1.本发明的一个方式涉及一种文档检索系统。此外,本发明的一个方式涉及一种文档检索方法。
背景技术:
2.各种各样的文档检索技术已被提出。在现有的文档检索当中,主要使用单词(字符串)检索。例如,网页利用页面排序算法等,专利领域利用类属词典。此外,还有得到单词的集合来使用jaccard系数、dice系数、simpson系数等表现文本相似度的方法。此外,还有使用tf-idf、bag of words(bow)、doc2vec等使文本矢量化来对比余弦相似度的方法。此外,还有汉明距离、莱文斯坦距离、jaro-winkler距离等评估文本的字符串的相似度来检索所希望的文档的方法。此外,专利文献1公开了一种语言处理装置,其中通过将句子的构成单位转换为串结构,计算出串结构间距离,从句子是否相似的观点来进行对比。[先行技术文献][专利文献]
[0003]
[专利文献1]日本专利申请公开第2005-258624号公报
技术实现要素:
发明所要解决的技术问题
[0004]
为了检索各种领域的文档,需要准确度更高的文档检索方法。例如,专利文件(说明书、专利申请范围等)或合同书等文档在很多情况下使用类似单词。因此,重要的不仅是在文档中使用的单词,而且还是考虑到文档的概念(概括内容)的检索技術。
[0005]
鉴于此,本发明的一个方式的目的之一是提供一种考虑到文档的概念的文档检索系统。此外,本发明的一个方式的目的之一是提供一种考虑到文档的概念的文档检索方法。
[0006]
注意,这些目的的记载并不妨碍其他目的的存在。本发明的一个方式并不需要实现所有上述目的。可以从说明书、附图、权利要求书等的记载中显然得知并抽取上述目的以外的目的。解决技术问题的手段
[0007]
本发明的一个方式是一种文档检索系统,包括处理部。处理部具有使用文本形成图(graph)的功能,检索图由检索文本形成,检索图包括第一至第m(m为1以上的整数)检索局部图,第一至第m检索局部图都由两个节点及两个节点间的边构成,处理部还具有对参考文档进行第一至第m句子的检索的功能,第i(i为1以上且m以下的整数)句子具有第(3i-2)单词、第(3i-1)单词及第3i单词,第(3i-2)单词是第i检索局部图的两个节点中的一方、两个节点中的一方的相关词或两个节点中的一方的下位词,第(3i-1)单词是第i检索局部图的两个节点中的另一方、两个节点中的另一方的相关词或两个节点中的另一方的下位词,第3i单词是第i检索局部图的边、边的相关词或边的下位词,处理部还具有根据在第一至第m句子中参考文档所包括的句子数对参考文档的得分赋予第一分数的功能。
[0008]
在上述文档检索系统中,处理部优选具有如下功能:在参考文档包括第j(j为1以上且m以下的整数)句子及第k(k为不是j的1以上且m以下的整数)句子的情况下,根据第j句子与第k句子之距离对参考文档的得分赋予第二分数;以及根据被赋予到参考文档的得分的分数算出参考文档的得分。
[0009]
在上述文档检索系统中,处理部优选具有根据第j句子中的第(3j-2)单词与基于第j检索局部图的两个节点中的一方的单词的概念相似度对参考文档的得分赋予第三分数的功能。
[0010]
在上述文档检索系统中,处理部优选具有从多个参考文档抽出包括第l(l为1以上且m以下的整数)句子所包括的第(3l-2)单词及第(3l-1)单词的参考文档的功能。
[0011]
在上述文档检索系统中,处理部所具有的使用文本形成图的功能优选具有如下功能:将文本分割成多个标记(token);进行依存分析;根据依存分析的结果联结标记的一部分;根据依存分析的结果评估标记间的联结关系;以及根据标记间的联结关系构建图。
[0012]
在上述文档检索系统中,处理部所具有的使用文本形成图的功能优选还具有将有代表词或上位词的标记置换成代表词或上位词的功能。
[0013]
在上述文档检索系统中,优选的是,除了处理部之外还包括输入部,输入部具有将检索文本供应到处理部的功能。
[0014]
在上述文档检索系统中,优选的是,除了处理部及输入部之外还包括输出部,输出部具有供应参考文档的得分的功能。发明效果
[0015]
根据本发明的一个方式,可以提供一种考虑到文档的概念的文档检索系统。此外,根据本发明的一个方式,可以提供一种考虑到文档的概念的文档检索方法。
[0016]
注意,本发明的一个方式的效果不局限于上述效果。上述效果并不妨碍其他效果的存在。此外,其他效果是指将在下面的记载中描述的上述以外的效果。本领域技术人员可以从说明书、附图等的记载中导出并适当抽出上述以外的效果。此外,本发明的一个方式具有上述效果及/或其他效果中的至少一个。因此,本发明的一个方式根据情况而有时没有上述效果。附图简要说明
[0017]
图1是示出文档检索系统的一个例子的图。图2是示出文档检索方法的一个例子的流程图。图3是示出图形成工序的一个例子的流程图。图4a至图4c是示出在各工序中得到的结果的图。图5a至图5c是示出在各工序中得到的结果的图。图6a至图6d是示出在各工序中得到的结果的图。图7a至图7c是示出在各工序中得到的结果的图。图8是说明图的一个例子的图。图9是示出参考文档分析的一个例子的流程图。图10是示出参考文档分析的一个例子的流程图。图11是说明单词的相关的图。图12a是说明图的一个例子的图。图12b是示出在各工序中得到的结果的图。
图13a及图13b是示出在各工序中得到的结果的图。图14是示出文档检索方法的一个例子的流程图。图15是示出筛选参考文档的一个例子的流程图。图16是示出文档检索系统的硬件的一个例子的图。图17是示出文档检索系统的硬件的一个例子的图。实施发明的方式
[0018]
参照附图对实施方式进行详细说明。注意,本发明不局限于下面说明,所属技术领域的普通技术人员可以很容易地理解一个事实就是其方式及详细内容在不脱离本发明的宗旨及其范围的情况下可以被变换为各种各样的形式。因此,本发明不应该被解释为仅限定在以下所示的实施方式所记载的内容中。
[0019]
此外,在下面所说明的发明的结构中,在不同的附图中共同使用相同的符号来表示相同的部分或具有相同功能的部分,而省略其重复说明。此外,当表示具有相同功能的部分时有时使用相同的阴影线,而不特别附加符号。
[0020]
此外,为了便于理解,有时附图中示出的各构成要素的位置、大小及范围等并不显示其实际的位置、大小及范围等。因此,所公开的发明不一定局限于附图所公开的位置、大小、范围等。
[0021]
此外,在本说明书中使用的“第一”、“第二”、“第三”等序数词是为了方便识别构成要素而附的,而不是为了在数目方面上进行限定的。
[0022]
在本说明书等中,定义为“文本”由一个以上的“句子”构成。因此,“文本”还包括“句子”。另外,“文档”有时是指由文字表示的一个记录。注意,在本说明书等中,“文档”有时是指文档中的文本的一部分或全部。也就是说,可以将“文档”换称为“文本”。另外,有时将文档中的文本的一部分或全部简单地记为“文本”。
[0023]
另外,在本说明书等中,“文本”或“文档”有时是指可以在服务器、个人计算机等数据处理装置中进行处理及传送的文本信息或文本编码的集合。注意,有时将该集合称为文本数据。
[0024]
(实施方式1)在本实施方式中,参照图1至图15说明本发明的一个方式的文档检索系统及文档检索方法。
[0025]
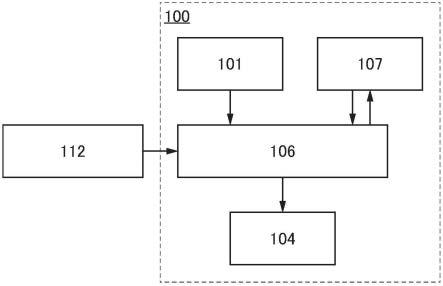
《文档检索系统》图1是示出文档检索系统100的结构的图。
[0026]
可以在用户利用的个人计算机等信息处理装置中设置文档检索系统100。此外,可以在服务器中设置文档检索系统100的处理部,以从客户pc通过网络利用文档检索系统100。
[0027]
文档检索系统100至少包括处理部106。图1所示的文档检索系统100包括处理部106、输入部101、存储部107及输出部104。另外,文档检索系统100通过网络与概念词典112连接。
[0028]
处理部106具有使用文本形成图的功能。该文本是用户为检索而指定的文本(也称为检索文本、查询文本等)以及包括在作为检索对象的文档(也称为参考文档)中的文本。注意,从用户为检索而指定的文本形成的图也被称为检索图、查询图等。
[0029]
图由节点集合(也称为节点群)和表示节点间的联结关系的边集合(也称为边群)构成。该节点群具有两个以上的节点。另外,该边群具有一个以上的边。注意,有时在具有一个边的情况下也被记为边群。
[0030]
图优选为有向图。有向图是指由节点群及有向边群构成的图。此外,图更优选为对节点及边赋予标签的有向图。通过使用被赋予标签的有向图,可以提高检索的准确度。另外,也可以对图所具有的节点及/或边设定权重。通过对节点及/或边设定权重,可以检索用户所希望的文档。注意,图也可以为无向图。
[0031]
处理部106例如优选具有进行语素分析的功能、进行依存分析的功能、进行抽象化的功能以及构建图的功能。此外,处理部106具有参照概念词典112的功能。通过参照概念词典112,在处理部106中使用文本形成图。
[0032]
进行语素分析的功能及/或进行依存分析的功能也可以设置在与文档检索系统100不同的装置中。此时,文档检索系统100将上述文本发送到该装置,并接收该装置所进行的语素分析及/或依存分析的结果,来将所接收的数据发送到处理部106即可。
[0033]
处理部106具有分析参考文档的功能。另外,处理部106具有评估参考文档的功能。例如,处理部106优选具有对参考文档的得分赋予分数的功能。另外,处理部106具有抽出参考文档的功能。
[0034]
使用输入部101输入文本。输入部101具有将该文本供应到处理部106的功能。该文本是用户为检索而指定的文本。该文本为文本数据。注意,该文本也可以为音频数据或图像数据。输入部101为如键盘、鼠标、触摸传感器、麦克风、扫描仪、相机等输入设备。
[0035]
文档检索系统100也可以具有将音频数据转换为文本数据的功能。例如,处理部106也可以具有该功能。此外,文档检索系统100也可以还包括具有该功能的音频文本转换部。
[0036]
文档检索系统100也可以具有光学文字识别(ocr)功能。由此,能够识别图像数据所包括的文字来生成文本数据。例如,处理部106也可以具有该功能。此外,文档检索系统100也可以还包括具有该功能的文字识别部。
[0037]
