一种基于padua量表的自然语言处理自动打表方法
技术领域
1.本发明提供一种基于padua量表的自然语言处理自动打表方法,自然语言处理和医疗信息技术领域。
背景技术:
2.随着时代的发展,自然语言处理(nlp)在医疗信息领域,有巨大的研究前景。医疗文本包含了大量丰富的医疗信息(诊断报告、影像报告等),是进行疾病预测、个性化信息推荐、临床决策支持等的重要文本资源。
3.从需求角度看,静脉血栓栓塞症(vte)是深静脉血栓形成和肺栓塞的统称,研究报道全球范围内每年发生vte约1 000万例,几乎每千人中就有1人或2 人发生静脉血栓形成。vte已成为继缺血性心脏病和脑卒中后的第三大心血管疾病死亡原因,是全球非传染性疾病的重大负担。所以在临床上对静脉血栓的预防成为医生的一项重点工作。
4.然而,在临床上多数情况下依旧使用人工判断的方法对患者vte进行打表评分,是对人力成本的一项巨大消耗。并且,如果患者因为与血栓无关的问题入院,医生可能会忽略以往的一些问题而使得既往的血栓情况被遗忘和淹没。
技术实现要素:
5.鉴于现有技术中的上述缺陷或不足,本发明提供了一种基于padua量表的自然语言处理自动打表方法,解决中文条件下的活动性癌症、既往vte病史、心衰和或呼吸衰竭、急性心肌梗死或缺血性脑卒中、急性感染和或风湿性疾病表项的自动padua评估问题。
6.本发明的技术方案是:一种基于padua量表的自然语言处理自动打表方法,所述方法包括:
7.包括如下:
8.step1、获取icd-10国际诊断分类中padua量表所对应诊断语言内容,对所诉诊断内容进行预处理,得到数据处理后的诊断类别数据;
9.step2、对step1中得到的类别数据进行数据预处理,构建自然语言处理模型,使用诊断类别数据分别训练判断“既往史”的二分类模型和判断“病程记录”的五分类模型;
10.step3、获取医院电子病例中的既往病史和病程记录中的初步诊断以及补充诊断,对病史和诊断进行预处理;
11.step4、将处理好既往病史和病程记录中的诊断信息输入预构建的自然语言处理模型,得到基于病人病例的padua量表智能评估结果。
12.作为本发明的进一步方案,所述step1的具体步骤如下:
13.step1.1.针对padua量表中的“活动性恶性肿瘤,患者先前有局部或远端转移和(或)6个月内接受过化疗和放疗”,“既往静脉血栓栓塞症”,“心脏和(或)呼吸衰竭”,“急性心肌梗死和(或)缺血性脑卒中”,“急性感染和 (或)风湿性疾病”五个类别进行归类整理,得到对应类别的诊断的正样本数据集合。
14.step1.2.选取正样本中的10%把“待查”、“?”、“未定”等经常出现的诊断语句随机融入到正样本中作为负样本第一部分;
15.step1.3.把icd-10中与正样本明显对立的医学诊断构成负样本第二部分;
16.step1.4.把非正样本非负样本一和二的icd-10医学诊断随机选择60%作为负样本三。
17.作为本发明的进一步方案,所述step2的具体步骤如下:
18.step2.1、对step1中得到的数据进行数据预处理,数据预处理包括拆分训练模型数据和数据映射;
19.step2.2.构建用于判断padua类别的模型结构,首先将处理好的icd-10数据作为albert层的输入,而后将albert模型作为embedding输入到bilstm层提取每一个字符特征,随后将第一个bilstm层的输出输入到第二个bilstm层。取第二个bilstm层最后一个细胞状态c
t
作为一整个诊断信息输入到最后的分类层次;
20.step2.3.使用判断“既往史”的二分类模型和判断“病程记录”的五分类模型分别对是否“既往静脉血栓栓塞症”和是否“活动性恶性肿瘤,患者先前有局部或远端转移和/或6个月内接受过化疗和放疗”,“心脏和/或呼吸衰竭”,“急性心肌梗死和/或缺血性脑卒中”,“急性感染和/或风湿性疾病”进行训练,二分类模型和五分类模型分别使用focal loss和交叉熵损失。
21.作为本发明的进一步方案,所述step3包括:
22.step3.1.使用正则表达式提取电子病例中的既往病史中的诊断信息作为既往史list;
23.step3.2.使用正则表达式提取病程记录中的初步诊断以及补充诊断中的诊断信息作为病程记录list。
24.作为本发明的进一步方案,所述step4包括把诊断文本预处理、基于既往史的诊断识别和基于病程记录初步诊断和补充诊断识别,具体步骤如下:
