统语音情感识别方法。
[0034]
本发明的其他特征和优点将在随后的说明书中阐述,并且,部分的从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
附图说明
[0035]
附图仅用于示出具体实施例的目的,而并不认为是对本发明的限制,在整个附图中,相同的参考符号表示相同的部件。
[0036]
图1为本发明实施例的基于自监督学习的语音情感识别方法的流程图。
[0037]
图2为本发明实施例的语音自监督学习模型的结构图。
具体实施方式
[0038]
下面结合附图来具体描述本发明的优选实施例,其中,附图构成本技术一部分,并与本发明的实施例一起用于阐释本发明的原理,并非用于限定本发明的范围。
[0039]
本实施例中的一种基于自监督学习的语音情感识别方法,如图1所示,包括以下步骤:
[0040]
步骤s1、基于无标注语音样本集合训练得到语音自监督学习模型;所述语音自监督学习模型用于输出所述无标注语音样本对应的通用语音特征;其中,无标注语音样本集合包括不同性别、不同语种的广播、对话等不同形式的纯人声语音;通用语音特征为神经网络依据自身结构自动从输入语音中获取的语音特征,可以包括声强、响度、音高、短时过零率,基频和能量等特征,可用于语音情感识别、语种识别、语音转写等语音处理任务。
[0041]
具体的,如图2所示,语音自监督学习模型包括特征编码器、量化模块、掩蔽模块和上下文网络;其中,
[0042]
特征编码器用于根据输入的无标注语音样本获取所述无标注语音样本的隐层语音表示;隐层语音表示为特征编码器从输入语音中获取的语音特征。
[0043]
优选的,特征编码器采用2层cnn结构,卷积核为5*3,步长为2;将样本集合中的无标注语音按照预设时间间隔为单位分为多个语音片段,得到无标注语音序列x,将x输入特征编码器,特征编码器从x中自动获取无标注语音样本对应的隐层语音表示z={z1,z2,
…
,z
t
,
…
,z
t
},其中z
t
为时间步t的隐层语音表示,为512维向量;t=1,
……
t;t=无标注语音长度/预设时间间隔,示例性的,预设时间间隔可以为20ms。
[0044]
量化模块用于根据特征编码器输出的隐层语音表示,通过乘积量化得到量化隐层
语音表示;具体的,将特征编码器输出的无标注语音样本对应的隐层语音表示z输入量化模块后,通过量化模块将特征编码器输出的每个时间步的隐层语音表示分为n组子向量,n为大于1的整数,对每组子向量进行聚类,得到n个码本;从时间步t的n个码本中各随机选择一个中心点进行拼接,得到时间步t的量化隐层语音表示q
t
;优选的,本实施例中,首先将隐层语音表示z中每一个时间步的语音表示平均分为4组子向量,每组子向量为128维,对于每组子向量使用kmeans方法聚成256类,即得到256个中心点,则每组子向量构成一个码本,得到4个码本。在训练过程中,从时间步t的隐层语音表示z
t
对应的4个码本中随机选择一个中心点并进行拼接,得到时间步t的量化语音表示q
t
。
[0045]
所述掩蔽模块用于对特征编码器获取到的所述隐层语音表示进行随机时间步掩蔽,得到掩蔽结果;本实施例中,随机选择时间步t作为起始索引,将起始索引及随后的m个连续时间步替换为静音,得到时间步t的掩蔽结果,其中m为大于1的整数;按照预先设定的比例p对所述隐层语音表示进行随机掩蔽,得到输入的无标注语音的掩蔽结果。优选的,两次掩蔽的部分之间可以重叠,p的取值在0.06-0.07之间。
[0046]
所述上下文网络用于根据所述掩蔽结果,利用自注意力机制,得到包括每个时间步的序列表征的所述无标注语音样本的整体序列表征;具体的,将掩蔽模块输出的掩蔽结果作为上下文网络的输入;上下文网络采用原生transformer结构,利用自注意力机制,得到无标注语音的整体序列表征c={c1,c2,
…ct
,
…
,c
t
},其中c
t
为无标注语音在时间步t的序列表征。
[0047]
训练所述语音自监督学习模型时,基于所述量化隐层语音表示和整体序列表征进行损失迭代更新。具体的,对于上下文网络输出的在时间步t的序列表征c
t
,语音自监督学习模型需要在一组包括q
t
和干扰项的量化候选表示集合中预测出真实的量化隐层语音表示q
t
。首先构建包含干扰项和所述量化隐层语音表示q
t
的量化候选表示集合,优选的,干扰项为k个,k个所述干扰项为在当前输入的无标注语音的除时间步t以外的时间步中均匀取样的k个时间步所对应的序列表征;其中,k为大于1的整数。模型的损失为对比误差l,如下列公式所示:
[0048][0049]