存储部107储存多个参考文档。该多个参考文档也可以通过输入部101、存储介质、通信等被储存在存储部107中。
[0038]
储存在存储部107中的多个参考文档优选为文本数据。作为不同例子,在储存在存储部107中的多个参考文档为音频数据或图像数据的情况下,通过将音频数据或图像数据所包括的文本信息转换为文本数据,可以减少数据量。因此,通过将文本数据储存在存储部107中,可以降低存储部107的存储容量的增大。
[0039]
此外,存储部107也可以储存用输入部101输入的文本。另外,也可以储存根据该文本在处理部106中形成的图作为文本数据、图像数据等。
[0040]
输出部104具有输出信息的功能。该信息是由处理部106评估参考文档的结果。例如,该信息是参考文档的得分。或者,该信息是得分最高的参考文档。或者,该信息是根据得分被排序的排序数据。
[0041]
上述信息例如作为字符串、数值、图表等视觉信息或听觉信息等被输出到输出部104。输出部104为如显示器、扬声器等输出设备。
[0042]
文档检索系统100也可以具有将文本数据转换为音频数据的功能。例如,文档检索
系统100也可以还包括具有该功能的文本音频转换部。
[0043]
概念词典112是附有单词的分类、与其他单词的关系等的列表。概念词典112也可以是现有概念词典。或者,也可以生成专门于检索文本或参考文档的领域的概念词典。或者,也可以对通用概念词典追加在检索文本或参考文档的领域中常用的单词。
[0044]
此外,虽然在图1中示出概念词典112设置在与文档检索系统100不同的装置中的结构,但是不局限于此。概念词典112也可以包括在文档检索系统100中。
[0045]
以上说明了文档检索系统100的结构。通过使用作为本发明的一个方式的文档检索系统,可以考虑到文本的概念从多个参考文档中检索与该文本相似的文档。此外,也可以从多个参考文档中形成与该文本相似的文档的一览。例如,与文本相似的文档是指使用不同单词也被判断为(大体上的)含义与该文本相同的文档。另外,在语言不同的两个文本之间,在文本具有相同的概念时,使用该两个文本各自形成的图为相同的。因此,通过使用作为本发明的一个方式的文档检索系统,可以容易在不同语言之间检索文档。
[0046]
根据本发明的一个方式,可以提供一种考虑到文档的概念的文档检索系统。
[0047]
《文档检索方法》图2是说明文档检索系统100所执行的处理的流程的流程图。也就是说,图2是示出作为本发明的一个方式的文档检索方法的一个例子的流程图。
[0048]
对本发明的一个方式的文档检索方法进行说明。在该方法中,根据使用文本形成的图分析并评估参考文档。参照图2说明文档检索方法。
[0049]
如图2所示,文档检索方法包括步骤s001至步骤s005。
[0050]
[步骤s001]在步骤s001中,取得文本20。文本20是从输入部101供应到处理部106的文本。文本20是用户为检索而指定的文本。注意,在文本20的数据是文本数据以外的数据(音频数据或图像数据)的情况下,在转到步骤s002之前将音频数据或图像数据转换为文本数据。为了将音频数据转换为文本数据,利用处理部106所具有的将音频数据转换为文本数据的功能或音频文本转换部即可。为了将图像数据转换为文本数据,利用处理部106所具有的光学文字识别(ocr)功能或文字识别部即可。
[0051]
在文本20为专利申请范围的情况下,也可以在转到步骤s002之前对文本20进行清理处理。在该清理处理中,去除文本中的噪声。例如,该清理处理是指删除分号、将冒号置换成逗号等。通过对文本进行清理处理,可以提高语素分析的准确度。另外,在文本20为权利要求的情况下,也可以在转到步骤s002之前对文本20进行清理处理。
[0052]
此外,在文本20不是专利申请范围也不是权利要求的情况下,也可以根据需要适当地进行上述清理处理。此外,文本20也可以在被进行上述清理处理之后被储存在存储部107中。
[0053]
[步骤s002]在步骤s002中,使用文本20形成图21。图3是示出使用文本形成图的工序的一个例子的流程图。步骤s002包括图3所示的步骤s021至步骤s024。为了说明步骤s002,参照步骤s021至步骤s024进行说明。
[0054]
在步骤s021中,在处理部106中对文本进行语素分析。由此,该文本被分割成语素(单词)。在本说明书中,被分割出的语素(单词)有时被称为标记。
[0055]
在步骤s021中,优选对上述标记分别判定标记的词类来使词类标签有关联。通过使标记与词类标签有关联,可以提高依存分析的准确度。此外,在本说明书等中,“使标记与词类标签有关联”可以被换称为“对标记赋予词类”。
[0056]
在处理部106没有进行语素分析的功能的情况下,也可以使用被组装在与文档检索系统不同的装置中的语素分析程序(也称为语素分析器)对文本分别进行语素分析。此时,在步骤s021中,将文本发送到该装置,在该装置中进行语素分析,并接收语素分析的结果。
[0057]
在步骤s022中,在处理部106中进行依存分析。也就是说,根据标记的各依存关系而结合多个标记的一部分。例如,在标记满足特定条件的情况下,使满足条件的标记彼此结合来生成新的标记。由此,标记数减少,而可以减少下面工序中的处理数。因此,可以实现被施加到中央处理器及存储器的负荷的降低、检索时间的缩减等。另外,可以在用户利用的个人计算机等信息处理装置或者小规模的服务器中设置文档检索系统100。
[0058]
在使用日文的文本中,具体而言,在第一标记为名词且位于第一标记正前的标记为形容词的情况下,结合位于第一标记正前的标记与第一标记来生成新的标记。此外,在第一标记为名词且位于第一标记正后的标记为名词的情况下,结合第一标记与位于第一标记正后的标记来生成新的标记。
[0059]
注意,上述条件根据在文本中使用的语言而适当地设定即可。
[0060]
上述依存分析优选包括合成词分析。通过进行该依存分析,结合多个标记的一部分来生成合成词作为新的标记。由此,即使该文本包括在概念词典112中没有登录的合成词,也可以以高准确度将该文本分割成标记。此外,也可以对概念词典112追加生成了的合成词。由此,可以提高将该文本分割成标记的效率。
[0061]
另外,步骤s022除了上述结合多个标记的一部分的工序之外还包括评估标记间的联结关系的工序。注意,评估标记间的联结关系的工序在上述结合多个标记的一部分的工序之后进行即可。
[0062]
在评估标记间的联结关系的工序中,例如搜索句子中有没有主语、宾语及谓语。
[0063]
例如,当在文本中使用日文时,句子按主语、宾语、谓语(动词、形容词、形容动词、名词与助词的组合等)的顺序被记载。鉴于此,依次搜索作为主语的标记、作为宾语的标记及作为谓语的标记。在上述标记包括在该句子中的情况下,将作为主语的标记及作为宾语的标记抽出为节点并将作为谓语的标记抽出为边即可。
[0064]
例如,当在文本中使用英文时,句子按主语、谓语(动词)、宾语的顺序被记载。鉴于此,依次搜索作为主语的标记、作为谓语(动词)的标记及作为宾语的标记。在上述标记包括在该句子中的情况下,将作为主语的标记及作为宾语的标记抽出为节点并将作为谓语(动词)的标记抽出为边即可。
[0065]
如上所述,主语、宾语及谓语的记载顺序根据在文本中使用的语言不同,因此根据语言适当地调整即可。
[0066]
另外,例如也可以搜索第一标记与第二标记之间的作为介词的标记。在作为介词的标记包括在该句子中的情况下,将第一标记及第二标记抽出为节点并将作为介词的标记抽出为边即可。
[0067]
另外,例如优选还搜索作为限定词的标记。限定词位于名词之前,明确地表示出该
名词所示的对象。因此,通过搜索作为限定词的标记,可以联结该限定词正后的名词与记载于该限定词之前的名词的关系。由此,可以判断上述名词是否同一个节点。
[0068]
注意,根据语言有个词类没有存在。因此,上述条件根据在文本中使用的语言而适当地设定即可。
[0069]
在处理部106没有进行依存分析的功能的情况下,也可以使用被组装在与文档检索系统不同的装置中的依存分析程序(也称为依存分析器)进行依存分析。此时,在步骤s022中,将标记发送到该装置,在该装置中进行依存分析,并接收依存分析的结果。
[0070]
在步骤s023中,在处理部106中使标记抽象化。该标记是在步骤s022中抽出的作为节点及边的标记。例如,通过分析标记所包含的单词,取得代表词。此外,在该代表词包含上位词的情况下,取得该上位词。然后,将该标记置换成所取得的该代表词或该上位词。在此,代表词是指同义词组中的词头(也称为词目)。此外,上位词是指相当于代表词的上位概念的代表词。也就是说,使标记抽象化是指将标记置换成代表词或上位词。此外,在标记为代表词或上位词的情况下,不需要置换该标记。
[0071]
要置换的上位词层次的上限优选为1层以上且2层以下,更优选为1层。此外,也可以指定要置换的上位词层次的上限。由此,可以抑制标记被过度转换成上位概念而从文本的概念脱离。另外,可以减少使标记抽象化的工序中的处理数。因此,可以实现被施加到中央处理器及存储器的负荷的降低、检索时间的缩减等。另外,可以在用户利用的个人计算机等信息处理装置或者小规模的服务器中设置文档检索系统100。
[0072]
标记的抽象适度根据每个领域而不同。于是,优选通过进行符合领域的机器学习来使标记抽象化。例如,通过使标记或进一步分割该标记而得的标记中的一个矢量化并使用分类器进行分类,使该标记抽象化。作为该分类器,可以使用如决策树、支持向量机、随机森林、多层感知器等算法。具体而言,“氧化物半导体”、“非晶半导体”、“硅半导体”以及“gaas半导体”可以被分类为“半导体”。此外,“氧化物半导体层”、“氧化物半导体膜”、“非晶半导体层”、“非晶半导体膜”、“硅半导体层”、“硅半导体膜”、“gaas半导体层”以及“gaas半导体膜”也可以被分类为“半导体”。
[0073]
此外,也可以使用分类器根据进一步分割标记而得的多个标记分类该标记。例如,在使作为标记的“氧化物半导体层”抽象化的情况下,将该标记进一步分割为语素而得的标记(“氧化”、“物”、“半导体”以及“层”)输入到分类器。作为输入到分类器的结果,如果被分类为“半导体”,就将该标记置换成“半导体”。由此,可以使该标记抽象化。
[0074]
