一种用于深度学习任务的gpu资源分配方法
技术领域
1.本发明涉及容器云平台技术领域,具体来说涉及一种gpu资源分配方法,更具体地说,涉及一种用于深度学习任务的gpu资源分配方法。
背景技术:
2.随着人工智能、深度学习技术的迅速发展,传统cpu(图形处理器,graphics processing unit))的计算资源已难以满足深度学习应用负载的算力需求。gpu因具有更强的计算资源和较高的访存带宽,成为了深度学习应用的主流加速器。gpu集群中的一个关键问题就是如何调度多个深度学习应用任务,来实现最优的系统性能。当前,伴随着云计算技术的迅速发展,基于docker容器化的云平台成为了运行深度学习应用的主要基础设施平台之一。kubernetes作为容器集群调度系统及资源管理平台,可以集中管理集群中的cpu、内存以及网络等资源,也支持通过设备插件框架添加包括gpu在内的其他异构硬件资源。在nvidia实现的gpu调度管理插件中,kubernetes可以管理gpu资源,但只能将一块gpu分配给一个容器组,无法在多个容器组中共享资源。
3.为解决上述技术问题,现目前多基于虚拟统一计算设备架构(virtual compute unified device architecture,vcuda)来现gpu资源在任务间的共享,即:vcuda通过对gpu资源进行细粒度的切割,让用户指定gpu使用份额,以限制容器组对单个gpu的使用,从而实现多个容器组共享同一gpu资源。但在任务调度上,由于vcuda采用简单的binpack方法,忽略了任务本身的特征,因此容易造成资源过度分配,使得gpu资源无法得到充分利用的问题。
技术实现要素:
4.因此,本发明的目的在于克服上述现有技术的缺陷,提供一种用于深度学习任务的gpu资源分配方法。
5.本发明的目的是通过以下技术方案实现的:
6.根据本发明的第一方面,提供一种用于深度学习任务的gpu资源分配方法,应用于多租户容器云平台的资源调度系统,所述资源调度系统包括一个控制节点及多个工作节点,所述方法包括在控制节点执行如下步骤:
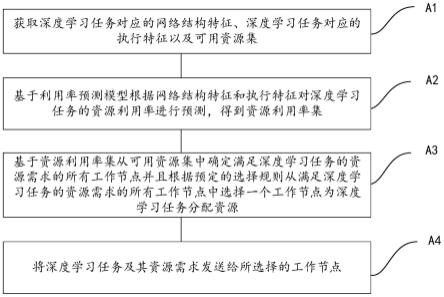
7.获取深度学习任务对应的网络结构特征、深度学习任务对应的执行特征以及可用资源集,所述可用资源集包括多个工作节点中指定算力gpu的剩余资源;
8.基于利用率预测模型根据所述网络结构特征和所述执行特征对所述深度学习任务的资源利用率进行预测,得到资源利用率集,所述资源利用率集包括所述深度学习任务在多种指定算力gpu上的资源利用率;
9.基于所述资源利用率集从所述可用资源集中确定满足所述深度学习任务的资源需求的所有工作节点并且根据预定的选择规则从满足所述深度学习任务的资源需求的所有工作节点中选择一个工作节点为所述深度学习任务分配资源;
10.将所述深度学习任务及其资源需求发送给所选择的工作节点,所述资源需求指示所述深度学习任务在多种指定算力gpu上的资源利用率。
11.在本发明的一些实施例中,预定的选择规则是从满足所述深度学习任务的资源需求的所有工作节点中选择具有最多的gpu剩余资源的工作节点为所述深度学习任务分配资源。
12.在本发明的一些实施例中,所述利用率预测模型按照以下方式训练得到:
13.获取第一训练样本集,其包括多个训练样本,每个训练样本包括指定算力gpu对应的硬件特征、深度学习任务对应的网络结构特征、深度学习任务对应的执行特征以及标签,所述标签包括对训练样本中深度学习任务在该指定算力gpu上的资源利用率的指示;
14.利用所述第一训练样本集训练所述利用率预测模型输出资源利用率集,根据输出的资源利用率集和对应标签计算的损失值更新所述利用率预测模型的参数。
15.在本发明的一些实施例中,所述深度学习任务对应的网络结构特征包括其中各种图节点对应的输入数据大小,当所述网络计算图特征中存在重复的计算图节点时,从重复的计算图节点中选取具有最大的输入数据大小的计算图节点作为训练样本中所述重复的计算图节点对应的输入数据大小。
16.在本发明的一些实施例中,所述执行特征包括批次大小、迭代次数、输入大小或者其组合。
17.在本发明的一些实施例中,所述方法还包括:
18.在当前所有的工作节点均不能满足所述深度学习任务的资源需求且所述深度学习任务为延时敏感任务时,判断是否存在可释放资源且可释放资源不少于分配给所述深度学习任务资源的工作节点,
19.若是,释放所述可释放资源并将所述深度学习任务分配给该工作节点;
20.若否,将所述深度学习任务存放至延时敏感任务等待队列,所述可释放资源为分配给非延时敏感任务的资源。
21.在本发明的一些实施例中,所述方法还包括:
22.在当前所有的工作节点均不能满足所述深度学习任务的资源需求且所述深度学习任务为非延时敏感任务时,将所述深度学习任务存放至非延时敏感任务等待队列。
23.在本发明的一些实施例中,所述方法还包括:
24.基于执行时间预测模型根据所述深度学习任务对应的网络结构特征、所述深度学习任务对应的执行特征、所述深度学习任务在指定算力gpu上对应的资源利用率以及指定算力gpu对应的硬件特征对所述深度学习任务在指定算力gpu上的执行时间进行预测,得到用于检测非延时敏感任务的执行情况是否满足预设服务质量的预测执行时间集,并将所述预测执行时间集传输至为所述深度学习任务分配资源的工作节点,所述预测执行时间集包括所述深度学习任务在多种指定算力gpu上的预测执行时间。
25.在本发明的一些实施例中,所述执行时间预测模型按照以下方式训练得到:
26.获取第二训练样本集;其包括多个训练样本,每个训练样本包括指定算力gpu对应的硬件特征、深度学习任务对应的网络结构特征、深度学习任务对应的执行特征、深度学习任务在指定算力gpu上对应的资源利用率以及标签,所述标签包括对训练样本中深度学习任务在该指定算力gpu上的执行时间的指示;
27.利用所述第二训练样本集训练所述执行时间预测模型输出预测执行时间,根据输出的预测执行时间和对应标签计算的损失值更新所述执行时间预测模型的参数。
28.根据本发明第二方面,提供一种用于深度学习任务的gpu资源分配方法,应用于多租户容器云平台的资源调度系统,所述资源调度系统包括一个控制节点及多个工作节点,每个工作节点包括多个gpu,所述方法包括在每个工作节点执行如下步骤:
29.接收控制节点按照第一方面的方法发送给当前工作节点的深度学习任务及其资源需求,所述资源需求指示所述深度学习任务在多种指定算力gpu上的资源利用率;
30.基于当前工作节点中多个gpu的剩余资源和所述资源需求为所述深度学习任务分配gpu及对应的gpu资源。
31.在本发明的一些实施例中,当所述深度学习任务为延时敏感任务时,将所述深度学习任务分配至具有最多剩余资源的gpu中。
32.在本发明的一些实施例中,当所述深度学习任务为非延时敏感任务时,将所述深度学习任务分配至具有最短执行时间的gpu中,其中,执行时间基于执行时间预测模型根据所述深度学习任务对应的网络结构特征、所述深度学习任务在指定算力gpu上对应的资源利用率以及指定算力gpu对应的硬件特征进行预测。
33.在本发明的一些实施例中,所述方法还包括:
34.当所述深度学习任务为延时敏感任务时,从控制节点发送的预测执行时间集中获取所述深度学习任务在当前gpu上的预测执行时间,基于所述预测执行时间监控所述深度学习任务的执行情况是否满足预设服务质量。
35.在本发明的一些实施例中,所述监控所述深度学习任务的执行情况是否满足预设服务质量包括:
36.获取所述深度学习任务的已执行时间以及执行进度;
37.根据所述执行进度更新所述深度学习任务对应的执行特征以及网络结构特征;
38.基于所述执行时间预测模型根据所述深度学习任务在指定算力gpu上对应的资源利用率、指定算力gpu对应的硬件特征、更新后的执行特征以及网络结构特征预测所述深度学习任务的剩余执行时间;
39.在所述已执行时间和所述剩余执行时间之和大于预设执行时间时,判断所述延时敏感任务的执行情况未满足所述预设服务质量。
40.在本发明的一些实施例中,在监控到所述深度学习任务的执行情况未满足预设服务质量时,增加当前gpu分配给所述深度学习任务的gpu资源;若在增加分配给所述深度学习任务的资源时出现gpu资源不足,减少对当前gpu上的非延时敏感任务的资源分配;若增加分配给所述深度学习任务的gpu资源后,出现非延时敏感任务的执行资源不足,保存所述非延时敏感任务的执行状态并结束所述非延时敏感任务的执行。
41.在本发明的一些实施例中,所述方法还包括:
42.在监控到所述深度学习任务的执行情况满足预设服务质量时,查询所述深度学习任务在当前gpu上的资源利用率,若所述资源利用率超过所述控制节点发送的所述深度学习任务在当前gpu上的预测资源利用率时,暂停所述深度学习任务在当前gpu上的执行,待所述资源利用率下降至所述预测资源利用率时,重新在当前gpu上执行所述深度学习任务。
43.根据本发明第三方面,提供一种支持gpu共享的资源调度系统,包括:
44.控制节点,被配置为按照第一方面的方法向工作节点传输深度学习任务及其资源需求,所述资源需求指示所述深度学习任务在多种指定算力gpu上的资源利用率;
45.多个工作节点,每个工作节点被配置为按照第二方面的方法为所述深度学习任务分配gpu及对应的gpu资源。
46.在本发明的一些实施例中,所述控制节点包括:
47.第一预测单元,用于基于利用率预测模型根据所述网络结构特征和所述执行特征对所述深度学习任务的资源利用率进行预测,得到资源利用率集,所述资源利用率集包括所述深度学习任务在多种指定算力gpu上的资源利用率;
48.第一调度单元,用于基于所述资源利用率集从所述可用资源集中确定满足所述深度学习任务的资源需求的所有工作节点并且根据预定的选择规则从满足所述深度学习任务的资源需求的所有工作节点中选择一个工作节点为所述深度学习任务分配资源,并将所述深度学习任务及其资源需求发送给所选择的工作节点,所述资源需求指示所述深度学习任务在多种指定算力gpu上的资源利用率。
49.在本发明的一些实施例中,所述控制节点还包括:
50.延时敏感任务等待队列,用于在当前所有的工作节点均不能满足延时敏感任务的资源需求时存放所述延时敏感任务;
51.非延时敏感任务等待队列,用于当前所有的工作节点均不能满足非延时敏感任务的资源需求时存放所述非延时敏感任务;
52.其中,在延时敏感任务等待队列不为空时,优先为敏感任务等待队列中的延时敏感任务分配gpu资源。
53.在本发明的一些实施例中,所述第一预测单元还用于基于执行时间预测模型根据所述深度学习任务对应的网络结构特征、所述深度学习任务对应的执行特征、所述深度学习任务在指定算力gpu上对应的资源利用率以及指定算力gpu对应的硬件特征对所述深度学习任务在指定算力gpu上的执行时间进行预测,得到用于检测非延时敏感任务的执行情况是否满足预设服务质量的预测执行时间集。
54.在本发明的一些实施例中,所述工作节点包括:
55.拓扑感知单元,用于获取当前工作节点中多个gpu的剩余资源;
56.第二预测单元,用于基于执行时间预测模型根据非延时敏感任务对应的网络结构特征、非延时敏感任务对应的执行特征、非延时敏感任务在指定算力gpu上对应的资源利用率以及指定算力gpu对应的硬件特征对非延时敏感任务在指定算力gpu上的执行时间进行预测,得到非延时敏感任务在多种指定算力gpu上的执行时间;
