1.本发明涉及图像处理领域的医学图像分割技术,特别涉及一种基于全分辨率表示网络的医学图像分割方法。
背景技术:
2.医学图像分割在计算机辅助诊断中起着关键作用,其目的是提取图像中感兴趣的区域,如组织,器官,病理学和生物结构等。目前流行的分割任务包括细胞分割、皮肤损伤分割、肺分割和心脏分割等。在通常的实践中,分割由领域专家手动执行,这种人工操作既费时又费力。随着医学成像技术的发展,医学图像的样本量和多样性快速增加,且感兴趣区域的形状和尺寸多变,手动分割已经不能满足实际需求。因此,开发自动、准确和鲁棒的医学图像分割方法具有重要意义。
3.最近,基于深度学习的方法在图像分类、目标检测和语义分割等领域取得了令人满意的结果。就语义分割任务而言,最先进的方法依赖于完全卷积网络的编码器-解码器体系结构。例如u型网络(u-net)利用编码器网络学习高级语义表示,解码器从高级表示中恢复丢失的空间信息。同时,跳跃连接用于重复使用高分辨率的特征映射和进行多尺度特征融合。此后,人们提出了各种改进方法来解决各种分割问题。deeplab系列通过空洞卷积和池化操作来扩大感受野并聚合多尺度信息。一些工作引入内置的深度可变的u-net集合并重新设计跳跃连接实现更灵活的特征融合。通过增强编码器和解码器的特征表示能力以及利用自注意力机制产生更具分辨性的特征表示,对输入特征的远程依赖性进行建模是提高模型分割性能的方法。尽管这些方法已被证明有利于图像分割,但是下采样会丢失纹理信息,使用不同大小的空洞卷积不利于特征的一致性。此外,基于transformer的方法通常在大规模数据集的训练下才能很好地工作,而医学数据集中可用于训练的图像数量往往相对较少。
4.综上所述,减少特征信息的丢失,融合多尺度特征以及在较小数据集上表现出良好的性能是医学图像分割亟待解决的关键问题。
技术实现要素:
5.针对上述问题,本发明的目的在于实现基于全分辨率表示网络的医学图像分割方法,学习图像的全分辨率表示,建立不同图像块之间的长期依赖关系,实现不同分支的多尺度信息融合。技术方案如下:
6.一种基于全分辨率表示网络的医学图像分割方法,包括以下步骤:
7.步骤1)挑选公开的医学图像分割数据集,并对数据集中的训练集进行预处理;
8.步骤2)构建图像块卷积模块对图像块的局部特征进行挖掘;
9.步骤3)构建特征重建模块实现对图像块的多尺度融合,完成全分辨率表示网络两个分支的相互转换;
10.步骤4)构建多层感知器模块建模图像块之间的长期依赖关系;
11.步骤5)设计由图像块卷积模块、特征重建模块、多层感知器模块三个部分组成图像分割框架,实现医学图像的分割。
12.进一步的,所述步骤1)中,所述步骤1)中数据集分别为:kaggle 2018 data science bowl,retinal lmages vessel tree extraction和gland segmentation;对数据集中的训练集进行预处理为:将所有图像调整为216
×
216像素大小的图像块。
13.更进一步的,所述步骤2)构建图像块卷积模块对图像块的局部特征进行挖掘具体过程如下:
14.步骤2.1)将图像块卷积模块的输入特征映射表示为:
15.m
in
∈r
n,c,h,w
16.其中,n为批量大小,c表示通道数量,h和w分别为图像的高度和宽度;
17.步骤2.2)将m
in
划分为一系列大小为(h/2i,w/2i)和(h/3
i-1
,w/3
i-1
)的图像块,i表示该模块的阶段数,i≥0;所述图像块的数量随阶段数增加而逐渐增多,且分辨率为上一阶段的1/2或1/3;划分成图像块的操作通过以下三步完成:
18.①
将m
in
∈rn×c×h×w重建为(n,c,2i,h/2i,2i,w/2i)大小;
19.②
重新将轴的顺序排列为(n,2i,2i,c,h/2i,w/2i)大小;
20.③
最后将(n,c,2i,h/2i,2i,w/2i)重建为
21.步骤2.3)将每个图像块按照通道的维度排列,并用一组具有残差连接的共享卷积作用于m
p
,输出结果m
conv
,用以下公式表示:
[0022][0023]
其中,n表示图像块数量,[
……