除了上述机器学习算法之外,还可以使用条件随机场(conditional random field:crf)。此外,也可以组合crf与上述方法。
[0075]
通过使标记抽象化,可以把握文本的概念。因此,在检索文本时不易于受文本的结构或表现的影响。也就是说,可以根据文本的概念进行检索。
[0076]
为了取得代表词及上位词,既可利用概念词典,又可通过机器学习进行分类。作为该概念词典,既可使用设置在与文档检索系统100不同的装置中的概念词典112,又可使用文档检索系统100所具有的概念词典。
[0077]
在步骤s024中,在处理部106中构建图。也就是说,使用已在步骤s023中准备完的标记构建图。例如,在文本包括作为名词句的第一标记及第二标记,并包括表示第一标记与第二标记的联结关系的第三标记的情况下,将第一标记及第二标记各自作为节点及该节点
的标签,并且将第三标记作为边及该边的标签,由此构建图。也就是说,节点的标签及边的标签由已在步骤s023中准备完的标记构成。以下,在简单地记作节点的情况下,其有时表示节点的标签。另外,在简单地记作边的情况下,其有时表示边的标签。
[0078]
例如,在文本20为专利申请范围或权利要求的情况下,图的节点表示构成要素,并且图的边表示构成要素之间的关系。此外,在文本20为合同书等的情况下,图的节点表示甲方及乙方,并且图的边表示合同内容及条件。
[0079]
图也可以根据标记之间的依存关系而按规则构建。此外,也可以使用crf进行根据标记列表而对节点及边赋予标签的机器学习。由此,可以根据标记列表而对节点及边赋予标签。此外,也可以使用递归神经网络(recurrent neural network:rnn)、长短期记忆(long short-term memory:lstm)等进行通过输入标记列表来输出节点及边的方向的seq2seq模型学习。由此,可以根据标记列表而输出节点及边的方向。
[0080]
处理部106也可以具有使边的方向反转且将该边的标签置换成该边的标签的反义词的功能。例如,假设图包括第一边及被赋予作为第一边的标签的反义词的标签的第二边的情况。此时,使用该功能使第二边的方向反转且将第二边的标签置换成第二边的标签的反义词(即第一边的标签)。由此,该图被重新构建。通过使用重新构建的图,可以囊括实质上相同的结构。因此,可以根据概念性要素检索文档,而不易于受文档的结构或表现的影响。因此,在检索文本时不易于受文本的结构或表现的影像。也就是说,可以根据文本的概念进行检索。
[0081]
此外,优选对文本中的出现频率较低一方的边进行上述处理。也就是说,在第二边的出现频率低于或等于第一边的出现频率的情况下,优选进行使第二边的方向反转且将第二边的标签置换成第二边的标签的反义词(即第一边的标签)的处理。由此,可以减少进行上述处理的频率而缩短文档检索所需的时间。
[0082]
步骤s023与步骤s024的顺序也可以替换。在步骤s023及步骤s024的顺序替换的情况下,在构建图之后,该图所包含的节点及边被抽象化。由此,在步骤s023与步骤s024的顺序替换的情况下,也可以使用文本形成被抽象化的图。
[0083]
通过步骤s021至步骤s024,可以使用文本20形成图21。
[0084]
另外,也可以在进行步骤s002之后输出图21。或者,也可以设置在进行步骤s002之后输出构成图21的节点及边并在转到步骤s004或步骤s005之前对该节点及/或该边分别设定权重的步骤。
[0085]
《《使用文本形成图的实例》》在此,参照图4a至图4c、图5a至图5c、图6a至图6d以及图7a至图7c说明使用文本形成图的实例。
[0086]
首先,以使用日文的文本,即“氧化物半导体层在绝缘体层上方(sankabutsuhandoutaisou ha zetsuentaisou no jouhou ni aru)”(参照图4a)为例进行说明。此外,图4b、图4c及图5a所示的圆角四边形表示标记,圆角四边形下方附上对该标记赋予的词类。
[0087]
首先,通过对上述文本进行语素分析,将上述文本分割成标记。注意,也可以对各标记赋予词类(图3所示的步骤s021)。其结果是,得到图4b所示的结果。具体而言,上述文本被分割成标记,即
““
氧化(sanka)”(名词)|“物(butsu)”(名词)|“半导体(handoutai)”(名
词)|“层(sou)”(名词)|“(ha)”(助词)|“绝缘(zetsuen)”(名词)|“体(tai)”(名词)|“层(sou)”(名词)|“(no)”(助词)|“上方(jouhou)”(名词)|“(ni)”(助词)|“在(aru)”(动词)”,并且对各标记赋予词类。
[0088]
接着,进行依存分析(图3所示的步骤s022。具体而言,“氧化(sanka)”及“物(butsu)”、“物(butsu)”及“半导体(handoutai)”、“半导体(handoutai)”及“层(sou)”都满足上述步骤s022所提到的条件。因此,四个标记(“氧化(sanka)”、“物(butsu)”、“半导体(handoutai)”、“层(sou)”)结合而被置换成一个标记(“氧化物半导体层(sankabutsuhandoutaisou)”)。此外,“绝缘(zetsuen)”及“体(tai)”、“体(tai)”及“层(sou)”都满足上述步骤s022所提到的条件。因此,三个标记(“绝缘(zetsuen)”、“体(tai)”、“层(sou)”)结合而被置换成一个标记(“绝缘体层(zetsuentaisou)”)。由此,上述文本成为
““
氧化物半导体层(sankabutsuhandoutaisou)”(名词)|“(ha)”(助词)|“绝缘体层(zetsuentaisou)”(名词)|“(no)”(助词)|“上方(jouhou)”(名词)|“(ni)”(助词)|“在(aru)”(动词)”(参照图4c)。
[0089]
接着,使标记抽象化(图3所示的步骤s023)。具体而言,“氧化物半导体层(sankabutsuhandoutaisou)”被置换成上位词,即“半导体(handoutai)”。此外,“绝缘体层(zetsuentaisou)”被置换成上位词,即“绝缘体(zetsuentai)”。此外,“上方(jouhou)”被置换成代表词,即“上(ue)”。由此,上述文本被抽象化而成为
““
半导体(handoutai)”(名词)|“(ha)”(助词)|“绝缘体(zetsuentai)”(名词)|“(no)”(助词)|“上(ue)”(名词)|“(ni)”(助词)|“在(aru)”(动词)”(参照图5a)。
[0090]
接着,构建图(图3所示的步骤s024)。具体而言,“半导体(handoutai)”及“绝缘体(zetsuentai)”各自成为图的节点及该节点的标签,“上(ue)”成为图的边及该边的标签。其结果是,可以从上述文本得到图5b所示的图。
[0091]
在此,“上(ue)”的反义词为“下(shita)”。于是,也可以使图5b所示的图结构的边的方向(箭头所示的方向)反转,并将图5b所示的图的边及该边的标签,即“上(ue)”置换成“下(shita)”,以重新构建图5c所示的图。由此,可以囊括实质上相同的结构。
[0092]
图5b所示的边的方向(箭头所示的方向)如下:从文本中先出现的节点(在上述文本中相当于“半导体(handoutai)”)至后出现的节点(在上述文本中相当于“绝缘体(zetsuentai)”)。也就是说,边的起点(箭头的起点)为先出现的节点,边的终点(箭头的终点)为后出现的节点。注意,本实施方式不局限于此。例如,也可以根据位置关系等单词间的意义关系而决定边的方向(箭头所示的方向)。具体而言,也可以形成一种图,其中边的起点(箭头的起点)是标签为“绝缘体(zetsuentai)”的节点,边的终点(箭头的终点)是标签为“半导体(handoutai)”的节点,这些节点间的边及该边的标签为“上(ue)”。由此,可以直觉地把握图。注意,决定边的方向(箭头所示的方向)的方法需要在文档检索方法中统一。
[0093]
如上所述,可以从上述文本形成被抽象化的图。
[0094]
接着,以使用英文的文本,即“a semiconductor device comprising:an oxide semiconductor layer over an insulator layer.”(参照图6a)为例进行说明。此外,图6c、图6d及图7a所示的圆角四边形表示标记。在此,示出标记不被赋予词类的例子,但是也可以对标记赋予词类。
[0095]
首先,对上述文本进行清理处理。在此,删除分号。其结果是,得到图6b所示的结
果。
[0096]
接着,通过对上述文本进行语素分析,将上述文本分割成标记(图3所示的步骤s021)。其结果是,上述文本成为“a|semiconductor|device|comprising|an|oxide|semiconductor|layer|over|an|insulator|layer”(参照图6c)。
[0097]
接着,进行依存分析(图3所示的步骤s022)。具体而言,三个标记(“a”、“semiconductor”、“device”)结合而被置换成一个标记(“a semiconductor device”)。此外,四个标记(“an”、“oxide”、“semiconductor”、“layer”)结合而被置换成一个标记(“an oxide semiconductor layer”)。此外,三个标记(“an”、“insulator”、“layer”)结合而被置换成一个标记(“an insulator layer”)。由此,上述文本成为“a semiconductor device|comprising|an oxide semiconductor layer|over|an insulator layer”(参照图6d)。
[0098]
接着,使标记抽象化(图3所示的步骤s023)。具体而言,“a semiconductor device”被置换成上位词,即“device”。此外,“an oxide semiconductor layer”被置换成上位词,即“a semiconductor”。此外,“an insulator layer”被置换成上位词,即“an insulator”。由此,上述文本被抽象化而成为“device|comprising|a semiconductor|over|an insulator”(参照图7a)。
