技术特征:
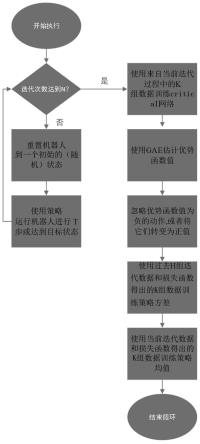
1.基于自适应近端优化的机器人动作方法,其特征在于,包括如下步骤,步骤s1.开始执行仿真训练任务,判断机器人数据迭代次数是否达到要求次数,若没有达到,则重置机器人到一个初始状态,使用策略运行机器人进行t步或达到目标状态,若达到,则使用来自当前迭代过程中的k组数据训练critical网络;步骤s2.使用gae估算优势函数值,忽视优势函数值为负的数据或将其转换为正值;步骤s3.使用过去h组迭代数据和损失函数获取k组数据训练策略方差;步骤s4.使用当前迭代数据和损失函数获取k组数据训练策略均值。2.根据权利要求1所述的基于自适应近端优化的机器人动作方法,其特征在于,仿真训练的服务项目为robocup 3d足球,其主体环境基于simspark生成,采用ode引擎在50hz的频率下运行,simspark环境中提供了以实体nao机器人为参照的仿真模型;该机器人拥有22个自由度,其中腿部关节拥有7个自由度,手部关节有4个,脖颈有2个;各关节所能达到的最大角速度为每20毫秒7.02度,由于仿真服务器的更新频率为50hz,在没有接受到agent发出的信号时默认其以前一个信号周期的状态运行,对于单个机器人,从自身改变参数并给服务器发出信号到接受到服务器返回的信号最快为40ms,即两个信号周期。3.根据权利要求1所述的基于自适应近端优化的机器人动作方法,其特征在于,策略为自适应近端策略,在时间t时,agent观测到状态矩阵s
t
并采取动作a
t
~π
θ
(a
t
|s
t
),其中π
θ
为策略,执行动作之后与环境的交互生成新的观测值s
t
并收到反馈r
t
,优化的最终目标为获取使累计奖励和达到最大数值的θ,其中γ为[0,1]中的任意数值,γ越低表示学习过程越偏向于速度,反之则允许较长时间的过程;ppo-cma在每一次的迭代过程中都生成出进程,收集“经验”[s
i
,a
i
,r
i
,s
i
]。在每一个迭代中,初始状态s0满足一个独立的稳定分布,逐步优化直到到达目标状态或是最大的进程长度。4.根据权利要求1所述的基于自适应近端优化的机器人动作方法,其特征在于,策略梯度采用gae,梯度ppo中策略梯度损失为其中,i为最小批采样索引,m为最小批采样大小,a
π
(s
i
,a
i
)为优势函数,用来估测在状态s
i
时采取的动作a
i
;正的a
π
表示动作优于平均水准;使用高斯策略处理连续动作空间,策略网络生成状态的均值μ
θ
(s)和协方差c
θ
(s)来采样动作,动作空间的分布符合正态分布即为将协方差矩阵简化为对角矩阵,则为设当前策略均值μ(s
i
)的优势函数为线性函数,则可以将优势函数值为负的动作镜像为正值的动作,则其中,为高斯核函数,给远离均值的动作分配更低的权值。
技术总结
一种基于自适应近端优化的机器人动作方法,包括如下步骤,步骤S1.开始执行仿真训练任务,判断机器人数据迭代次数是否达到要求次数,若没有达到,则重置机器人到一个初始状态,使用策略运行机器人进行T步或达到目标状态,若达到,则使用来自当前迭代过程中的k组数据训练critical网络;步骤S2.使用GAE估算优势函数值,忽视优势函数值中为负的数据或将其转换为正值;步骤S3.使用过去H组迭代数据和损失函数获取k组数据训练策略方差;步骤S4.使用当前迭代数据和损失函数获取k组数据训练策略均值。本方法在训练速度上的提升对于实际的动作训练帮助巨大。在执行三维连续动作的任务时稳定性明显优于其他方法。定性明显优于其他方法。定性明显优于其他方法。
技术研发人员:沈一鸥 梁志伟 高翔 付羽佳
受保护的技术使用者:南京邮电大学
技术研发日:2022.04.29
技术公布日:2022/8/16
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。