1.本发明涉及检索技术领域,尤其是一种学者网多模态检索模型的训练方法、系统和存储介质。
背景技术:
2.相关技术中,在常见的多模态数据中,图像往往对应于该图像的文字描述,即图像与文字具有相当强的底层语义关联关系。但是,在学术网站上收集起来的数据集,一般具有较弱的图文语义对应关系,更偏向于人的活动而非图文在细节上的对应,同时数据的噪声也比较大。相对于已有的图文数据集,学者网里面的文本会更加常,会更加以文本为主,而且不是用来对图像进行具体的描述。因此,基于学者网的多模态数据的分布与已有的数据集分布是不同的,导致使用现有的预训练模块当初始化参数,再使用少量的下游数据进行微调的方式,再使用少量下游数据进行微调的方式,难以提高检索结果的准确度。
技术实现要素:
3.本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明提出一种学者网多模态检索模型的训练方法、系统和存储介质,能够有效提高学者网数据检索结果的准确度。
4.一方面,本发明实施例提供了一种学者网多模态检索模型的训练方法,所述学者网多模态检索模型包括数据适应模块、预训练模块和非线性迁移模块,所述训练方法包括以下步骤:
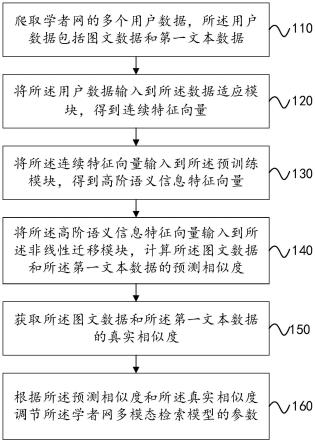
5.爬取学者网的多个用户数据,所述用户数据包括图文数据和第一文本数据;
6.将所述用户数据输入到所述数据适应模块,得到连续特征向量;
7.将所述连续特征向量输入到所述预训练模块,得到高阶语义信息特征向量;
8.将所述高阶语义信息特征向量输入到所述非线性迁移模块,计算所述图文数据和所述第一文本数据的预测相似度;
9.获取所述图文数据和所述第一文本数据的真实相似度;
10.根据所述预测相似度和所述真实相似度调节所述学者网多模态检索模型的参数。
11.在一些实施例中,所述数据适应模块包括线性嵌入层和文字提取层;所述将所述用户数据输入到所述数据适应模块,得到连续特征向量,包括:
12.将所述第一文本数据输入所述线性嵌入层,得到第一文本连续特征向量;
13.将所述图文数据输入所述文字提取层,得到第二文本数据;
14.将所述第二文本数据输入到所述线性嵌入层,得到第二文本连续特征向量。
15.在一些实施例中,所述预训练模块包括文本特征提取器和视觉特征提取器;所述将所述连续特征向量输入到所述预训练模块,得到高阶语义信息特征向量,包括:
16.将所述第一文本连续特征向量输入所述文本特征提取器,得到第一文本高阶语义信息特征向量;以及将第二文本连续特征向量输入所述文本特征提取器,得到第二文本高
阶语义信息特征向量;
17.将所述图文数据输入所述视觉特征提取器,得到图像高阶语义信息特征向量。
18.在一些实施例中,所述将所述高阶语义信息特征向量输入到所述非线性迁移模块,计算所述图文数据和所述第一文本数据的预测相似度,包括:
19.将所述第一文本高阶语义信息特征向量和所述图像高阶语义信息特征向量输入到所述非线性迁移模块,得到第一相似度;
20.将所述第一文本高阶语义信息特征向量和所述第二文本高阶语义信息特征向量输入到所述非线性迁移模块,得到第二相似度;
21.根据所述第一相似度和所述第二相似度,计算预测相似度。
22.在一些实施例中,所述非线性迁移模块包括全连接层、bn层和relu层。
23.在一些实施例中,在所述将所述第一文本数据输入所述线性嵌入层之前,所述方法还包括以下步骤:
24.通过中文分词工具将所述第一文本数据转换为单词文本。
25.在一些实施例中,所述文字提取层包括ocr模块。
26.另一方面,本发明实施例提供了一种学者网多模态检索模型的训练系统,所述学者网多模态检索模型包括数据适应模块、预训练模块和非线性迁移模块,所述系统包括:
27.爬取模块,用于爬取学者网的多个用户数据,所述用户数据包括图文数据和第一文本数据;
28.第一数据处理模块,用于将所述用户数据输入到所述数据适应模块,得到连续特征向量;
29.第二数据处理模块,用于将所述连续特征向量输入到所述预训练模块,得到高阶语义信息特征向量;