[0099]
接着,构建图(图3所示的步骤s024)。具体而言,“deveice”、“semiconductor”及“insulator”各自成为图的节点及该节点的标签,“comprising”及“over”各自成为图的边及该边的标签。其结果是,可以从上述文本得到图7b所示的图。
[0100]
在此,“over”的反义词为“under”。于是,也可以使图7b所示的图的边的方向(箭头)反转,并将图7b所示的图结构的边及该边的标签,即“over”置换成“under”,以重新构建图7c所示的图。由此,可以囊括实质上相同的结构。
[0101]
图7b所示的边的方向(箭头所示的方向)如下:从文本中先出现的节点(在上述文本中相当于“semiconductor”)至后出现的节点(在上述文本中相当于“insulator”)。也就是说,边的起点(箭头的起点)为先出现的节点,边的终点(箭头的终点)为后出现的节点。注意,本实施方式不局限于此。例如,也可以根据位置关系等单词间的意义关系而决定边的方向(箭头所示的方向)。具体而言,也可以形成一种图,其中边的起点(箭头的起点)是标签为“insulator”的节点,边的终点(箭头的终点)是标签为“semiconductor”的节点,这些节点间的边及该边的标签为“over”。由此,可以直觉地把握图。注意,决定边的方向(箭头所示的方向)的方法需要在文档检索方法中统一。
[0102]
如上所述,可以从上述文本形成被抽象化的图。
[0103]
虽然到此以使用日文的文本及使用英文的文本为例说明使用文本形成图的步骤,但是文本的语言不局限于日文及英文。经同样步骤,也可以用使用如中文、韩文、德文、法文、俄文或天城文等语言的文本形成图。
[0104]
[步骤s003]在步骤s003中,取得一个或多个参考文档。一个或多个参考文档是作为检索对象的文档,储存在存储部107中。
[0105]
在参考文档为专利申请范围或权利要求的情况下,也可以在转到步骤s004之前对参考文档中的文本进行上述清理处理。通过进行该清理处理,可以提高语素分析的准确度。此外,在参考文档不是专利申请范围也不是权利要求的情况下,也可以根据需要适当地进
行上述清理处理。
[0106]
在此,为了简化下面说明,图8示出图21的一个例子。
[0107]
图8所示的图21为有向图。图21由节点群(节点22_1至节点22_n(n为2以上的整数))和边群(边23_1至边23_m(m为1以上且小于n的整数))构成。各节点22_1至节点22_n的入度与出度之和优选为1以上。
[0108]
边23_1的起点为节点22_1,边23_1的终点为节点22_2。另外,边23_2的起点为节点22_2,边23_2的终点为节点22_3。另外,边23_m的起点为节点22_n-1,边23_m的终点为节点22_n。另外,边23_3至边23_m-1都是上述节点群中的一个与上述节点群中的另一个的边。
[0109]
在图8中,在节点22_1与节点22_n-1之间有通过一个以上的节点的路径(path)。换言之,在图8中省略节点22_1与节点22_n-1之间的一个以上的节点及与其有关的边。
[0110]
图21也可以利用集合表示。例如,假设图21(g)由顶点集合v和边集合e构成。此时,顶点集合v及边集合e各自被表示为如下算式(参照算式1)。
[0111]
[算式1]g=(e,v)v={22_1,22_2,22_3,
…
,22_n-1,22_n}e={23_1,23_2,
…
,23_m}
[0112]
注意,顶点集合v具有n个要素,边集合e具有m个要素。
[0113]
上面利用集合(顶点集合v及边集合e)表示图21(g),但不局限于此。图21也可以利用矩阵表示。作为该矩阵,例如可以举出邻接矩阵、关联矩阵、次数矩阵等。图21的邻接矩阵由n
×
n矩阵表示。另外,图21的关联矩阵由n
×
m矩阵表示。
[0114]
在本说明书等中,有时将由边23_1至边23_m中的任一个边、作为该边的起点的节点和作为该边的终点的节点构成的图称为图21的局部图。图21的局部图的形成个数与边数相等。也就是说,m个图21的局部图存在。以下,有时将m个图21的局部图记作图21的局部图群。或者,有时将其记作局部图24_1至局部图24_m。另外,有时将图21的局部图记作检索局部图、查询局部图等。
[0115]
[步骤s004]在步骤s004中,在处理部106中分析参考文档。以下,参照图9说明示出分析参考文档的工序的一个例子的流程图。注意,假设参考文档由句子41_1至句子41_p(p为1以上的整数)构成。
[0116]
分析参考文档的工序包括图9所示的步骤s031至步骤s034。注意,从句子41_1开始分析参考文档即可。
[0117]
[步骤s031]在步骤s031中,判断句子41_pp(pp为1以上且p以下的整数)是否满足条件a。在此,满足条件a的情况是句子41_pp包括单词32a_1至单词32a_n中的两个的情况。在此,单词32a_i(i为1以上且n以下的整数)是指构成图21的节点22_i、节点22_i的相关词或节点22_i的下位词。也就是说,在单词32a_i是节点22_i的相关词或节点22_i的下位词的情况下,被抽象化的单词32a_i与节点22_i一致。
[0118]
作为相关词,可以举出同义词、近义词、反义词、代表词、上位词、下位词等。在本说明书中,将相关词定义为同义词、近义词、反义词、代表词等。此外,下位词是指相当于代表
词的下位概念的代表词。作为相关词及下位词可以参照概念词典等。
[0119]
例如,参照图4c及图5a进行说明,在将“半导体”设为上位词的情况下,“半导体”的下位词有“氧化物半导体”、“硅半导体”等。另外,“氧化物半导体”的相关词有“氧化物半导体层”、“氧化物半导体膜”、“结晶氧化物半导体”、“多晶氧化物半导体”等。另外,“硅半导体”有“硅半导体层”、“硅半导体膜”、“单晶硅”、“氢化非晶硅(有时记为a-si:h)”等。另外,“氧化物半导体”的下位词有“含有铟、镓及锌的氧化物(有时记为igzo等)”、“含有铟及锌的氧化物(有时记为izo等)”等。
[0120]
在句子41_pp包括单词32a_1至单词32a_n中的一个或不包括单词32a_1至单词32a_n的所有单词的情况下,判断句子41_pp不满足条件a。此时,转到下个句子(句子41_pp 1)的分析。
[0121]
在句子41_pp包括单词32a_i1(i1为1以上且n以下的整数)及单词32a_i2(i2为不是i1的1以上且n以下的整数)的情况下,判断句子41_pp满足条件a。此时,可以从句子41_pp取得单词32a_i1及单词32a_i2。在判断句子41_pp满足条件a时,转到步骤s032。
[0122]
[步骤s032]在步骤s032中,判断是否能够从句子41_pp取得成为单词32a_i1及单词32a_i2的边的单词。以下,将成为单词32a_i1及单词32a_i2的边的单词记为单词33a。在能够取得单词33a的情况下,在取得单词32a_i1、单词32a_i2及单词33a之后转到步骤s033。注意,通过进行步骤s021及步骤s022取得单词32a_i1、单词32a_i2及单词33a,即可。通过对句子41_pp进行步骤s021及步骤s022,可以根据句子41_pp准备标记并知道该标记之间的关系。在不能够从句子41_pp取得单词33a的情况下,转到下个句子(句子41_pp 1)的分析。
[0123]
[步骤s033]在步骤s033中,使单词32a_i1、单词32a_i2及单词33a抽象化。注意,使单词32a_i1、单词32a_i2及单词33a抽象化的工序是与步骤s023同样的工序。因此,使单词32a_i1、单词32a_i2及单词33a抽象化的工序可以参照步骤s023的说明。在此,将被抽象化的单词32a_i1、被抽象化的单词32a_i2及被抽象化的单词33a分别记为节点32_i1、节点32_i2及边33。节点32_i1及节点32_i2分别与节点22_i1及节点22_i2一致。在使单词32a_i1、单词32a_i2及单词33a抽象化之后转到步骤s034。
[0124]
[步骤s034]在步骤s034中,判断边33是否满足条件b。在此,满足条件b的情况是边33与构成图21的节点22_i1和节点22_i2的边一致的情况。换言之,满足条件b的情况是从句子41_pp抽出的由节点32_i1、节点32_i2及边33构成的图为图21的局部图或导出子图的情况。
[0125]
此外,也可以对句子41_pp设定旗标(flag)。例如,在判断满足条件b的情况下,立起句子41_pp的旗标即可。另一方面,在判断不满足条件b的情况下,倒下句子41_pp的旗标即可。
[0126]
由此,结束是否满足条件b的判断。在该判断后,转到下个句子(句子41_pp 1)的分析。
[0127]
对句子41_1至句子41_p的所有句子进行判断是否满足条件a的工序至判断是否满足条件b的工序。在句子41_p的分析结束后,转到下个参考文档的分析。
[0128]
分析参考文档的工序不局限于图9的流程图。例如,也可以采用图10的流程图。在
图10的流程图中,从参考文档中检索可形成局部图24_1至局部图24_m的句子。
[0129]
局部图24_mm(mm为1以上且m以下的整数)由两个节点及该两个节点间的边构成。在此,将该两个节点中的一方、该两个节点中的一方的相关词及该两个节点中的一方的下位词总记为单词群22a_m1(m1为1以上且n以下的整数)。另外,将该两个节点中的另一方、该两个节点中的另一方的相关词及该两个节点中的另一方的下位词总记为单词群22a_m2(m2为不是m1的1以上且n以下的整数)。另外,将该边、该边的相关词及该边的下位词总记为单词群23a_mm。也就是说,可形成局部图24_mm的句子至少包括单词群22a_m1中的任一个、单词群22a_m2中的任一个及单词群23a_mm中的任一个。
[0130]
图10所示的分析参考文档的工序包括步骤s041。注意,从局部图24_1开始分析参考文档即可。
[0131]