57.第二调度单元,用于基于当前工作节点中多个gpu的剩余资源和所述资源需求为所述深度学习任务分配gpu及对应的gpu资源;还用于根据非延时敏感任务在多种指定算力gpu上的执行时间为所述非延时敏感任务分配具有最短执行时间的gpu。
58.在本发明的一些实施例中,所述工作节点还包括:
59.弹性调整单元,用于监控延时敏感任务的执行情况是否满足预设服务质量,并在延时敏感任务的执行情况未满足预设服务质量时,增加当前gpu分配给所述深度学习任务的gpu资源;若在增加分配给所述深度学习任务的资源时出现gpu资源不足,减少对当前gpu上的非延时敏感任务的资源分配;若增加分配给所述深度学习任务的gpu资源后,出现非延
时敏感任务的执行资源不足,保存所述非延时敏感任务的执行状态并结束所述非延时敏感任务的执行;
60.资源限制单元,用于在延时敏感任务的执行情况满足预设服务质量时,查询延时敏感任务在当前gpu上的资源利用率,若所述延时敏感任务在当前gpu上的资源利用率超过所述控制节点发送的所述延时敏感任务在当前gpu上的预测资源利用率时,暂停所述延时敏感任务在当前gpu上的执行,待所述资源利用率下降至所述预测资源利用率时,重新在当前gpu上执行所述延时敏感任务。
61.与现有技术相比,本发明的优点在于:
62.通过对深度学习任务的资源需求量进行预测,根据预测的资源需求量来对容器云集群中的gpu资源进行合理分配,从而实现容器云集群中的gpu资源共享以及提升容器云集群中的gpu利用率。
附图说明
63.以下参照附图对本发明实施例作进一步说明,其中:
64.图1为根据本发明实施例的一种用于深度学习任务的gpu资源分配方法在控制节点上实施的流程示意图;
65.图2为根据本发明实施例的深度学习任务的网络结构的dag图;
66.图3为根据本发明实施例的一种用于深度学习任务的gpu资源分配方法在工作节点上实施的流程示意图;
67.图4为根据本发明实施例的一种基于kubernetes平台的资源调度系统的示意图。
具体实施方式
68.为了使本发明的目的,技术方案及优点更加清楚明白,以下结合附图通过具体实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
69.如在背景技术部分提到的,为了实现在多个容器组中共享gpu资源,现目前提出了基于虚拟统一计算设备架构(virtual compute unified device architecture,vcuda)来现gpu资源在任务间的共享,但由于在任务调度上,vcuda采用简单的binpack方法,忽略了任务本身的特征,因此存在资源过度分配,使得gpu资源无法得到充分利用的问题。为解决上述技术问题,本技术实施例提供了一种用于深度学习任务的gpu资源分配方法,通过对深度学习任务的资源需求量进行预测,以根据预测的资源需求量来对容器云集群中的gpu资源进行合理分配,从而实现容器云集群中的gpu资源共享及提升容器云集群中的gpu利用率。
70.为了实现本发明,发明人对应用于kubernetes容器云平台中的资源调度系统的控制节点和工作节点分别进行了相应的改进,下面分别从(一)控制节点的改进、(二)工作节点的改进和(三)资源调度系统这三个方面进行说明。
71.(一)控制节点的改进
72.根据本发明的一个实施例,本发明提供一种用于深度学习任务的gpu资源分配方法,应用于多租户容器云平台的资源调度系统,其中,资源调度系统包括一个控制节点及多
个工作节点,方法包括在控制节点执行如图1所示的步骤a1、步骤a2、步骤a3以及步骤a4。为了更好地理解本发明,下面结合具体的实施例针对每一个步骤分别进行详细说明。
73.步骤a1:获取深度学习任务对应的网络结构特征、深度学习任务对应的执行特征以及可用资源集;
74.其中,深度学习任务对应的网络结构特征包括各种计算图节点以及各种计算图节点对应的输入数据大小(计算图节点的输入数据的个数),计算图节点至少包括加运算(addv2)、偏移加运算(biasadd)、梯度偏移加(biasaddgrad)、乘运算(mul)、二维卷积运算(conv2d)、合并数组运算(concat)、归一化指数函数(softmax)、线性整流函数(relu)、最大池化运算(maxpool)、平均池化运算(avgpool)或者其组合。由于每个深度学习任务不同,因此每个深度学习任务所涵盖的计算图节点以及对应的输入数据大小也不相同,为使得利用率预测模型能根据不同深度学习任务的网络结构特征都进行对应的资源预测,根据本发明的一个实施例,预先根据计算图节点构建一个网络结构特征表,然后在后续获取深度学习任务对应的网络结构特征时,将获取的输入数据大小填入网络结构特征表中对应的计算图节点即可,例如:预设的网络结构特征表为:{addv2(0),conv2d(0),maxpool(0),relu(0),matmul(0),avgpool(0),mul(0),concat(0),softmax(0)},其中,括号前的内容为计算图节点的名称,括号中的内容是计算图节点的输入数据大小。若深度学习任务a包括的图节点有addv2、conv2d、maxpool、matmul以及softmax,且各个计算图节点对应的输入数据大小分别为:2000、4800、3200、4200、100,则将输入数据大小填入对应的计算图节点即可得到深度学习任务a的网络结构特征:{addv2(2000),conv2d(4800),maxpool(3200),relu(0),matmul(4200),avgpool(0),mul(0),concat(0),softmax(100)};进一步地,考虑到在重复的计算图节点中对利用率预测影响较大的为具有最大输入数据大小的那个重复节点,因此当一个深度学习任务中出现了重复的计算图节点时,将重复的计算图节点中的最大的输入数据大小填入网络结构特征表中对应的计算图节点。