]表示沿通道方向拼接,c为卷积的输出通道数,k为卷积核大小,d是扩张率,随循环次数增大为原来的两倍,p为要填充的像素数;m
p
表示对输入特征图的重建结果,表示对第n个图像块输入特征图的重建结果;
[0024]
步骤2.4)使用层归一化对m
conv
进行规范化得到局部特征图像块
[0025]
更进一步的,所述步骤3)中特征重建模块的处理过程如下:
[0026]
步骤3.1)将图像块卷积模块的输出的局部特征图像块作为特征重建模块的输入,取两个局部特征图像块和
[0027]
步骤3.2)将局部特征图像块和的张量互相转换得到和
[0028]
步骤3.3)分别将上述得到的四个张量两两进行逐元素相加,即和得到多尺度融合图像块和
[0029]
更进一步的,所述步骤4)中多层感知器模块包括两个多层感知器层和非线性层,第一个多层感知器层作用于经空间维度平均池化后的图像块,用于学习不同图像块投影维度之间的联系,第二个多层感知器层作用于通道维度平均池化后的图像块,用于学习图像
块之间的长程依赖关系;处理过程如下:
[0030]
步骤4.1)利用空间维度全局平均池化聚合输入张量的空间信息,空间池化后的张量为
[0031]
步骤4.2)将张量m
sap
经过trans 1变换输入到第一个多层感知器层中:
[0032]mtrans1
=permute(up(m
sap
))
[0033]
其中,up(m
sap
)表示将m
sap
中的图像块按照原始图像的像素分布进行上采样,即然后重塑张量后得到形状为的m
trans1
;
[0034]
步骤4.3)利用trans 1的逆向操作将非线性层之后的特征图还原并与输入特征图跳跃连接;
[0035]
步骤4.4)利用通道维度的全局平均池化聚合输入张量的通道信息,即
[0036]
步骤4.5)将m
cap
通过trans 2变换为的张量,其每一行均包含一个图像块的所有信息;
[0037]
步骤4.6)使用跳跃连接将非线性层的输出与输入结果做哈达玛乘积得到多层感知器模块的输出特征。
[0038]
更进一步的,所述步骤5)具体包括:
[0039]
步骤5.1)所述图像分割框架中的全分辨率表示网络包括两个并行子网络,其中包括四个阶段:
[0040]
第0阶段利用核为7
×
7的卷积和一个图像块卷积模块提取输入图像的特征;从第1阶段开始到第3阶段,使用图像块卷积模块、特征重建模块和多层感知器模块以进行并行路径的多尺度特征融合以及产生丰富的全分辨率表示;还完成跳跃连接和层归一化;
[0041]
步骤5.2)定义四个阶段定义:
[0042]
用si和s
′i表示两个不同分支子网络的第i阶段,m
in
为输入特征,则第0、1阶段的结果为:
[0043]
s0=patchconv(bn(conv7×7(m
in
)))
[0044]s′1=patchconv(bn(conv7×7(s0)))
[0045]
s1=mlp(patchconv(s0) frb(s
′1))
[0046]
式中,patchconv表示图像块卷积模块处理;bn表示批量归一化处理;conv7×7表示核为7
×
7的卷积操作;mlp表示多层感知器模块处理;frb表示特征重建模块处理;
[0047]
从第2阶段开始,连续的网络模块计算如下:
[0048]
si=mlp(patchconv(s
i-1
) patchconv(frb(s
′
i-1
)))
[0049]s′i=mlp(patchconv(frb(s
i-1
)) patchconv(s
′
i-1
))
[0050]
上式中i∈[2,
…
,i],i表示可扩展最大阶段数。
[0051]
采用上述技术方案带来的有益效果:
[0052]
1)本发明设计一种基于全分辨率表示网络的医学图像分割方法。该网络在整个过程中始终保持全分辨率表示,从而避免了图像分割过程中下采样丢失图像细节信息的问题。
[0053]
2)本发明不同于传统的浅层和深层特征融合的方法,通过在相同深度(阶段)执行多尺度融合以提高不同阶段的全分辨率表示,使得在每个阶段都具有相同通道数的情况下仍然保持了较好的分割性能。
[0054]
