1.本发明属于计算机视觉和图像处理领域,特别是涉及一种基于深度残差傅里叶变换的图像盲去模糊方法。
背景技术:
2.在图像成像的过程中,有时图像的质量会受到各种因素的影响导致成像质量下降。图像去模糊旨在去除模糊伪影以恢复清晰图像。图像的模糊可能由许多因素引起,例如,不规则的摄像机或物体移动、离焦光学等。模糊图像导致视觉质量低下,并妨碍后续高级视觉任务,如安全、医学成像以及物体识别。
3.在过去的几十年里,为了探索准确有效的图像去模糊方法,已经做了大量的研究工作。基于核的方法试图在给定一个模糊图像的情况下,估计潜在的锐利图像和模糊算子。但与核相关的问题常常阻碍其在图像去模糊中的有效应用,如核估计方法对噪声敏感,以及对模糊模型特性存在各种约束,这些约束在实际场景中并不适用。
4.deepdeblur首先采用端到端的训练方法,直接通过卷积神经网络建立了模糊图像到清晰图像的映射。srn提出了一种编码器-解码器结构,以提升模型的效果。对抗训练也得到了广泛的研究。这些网络大多在图像的空间域上进行建模,以从模糊图像中恢复清晰图像。
5.在许多端到端的图像去模糊神经网络中,残差卷积模块(resblock)是一个被广泛使用的模块,残差卷积模块(resblock)的结构通常如图3(a)所示以将输入特征经过conv-relu-conv后与输入特征相加的形式出现。残差卷积模块(resblock)能够在训练时实现更深的结构、更大的感受野大小和更快的收敛速度。
6.各种研究都尝试过修改残差卷积模块(resblock),例如,saphn提出的内容识别处理模块(content-aware processing module)、mprnet提出的通道注意力模块(channel attention block)、hinet提出的半实例规范化模块(half instance normalization block)和sdwnet提出的空洞卷积模块(dilated convolution module)。然而,以上所有提到的方法都侧重于从空间域中提取信息,而忽略了频域中的重要差异。
7.通常情况下,卷积神经网络(cnn)易于从图像边缘或轮廓中捕捉基本的视觉特征,尤其是在较低的层中,而较深的层也会倾向于拟合这些特征而忽视了图像的低频信息。
技术实现要素:
8.为解决上述问题,本发明从图像频域的角度出发,提出了残差傅里叶卷积模块(res fft-conv block),通过同时获取空间域和频域的信息的方式达到对特征的高低频信息的利用。进一步,结合模糊图像恢复网络结构(mimo-unet)和涨点模块(do-conv)提出深度残差傅里叶变换(deeprft),有效地将模糊图像恢复为更加清晰的图像。
9.为实现上述目的,本发明提供了一种基于深度残差傅里叶变换的图像盲去模糊方法,包括以下步骤:
10.获取图像去模糊数据集,对所述图像去模糊数据集进行预处理,获得图像去模糊数据集的训练集;
11.基于所述训练集中的模糊图像、清晰图像,对初始深度残差傅里叶变换网络进行训练,获得目标深度残差傅里叶变换网络;
12.将待测模糊图像输入到所述目标深度残差傅里叶变换网络中进行图像盲去模糊处理,获得目标清晰图像。
13.优选地,所述图像去模糊数据集包括:gopro数据集、hide数据集、realblur数据集、dpdd数据集。
14.优选地,所述初始深度残差傅里叶变换网络,采用模糊图像恢复网络结构,包括:第一编解码器、第二编解码器、第三编解码器;所述第一编解码器对应所述模糊图像原始尺度,所述第二编解码器对应所述模糊图像降采样一次后的尺度,所述第三编解码器对应所述模糊图像降采样两次后的尺度。
15.优选地,所述第一编解码器、第二编解码器、第三编解码器包括:卷积模块、残差傅里叶卷积模块;所述残差傅里叶卷积模块,在原始的残差卷积模块的基础上增加了图像频域特征提取分支。
16.优选地,基于所述训练集中的模糊图像、清晰图像,对初始深度残差傅里叶变换网络进行训练的过程包括:
17.将所述模糊图像输入初始深度残差傅里叶变换网络中,获得输出图像;
18.基于所述输出图像与所述清晰图像间的差距,计算损失并进行梯度反转,对所述初始深度残差傅里叶变换网络的参数进行更新;
19.重复以上训练步骤,直至训练次数达到预先设定的数量,获得目标深度残差傅里叶变换网络。
20.优选地,将所述模糊图像输入初始深度残差傅里叶变换网络中,获得输出图像的过程包括:
21.将所述模糊图像、降采样一次模糊图像、降采样两次模糊图像,输入到所述初始深度残差傅里叶变换网络中,通过第一编解码器、第二编解码器、第三编解码器进行处理,获得对应的模糊特征预测尺度;
22.将所述模糊图像、降采样一次模糊图像、降采样两次模糊图像的尺度与所述对应的模糊特征预测尺度相加,获得第一输出图像、第二输出图像、第三输出图像。
23.优选地,基于所述输出图像与所述清晰图像间的差距,计算损失的过程包括,
24.所述训练集中的清晰图像与第一输出图像进行对比,获得第一差距;降采样一次清晰图像与第二输出图像进行对比,获得第二差距;降采样两次清晰图像与第三输出图像进行对比,获得第三差距;基于所述第一差距、第二差距、第三差距,计算得到损失。
25.本发明的技术效果为:
26.本发明提出一种基于深度残差傅里叶变换的图像盲去模糊方法,其中深度残差傅里叶变换网络包含残差傅里叶卷积模块,从图像频域的角度出发,通过同时获取空间域和频域的信息的方式达到对特征的高低频信息的利用。进一步,深度残差傅里叶变换网络结合了模糊图像恢复网络结构和深度过参数化卷积,有效地将模糊图像恢复为更加清晰的图像。
附图说明
27.构成本技术的一部分的附图用来提供对本技术的进一步理解,本技术的示意性实施例及其说明用于解释本技术,并不构成对本技术的不当限定。在附图中:
28.图1为本发明实施例中的流程示意图;
29.图2为本发明实施例中的深度残差傅里叶变换模型示意图;
30.图3为本发明实施例中的传统残差卷积模块和残差傅里叶卷积模块的对比图;
31.图4为本发明实施例中的清晰图像和模糊图像频域对比图;
32.图5为本发明实施例中的残差卷积模块和残差傅里叶卷积模块输出特征频域信息对比图;
33.图6为本发明实施例中的gopro测试数据示例图。
具体实施方式
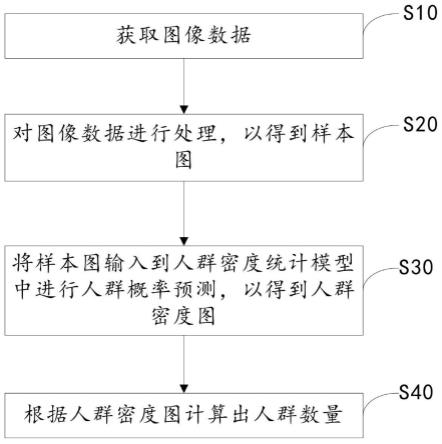
34.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
35.为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
36.实施例一
37.如图1示,本实施例中提供一种基于深度残差傅里叶变换的图像盲去模糊方法,包括两个阶段,分别为网络训练阶段和网络预测阶段。
38.网路的训练阶段包含以下步骤:
39.1.准备图像去模糊标准数据集,选取的图像去模糊数据集为:gopro数据集,hide数据集,realblur数据集和dpdd数据集;
40.2.对数据集进行预处理,在将实验数据输入模型训练之前先将数据随机切割为256
×
256大小并进行随机水平上下翻转;
41.3.将图像去模糊标准数据集的训练集中的模糊图像输入深度残差傅里叶变换(deep residual fourier transformation)中得到其估计出的可能清晰的图像。
42.4.计算网络输出图像与训练集中的清晰图像间的差距得到损失并返回梯度进行网络的参数更新,如此反复直至训练次数达到预先设定的数量。计算损失时,训练集中的清晰图像会分别降采样一次和两次后和深度残差傅里叶变换(deep residual fourier transformation)的三个不同尺度的输出图像同时计算得到损失。设与sk分别为网络第k个阶段输出的重建结果和真实清晰数据。网络训练的损失函数分别为以下三个损失函数的组合:
43.1)多尺度目标检测损失函数(msc loss):
44.45.2)多尺度边缘检测损失函数(msed loss):
[0046][0047]
3)多尺度频率重构损失函数(msfr loss):
[0048][0049]
最终的损失函数如下:
[0050]
l
·
=l
msc
αl
msed
βl
msfr
[0051]
其中δ表示图像拉普拉斯变换,α和β为超参数,分别设为0.05与0.01。
[0052]
网络的预测阶段:将模糊图像输入训练好的网络得到网络预测的清晰图像。
[0053]