例如:深度学习任务b包括3个重复的计算图节点conv2d,输入数据大小分别为2400、2800、4800;其余的计算图节点为:addv2、maxpool、relu以及concat,输入数据大小分别为2400、4800、1000、100,由于计算图节点conv2d中的最大输入数据大小为4800,因此将4800填入网络结构特征表中的conv2d处,则深度学习任务b对应的网络结构特征为:{addv2(2400),conv2d(4800),maxpool(4800),relu(1000),matmul(0),avgpool(0),mul(0),concat(100),softmax(100)}。
75.执行特征包括批次大小、迭代次数、输入大小或者其组合,由于每个深度学习任务不同,因此批次大小、迭代次数以及输入大小所对应的数据也不相同,为使得利用率预测模型能根据不同深度学习任务的执行特征都进行对应的资源预测,根据本发明的一个实施例,预先根据执行特征构建一个执行特征表,在后续获取深度学习任务对应的执行特征时,将获取的数据填入执行特征表中对应的计算图节点即可,例如:预设的执行特征表为:{batchsize(0),iteration(0),input(0)},其中,括号前的内容分别为批次大小、迭代次数和输入大小,括号中的内容是对应的参数。若深度学习任务a的批次大小、迭代次数和输入大小的参数分别为32、2000以及1000,则深度学习任务a的执行特征表示为:{batchsize(32),iteration(2000),input(1000)}。
76.根据本发明的一个实施例,考虑到资源调度系统中具有多个工作节点,每个工作节点中拥有多个gpu,gpu会因其规格参数的不同导致其具备不同的算力,因此为便于后续
为深度学习任务分配合适的gpu资源,在获取可用资源集时,除了统计工作节点中各个gpu具有的剩余资源,还需要统计各个gpu对应的算力,即在本技术实施例中,可用资源集包括多个工作节点中指定算力gpu的剩余资源。
77.步骤a2:基于利用率预测模型根据网络结构特征和执行特征对深度学习任务的资源利用率进行预测,得到资源利用率集;根据本发明的一个实施例,考虑到gpu的算力存在差异性,相同的深度学习任务在不同算力的gpu上的资源利用率是不一致的,因此,为合理的为深度学习任务分配相应的gpu资源,需对深度学习任务在所有算力的gpu上都进行预测,得到深度学习任务在所有算力gpu上的资源利用率,即在本技术实施例中,资源利用率集包括深度学习任务在多种指定算力gpu上的资源利用率。
78.根据本发明的一个实施例,利用率预测模型包括gpu计算资源利用率预测模型和存储资源使用率预测模型,其中,gpu计算资源利用率预测模型用于预测深度学习任务在多种指定算力gpu上的计算资源利用率,以便gpu为其分配相应的计算资源;存储资源使用率预测模型用于预测深度学习任务在多种指定算力gpu上的存储资源利用率,以便gpu为其分配相应的存储资源。根据本发明的一个实施例,gpu计算资源利用率预测模型和存储资源使用率预测模型除了标签不相同(gpu计算资源利用率预测模型的标签为:对训练样本中深度学习任务在该指定算力gpu上的计算资源利用率的指示;存储资源使用率预测模型的标签为:对训练样本中深度学习任务在该指定算力gpu上的存储资源利用率的指示),其余的训练样本、训练模型以及训练方式均一致,因此,以下以gpu计算资源利用率预测模型为例对两个模型的训练过程进行说明。根据本发明的一个实施例,gpu计算资源利用率预测模型按照以下方式训练得到:获取第一训练样本集,其包括多个训练样本,每个训练样本包括指定算力gpu对应的硬件特征、深度学习任务对应的网络结构特征、深度学习任务对应的执行特征以及标签,标签包括对训练样本中深度学习任务在该指定算力gpu上的计算资源利用率的指示;利用第一训练样本集训练利用率预测模型输出计算资源利用率集,根据输出的计算资源利用率集和对应标签计算的损失值更新gpu计算资源利用率预测模型的参数。根据本发明的一个实施例,gpu计算资源利用率预测模型基于多层感知机采用反向传播算法训练得到,代价函数设置均方误差或平均绝对值误差。根据本发明的一个实施例,训练样本中的硬件特征包括gpu的计算能力、gpu的显存大小以及gpu的计算核心数,可直接通过查看gpu的性能参数获取,为便于模型识别gpu的硬件特征,训练样本中的gpu的硬件特征按照预设格式表示,例如可表示为:{capability(),memory(),cores()},其中,括号前的内容分别表示为gpu的计算能力、gpu的显存大小(单位为吉字节(giga byte,gb))和gpu的计算核心数,括号中的内容为对应的性能参数,例如一gpu的硬件特征可表示为:{capability(7),memory(32),cores(2880)}。根据本发明的一个实施例,训练样本中的深度学习任务对应的网络结构特征由tensorflow程序通过有向无环图(dag)来描述,如图2所示,使用dag节点结构作为深度学习任务的网络模型特征。考虑到每个深度学习任务不同,因此每个深度学习任务所涵盖的计算图节点以及对应的输入数据大小也不相同,为便于模型识别出网络结构特征,训练样本中的网络结构特征按照预设格式表示,例如可表示为:{addv2(0),conv2d(0),maxpool(0),relu(0),matmul(0),avgpool(0),mul(0),concat(0),softmax(0)},其中,括号前的内容为计算图节点的名称,括号中的内容是计算图节点对应的输入数据大小。若深度学习任务a包括的计算图节点有addv2、conv2d、maxpool、matmul以及softmax,且各