3)本发明提出由两个并行子网络构成的框架,不同于有跳跃连接的对称编码器-解码器体系结构,避免因为反复的下采样和上采样操作丢失图像的细节信息。通过在不同尺度的双分支编码器中集成图像块卷积模块和特征重建模块来提取丰富的局部特征,从而捕获重要的全局上下文信息。
[0055]
4)本发明使用图像块卷积模块、特征重建模块和多层感知器模块以进行并行路径的多尺度特征融合以及产生丰富的全分辨率表示。通过图像块卷积模块中以挖掘图像块的局部特征,用于反复多尺度融合特征重建模块以及多层感知器模块以建模图像块之间的长期依赖关系;在特征重建模块和多层感知器模块处理过程中,始终学习的是图像的全分辨率表示,进一步细化局部特征,符合人类对图像的视觉感知。
附图说明:
[0056]
图1为本发明的图像块卷积模块。
[0057]
图2为本发明的特征重建模块。
[0058]
图3为本发明的多层感知器模块。
[0059]
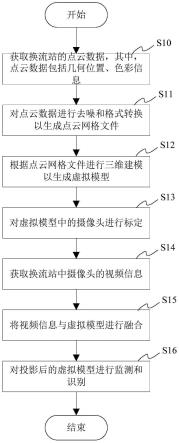
图4为本发明的基于全分辨率表示网络的医学图像分割方法的流程图。
具体实施方式
[0060]
下面将结合本发明中的附图,对本发明中的技术方案做进一步详细说明。
[0061]
本发明设计了一种基于全分辨率表示网络的医学图像分割方法。首先,将原始分辨率图像按照不同阶段划分为不同尺寸的图像块,利用现代卷积神经网络中高效灵活的元件(例如空洞卷积和残差连接)提取从大尺寸到小尺寸图像块的局部特征;其次,设计了一种用于显式建模图像块之间长期依赖关系的多层感知器模块,以弥补卷积运算造成的固有感应偏差;此外,进行多次多尺度融合,使得每个阶段接收来自并行路径的表示信息,从而产生丰富的全分辨率表示。
[0062]
本发明在不同的医学图像分割任务上评估了所提出的方法,在多个数据集上与最新的深度学习分割方法(包括基于cnn和基于transformer的架构)相比取得了具有竞争力的性能。本发明为基于全分辨率表示的研究提供一种改进思路。
[0063]
步骤1:挑选公开的医学图像分割数据集,并对数据集进行预处理。
[0064]
对训练集进行预处理的具体实施如下:
[0065]
本发明在三个公开的生物医学图像分割数据集上进行分割训练任务,对于所有数据集均采用5折交叉验证方法进行训练。其中数据集分别为:kaggle 2018 data science bowl(nuclei),retinal lmages vessel tree extraction(rite)和gland segmentation(glas)。
[0066]
nuclei数据集由博思艾伦基金会(booz allen foundation)提供,包含670张细胞核特征图,并为每张图像提供一个标签。训练过程中将不同分辨率的图像和相应的标签调整为216
×
216。
[0067]
rite数据集可以对视网膜眼底图像上的动脉和静脉的分割或分类进行比较研究,该数据集是基于公共可用的drive数据库建立的,包含40组图像,分辨率统一为565
×
584,对于每组,有一张眼底照片、一个血管参考标准和一个动脉/静脉(a/v)参考标准。考虑到该数据集的分割目标比较离散,直接将大分辨率图像大小调整为较小分辨率(216
×
216或224
×
224)的图像可能会影响原始图像的质量,先将原始图像大小调整为432
×
432的分辨率,然后按照四个角进行裁剪得到四张分辨率为216
×
216的图像。一方面尽可能保留了原始图像的质量,另一方面将数据扩充为原来的四倍,即数据总量为160张图像。
[0068]
glas数据集包含苏木精和伊红(hematoxylin and eosin)染色玻片的显微图像,以及专家病理学家提供的相应标注。它共包含165幅图像,最小分辨率为433
×
574,最大分辨率为775
×
522。与第一个数据集相同,在训练和测试过程中将图像的分辨率统一调整为216
×
216。
[0069]
步骤2:采用图像块卷积模块对图像块的局部特征进行挖掘,每个图像块按照通道的维度排列,参考图1为本发明的图像块卷积模块。
[0070]
1)该模块的输入特征映射表示为:
[0071]min
∈r
n,c,h,w
[0072]
其中,n为批量大小,c表示通道数量,h和w分别为高度和宽度。
[0073]