参照图2,深度残差傅里叶变换(deep residual fourier transformation)采用的是模糊图像恢复网络结构(mimo-unet),包含三个不同尺度的编码器和解码器,分别对应图像原始尺度、图像降采样一次后的尺度、图像降采样两次后的尺度,编码器和解码器之间存在三个横向连接和四个跨尺度连接。实验数据首先进行降采样一次和两次分别后进入深度残差傅里叶变换(deep residual fourier transformation)的不同尺度的编码器,同时大尺度的编码器的输出会经过降采样后输入到小尺度的编码器。然后输入解码器,经过不同尺度的解码器得到模糊特征预测后与对应尺度的输入相加得到三个不同尺度的恢复图像。本发明通过改变编码器和解码器中包含的残差傅里叶卷积模块(res fft-conv block)个数,分别设计了三个模型deeprft-small、deeprft、和deeprft ,其中deeprft-small每个编码器和解码器包含4个残差傅里叶卷积模块(res fft-conv block),而deeprft和deeprft 继承了mimo-unet和mimo-unet 的设计,分别包含8个和20个。除此之外,本发明将网络结构中所有非1
×
1卷积替换为深度过参数化卷积(do-conv)。深度过参数化卷积(do-conv)在许多高级视觉任务如图像分类、语义分割和目标检测中显示了它的潜力。深度过参数化卷积(do-conv)通过对卷积层进行深度卷积提升训练参数,达到了加快训练收敛速度并能取得更好的训练效果。实验表明,添加深度过参数化卷积(do-conv)可以帮助收敛到一个更低的损失并取得更好的测试效果。同时,深度过参数化卷积(do-conv)是两个相邻的线性运算,在推理时可以组合成传统的卷积运算,因此并不会影响网络的测试速度。
[0054]
参照图3(b),残差傅里叶卷积模块(res fft-conv block)的频域分支处理过程如下:
[0055]
(1)计算z的2d实快速傅里叶变换,得到
[0056]
(2)提取的实部和虚部,将二者沿通道维度进行拼接得到的实部和虚部,将二者沿通道维度进行拼接得到
⊙c表示沿通道维度拼接;
[0057]
(3)将经过1
×
1conv-relu-1
×
1conv得到f;
[0058]
(4)将f=f
real
⊙cf
imag
通过反快速傅里叶变换还原为空间域得到最终输出y
fft
,即
[0059]
通过上述操作,本发明对所有频率的信息和相关性完成了建模。然后傅里叶变换卷积模块(res fft-conv block)的最终输出通过y=y
fft
y
res
z计算得到,其中y
res
使用与原始resblock相同的计算。
[0060]
参照图4,清晰的图像相比于其对应的模糊图像,通常包含更少的低频信息和更多的高频信息。
[0061]
参照图5,本发明提取出了深度残差傅里叶变换(deeprft)的最后一层残差傅里叶卷积模块(res fft-conv block)中残差卷积分支和傅里叶分支输出特征的傅里叶变换后的平均幅值(图5b),将其与经过同样操作后得到的模糊图像恢复网络结构(mimo-unet)最后一层残差模块中的卷积分支输出特征的傅里叶变换后的平均幅值(图5a)进行比较。可以明显看出引入傅里叶变换分支后能够很好地提升网络对低频信息的捕获能力。
[0062]
参照图6,左图为原始模糊图像,小图从左上到右下是分别是模糊图像,dmphn、mimo-unet 、hinet、mprnet、deeprft、deeprft 结果和清晰图像。通过mimo-unet 的结果与深度残差傅里叶变换(deeprft)的对比,可以说明本发明能够有效地提升卷积神经网络的去模糊能力,相比于目前主流的去模糊神经网络,深度残差傅里叶变换(deeprft)有着更优的去模糊能力。
[0063]
本发明的主要特点在于残差傅里叶卷积模块(res fft-conv block)的设计。图像去模糊任务需要在图像处理过程中获取较大的感受野,然而目前主流的获取大感受野的方法如transformer与non-local等存在着诸如难以训练、显存消耗巨大等问题,而且目前主流深度神经网络所聚焦的的仍为图像的空间信息,图像的频域信息是目前图像去模糊神经网络所忽视的。残差傅里叶卷积模块(res fft-conv block)成功将特征的频域信息融入了卷积神经网路,增加了模型对于频域信息的获取与处理,提升了模型的性能。
[0064]
以上所述,仅为本技术较佳的具体实施方式,但本技术的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本技术的保护范围之内。因此,本技术的保护范围应该以权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。