30.计算模块,用于将所述高阶语义信息特征向量输入到所述非线性迁移模块,计算所述图文数据和所述第一文本数据的预测相似度;
31.获取模块,用于获取所述图文数据和所述第一文本数据的真实相似度;
32.调节模块,用于根据所述预测相似度和所述真实相似度调节所述学者网多模态检索模型的参数。
33.另一方面,本发明实施例提供了一种学者网多模态检索模型的训练系统,包括:
34.至少一个存储器,用于存储程序;
35.至少一个处理器,用于加载所述程序以执行所述的学者网多模态检索模型的训练方法。
36.另一方面,本发明实施例提供了一种存储介质,其中存储有计算机可执行的程序,所述计算机可执行的程序被处理器执行时用于实现所述的学者网多模态检索模型的训练方法。
37.本实施例提供的一种学者网多模态检索模型的训练方法,具有如下有益效果:
38.本实施例通过将爬取的多个包括图文数据和第一文本数据的用户数据输入到数据适应模块内,以得到预训练模块能够接收的连续特征向量,接着将连续特征向量输入到预训练模块后,得到高阶语义信息特征向量,再通过非线性迁移模块根据高阶语义信息特征向量,计算得到图文数据和第一文本数据的预测相似度,再将预测相似度与真实相似度
来调节学者网多模态检索模型的参数,从而可以使学者网多模态检索模型的参数能够达到学者网数据检索的较佳效果,以有效提高学者网数据检索结果的准确度。
39.本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
40.下面结合附图和实施例对本发明做进一步的说明,其中:
41.图1为本发明实施例的一种学者网多模态检索模型的训练方法的流程图;
42.图2为本发明实施例的一种学者网多模态检索模型的示意图。
具体实施方式
43.下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
44.在本发明的描述中,需要理解的是,涉及到方位描述,例如上、下、前、后、左、右等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
45.在本发明的描述中,若干的含义是一个以上,多个的含义是两个以上,大于、小于、超过等理解为不包括本数,以上、以下、以内等理解为包括本数。如果有描述到第一、第二只是用于区分技术特征为目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量或者隐含指明所指示的技术特征的先后关系。
46.本发明的描述中,除非另有明确的限定,设置、安装、连接等词语应做广义理解,所属技术领域技术人员可以结合技术方案的具体内容合理确定上述词语在本发明中的具体含义。
47.本发明的描述中,参考术语“一个实施例”、“一些实施例”、“示意性实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
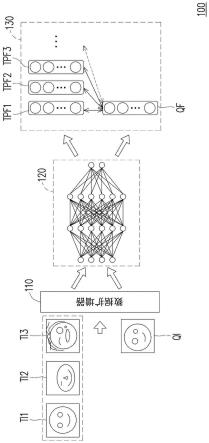
48.随着互联网的快速发展和广泛应用,学术社交网络受到了广泛的关注。学者网是一个有着大量学者用户的学术社交网站,其中产生了大量实际应用的学术数据,使得真实场景下的学术关系、学术活动等学术服务有了数据基础。这些数据中也存在大量学者们发布在学者网上的包含了的图片和文本的多模态数据。
49.为了更好地学习与理解真实学术社交网络的多模态数据,一种做法是收集大量的真实数据来训练,但要收集足够的数据是比较困难的。另一方面,随着计算资源的不断扩大,网络层数也越来越深、参数越来越多,是数据饥渴的。这两个方面都使得直接使用目标数据从头开始训练变得困难。
50.面向实际应用的学术社区多模态数据集不同于一般的多模态数据集。在常见的多
模态数据集中,图像往往对应于该图像的文字描述,是具有相当强的低层语义关联信息。但在学术网站上的收集起来的数据集,一般来说具有较弱的图文语义对应,更偏向于人的活动而非图文在细节上的对应,同时数据的噪声也比较大。相对于已有的图文数据集,学者网里面的文本会更加长,会更加以文本为主,而且不是用来对图像进行具体的描述。图像在这里充当补充信息,用来更好说明具体情况。基于学者网的多模态数据的分布跟已有的数据集的分布是不同的,这使得传统的使用预训练模块当初始化参数,再使用少量的下游数据进行微调的方式很难取得很好的效果。