个计算图节点对应的输入数据大小分别为:2000、4800、3200、4200、100,则深度学习任务a的网络结构特征表示为:{addv2(2000),conv2d(4800),maxpool(3200),relu(0),matmul(4200),avgpool(0),mul(0),concat(0),softmax(100)}。进一步地,考虑到网络结构特征中存在重复的计算图节点,而在重复的计算图节点中对利用率预测影响较大的为具有最大输入数据大小的那个重复节点,因此当一个深度学习任务中出现了重复的计算图节点时,将重复的计算图节点中的最大的输入数据大小填入网络结构特征表中对应的计算图节点。例如:深度学习任务b包括3个重复的计算图节点conv2d,输入数据大小分别为2400、2800、4800;其余的计算图节点为:addv2、maxpool、relu以及concat,输入数据大小分别为2400、4800、1000、100,由于计算图节点conv2d中最大的输入数据大小为4800,因此将4800填入网络结构特征表中的conv2d处,则深度学习任务b对应的网络结构特征为:{addv2(2400),conv2d(4800),maxpool(4800),relu(1000),matmul(0),avgpool(0),mul(0),concat(100),softmax(100)}。根据本发明的一个实施例,执行特征包括批次大小、迭代次数以及输入大小,为便于模型识别执行特征,训练样本中的执行特征按照预设格式表示,例如可表示为:{batchsize(0),iteration(0),input(0)},其中,括号前的内容分别表示为批次大小、迭代次数和输入大小,括号中的内容为对应的参数。例如一深度学习任务a的批次大小、迭代次数和输入大小的参数分别为32、2000以及1000,则深度学习任务a的执行特征表示为:{batchsize(32),iteration(2000),input(1000)}。综上,在本发明的一个实施例中,每个训练样本由网络结构特征、执行特征以及gpu硬件特征三个维度的数据表示,即训练样本表示为:
79.p={i_dag,i_exec,i_gpu};
80.其中,idag,iexec,igpu分别表示网络计算图特征,执行特征和硬件特征的关键信息。例如:一训练样本的网络计算图特征表示为:i_dag={addv2(2000),conv2d(4800),maxpool(3200),relu(1000),matmul(4200),avgpool(0),mul(0),concat(100),softmax(100)};执行特征表示为:idag={batchsize(32),iteration(2000),input(1000)};硬件特征表示为igpu={capability(7),memory(32),cores(2880)},则p表示为:p={addv2(2000),conv2d(4800),maxpool(3200),relu(1000),matmul(4200),avgpool(0),mul(0),concat(100),softmax(100),batchsize(32),iteration(2000),input(1000),capability(7),memory(32),cores(2880)}。
81.其中,值得说明的是,网络计算图特征中各个计算图节点的顺序、执行特征中各个特征的顺序、硬件特征中各个特征的顺序以及训练样本中各个参数的顺序仅为一个适应性说明,实施者可以根据实际应用的具体情况作出相应的调整,本发明对此不作任何限制。
82.步骤a3:基于资源利用率集从可用资源集中确定满足深度学习任务的资源需求的所有工作节点并且根据预定的选择规则从满足深度学习任务的资源需求的所有工作节点中选择一个工作节点为深度学习任务分配资源;
83.由于可用资源集中包含了各工作节点中各个gpu的剩余资源,资源利用率集中包含了深度学习任务在各种算力gpu上的资源利用率,因此在用深度学习任务在各种算力gpu上的资源利用率去匹配满足相应资源需求的工作节点时会存在匹配出多个工作节点的情况,而在为深度学习任务分配资源时,只需要一个工作节点为其分配gpu资源,因此还需要根据预定的选择规则从满足深度学习任务的资源需求的所有工作节点中选择一个工作节
点为深度学习任务分配资源。考虑到后续可以根据深度学习任务的执行情况增加分配给深度学习任务的gpu资源,根据本发明的一个实施例,预定的选择规则设置为:从满足深度学习任务的资源需求的所有工作节点中选择具有最多的gpu剩余资源的工作节点为深度学习任务分配资源。例如,深度学习任务d对应的资源利用率集为:{a1算力gpu的40%资源、a2算力gpu的50%资源、a3算力gpu的70%资源},可用资源集为:{工作节点a(a1算力gpu的剩余资源90%、a1算力gpu的剩余资源100%、a1算力gpu的剩余资源30%)、工作节点b(a1算力gpu的剩余资源90%、a2算力gpu的剩余资源40%、a3算力gpu的剩余资源80%)、工作节点c(a1算力gpu的剩余资源10%、a2算力gpu的剩余资源20%、a3算力gpu的剩余资源50%)},由此可知,工作节点a和工作节点b均能分配相应的gpu资源给深度学习任务d,但是由于工作节点a中有一个a1算力gpu的剩余资源为100%,多于工作节点b中a1算力gpu的剩余资源和a3算力gpu的剩余资源,因此为便于后续根据深度学习任务d的执行情况增加分配给深度学习任务d的gpu资源,将深度学习任务d发送至工作节点a。