2)将m
in
划分为一系列大小为(h/2i,w/2i)和(h/3
i-1
,w/3
i-1
)的图像块,i表示该模块阶段数(i≥0)。这些图像块的数量逐渐增多,且分辨率为上一阶段的1/2或1/3。
[0074]
3)划分成图像块的操作不会在内存中移动数据且不进行训练,可以通过以下三步完成(以下均以第一个分支举例):
[0075]
①
将m
in
∈rn×c×h×w重建为(n,c,2i,h/2i,2i,w/2i)大小;
[0076]
②
重新将轴的顺序排列为(n,2i,2i,c,h/2i,w/2i)大小;
[0077]
③
最后将(n,c,2i,h/2i,2i,w/2i)重建为
[0078]
4)将每个图像块按照通道的维度排列,并用一组具有残差连接的共享卷积作用于m
p
,输出结果m
conv
,用以下公式表示:
[0079][0080]
其中,n表示图像块数量,[
……
]表示沿通道方向拼接,c为卷积的输出通道数,k为卷积核大小,d是扩张率,随循环次数增大为原来的两倍,p为要填充的像素数;m
p
表示对输入特征图的重建结果,表示对第n个图像块输入特征图的重建结果。
[0081]
5)使用层归一化对m
conv
进行规范化得到局部特征图像块不使用传统的批量标准化是因为它会破坏图像的整体信息,导致分割精度降低。上述操作可以理解为在空间维度上的分组卷积,本专利将卷积的注意力聚焦于每个图像块,这有助于挖掘图像块的局部信息,同时不会引起计算量的增加。
[0082]
步骤3:采用特征重建模块实现对图像块的多尺度融合,完成网络两个分支的相互转换。随着网络深度变深,每个图像块的分辨率也逐渐变小,局部特征被进一步细化,这符合人类对图像的视觉感知,因为人们总是先关注较大的区域,然后将注意力转向较小且感
兴趣的区域。此外,由于两个分支图像块的尺寸不同,本专利在相同深度融合了不同尺度的信息,与浅层和深层特征融合的方式相比可以获得尺度互补信息,参考图2为本发明的特征重建模块。
[0083]
1)将建图像块卷积模块的输出的局部特征图像块作为特征重建模块的输入,取两个局部特征图像块和
[0084]
2)为了方便特征融合,将局部特征图像块和张量互相转换得到和
[0085]
3)分别对上述得到的四个张量两两进行逐元素相加,即和得到多尺度融合图像块和
[0086]
步骤4:多层感知器模块主要由两个多层感知器层和非线性层组成,第一个多层感知器层作用于经空间维度平均池化后的图像块,用于学习不同图像块投影维度之间的联系,第二个多层感知器层作用于经通道维度平均池化后的图像块,用于学习图像块之间的长程关系,参考图3为本发明的多层感知器模块。
[0087]
1)利用空间维度全局平均池化聚合输入张量,利用空间维度全局平均池化聚合输入张量的空间信息,空间池化(sap)后的张量为
[0088]
2)将m
sap
经过以下变换(“trans 1”)输入到多层感知器层mlp1中:
[0089]mtrans1
=permute(up(m
sap
))
[0090]
其中,up与传统的插值算法不同,本专利将m
sap
中的图像块按照原始图像的像素分布进行上采样,即然后重塑张量得到形状为的m
trans1
。以上变换是无代价的,且多层感知器层的输入和输出保持一致。与直接在原始图像或原始输入特征上进行线性映射相比,所需要的计算量从hwc2减少到p2c2。
[0091]
3)利用“trans 1”的逆向操作将非线性层(relu)之后的特征图还原并与输入特征图跳跃连接。
[0092]
4)利用通道维度的全局平均池化(cap)聚合输入张量的通道信息,即
[0093]
5)将m
cap
(即“trans 2”操作)变换为的张量,它的每一行都包含了一个图像块的所有信息。
[0094]
6)使用跳跃连接将relu层的结果与输入结果做哈达玛乘积得到多层感知器模块的输出特征。
[0095]
步骤5:设计由图像块卷积模块、特征重建模块、多层感知器模块三个部分组成图像分割框架,参考图4为本发明的基于全分辨率表示网络的医学图像分割方法的流程图。
[0096]
1)该框架由三种模块组成:
[0097]