其中,sim(a,b)=a
t
b/‖a‖‖b‖表示上下文表示和量化隐层语音表示之间的余弦相似性,a代表c
t
,b代表q
t
;为量化候选表示集合;c
t
为上下文网络输出的时间步t对应的序列表征;q
t
为量化模型输出的时间步t对应的量化隐层语音表示。
[0050]
在训练过程中,将无标注语音样本集合输入模型,使用adam优化方法逐步降低对比误差l,得到收敛的语音自监督学习模型,即获得了通用语音特征。
[0051]
需要说明的是,自监督学习是一种自动为数据产生标签,在标签上学习领域通用特征的方法。自监督学习方法通过特定的辅助任务来为数据自动产生标签,通过对大量数据的自动标注和训练,生成领域通用特征;本发明引入自监督学习技术大大降低了语音情感识别方法对带标注数据的依赖性,使用自监督学习技术在大规模无标注数据集上学习通用语音特征,之后采用少量带情感标注的数据进行训练,即可得到高准确性、高泛化能力的语音情感识别模型。
[0052]
步骤s2:基于包含语音情感标签的训练样本集合,构建并训练得到包括所述语音自监督学习模型的语音情感识别模型。
[0053]
具体的,语音情感识别任务可以看作多分类任务,可使用softmax层接收语音自监督学习模型的输出,并生成一个n维向量,多分类任务中的每个情感类别对应一个向量,同时softmax层对每个向量的值进行归一化,并转化为针对n个情感类别的概率,概率最大的类别即为当前输入语音对应的情感类型。
[0054]
优选的,本实施例采用包含标注标签的ravdess数据集作为训练样本,ravdess数据集包含7356条语音,包括冷静、快乐、悲伤、愤怒、恐惧、厌恶和惊讶七个情感类型。在语音自监督学习模型的基础上,增加一个softmax层,用于接收语音自监督学习模型输出的通用语音特征,进行情感多分类任务,使用ctc损失作为模型损失函数进行梯度更新,得到收敛的语音情感识别模型。
[0055]
本发明在经过预训练的语音自监督学习模型的基础上,使用少量带情感标签的数据进行简单拟合,即实现了语音情感识别方法,减少了获取大量标记数据耗费的人力成本、时间成本。
[0056]
步骤s3、将待进行情感识别的语音输入所述语音情感识别模型,利用所述语音情感识别模型识别得到对应的情感类别。具体的,将待识别的无标注语音输入训练完毕的语音情感识别模型,模型根据输入语音的特征自动生成输入语音所属的情感类型。
[0057]
综上所述,本发明提出的一种基于自监督学习的语音情感识别方法,引入自监督学习技术,使用无标注语音数据集进行训练,在大规模无标注语音数据集上学习通用语音特征;然后在通用语音特征上基于小规模的带情感标注数据进行微调,实现了高准确性和泛化性的语音情感识别方法;实验表明,本发明技术方案的效果优于传统的语音情感识别方法。
[0058]
现有技术中语音情感识别的主要流程为:将语音情感识别看作分类问题,准备大量含有情感类型标签的语音作为训练数据集;针对领域特点构建特定的神经网络结构,使用含情感类型标签的训练数据集进行训练,得到语音情感识别模型;将不包含情感类型标签的语音输入语音情感识别模型,得到语音对应的情感类型,实现语音情感识别。本发明使用自监督学习方法对现有语音情感识别方法进行了优化,使得语音情感识别方法在当前大规模、高质量的带标注数据集缺乏的情况下也可以达到理想的识别效果。本发明采用两次训练的方式,首先将基于无标注语音样本集合训练得到的模型作为初始模型,得到通用语音特征;其次,在通用语音特征基础上使用少量待情感标签的数据集进行第二次训练,解决了传统语音情感识别方法对大规模、高质量带情感标注的数据集的依赖问题,使用少量的训练样本,提高了情感识别的准确率和泛化性能。
[0059]
本发明的另一个实施例,提供了一种计算机设备,包括至少一个处理器,以及至少一个与所述处理器通信连接的存储器;存储器存储有可被处理器执行的指令,所述指令用于被处理器执行以实现前述实施例的基于自监督学习的语音情感识别方法。
[0060]
本领域技术人员可以理解,实现上述实施例方法的全部或部分流程,可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于计算机可读存储介质中。其中,所述计算机可读存储介质为磁盘、光盘、只读存储记忆体或随机存储记忆体等。
[0061]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,
任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。