51.基于此,参照图1,本发明实施例提供了一种学者网多模态检索模型的训练方法。具体地,如图2所示,所述学者网多模态检索模型包括数据适应模块、预训练模块和非线性迁移模块。对于图2所示模型的训练方法,如图1所示,所述训练方法包括步骤110-步骤150:
52.步骤110、爬取学者网的多个用户数据,所述用户数据包括图文数据和第一文本数据。
53.在本技术实施例中,主要爬取学术社交网络中学者的多模态数据作为用户数据。其中,学者的多模态数据包括文本数据ti和图像数据ii,将爬取得到的文本数据ti作为第一文本数据。定义表示一组具有图像和文本两个模态的训练样本。由于在图像数据中也包括一部分文本数据则可以将该部分的文本数据作为第二文本数据,并定义在多模态数据检索过程中,给出一种模态的数据,则可以检索得到另一种模态的数据。例如,用户给出图像数据,则可以检索得到图文数据对应的文本数据;反之,用户给出文本数据,则可以检索得到图像数据。
54.步骤120、将所述用户数据输入到所述数据适应模块,得到连续特征向量。
55.在本技术实施例中,如图2所示,所述数据适应模块包括线性嵌入层和文字提取层。基于该结构,本步骤可以通过将所述第一文本数据输入所述线性嵌入层,以通过线性嵌入层将第一文本数据转换为第一文本连续特征向量;将所述图文数据输入所述文字提取层,通过文字提取层从图像数据中提取得到第二文本数据,再将所述第二文本数据输入到所述线性嵌入层,以通过线性嵌入层将第二文本数据转换为第二文本连续特征向量。在本实施例中,文字提取层可以采用ocr模块。其中,ocr(optical character recognition)模块是指电子设备监测纸上打印的字符,通过检测暗亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字。
56.在本实施例中,由于本实施例聚焦图像与文本的检索,对于文本模态,由于文本在数据集上的分布与其他多模态数据集的分布不相同,本实施例通过添加一个简单线性嵌入层,以得到学者网上面的中文特征。对于图像视觉模态,为了充分利用图像上包含的文字信息,本实施例先利用ocr技术提取图像中的文本,并将提取到的文本作为附加信息。
57.具体地,对于图2中的数据自适应模块,本实施例先采用中文分词工具将数据集里面的中文进行分词,然后将分好的单词采用预训练模块chinese roberta large得到中文的特征表示,再接入简单线性层,将文本特征处理成预训练模块的文本输入向量。文本ti可表示为w1,w2,...,wm,其中wj是第j个中文样本的特征表示,m是这段文本里面总共的字数。由于学者网图像上有大量的文字信息,本实施例使用已有的ocr模型对图像进行文字抽取
其中,ocr是任意一个光学字符识别算法,是对图像抽取出来的文字。对图像抽取出来的文本也进行相同的操作,从而得到的每个单词的特征表示其中l是总共的词的数量。
58.步骤130、将所述连续特征向量输入到所述预训练模块,得到高阶语义信息特征向量。
59.在本技术实施例中,如图2所示,所述预训练模块包括文本特征提取器和视觉特征提取器。基于该结构,本步骤可以将所述第一文本连续特征向量输入所述文本特征提取器,得到第一文本高阶语义信息特征向量;以及将第二文本连续特征向量输入所述文本特征提取器,得到第二文本高阶语义信息特征向量;将所述图文数据输入所述视觉特征提取器,得到图像高阶语义信息特征向量。具体地,第一文本连续特征向量和第二文本连续特征向量可以通过同一个文本特征提取器进行编码后得到文本高阶语义信息特征向量。视觉特征提取器是通过将图像数据从像素点处理成连续的特征表示。