采用图像块卷积模块挖掘图像块的局部特征,用于反复多尺度融合的特征重建模块以及多层感知器模块以建模图像块之间的长期依赖关系。本专利不同于有跳跃连接的对称编码器-解码器体系结构,因为反复的下采样和上采样操作会丢失图像的细节信息。通过在不同尺度的双分支编码器中集成图像块卷积模块和多层感知器模块,不仅可以提取丰富
的局部特征,而且还可以捕获重要的全局上下文信息。此外,本专利在基础网络大型模型2rnet-b的基础上还设计了微型2rnet-t,小型2rnet-s和巨大2rnet-l,这些实例的复杂性越来越高,性能也逐步提升。
[0098]
2)模型架构及超参数设置:
[0099]
本发明在nvidia tesla v100 gpu(32g)上通过训练实现了基于pytorch的方法。使用adam优化器,学习速率固定为1e-4
。批量大小设置为16(f2rnet-l设置为8),在网络的末端采用交叉损失函数。当验证损失稳定且30个epoch内无显著变化时,采用提前停止机制停止训练。通过应用随机旋转(
±
25
°
),随机水平和垂直移位(15%)以及随机翻转(水平和垂直)来扩充训练数据集。
[0100]
3)该框架由两个并行子网络构成的四个阶段(阶段0~阶段3)组成:
[0101]
第0阶段利用核为7
×
7的卷积和图像块卷积模块提取输入图像的特征。从第1阶段到第3阶段,本专利使用图像块卷积模块、特征重建模块和多层感知器模块以进行并行路径的多尺度特征融合以及产生丰富的全分辨率表示。此外还使用其他标准体系结构组件:跳跃连接和层归一化。
[0102]
4)四个阶段定义:
[0103]
用si和s
′i表示两个不同分支的第i阶段,m
in
为输入特征,那么第0、1阶段的结果为:
[0104]
s0=patchconv(bn(conv7×7(m
in
)))
[0105]s′1=patchconv(bn(conv7×7(s0)))
[0106]
s1=mlp(patchconv(s0) frb(s
′1))
[0107]
式中,patchconv表示图像块卷积模块处理;bn表示批量归一化处理;conv7×7表示核为7
×
7的卷积操作;mlp表示多层感知器模块处理;frb表示特征重建模块处理;
[0108]
从第2阶段开始,连续的网络模块计算如下:
[0109]
si=mlp(patchconv(s
i-1
) patchconv(frb(s
′
i-1
)))
[0110]s′i=mlp(patchconv(frb(s
i-1
)) patchconv(s
′
i-1
))
[0111]
上式中i∈[2,
…
,i],i表示可扩展最大阶段数,在本发明中i为3。特征重建模块是为了对齐相同深度不同形状的张量,该模块不产生计算代价。此外,从第0阶段开始允许这些阶段进行多次循环以增加网络的深度,当深度增加时,图像块卷积模块的空洞率是上一次循环的两倍。最后,模型的输出由两个分支共同决定,这两个分支通过哈达玛乘积来汇总特征信息,在预测层前本专利使用一个标准卷积整合两个分支特征。
[0112]
5)基础模型f2rnet-b及变体:
[0113]
f2rnet-b使其模型参数设置与基于resnet的主干网络相似。还设计了f2rnet-t、f2rnet-s和f2rnet-l,这些实例的复杂性越来越高,性能也逐步提升。这些型号变体的架构参数包括:
[0114]
f2rnet-t:c=32, l=1,1,1,1
[0115]
f2rnet-s:c=32,l=1,2,2,2
[0116]
f2rnet-b:c=64,l=1,1,2,2
[0117]
f2rnet-l:c=96, l=1,1,1,2
[0118]
其中,c是第0阶段中特征通道数量,在整个网络中c保持不变。l表示不同阶段的循
环次数。
[0119]
6)模型f2rnet具体实施如下:
[0120]
首先将空间维度上的分组卷积作用于具有金字塔结构的图像块上,以学习图像的局部特征;然后利用基于多层感知架构的多层感知器模块用于增强不同图像块之间的长期依赖关系;最后通过在相同深度进行多尺度特征交互和融合进而产生丰富的全分辨率表示。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。