此外,若多个工作节点中用于为深度学习任务分配资源的gpu的剩余资源相同,则随机选择一个工作节点分配深度学习任务或者按照工作节点在资源调度系统中的分布顺序进行分配。例如,深度学习任务e对应的资源利用率集为:{a1算力gpu的30%资源、a2算力gpu的50%资源、a3算力gpu的90%资源},可用资源集为:{工作节点a(a1算力gpu的剩余资源0%、a1算力gpu的剩余资源20%、a1算力gpu的剩余资源80%)、工作节点b(a1算力gpu的剩余资源0%、a1算力gpu的剩余资源30%、a3算力gpu的剩余资源80%)、工作节点c(a1算力gpu的剩余资源20%、a2算力gpu的剩余资源80%、a3算力gpu的剩余资源80%)},由此可知,三个工作节点均能为深度学习任务分配gpu资源且能为深度学习任务分配gpu资源的gpu具有的最大剩余资源相同,均为80%,因此将深度学习任务随机分配给其中的一个工作节点,或者根据工作节点在资源调度系统中的分布顺序将深度学习任务分配给工作节点a。
84.其中,值的说明的是,本方案中的选择规则并不唯一,本技术实施例只是一个示意性说明,实施者可以根据实际应用的具体情况作出相应的调整,例如,可以基于预定的评分规则对满足深度学习任务的资源需求的所有工作节点进行评分,从所有的工作节点中选择评分最高的工作节点为深度学习任务分配资源,本发明对此不作任何限制。
85.根据本发明的一个实施例,若在分配过程中出现当前所有的工作节点均不能满足深度学习任务的资源需求且深度学习任务为延时敏感任务时,则判断是否存在可释放资源且可释放资源不少于分配给深度学习任务资源的工作节点,若是,释放可释放资源并将深度学习任务分配给该工作节点;若否,将深度学习任务存放至延时敏感任务等待队列,其中,可释放资源为分配给非延时敏感任务的资源。由于延时敏感任务对时效性要求较高,不能容忍长时间的延迟,而非延时敏感任务对时效无要求,不需要保障其执行速度,因此在没有gpu资源分配给延时敏感任务时,通过检查是否有非延时敏感任务占用gpu资源,并在有非延时敏感任务占用gpu资源释放其资源,使得将资源优先供给延时敏感任务以提升延时敏感任务的服务质量。例如:深度学习任务f对应的资源利用率集为:{a1算力gpu的35%资源、a2算力gpu的45%资源、a3算力gpu的65%资源},可用资源集为:{工作节点a(a1算力gpu的剩余资源0%、a1算力gpu的剩余资源0%、a1算力gpu的剩余资源0%)、工作节点b(a1算力gpu的剩余资源0%、a1算力gpu的剩余资源30%、a3算力gpu的剩余资源50%)、工作节点c(a1算力gpu的剩余资源20%、a2算力gpu的剩余资源20%、a3算力gpu的剩余资源40%)},由
此可知,工作节点a、工作节点b以及工作节点c均不能分配相应的资源给深度学习任务c,但是工作节点c中a1算力gpu分配有40%的资源给非延时敏感任务,在回收给分配给非延时敏感任务的资源后,工作节点c中a1算力gpu的可用资源变为60%,因此可以在回收分配给非延时敏感任务的资源后,将深度学习任务发送至工作节点c。根据本发明的一个实施例,若在当前所有的工作节点均不能满足深度学习任务的资源需求且深度学习任务为非延时敏感任务时,则将深度学习任务存放至控制节点中的非延时敏感任务等待队列,待有空闲资源时再被重新调度。
86.步骤a4:将深度学习任务及其资源需求发送给所选择的工作节点,资源需求指示深度学习任务在多种指定算力gpu上的资源利用率。
87.进一步地,考虑到在单个gpu上并发执行多个服务会增加单一任务的延时,影响任务的执行。而在深度学习任务中,很多延时敏感任务都有服务质量的要求,其对时效性要求较高,不能容忍长时间的延迟,因此在资源分配中,不仅需要考虑任务的资源利用率,还需要满足任务的服务质量,根据本发明的一个实施例,为监控延时敏感任务的服务质量,还对延时敏感任务的执行时间进行了预测,以便后续根据延时敏感任务的执行时间来增加分配给延时敏感任务的gpu资源,防止因gpu资源分配不足而带来的低服务质量问题。根据本发明的一个实施例,基于执行时间预测模型根据延时敏感任务对应的网络结构特征、延时敏感任务对应的执行特征、延时敏感任务在指定算力gpu上对应的资源利用率以及指定算力gpu对应的硬件特征对延时敏感任务在指定算力gpu上的执行时间进行预测,得到预测执行时间集,并将预测执行时间集传输至为延时敏感任务分配资源的工作节点,预测执行时间集包括延时敏感任务在多种指定算力gpu上的预测执行时间。根据本发明的一个实施例,执行时间预测模型按照以下方式训练得到:获取第二训练样本集;其包括多个训练样本,每个训练样本包括指定算力gpu对应的硬件特征、延时敏感任务对应的网络结构特征、延时敏感任务对应的执行特征、延时敏感任务在指定算力gpu上对应的资源利用率以及标签,标签包括对训练样本中延时敏感任务在该指定算力gpu上的执行时间的指示;利用第二训练样本集训练执行时间预测模型输出预测执行时间,根据输出的预测执行时间和对应标签计算的损失值更新执行时间预测模型的参数。其中,gpu对应的硬件特征、延时敏感任务对应的网络结构特征以及延时敏感任务对应的执行特征的处理方式参见利用率预测模型,因此本技术实施例不在对其进行阐述。
88.(二)工作节点的改进