60.在本技术实施例中,对于预训练模块,主要包括三个输入数据,一个是原来的文本ti可表示为w1,w2,...,wm,图像数据ii和图像抽取出来的文本对于视觉特征,利用已经训练好的视觉特征提取器将图像从像素点处理成连续的特征表示vi=visual encoder(ii)。同理对于两个文本,使用相同的文本提取器得到两个文本的特征表示,文本数据的特征表示分别为fi=text encoder(ti)、对于预训练模块,由于下游任务学者网多模态数据的数据量过少,本实施例固定模型参数,以便提高模型利用利用率。
61.步骤140、将所述高阶语义信息特征向量输入到所述非线性迁移模块,计算所述图文数据和所述第一文本数据的预测相似度。
62.在本实施例中,可以将所述第一文本高阶语义信息特征向量和所述图像高阶语义信息特征向量输入到所述非线性迁移模块,得到第一相似度;同时将所述第一文本高阶语义信息特征向量和所述第二文本高阶语义信息特征向量输入到所述非线性迁移模块,得到第二相似度;然后根据所述第一相似度和所述第二相似度,计算预测相似度。
63.具体地,由于预训练模型所使用的的数据跟下游学者网数据分布存在差异,已有的多模态数据更加关注具体的低层的语义关联,而学术多模态数据需要的是更高层的学术活动等主题,为了在知识迁移过程中,减少低层的语义而更加关注高层的语义,在训练过程中,本实施例利用一个非线性的迁移模块将上游学习到的知识更好地迁移到学者网的数据中。同时,提出了一个轻量级迁移模块adapter2scholar,将现有的预训练模块转换到学者网多模态数据。
64.图像和文本通过预训练好的模型后,得到的特征表示fi、vi和再通过一个轻量级非线性的迁移模块适应并学习下游学者网的多模态数据,该模块由多个全连接层、bn层和relu(激活函数)层组成。图像数据和第一文本数据的新特征表示分别为其中wv和w
t
是要学习两个参数,wv是学习视觉特征,而w
t
是学习文本特征。经过一个残差神经网络,对原特征堆叠多个层进行非线性变换,再加上原特征得到样本i的两个新特征,图像数据和第一文本数据的相似度为
65.根据上述网络可以得到图像补充文字(第二文本数据)和已有文本数据(第一文本数据)的新特征表示分别为由于抽取的文字好已有文本属于同一模态,为了更好地学习两者之间的相似性,使用同一个学习参数两个特征之间的相似度为这些新的特征忽略低层的语义关联特征,关注更高层的主题和人的活动等信息,从而更好地将预训练多模态模型学习到的知识迁移到学者网的多模态数据检索中。将图像语文本的相似度、文本和文本的相似度两个维度进行融合,得到最终的多相似度融合结果sim=sim1 sim2。将多相似度融合结果作为图文数据和第一文本数据的预测相似度。
66.步骤150、获取所述图文数据和所述第一文本数据的真实相似度。
67.步骤160、根据所述预测相似度和所述真实相似度调节所述学者网多模态检索模型的参数。
68.在本技术实施例中,通过反向调节模型的参数,从而可以使模型更好的适应学者网的多模态检索过程。
69.在本实施例的训练过程中,定义logistic回归损失函数minl
sim
=∑
(i,j)
y(i,j)log(sim(i,j) (1-y(i,j)log(1-sim(i,j)))),其中y(i,j)指图像与文本之间的真实相似度,1表示相似,0表示不相似。本实施例利用损失函数,通过反向传导的方式将梯度传回轻量级迁移模块,实现从下游到上游的迁移模块的参数学习,从而利用模型得到图文检索结果。
70.具体地,当完成上述模型的训练过程后,可以将上述模型用于实际的检索过程。其中,检索过程中包括以下步骤:
71.步骤一、对学者网数据进行图文模态数据采样,分成文本数据ti和图像数据ii;
72.步骤二、用分词工具处理文本数据,在预训练模块前添加一个简单的线性嵌入层linear embedding,将文本数据处理为连续的特征向量ti={w1,w2,...,wm};
73.步骤三、利用光学字符识别算法ocr提取出图像中的文本数据得到图像的文本补充信息的连续特征向量
74.步骤四、对图像数据和文本数据分别使用视觉特征提取器visual encoder(ii)和text encoder(ti),得到具有高阶语义的特征向量表示vi、fi、
75.步骤五、在预训练模型后端加上一个轻量级非线性迁移模块以适应下游的少样本多模态数据,再将具有高阶语义的特征向量输入由多个全连接层、bn层和relu层组成的迁移模块中;