[步骤s041]在步骤s041中,判断句子41_pp是否满足条件d。在此,满足条件d的情况是句子41_pp包括单词群22a_m1中的任一个、单词群22a_m2中的任一个及单词群23a_mm中的任一个的情况。
[0132]
在判断句子41_pp满足条件d的情况下,转到下个局部图(局部图24_mm 1)。
[0133]
另一方面,在判断句子41_pp不满足条件d的情况下,对句子41_pp 1进行同样的判断。在判断句子41_1至句子41_p都不满足条件d的情况下,转到下个局部图(局部图24_mm 1)。
[0134]
此外,也可以对句子41_pp设定旗标。例如,在判断满足条件d的情况下,立起句子41_pp的旗标即可。另一方面,在判断不满足条件d的情况下,倒下句子41_pp的旗标即可。
[0135]
对局部图24_1至局部图24_m的所有局部图进行上述判断。在局部图24_m的判断结束后,转到下个参考文档的分析。
[0136]
以上说明了示出与图9的流程图不同的参考文档分析的一个例子的流程图。
[0137]
注意,也可以从上述参考文档形成顶点集合vr及边集合er。例如,将满足条件b的边及与该边连接的节点分别追加到边集合er及顶点集合vr,即可。注意,在该边已包括在边集合er中的情况下,也可以不追加该边。另外,在该节点已包括在顶点集合vr中的情况下,也可以不追加该节点。由此,边集合er成为满足条件b的边的并集。另外,顶点集合vr成为与满足条件b的边连接的节点的并集。
[0138]
对上述的一个例子进行说明。假设如下情况:在参考文档中确认了两个满足条件b的句子;从两个句子中的一方抽出与节点22_1一致的节点、与节点22_2一致的节点及与边23_1一致的边;从两个句子中的另一方抽出与节点22_n-1一致的节点、与节点22_n一致的节点及与边23_m一致的边。此时,顶点集合vr由节点22_1、节点22_2、节点22_n-1及节点22_n构成。另外,边集合er由边23_1及边23_m构成。
[0139]
由此,可以分析参考文档。在对所有参考文档进行到上述分析后,转到步骤s005。
[0140]
[步骤s005]在步骤s005中,在处理部106中评估参考文档。具体而言,根据文本20与参考文档的相似度对该参考文档的得分赋予分数并算出该参考文档的得分。
[0141]
以下说明对参考文档的得分赋予分数的基准以及根据该基准对参考文档的得分赋予的分数的一个例子。
[0142]
《《赋予分数的基准1》》在可从参考文档抽出的节点及边中构成图21的节点及边越多,将越高的分数赋予到该参考文档。在此,将根据基准1赋予到参考文档的得分的分数记为分数61。
[0143]
例如,根据包括在图21的局部图群(局部图24_1至局部图24_m)中的可从参考文档形成的子图数算出分数61即可。具体而言,也可以根据在可形成各局部图24_1至局部图24_m的m个句子中参考文档所包括的句子数s与图21的局部图群数m之比(记为包括率)算出分数61。在此,包括率为(s/m)。
[0144]
注意,s可以为参考文档所包括的句子41_1至句子41_p中的满足上述条件b的句子数,也可以为参考文档所包括的句子41_1至句子41_p中的满足上述条件d的句子数。
[0145]
此时,在可形成各局部图24_1至局部图24_m的m个句子都包括在参考文档中的情况下,该包括率为1。另外,在可形成各局部图24_1至局部图24_m的m个句子都不包括在参考文档中的情况下,该包括率为0。因此,将该包括率与权重x1之积作为分数61赋予到参考文档的得分即可。
[0146]
另外,例如也可以根据可从参考文档抽出的边与构成图21的边的一致率算出分数61。具体而言,也可以根据边集合er和图21的边集合e的共同部分数与边集合e的要素个数之比(记为一致率)算出分数61。在此,一致率为(t/m)。
[0147]
在此,t为在步骤s004中形成的边集合er和图21的边集合e的共同部分数。另外,m为边集合e的要素个数|e|。此时,该一致率的最大值为1,其最小值为0。因此,将该一致率与权重x2之积作为分数61赋予到参考文档的得分即可。
[0148]
权重x1或权重x2可以预先被指定,也可以被用户指定。另外,用户在转到步骤s005之前指定权重x1或权重x2即可。例如,可以在输入文本20的时序指定,也可以在进行步骤s002之后指定。
[0149]
注意,示出了使用上述包括率或上述一致率算出分数61的例子,但不局限于该方法。例如,分数61可以根据图21的邻接矩阵与从顶点集合vr形成的邻接矩阵之frobenius内积(也称为矩阵内积)算出,也可以根据图21的关联矩阵与从顶点集合vr及边集合er形成的关联矩阵之内积算出。
[0150]
《《赋予分数的基准2》》在参考文档中出现图21所包括的节点及边的句子之间的距离越近,将越高的分数赋予到该参考文档的得分。例如,根据出现图21所包括的节点及边的句子与出现图21所包括的节点及边的另一个句子之距离算出该分数即可。另外,使用在步骤s004中设定的旗标算出该距离即可。在此,将根据基准2赋予到参考文档的得分的分数记为分数62。
[0151]
将出现图21所包括的节点及边的句子设为句子41_p1(p1为1以上且p以下的整数),将出现图21所包括的节点及边的另一个句子设为句子41_p2(p2为不是p1的1以上且p以下的整数)。具体而言,将句子41_p1与句子41_p2之距离r设为(|p1-p2|-1)。也就是说,在句子41_p1与句子41_p2相邻的情况下,r为0。另外,句子41_p1离句子41_p2最远的情况下,r为(p-2)。
[0152]
鉴于此,算出值(p-2-r)/(p-2)。在句子41_p1与句子41_p2相邻的情况下,值(p-2-r)/(p-2)为1,在句子41_p1离句子41_p2最远的情况下,值(p-2-r)/(p-2)为0。因此,将值(p-2-r)/(p-2)与权重y之积作为分数62赋予到参考文档的得分即可。
[0153]
权重y可以预先被指定,也可以被用户指定。另外,用户在转到步骤s005之前指定权重y即可。例如,可以在输入文本20的时序指定,也可以在进行步骤s002之后指定。
[0154]
注意,出现节点及边的句子与出现节点及边的另一个句子之距离的算出方法不局限于上述方法。例如,在图21为有向图的情况下,关于入度与出度之和为2以上的节点,也可以算出可抽出该节点和相邻于该节点的节点之间的边的句子与可抽出该节点和相邻于该节点的另一个节点之间的边的句子之距离。
[0155]
《《赋予分数的基准3》》从参考文档中的文本取得的被抽象化之前的节点及边越近似于构成图21的被抽象化之前的节点及边,将越高的分数赋予到该参考文档的得分。例如,评估从参考文档中的文本取得的被抽象化之前的节点(边)与构成图21的被抽象化之前的节点(边)的关系来决定赋予的分数即可。在此,将根据基准3赋予到参考文档的得分的分数记为分数63。
[0156]
如上所述,抽象化是将标记置换成代表词或上位词的工作。也就是说,被抽象化之前的节点是被置换成上位词或代表词之前的标记,即转到步骤s023之前的标记。换言之,被抽象化之前的节点是出现在上述参考文档中的文本中的单词本身。
[0157]
在此,说明从参考文档中的文本取得单词32a_i3(i3为1以上且n以下的整数)的情况。注意,使单词32a_i3抽象化而得的节点32_i3与图21的节点22_i3一致。另外,将被抽象化之前的节点22_i3记为单词22a_i3。单词22a_i3为出现在文本20中的单词。
[0158]
例如,在单词32a_i3与单词22a_i3一致的情况下,该参考文档与文本20相似的可能性高。因此,可以看作该参考文档近似于文本20的概念。此时,提高赋予到该参考文档的得分的分数63。
[0159]
在单词32a_i3不与单词22a_i3一致的情况下,该参考文档与文本20相似的可能性低。因此,可以看作该参考文档远离文本20的概念。此时,降低赋予到该参考文档的得分的分数63或将该分数63降低到0。根据单词32a_i3与单词22a_i3的关系调整赋予到该参考文档的得分的分数63即可。
[0160]
在此,将表示单词32a_i3与单词22a_i3的关系的值设为r2。值r2根据以单词22a_i3为准时的单词32a_i3的位置算出。在此,参照图11说明值r2的算出方法的一个例子。
[0161]
图11是说明单词的相关的图。如图11所示,单词a1和单词a2为单词a0的下位词。单词a1和单词a2为彼此的相关词。单词a11和单词a12为单词a1的下位词。单词a11和单词a12为彼此的相关词。单词a21和单词a22为单词a2的下位词。单词a21和单词a22为彼此的相关词。
[0162]
在此,如图11所示,联结单词与该单词的上位词。另外,联结单词与该单词的下位词。此时,可以将图11所示的单词(单词a0、单词a1、单词a2、单词a11、单词a12、单词a21及单词a22)看作图的节点。另外,可以将连接单词之间的线看作该图的边。
[0163]
将单词a0与单词a1之距离设为w1。将单词a0与单词a2之距离设为w2。将单词a1与单词a11之距离设为w11。将单词a1与单词a12之距离设为w12。将单词a2与单词a21之距离设为w21。将单词a2与单词a22之距离设为w22。
[0164]
假设单词22a_i3为图11所示的单词a1。另外,将单词32a_i3至单词22a_i3的最短路径距离设为w。单词32a_i3至单词22a_i3的最短路径是指在连接单词32a_i3与单词22a_i3的路径中边数最小的路径。也就是说,该最短路径的距离是相当于在该最短路径中存在
的边的距离之和。
[0165]
在单词32a_i3与单词22a_i3一致的情况下,w为0。在单词32a_i3为单词22a_i3的上位词(图11所示的单词a0)的情况下,w为w1。在单词32a_i3为单词22a_i3的下位词(图11所示的单词a11或单词a12)的情况下,w为w11或w12。在单词32a_i3为单词22a_i3的相关词(图11所示的单词a2)的情况下,w为w1 w2。在单词32a_i3为单词22a_i3的相关词的下位词(图11所示的单词a21或a22)的情况下,w为w1 w2 w21或w1 w2 w22。
[0166]
由1/(1 w)算出值r2即可。由此,在单词32a_i3与单词22a_i3一致的情况下值r2为1,在单词32a_i3至单词22a_i3的最短路径距离最大的情况下值r2为最小值。