25.step4.1.把step3中得到的既往史list和病程记录list通过步骤step2.1中数据映射的方法进行数据预处理,从而得到处理好的既往史list和病程记录list;
26.step4.2.使用step2中训练出的判断“既往史”的二分类模型和判断“病程记录”的五分类模型;
27.step4.3.把步骤step4.1中得到的既往史list和病程记录list分别输入到 step4.2中的二分类模型和五分类模型对每个诊断进行逐个判别;
28.step4.4.把步骤step4.3中得到的判别结果进行去重统计,最终得到padua量表的打分结果;
29.step4.5.将step4.1到step4.4进行封装可以提供接口为外部提供服务。
30.本发明的有益效果是:本发明引入自然语言处理技术,能根据padua量表针对电子病例中的既往史和病程记录进行智能评估。可以有效减少临床医生在评估病人vte风险方面的工作量。
附图说明
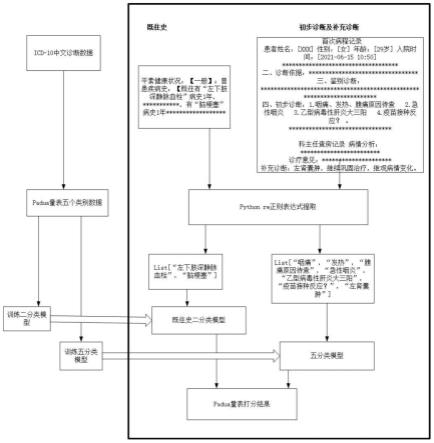
31.图1是本发明公开的基于padua量表的自然语言处理自动打表方法流程图;
32.图2是本发明公开的模型结构图;
33.图3是发明公开的padua量表的自然语言处理自动打表模型的训练和预测流程图;
34.图4是本发明公开的padua量表接口调用展示示意图。
具体实施方式
35.为了进一步了解本发明的结构、特征及其目的,现结合所附图说明如下,附图所说明的实施仅用于说明本发明的技术方案,并非限定本发明。
36.实施例1,如图1-图4所示,提供一种基于padua量表的自然语言处理自动打表方法,所述方法包括:
37.step1:获取icd-10国际诊断分类中padua量表所对应诊断语言内容,对所诉诊断内容进行预处理,得到数据处理后的诊断类别数据,最终得到的数据数量如表1。具体实施步骤如下:
38.表1训练集各padua量表项数据
[0039][0040]
step1.1.针对padua量表中的“活动性恶性肿瘤,患者先前有局部或远端转移和(或)6个月内接受过化疗和放疗”,“既往静脉血栓栓塞症”,“心脏和 (或)呼吸衰竭”,“急性心肌梗死和(或)缺血性脑卒中”,“急性感染和(或) 风湿性疾病”五个类别进行归类整理,得到对应类别的诊断的数据集合;
[0041]
step1.2.选取正样本中的10%把“待查”、“?”、“未定”等经常出现的诊断语句随机融入到正样本中作为负样本第一部分。
[0042]
step1.3.把icd-10中与正样本明显对立的医学诊断构成负样本第二部分。
[0043]
step1.4.把非正样本非负样本二的icd-10医学诊断随机选择60%作为负样本三。
[0044]
step2.如图1所示,将诊断类别及诊断文本输入构建的自然语言处理模型,训练自然处理模型,包含基于step1中整理的icd-10数据训练“既往史”二分类模型和“病程记录”五分类模型。具体实施步骤如下:
[0045]
step2.1对step1中得到的数据进行数据预处理,数据预处理包括拆分训练模型数据和数据映射。
[0046]
拆分训练模型数据:把准备好的数据按照训练二分类模型的既往静脉血栓数据和训练五分类的其他数据分成两份。二分类模型的负样本三按照负样本三中的随机300份。而
五分类模型使用全体负样本三。将处理后的数据按照8:2的比例拆分成训练集和测试集。使用训练集数据训练albert bilstm模型。
[0047]
数据映射:首先将输入序列调整到指定尺寸。将诊断字符数量小于25的补 0作为填充,大于25的截取前23个字符。把医疗诊断分别都映射成文本词库的对应数字并在首尾位置分别加上[cls]和[sep]代表开始和结束。
[0048]
例如:将“左下肢深静脉血栓”处理为[1,1,1,1,1,1,1,1, 1,1,1,1,1,1,1,102,2340,678,5501,3918,7474,5549,6117,3410, 103]。其中102和103分别代表[cls]和[sep]的映射位置。
[0049]
其次映射出诊断整体句子位置信息。
[0050]
例如:将“左下肢深静脉血栓”处理为 [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]。因为“左下肢深静脉血栓”只有一句话。所以0代表这个诊断句子同属于第一句话。
[0051]
最后由于第一步的映射,模型api能够读出语句字位置的映射。