76.步骤六、将图像和文本数据的高阶语义特征输入迁移模块,得到图像及文本的新特征通过计算两个新特征的余弦相似度得到图文相似度
77.步骤七、将从图像上抽取的文本和已有文本的高阶语义特征输入迁移模块,得到
新特征计算出两者之间的相似度
78.步骤八、融合图像与文本、文本和文本两个维度的特征相似度得到文本与图像的多维相似度sim=sim1 sim2;
79.步骤九、利用图文匹配后得到的相似度分数sim来表示输入图像跟文本的相似程度,从而进行图文信息的检索。
80.综上可知,本实施例提供的一种学者网多模态检索模型的训练方法,具有如下有益效果:
81.第一、抽取图像上的文字信息作为图像的补充信息,进一步提高图文检索的准确率;
82.第二、在数据输入端添加简单的线性嵌入层和光学字符识别技术ocr,将数据处理成连续的特征向量,便于更好地利用学者网数据的特点;
83.第三、选用由海量大数据训练出来的预训练模型,对少量的学术多模态数据进行快速的数据分析,加强数据学习特征表达的能力;
84.第四、固定预训练模型的参数以解决下游学者网多模态数据量不足的问题,同时更好地利用已有模型;
85.第五,在训练过程中,自动学习一个非线性的模型迁移模块,该模块用来将上游学习到的知识更好地迁移到学者网的数据中;
86.第六、在预训练好的多模态模型后端添加多个非线性层,用于进一步从上游任务蒸馏相关的知识到下游任务中,更好地实现上游到下游的知识迁移。
87.第七、使用一个轻量级迁移模块将现有的预训练模型迁移到学者网多模态数据,解决模型数据与测试数据的差异性问题。
88.本发明实施例提供了一种学者网多模态检索模型的训练系统,所述学者网多模态检索模型包括数据适应模块、预训练模块和非线性迁移模块,所述系统包括:
89.爬取模块,用于爬取学者网的多个用户数据,所述用户数据包括图文数据和第一文本数据;
90.第一数据处理模块,用于将所述用户数据输入到所述数据适应模块,得到连续特征向量;
91.第二数据处理模块,用于将所述连续特征向量输入到所述预训练模块,得到高阶语义信息特征向量;
92.计算模块,用于将所述高阶语义信息特征向量输入到所述非线性迁移模块,计算所述图文数据和所述第一文本数据的预测相似度;
93.获取模块,用于获取所述图文数据和所述第一文本数据的真实相似度;
94.调节模块,用于根据所述预测相似度和所述真实相似度调节所述学者网多模态检索模型的参数。
95.本发明方法实施例的内容均适用于本系统实施例,本系统实施例所具体实现的功能与上述方法实施例相同,并且达到的有益效果与上述方法达到的有益效果也相同。
96.本发明实施例提供了一种学者网多模态检索模型的训练系统,包括:
97.至少一个存储器,用于存储程序;
98.至少一个处理器,用于加载所述程序以执行图1所示的学者网多模态检索模型的训练方法。
99.本发明方法实施例的内容均适用于本系统实施例,本系统实施例所具体实现的功能与上述方法实施例相同,并且达到的有益效果与上述方法达到的有益效果也相同。
100.本发明实施例提供了一种存储介质,其中存储有计算机可执行的程序,所述计算机可执行的程序被处理器执行时用于实现图1所示的学者网多模态检索模型的训练方法。
101.本发明实施例还提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存介质中。计算机设备的处理器可以从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行图1所示的学者网多模态检索模型的训练方法。
102.上面结合附图对本发明实施例作了详细说明,但是本发明不限于上述实施例,在所属技术领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。此外,在不冲突的情况下,本发明的实施例及实施例中的特征可以相互组合。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。