[0167]
或者,也可以由(wmax-w)/wmax算出值r2。在此,wmax为单词32a_i3至单词22a_i3的最短路径距离的最大值。由此,在单词32a_i3与单词22a_i3一致的情况下值r2为1,在单词32a_i3至单词22a_i3的最短路径距离最大的情况下值r2为0。
[0168]
将通过上述方法算出的值r2与权重z1之积作为分数63赋予到参考文档的得分即可。
[0169]
单词间距离(距离w1、距离w2、距离w11、距离w12、距离w21及距离w22)可以预先被指定,也可以被用户指定。另外,用户在转到步骤s005之前指定单词间距离即可。例如,可以在输入文本20的时序指定,也可以在进行步骤s002之后指定。
[0170]
关于边也以与上述方法同样的方法决定赋予到参考文档的得分的分数63即可。例如,分数63为值r2与权重z2之积即可。
[0171]
注意,在图21为有向图的情况下,边具有方向。因此,在从参考文档中的句子取得的边的方向与图21的边的方向相同的情况下,可以看作该边近似于被抽象化之前的图21的概念。此时,提高赋予到该参考文档的得分的分数63即可。另一方面,在从参考文档中的句子抽出的边的方向与图21的边的方向相反的情况下,可以看作该边远离被抽象化之前的图21的概念。此时,降低赋予到该参考文档的得分的分数63或将该分数63降低到0即可。
[0172]
权重z1及权重z2可以预先被指定,也可以被用户指定。另外,用户在转到步骤s005之前指定权重z1及权重z2即可。例如,可以在输入文本20的时序指定,也可以在进行步骤s002之后指定。
[0173]
《《赋予分数的基准4》》在节点及边为图21的上位概念或下位概念的情况下,根据检索条件对参考文档的得分赋予分数。例如,调整图11所示的单词间距离(距离w1、距离w2、距离w11、距离w12、距离w21及距离w22)的值即可。在此,将根据基准4赋予到参考文档的得分的分数记为分数64。
[0174]
在想要检索作为图21的上位概念的文档的情况下,将距离w11及距离w12设为无穷大或与其他单词间距离(例如为距离w1)的值相比极大的值。由此,可以使赋予到作为图21的下位概念的参考文档的得分的分数64的值几乎为0。因此,可以提高图21的上位概念的参考文档的检索性。另外,也可以将距离w2、或者距离w21及距离w22设为无穷大或与其他单词间距离(例如为距离w1)的值相比极大的值。由此,可以进一步提高图21的上位概念的参考文档的检索性。
[0175]
在想要检索作为图21的下位概念的文档的情况下,将距离w1设为无穷大或与其他单词间距离(例如为距离w11)的值相比极大的值。由此,可以使赋予到作为图21的上位概念的参考文档的得分的分数64的值几乎为0。因此,可以提高图21的下位概念的参考文档的检
索性。
[0176]
由此,可以根据检索条件高效地检索文档。
[0177]
以上说明了对参考文档的得分赋予分数的基准以及根据该基准对参考文档的得分赋予的分数的一个例子。注意,作为对参考文档的得分赋予的分数,适当地组合上述基准1至基准4中的一个或多个即可。另外,对参考文档的得分赋予的分数的基准不局限于上述基准,适当地设置条件来算出参考文档的得分即可。
[0178]
《《算出参考文档的得分的例子》》在此,参照图12a、图12b、图13a及图13b说明算出参考文档的得分的例子。为了便于说明,在本项中使用具有图12a所示的结构的图21a。另外,假设作为检索对象的参考文档为四个(参考文档40a、参考文档40b、参考文档40c及参考文档40d)。
[0179]
假设参考文档40a至参考文档40d都由10个句子构成。也就是说,假设参考文档40a至参考文档40d的p都为10。此时,参考文档40a由句子41a_1至句子41a_10构成,参考文档40b由句子41b_1至句子41b_10构成,参考文档40c由句子41c_1至句子41c_10构成,参考文档40d由句子41d_1至句子41d_10构成。
[0180]
图12a所示的图21a是图21的另一个例子。图21a由节点22_1至节点22_4以及边23_1至边23_3构成。边23_1的起点为节点22_1,边23_1的终点为节点22_2。边23_2的起点为节点22_2,边23_2的终点为节点22_3。边23_3的起点为节点22_1,边23_3的终点为节点22_4。
[0181]
另外,图12a所示的局部图24_1、局部图24_2及局部图24_3都是图21a的局部图,也是图21a的子图。局部图24_1由节点22_1、节点22_2及边23_1构成。局部图24_2由节点22_2、节点22_3及边23_2构成。局部图24_3由节点22_1、节点22_4及边23_3构成。
[0182]
另外,将可形成局部图24_1的句子设为句子30_1。也就是说,可以使用从句子30_1抽出的单词形成局部图24_1。另外,将可形成局部图24_2的句子设为句子30_2。也就是说,可以使用从句子30_2抽出的单词形成局部图24_2。另外,将可形成局部图24_3的句子设为句子30_3。也就是说,可以使用从句子30_3抽出的单词形成局部图24_3。
[0183]
如图12b所示,假设参考文档40a包括句子30_1至句子30_3。在参考文档40a所包括的句子中,句子41a_5相当于句子30_1,句子41a_6相当于句子30_2,句子41a_8相当于句子30_3。
[0184]
另外,如图12b所示,假设参考文档40b包括句子30_1及句子30_2并不包括句子30_3。在参考文档40b所包括的句子中,句子41b_5相当于句子30_1,句子41b_6相当于句子30_2。
[0185]
另外,如图12b所示,假设参考文档40c包括句子30_1及句子30_2并不包括句子30_3。在参考文档40c所包括的句子中,句子41c_2相当于句子30_1,句子41c_6相当于句子30_2。
[0186]
另外,如图12b所示,假设参考文档40d包括句子30_1并不包括句子30_2及句子30_3。在参考文档40d所包括的句子中,句子41d_2相当于句子30_1。
[0187]
另外,按被评估的参考文档数适当地调整根据各基准算出的值(包括率、值(p-2-r)/(p-2)、值r2等)、权重(权重x1、权重y1及权重z1)、赋予的分数等的有效数字(有效数字的最后一位)。例如,被评估的参考文档数越多,使该有效数字越大或者使该有效数字的最后一位越小,即可。在此,该有效数字的最后一位为小数点第二位。
[0188]
首先,参照图12b说明根据上述基准1对参考文档40a至参考文档40d的各得分赋予分数61的例子。注意,权重x1为1.00。
[0189]
参考文档40a的上述包括率(以及赋予的分数61)为1.00。另外,参考文档40b及参考文档40c的上述包括率(以及赋予的分数61)为0.67(=2/3)。另外,参考文档40d的上述包括率(以及赋予的分数61)为0.33(=1/3)。因此,在四个参考文档中,对参考文档40a的得分赋予的分数61最高,对参考文档40b及参考文档40c的得分赋予的分数61第二高,对参考文档40d的得分赋予的分数61最低。
[0190]
接着,参照图13a说明根据上述基准2对参考文档40a至参考文档40d的各得分赋予分数62的例子。注意,权重y为1.00。
[0191]
在参考文档40a及参考文档40b中,句子30_1与句子30_2之距离r为0。因此,值(p-2-r)/(p-2)(以及赋予的分数62)为1.00。另外,在参考文档40c中,句子30_1与句子30_2之距离r为3。因此,值(p-2-r)/(p-2)(以及赋予的分数62)为0.63(=5/8)。因此,对参考文档40b的得分赋予的分数62比对参考文档40c的得分赋予的分数62高。注意,在参考文档40d中不能算出句子30_1与句子30_2之距离r,所以值(p-2-r)/(p-2)(以及赋予的分数62)为0.00。
[0192]
接着,参照图13b说明根据上述基准3及基准4对参考文档40a至参考文档40d的各得分赋予分数63及分数64(分数64a或分数64b)的例子。具体而言,说明根据参考文档40a至参考文档40d的每一个所包括的句子30_1算出对参考文档的得分赋予的分数63及分数64的方法。注意,权重z1为1.00。另外,由1/(1 w)算出值r2。
[0193]
在此,假设从句子30_1抽出单词32a_1。假设被抽象化的单词32a_1与节点22_1一致。在此,将被抽象化之前的节点22_1设为单词22a_1。单词22a_1为出现在文本20中的单词。另外,单词22a_1为图11所示的单词a1。
[0194]
如图13b所示,假设从参考文档40a取得的单词32a_1为图11所示的单词a1。假设从参考文档40b取得的单词32a_1为图11所示的单词a11。假设从参考文档40c取得的单词32a_1为图11所示的单词a0。从参考文档40d取得的单词32a_1为图11所示的单词a22。
[0195]
在上述情况下,参考文档40a的w为0,参考文档40b的w为w11,参考文档40c的w为w1,参考文档40d的w为w1 w2 w22。
[0196]
首先,将图11所示的单词间距离(距离w1、距离w2、距离w11、距离w12、距离w21及距离w22)都设为1.00。在此,对参考文档赋予的分数为分数63。
[0197]
此时,参考文档40a的值r2为1.00,参考文档40b的值r2为0.50(=1/2),参考文档40c的值r2为0.50(=1/2),参考文档40d的值r2为0.25(=1/4)。
[0198]
如上所述,在四个参考文档中,对参考文档40a的得分赋予的分数63最高,对参考文档40b及参考文档40c的得分赋予的分数63第二高,对参考文档40d的得分赋予的分数63最低。
[0199]
通过将单词间距离都设为1,可以提高近似于文本20的概念的参考文档的得分。
[0200]
接着,将距离w1、距离w21及距离w22设为1.00,将距离w2、距离w11及距离w12设为无穷大。在此,对参考文档赋予的分数为分数64a。
[0201]
此时,参考文档40a的值r2为1.00,参考文档40b的值r2实质上为0,参考文档40c的值r2为0.50(=1/2),参考文档40d的值r2实质上为0。