[0052]
step2.2.构建用于判断padua类别的模型结构,albert bilstm模型结构如图2所示。首先将处理好的icd-10数据作为文本向量化albert层的输入,而后将albert模型作为embedding输入到特征提取层中的第一个bilstm层提取每一个字符特征,随后将第一个bilstm层的输出输入到第二个bilstm层。取第二个bilstm层最后一个细胞状态c
t
作为一整个诊断信息输入到最后的分类层次。训练过程使用adam作为优化器,学习率设为0.00001。
[0053]
step2.3.使用判断“既往史”的二分类模型和判断“病程记录”的五分类模型分别对是否“既往静脉血栓栓塞症”和是否“活动性恶性肿瘤,患者先前有局部或远端转移和(或)6个月内接受过化疗和放疗”,“心脏和(或)呼吸衰竭”,“急性心肌梗死和(或)缺血性脑卒中”,“急性感染和(或)风湿性疾病”进行训练。二分类模型和五分类模型分别使用focal loss和交叉熵损失。
[0054]
step3.获取医院电子病例中的既往病史和病程记录中的初步诊断以及补充诊断,对所诉病史和诊断进行预处理。
[0055]
step3.1.使用正则表达式提取电子病例中的既往病史中的诊断信息。具体地,如图1,将半结构化的既往史病例。使用python中的re正则表达式api提取成 list。
[0056]
例如:“平素健康状况:【一般】;曾患疾病史:【既往有“左下肢深静脉血栓”病史1年,***********,有“脑梗塞”病史1年******************”使用python中的re正则表达式api提取成list[“左下肢深静脉血栓”,“脑梗塞”]。其中“*”代表省略的电子病例。
[0057]
step3.2.使用正则表达式提取病程记录中的初步诊断以及补充诊断中的诊断信息。具体地,如图1,将半结构化的电子病例病程记录信息使用python中的 re正则表达式api提取成list
[0058]
例如:“四、初步诊断:1.咽痛、发热、腹痛原因待查2.急性咽炎3. 乙型病毒性肝炎大三阳4.疫苗接种反应?。 *******************************科主任查房记录病情分析: ************************诊疗意见:*********************补充诊断:左肾囊肿,继续巩固治疗,继观病情变化。”提取成list[“咽痛”,“发热”,“腹痛原因待查”,“急性咽炎”,“乙型病毒性肝炎大三阳”,“疫苗接种反应?”,“左肾囊肿”]。其中“*”代表省略的电子病例。
[0059]
step4.将处理好既往病史和病程记录中的诊断信息输入预构建的自然语言处理
模型,得到基于病人病例的padua量表智能评估结果。具体实施步骤如下:
[0060]
为了实现对真实病例数据的padua量表的评估,本发明step4设计了一套评估流程,具体如图3所示,评估流程按照下面步骤进行:
[0061]
step4.1.把step3中得到的既往史list和病程记录list通过步骤step2.1中数据映射的方法进行数据预处理。从而得到处理好的既往史list和病程记录list。
[0062]
step4.2.使用step2中训练出的判断“既往史”的二分类模型和判断“病程记录”的五分类模型。
[0063]
step4.3.把步骤step4.1中得到的既往史list和病程记录list分别输入到 step4.2中的二分类模型和五分类模型对每个诊断进行逐个判别。
[0064]
step4.4.把步骤step4.3中得到的判别结果进行去重统计,最终得到padua量表的打分结果。
[0065]
step4.5.将step4.1到step4.4进行封装可以提供接口为外部提供服务,效果如图4所示。为了保护病人隐私,图中部分信息使用“*”替代。经由电子病历中“既往史”和“病程记录”作为输入,最终得到了这位病人关于padua量表需要打分的项。
[0066]
本发明公开了一种基于padua量表的自然语言处理自动打表方法,适用于医院电子病例基于padua量表自动评估病人vte风险。首先使用深度学习方法结合 icd-10为训练集训练模型。然后使用训练好的二分类模型和五分类模型针对电子病例中的“既往史”,与“病程记录”中的诊断文本信息判断病人的vte风险。
[0067]
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。