89.根据本发明的一个实施例,本发明提供一种用于深度学习任务的gpu资源分配方法,应用于多租户容器云平台的资源调度系统,资源调度系统包括一个控制节点及多个工作节点,每个工作节点包括多个gpu,方法包括在每个工作节点执行如图3所示的步骤b1和步骤b2。为了更好地理解本发明,下面结合具体的实施例针对每一个步骤分别进行详细说明。
90.步骤b1:接收控制节点按照前述实施例的方法发送给当前工作节点的深度学习任务及其资源需求,其中,资源需求指示深度学习任务在多种指定算力gpu上的资源利用率;
91.步骤b2:基于当前工作节点中多个gpu的剩余资源和资源需求为深度学习任务分配gpu及对应的gpu资源。
92.由于单个工作节点中具有多个gpu,每个gpu的算力及剩余资源并不相同,因此工
作节点还需根据gpu的剩余资源为深度学习任务分配对应的gpu及gpu资源。例如,深度学习任务g所需的资源为:a1算力gpu的20%资源,而工作节点具有4个a1算力gpu,每个gpu的剩余资源分别为:50%、10%、0%、0%。则工作节点则需将深度学习任务g分配给具有50%剩余资源的gpu,并分配20%的资源给深度学习任务g,从而实现资源的合理分配。其中,当当前工作节点中存在多个gpu可以为深度学习任务分配资源时,为便于后续可动态的调整分配给延时敏感任务的资源量,优选地,将深度学习任务分配至具有最多剩余资源的gpu中,例如:深度学习任务所需的资源为:a1算力gpu的30%资源,而工作节点具有4个a1算力gpu,每个gpu的剩余资源分别为:80%、40%、100%、10%。则工作节点将深度学习任务分配给具有100%剩余资源的gpu,并分配30%的资源给深度学习任务。
93.根据本发明的一个实施例,为了保证有足够多的gpu资源可以分配给延时敏感任务,也为了减少延时敏感任务在延时敏感等待队列的等待时间,保证延时敏感任务的执行效率,当深度学习任务为非延时敏感任务时,将深度学习任务分配至具有最短执行时间的gpu中。其中,执行时间基于执行时间预测模型根据非延时敏感任务对应的网络结构特征、非延时敏感任务对应的执行特征、非延时敏感任务在指定算力gpu上对应的资源利用率以及指定算力gpu对应的硬件特征进行预测。由于本技术实施例中的执行时间预测模型与控制节点中的执行时间预测模型相同,因此,相关训练或处理过程参见控制节点对执行时间预测模型的训练或处理过程即可,本技术实施例不再对其进行阐述。
94.考虑到在深度学习任务中,很多延时敏感任务都有服务质量的要求,因此为满足延时敏感任务的服务质量要求,还需要对延时敏感任务的执行情况是否满足预设服务质量进行监控。根据本发明的一个实施例,监控深度学习任务的执行情况是否满足预设服务质量包括:
95.获取延时敏感任务的已执行时间以及执行进度;
96.根据执行进度更新延时敏感任务对应的执行特征以及网络结构特征;
97.例如,一延时敏感任务的总迭代次数为100次,即iteration(100),执行一段时间后,该延时敏感任务已经执行了60次,还剩余40次未执行,则更新对应的迭代次数即可,即将iteration(100)更新iteration(40)。其中,值得说明的是,根据执行进度更新延时敏感任务对应的执行特征以及网络结构特征为现有技术,本技术不涉及对其的改进,因此不再对其具体的更新过程及原理做过多的阐述。
98.基于执行时间预测模型根据深度学习任务在指定算力gpu上对应的资源利用率、指定算力gpu对应的硬件特征、更新后的执行特征以及网络结构特征预测深度学习任务的剩余执行时间;
99.在已执行时间和剩余执行时间之和大于预设执行时间时,判断延时敏感任务的执行情况未满足预设服务质量。根据本发明的一个实施例,预设执行时间为控制节点发送的深度学习任务在当前gpu上的预测执行时间。
100.例如,延时敏感任务的预设执行时间为2min,此时任务已经执行了1min30s,执行时间预测模型根据当前的执行状况预测还有1min方能执行完毕,即:在当前执行情况下,该任务的实际执行实际为2min30s,超过了预设执行时间2min,说明任务的执行状态不正常,未满足预设服务质量,需要增加分配给该任务的资源,从而来缩短未执行时间以达到预设服务质。其中,值得说明的是,在增加分配给该任务的资源时,可以通过预先设置增长步长
来实现资源的增加,例如预设增长步长为10%,则在未满足预设服务质量,从当前的gpu中再分配10%的gpu资源给任务,若增加10%的gpu资源后,还是未满足预设服务质量,则从当前的gpu中再分配10%的gpu资源给任务,直至当前的gpu无剩余资源可分配给该任务。根据本发明的一个实施例,若在增加分配给深度学习任务的资源时出现gpu资源不足,则减少对该gpu上的非延时敏感任务的资源分配,由于非延时敏感任务可以容忍较长的延时,因此可以通过释放非延时敏感任务的资源以使得有更多的资源分配给延时敏感人物;若在增加分配给深度学习任务的资源后,出现非延时敏感任务的执行资源不足时,则保存非延时敏感任务的执行状态并结束非延时敏感任务的执行,并将非延时敏感任务放入非敏感等待队列,等到当前的gpu有空余的gpu资源时,再重新调度非延时敏感任务进行执行。根据本发明的一个实施例,在监控到深度学习任务的执行情况满足预设服务质量时,查询深度学习任务在当前gpu上的资源利用率,若资源利用率超过控制节点发送的深度学习任务在当前gpu上的预测资源利用率时,暂停深度学习任务在当前gpu上的执行,待资源利用率下降至预测资源利用率时,重新在当前gpu上执行所述深度学习任务。
101.(三)资源调度系统
102.根据本发明的一个实施例,本发明提供一种基于kubernetes平台的资源调度系统,如图4所示,包括:
103.控制节点,被配置为按照(一)控制节点的改进中对应实施例的方法向工作节点传输深度学习任务及其资源需求,资源需求指示深度学习任务在多种指定算力gpu上的资源利用率;
104.多个工作节点,每个工作节点被配置为根据(二)工作节点的改进中对应实施例的方法为深度学习任务分配gpu及对应的gpu资源。
105.根据本发明的一个实施例,控制节点包括:
106.第一预测单元,用于基于利用率预测模型根据网络结构特征和执行特征对深度学习任务的资源利用率进行预测,得到资源利用率集,资源利用率集包括深度学习任务在多种指定算力gpu上的资源利用率;
107.第一调度单元,用于基于资源利用率集从可用资源集中确定满足深度学习任务的资源需求的所有工作节点并且根据预定的选择规则从满足深度学习任务的资源需求的所有工作节点中选择一个工作节点为深度学习任务分配资源,并将深度学习任务及其资源需求发送给所选择的工作节点,资源需求指示深度学习任务在多种指定算力gpu上的资源利用率。
108.根据本发明的一个实施例,控制节点还包括:
109.延时敏感任务等待队列,用于在当前所有的工作节点均不能满足延时敏感任务的资源需求时存放所述延时敏感任务;
110.非延时敏感任务等待队列,用于当前所有的工作节点均不能满足非延时敏感任务的资源需求时存放非延时敏感任务;
111.其中,在延时敏感任务等待队列不为空时,优先为敏感任务等待队列中的延时敏感任务分配gpu资源。
112.根据本发明的一个实施例,第一预测单元还用于:
113.基于执行时间预测模型根据深度学习任务对应的网络结构特征、深度学习任务对
应的执行特征、深度学习任务在指定算力gpu上对应的资源利用率以及指定算力gpu对应的硬件特征对深度学习任务在指定算力gpu上的执行时间进行预测,得到用于检测非延时敏感任务的执行情况是否满足预设服务质量的预测执行时间集。
114.根据本发明的一个实施例,工作节点包括:
115.拓扑感知单元,用于获取当前工作节点中多个gpu的剩余资源;
116.第二预测单元,用于基于执行时间预测模型根据非延时敏感任务对应的网络结构特征、非延时敏感任务对应的执行特征、非延时敏感任务在指定算力gpu上对应的资源利用率以及指定算力gpu对应的硬件特征对非延时敏感任务在指定算力gpu上的执行时间进行预测,得到非延时敏感任务在多种指定算力gpu上的执行时间;
117.第二调度单元,用于基于当前工作节点中多个gpu的剩余资源和资源需求为深度学习任务分配gpu及对应的gpu资源;还用于根据非延时敏感任务在多种指定算力gpu上的执行时间为非延时敏感任务分配具有最短执行时间的gpu。
118.根据本发明的一个实施例,工作节点还包括:
119.弹性调整单元,用于监控延时敏感任务的执行情况是否满足预设服务质量,并在延时敏感任务的执行情况未满足预设服务质量时,增加当前gpu分配给所述深度学习任务的gpu资源;若在增加分配给所述深度学习任务的资源时出现gpu资源不足,减少对当前gpu上的非延时敏感任务的资源分配;若增加分配给所述深度学习任务的gpu资源后,出现非延时敏感任务的执行资源不足,保存所述非延时敏感任务的执行状态并结束所述非延时敏感任务的执行;
120.资源限制单元,用于在延时敏感任务的执行情况满足预设服务质量时,查询延时敏感任务在当前gpu上的资源利用率,若所述延时敏感任务在当前gpu上的资源利用率超过所述控制节点发送的所述延时敏感任务在当前gpu上的预测资源利用率时,暂停所述延时敏感任务在当前gpu上的执行,待所述资源利用率下降至所述预测资源利用率时,重新在当前gpu上执行所述延时敏感任务。
121.现有技术中由用户指定任务在gpu中的使用份额,忽略了任务本身的特征,存在资源过度分配导致gpu资源无法得到充分利用的问题,基于此,为克服上述技术问题,本技术实施例通过对深度学习任务的资源需求量进行预测,从而根据预测的资源需求量来对容器云集群中的gpu资源进行合理分配,实现了针对不同任务的特征合理分配gpu资源,用户不必指定任务需要使用的资源,避免了资源过度分配的问题,在实现容器云集群中的gpu资源共享的同时,提升了容器云集群中的gpu利用率。除此之外,还通过执行时间预测模块对任务的执行时间进行预测,从而可以实时监控延时敏感任务的执行状态并根据执行状态对延时敏感任务的资源分配进行及时的调整,保证了用户提交任务的服务质量。
122.需要说明的是,虽然上文按照特定顺序描述了各个步骤,但是并不意味着必须按照上述特定顺序来执行各个步骤,实际上,这些步骤中的一些可以并发执行,甚至改变顺序,只要能够实现所需要的功能即可。
123.本发明可以是系统、方法和/或计算机程序产品。计算机程序产品可以包括计算机可读存储介质,其上载有用于使处理器实现本发明的各个方面的计算机可读程序控制指令。
124.计算机可读存储介质可以是保持和存储由控制指令执行设备使用的控制指令的
有形设备。计算机可读存储介质例如可以包括但不限于电存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或者上述的任意合适的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:便携式计算机盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、静态随机存取存储器(sram)、便携式压缩盘只读存储器(cd-rom)、数字多功能盘(dvd)、记忆棒、软盘、机械编码设备、例如其上存储有控制指令的打孔卡或凹槽内凸起结构、以及上述的任意合适的组合。
125.以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。