[0202]
如上所述,在四个参考文档中,对参考文档40a的得分赋予的分数64a最高,对参考文档40c的得分赋予的分数64a第二高,对参考文档40b及参考文档40d的得分赋予的分数64a最低。
[0203]
通过作为单词间距离采用上述设定,可以提高近似于文本20的上位概念的参考文档的得分。
[0204]
接着,将距离w2、距离w11、距离w12、距离w21及距离w22设为1.00,将距离w1设为无穷大。在此,对参考文档赋予的分数为分数64b。
[0205]
此时,参考文档40a的值r2为1.00,参考文档40b的值r2为0.50(=1/2),参考文档40c的值r2实质上为0,参考文档40d的值r2实质上为0。
[0206]
如上所述,在四个参考文档中,对参考文档40a的得分赋予的分数64b最高,对参考文档40b的得分赋予的分数64b第二高,对参考文档40c及参考文档40d的得分赋予的分数64b最低。
[0207]
通过作为单词间距离采用上述设定,可以提高近似于文本20的下位概念的参考文档的得分。
[0208]
由此,可以算出参考文档的得分。
[0209]
在此,在权重x1、权重y及权重z1都为1.00的前提下进行说明,但不局限于此。例如,当想要关注在文本20中使用的单词检索文档时,使权重z1的值大于权重x1及权重y的值即可。例如,当想要关注图21a的边检索文档时,使权重x1及/或权重y的值大于权重z1的值即可。
[0210]
以上说明了步骤s005。通过进行步骤s005,根据文本20与参考文档的相似度分数被赋予到该参考文档的得分。因此,参考文档的得分越高,该参考文档与文本20的相似度越高。由此,可以检索与文本20相似的文档。
[0211]
通过上述方法可以检索文档。注意,文档检索方法不局限于上述方法。例如,如图14所示,文档检索方法除了步骤s001至步骤s005之外还可以包括步骤s011及步骤s012。
[0212]
[步骤s011]在步骤s011中,筛选参考文档。该步骤在步骤s003与步骤s004之间进行。以下,参照图15说明筛选在步骤s003中取得的多个参考文档(参考文档40_1至参考文档40_q(q为1以上的整数))的流程图。
[0213]
步骤s011从参考文档40_1开始即可。
[0214]
判断参考文档40_qq(qq为1以上且q以下的整数)是否满足条件c。在此,满足条件c的情况是参考文档40_qq包括在步骤s004中说明的单词32a_1至单词32a_n的全部的情况。
[0215]
在判断参考文档40_qq满足条件c的情况下,抽出参考文档40_qq。在判断参考文档40_qq不满足条件c的情况下,不抽出参考文档40_qq。
[0216]
注意,条件c不局限于上述条件。例如,满足条件c的情况也可以是参考文档40_qq包括在步骤s004中说明的单词32a_1至单词32a_n的一部分的情况。由此,可以根据该单词32a_1至单词32a_n的一部分检索相似文档。
[0217]
由此,结束是否满足条件c的判断。在该判断后,转到下个参考文档(参考文档40_qq 1)的分析。
[0218]
对参考文档40_1至参考文档40_q的全部进行判断是否满足条件c的工序。在参考
文档40_q的筛选结束后,转到步骤s004。
[0219]
通过进行步骤s011,可以从多个参考文档中仅抽出与文本20相似的参考文档。由此,可以筛选出与文本20对比的参考文档,而可以缩短文档检索所需的时间。
[0220]
[步骤s012]在步骤s012中,在输出部104中输出信息。该信息是指在处理部106中计算出的结果的有关信息。例如,该信息是参考文档的得分。或者,该信息是得分最高的参考文档。或者,该信息是根据得分被排序的排序数据。
[0221]
上述信息例如作为字符串、数值、图表等视觉信息或听觉信息等被输出到输出部104。另外,上述信息也可以被输出到存储部107、处理部106所包括的存储器等。
[0222]
以上说明了文档检索方法。通过使用作为本发明的一个方式的文档检索方法,可以考虑到为检索而指定的文本的概念检索到与该文本相似的文档。此外,可以在排序状态下检索到与为检索而指定的文本相似的文档。此外,可以根据文本的概念进行检索,而不易于受文本的结构或表现的影响。另外,在语言不同的两个文本之间,在文本具有相同的概念时,使用该两个文本各自形成的图为相同的。因此,通过使用作为本发明的一个方式的文档检索方法,可以容易在不同语言之间检索文档。
[0223]
根据本发明的一个方式,可以提供一种考虑到文档的概念的文档检索方法。
[0224]
本实施方式可以与其他实施方式适当地组合。此外,在本说明书中,在一个实施方式中示出多个结构例子的情况下,可以适当地组合该结构例子。
[0225]
(实施方式2)在本实施方式中,对于本发明的一个方式的文档检索系统,参照图16及图17进行说明。
[0226]
本实施方式的文档检索系统可以使用实施方式1所示的文档检索方法从文档容易检索且取得所需的信息。
[0227]
《文档检索系统的结构例子1》图16示出文档检索系统200的方框图。注意,本说明书的附图示出在独立的方框中根据其功能进行分类的构成要素,但是,实际的构成要素难以根据功能被清楚地划分,一个构成要素有时具有多个功能。此外,一个功能有时涉及到多个构成要素,例如,在处理部202中进行的各处理有时在不同的服务器中进行。
[0228]
文档检索系统200至少包括处理部202。图16所示的文档检索系统200还包括输入部201、存储部203、数据库204、显示部205及传送通道206。
[0229]
[输入部201]输入部201从文档检索系统200的外部被供应文本。该文本是检索文本,相当于实施方式1所示的文本20。此外,输入部201也可以从文档检索系统200的外部被供应多个参考文档。该多个参考文档是作为上述文本的对比对象的文档,相当于实施方式1所示的多个参考文档。被供应到输入部201的上述多个参考文档和上述文本都通过传送通道206被供应到处理部202、存储部203或数据库204。
[0230]
上述多个参考文档及上述文本例如作为文本数据、音频数据或图像数据被输入。包括在上述多个参考文档的每一个中的文本优选作为文本数据被输入。
[0231]
作为上述文本的输入方法,例如可以举出使用键盘、触摸面板等的键盘输入、使用
麦克风的音频输入、从记录介质的读取、使用扫描器、照相机等的图像输入、使用通信的取得等。
[0232]
文档检索系统200也可以具有将音频数据转换为文本数据的功能。例如,处理部202也可以具有该功能。或者,文档检索系统200也可以还包括具有该功能的音频转换部。
[0233]
文档检索系统200也可以具有光学文字识别(ocr)的功能。由此,能够识别图像数据所包括的文字来生成文本数据。例如,处理部202也可以具有该功能。或者,文档检索系统200也可以还包括具有该功能的文字识别部。
[0234]
[处理部202]处理部202具有使用从输入部201、存储部203、数据库204等被供应的数据进行处理的功能。处理部202可以将处理结果供应给存储部203、数据库204、显示部205等。
[0235]
处理部202包括实施方式1所示的处理部106。也就是说,处理部202具有进行语素分析的功能、进行依存分析的功能、进行抽象化的功能以及形成图的功能。处理部202具有分析参考文档的功能及评估参考文档的功能。
[0236]
处理部202也可以使用在沟道形成区域中包含金属氧化物的晶体管。由于该晶体管的关态电流极小,所以通过将该晶体管用作保持流入被用作存储元件的电容器的电荷(数据)的开关,可以确保长期的数据保持期间。通过将该特性应用于处理部202所包括的寄存器及高速缓冲存储器中的至少一个,可以仅在必要时使处理部202工作,而在其他情况下使之前的处理信息储存在该存储元件,可以使处理部202成为关闭状态。换言之,可以实现常闭运算(normally off computing),由此可以实现文档检索系统的低功耗化。
[0237]
此外,在本说明书等中,将在沟道形成区域中使用氧化物半导体的晶体管称为oxide semiconductor晶体管或os晶体管。os晶体管的沟道形成区域优选包含金属氧化物。
[0238]
沟道形成区域所具有的金属氧化物优选包含铟(in)。在沟道形成区域所具有的金属氧化物包含铟的情况下,os晶体管的载流子迁移率(电子迁移率)得到提高。此外,沟道形成区域所具有的金属氧化物优选包含元素m。元素m优选是铝(al)、镓(ga)或锡(sn)。作为可用作元素m的其他元素,有硼(b)、钛(ti)、铁(fe)、镍(ni)、锗(ge)、钇(y)、锆(zr)、钼(mo)、镧(la)、铈(ce)、钕(nd)、铪(hf)、钽(ta)、钨(w)等。注意,作为元素m有时也可以组合多个上述元素。元素m例如是与氧的键能高的元素。元素m例如是与氧的键能高于铟的元素。此外,沟道形成区域所具有的金属氧化物优选包含锌(zn)。包含锌的金属氧化物有时容易晶化。
[0239]
沟道形成区域所具有的金属氧化物不局限于包含铟的金属氧化物。沟道形成区域所具有的金属氧化物例如也可以是锌锡氧化物或镓锡氧化物等不包含铟且包含锌的金属氧化物、包含镓的金属氧化物或包含锡的金属氧化物等。
[0240]
此外,也可以将沟道形成区域中含有硅的晶体管用于处理部202。
[0241]
此外,作为处理部202,优选组合使用在沟道形成区域中包含氧化物半导体的晶体管和在沟道形成区域中包含硅的晶体管。
[0242]
处理部202例如包括运算电路或中央处理器(cpu:central processing unit)等。
[0243]
处理部202也可以包括dsp(digital signal processor:数字信号处理器)、gpu(graphics processing unit:图形处理器)等微处理器。微处理器也可以由fpga(field programmable gate array:现场可编程门阵列)、fpaa(field programmable analog array:现场可编程模拟阵列)等pld(programmable logic device:可编程逻辑器件)实现。
处理部202通过由处理器解释且执行来自各种程序的指令,可以进行各种数据处理及程序控制。可由处理器执行的程序储存在处理器所包括的存储器区域及存储部203中的至少一个。
[0244]
处理部202也可以包括主存储器。主存储器包括ram等易失性存储器及rom等非易失性存储器中的至少一个。
[0245]
作为ram,例如使用dram(dynamic random access memory:动态随机存取存储器)、sram(static random access memory:静态随机存取存储器)等,该ram分配有虚拟存储空间作为处理部202的工作空间,并用于处理部202。储存在存储部203中的操作系统、应用程序、程序模块、程序数据及查找表等在执行时被加载于ram中。处理部202直接存取并操作被加载于ram中的这些数据、程序及程序模块。
[0246]
rom可以储存不需要改写的bios(basic input/output system:基本输入/输出系统)及固件等。作为rom,可以举出掩模rom、otprom(one time programmable read only memory:初次可编程只读存储器)、eprom(erasable programmable read only memory:可擦除可编程只读存储器)等。作为eprom,可以举出通过紫外线照射可以消除存储数据的uv-eprom(ultra-violet erasable programmable read only memory:紫外线-可擦除可编程只读存储器)、eeprom(electrically erasable programmable read only memory:电子式可抹除可编程只读存储器)、快闪存储器等。
[0247]
[存储部203]存储部203具有储存处理部202执行的程序的功能。此外,存储部203例如也可以具有储存处理部202所生成的处理结果以及输入到输入部201的数据等的功能。具体而言,优选存储部203具有储存处理部202生成的图(例如,实施方式1所示的图21)、计算出的得分的结果等的功能。
[0248]
存储部203包括易失性存储器及非易失性存储器中的至少一个。存储部203例如可以包括dram、sram等易失性存储器。存储部203例如也可以包括以reram(resistive random access memory:电阻随机存取存储器,也称为阻变式存储器)、pram(phase-change random access memory:相变随机存取存储器)、feram(ferroelectric random access memory:铁电随机存取存储器)、mram(magnetoresistive random access memory:磁阻随机存取存储器,也称为磁阻式存储器)或快闪存储器等非易失性存储器。此外,存储部203也可以包括硬盘驱动器(hard disc drive:hdd)及固态驱动器(solid state drive:ssd)等记录介质驱动器。
[0249]
[数据库204]文档检索系统200也可以包括数据库204。例如,数据库204具有储存多个参考文档的功能。例如,也可以以数据库204所储存的该多个参考文档为对象使用本发明的一个方式的文档检索方法。此外,数据库204也可以储存概念词典。
[0250]
此外,存储部203及数据库204也可以彼此不分离。例如,文档检索系统200也可以包括具有存储部203及数据库204的双方的功能的存储单元。
[0251]
此外,处理部202、存储部203及数据库204所包括的存储器都被称为非暂时性计算机可读存储介质的一个例子。
[0252]
[显示部205]
显示部205具有显示处理部202中的处理结果的功能。此外,显示部205具有显示参考文档及对于该参考文档算出的得分的结果的功能。此外,显示部205也可以具有显示检索文本的功能。
[0253]
此外,文档检索系统200也可以包括输出部。输出部具有向外部供应数据的功能。
[0254]
[传送通道206]传送通道206具有将各种数据传送的功能。输入部201、处理部202、存储部203、数据库204及显示部205间的数据的收发可以通过传送通道206进行。例如,检索文本、作为该文本的对比对象的参考文档等的数据通过传送通道206被收发。
[0255]
《文档检索系统的结构例子2》图17示出文档检索系统210的方框图。文档检索系统210包括服务器220及终端230(个人计算机等)。
[0256]
服务器220包括处理部202、传送通道212、存储部213以及通信部217a。虽然在图17中未图示,但是服务器220也可以还包括输入输出部等。
[0257]
终端230包括输入部201、存储部203、显示部205、传送通道216、通信部217b以及处理部218。虽然在图17中未图示,但是终端230也可以还包括数据库等。
[0258]
文档检索系统210的用户向终端230的输入部201输入文本。该文本是检索文本,相当于实施方式1所示的文本20。该文本从终端230的通信部217b传送到服务器220的通信部217a。
[0259]
通信部217a所接收的上述文本通过传送通道212储存在存储部213中。或者,上述文本也可以从通信部217a直接被供应到处理部202。
[0260]
实施方式1所说明的图形成和参考文档分析及评估都需要较高处理能力。与终端230所包括的处理部218相比,服务器220所包括的处理部202的处理能力较高。因此,图形成和参考文档分析及评估优选都在处理部202中进行。
[0261]
然后,由处理部202算出得分。得分通过传送通道212储存在存储部213中。或者,得分也可以从处理部202直接被供应到通信部217a。得分从服务器220的通信部217a传送到终端230的通信部217b。得分显示在终端230的显示部205上。
[0262]
[传送通道212及传送通道216]传送通道212及传送通道216具有传送数据的功能。处理部202、存储部213及通信部217a间的数据的收发可以通过传送通道212进行。输入部201、存储部203、显示部205、通信部217b及处理部218间的数据的收发可以通过传送通道216进行。
[0263]
[处理部202及处理部218]处理部202具有使用从存储部213及通信部217a等供应的数据进行处理的功能。处理部218具有使用从输入部201、存储部203、显示部205及通信部217b等供应的数据进行处理的功能。处理部202及处理部218可以参照处理部202的说明。处理部202的处理能力优选高于处理部218。
[0264]
[存储部203]存储部203具有储存处理部218执行的程序的功能。此外,存储部203具有储存处理部218所生成的运算结果、输入到通信部217b的数据及输入到输入部201的数据等的功能。
[0265]
[存储部213]
存储部213具有储存多个参考文档、处理部202所生成的处理结果及输入到通信部217a的数据等的功能。
[0266]
[通信部217a及通信部217b]通过使用通信部217a及通信部217b可以在服务器220与终端230间进行数据的收发。作为通信部217a及通信部217b可以使用集线器(hub)、路由器、调制解调器等。数据的收发可以以有线或无线(例如,电波、红外线等)进行。
[0267]
此外,服务器220与终端230的通信可以通过连接为world wide web(www)的基盘的互联网、内联网、外联网、pan(personal area network:个域网)、lan(local area network:局域网)、can(campus area network:校园网)、man(metropolitan area network:城域网)、wan(wide area network:广域网)、gan(global area network:全球区域网络)等计算机网络来进行。
[0268]
本实施方式可以与其他实施方式适当地组合。[符号说明]
[0269]
a0:单词、a1:单词、a2:单词、a11:单词、a12:单词、a21:单词、a22:单词、r2:值、w1:距离、w2:距离、w11:距离、w12:距离、w21:距离、w22:距离、20:文本、21:图、21a:图、22_i:节点、22_i1:节点、22_i2:节点、22_i3:节点、22_n:节点、22_n-1:节点、22_1:节点、22_2:节点、22_3:节点、22_4:节点、22a_i3:单词、22a_m1:单词群、22a_m2:单词群、22a_1:单词、23_m:边、23_m-1:边、23_1:边、23_2:边、23_3:边、23a_mm:单词群、24_m:局部图、24_mm:局部图、24_1:局部图、24_2:局部图、24_3:局部图、30_1:句子、30_2:句子、30_3:句子、32_i1:节点、32_i2:节点、32_i3:节点、32a_i:单词、32a_i1:单词、32a_i2:单词、32a_i3:单词、32a_n:单词、32a_1:单词、33:边、33a:单词、40_q:参考文档、40_qq:参考文档、40_1:参考文档、40a:参考文档、40b:参考文档、40c:参考文档、40d:参考文档、41_p:句子、41_p1:句子、41_p2:句子、41_pp:句子、41_1:句子、41a_1:句子、41a_5:句子、41a_6:句子、41a_8:句子、41a_10:句子、41b_1:句子、41b_5:句子、41b_6:句子、41b_10:句子、41c_1:句子、41c_2:句子、41c_6:句子、41c_10:句子、41d_1:句子、41d_2:句子、41d_10:句子、61:分数、62:分数、63:分数、64:分数、64a:分数、64b:分数、100:文档检索系统、101:输入部、104:输出部、106:处理部、107:存储部、112:概念词典、200:文档检索系统、201:输入部、202:处理部、203:存储部、204:数据库、205:显示部、206:传送通道、210:文档检索系统、212:传送通道、213:存储部、216:传送通道、217a:通信部、217b:通信部、218:处理部、220:服务器、230:终端。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。