1.本发明涉及小样本分类领域,尤其是一种基于原型图神经网络的罕见病分类方法。
背景技术:
2.从少量样本中快速学习和概括的能力是人类智力的关键特征,因为人类可以利用从以前的学习经验中获得的先验知识。尽管现在深度学习方法在许多任务中取得了显著的成功,但大量的标记数据很难获得,尤其是在罕见病领域,样本不容易收集。
3.另外,训练还需要大量的时间,原因是每个任务都是独立训练的,模型参数是从零开始学习的,而不包含特定于任务的先验知识。如何利用有限的数据提取先验知识并将其转移到不可见的任务,已经成为最近研究的重点。
4.现有的基于深度学习的罕见病分类方法通常需要大量的数据来优化模型的参数。一旦数据量不足,就很难了解训练样本的内在特征,模型的鲁棒性不是很强,同时缺乏考虑样本和样本之间的关系,对新样本的适应能力很弱,分类的准确性不高。因此面对少量样本问题,网络不仅要关注数据样本本身,还要关注训练样本之间的关系。
技术实现要素:
5.本发明的目的是提供一种能够利用少量罕见病样本数据进行精确分类的方法,该方法利用原型图神经网络及小样本学习方法进行,首先提取出样本的特征计算每个类的“原型点”,然后将样本的低维特征向量及“原型点”带入图神经网络初始化,并依次经过节点特征传播网络、边特征传播网络和标签传播网络进行传播,最后用损失函数进行优化,得到最优原型图神经网络。原型图神经网络可以更好地利用样本之间的关系,使得在罕见病分类方面拥有更好的分类效果。
6.实现本发明目的的具体技术方案是:一种基于原型图神经网络和小样本学习的罕见病分类方法,特点是该方法包括以下具体步骤:步骤1:罕见病人脸数据集收集与划分1.1)采集罕见病人脸图片构成数据集,整个数据集按照8∶2的比例划分成训练集和测试集,训练集和测试集的类别标签不相交;1.2)训练集和测试集均采用n-way k-shot的小样本学习的划分方式划分h次,每次为一个迭代集,每一个迭代集里分为支持集和查询集,支持集里有n个类,每个类k个样本,k大于0,小于等于15;步骤2:样本特征提取2.1)将每个迭代集里的罕见病人脸样本进行二维人脸配准,使用基于haar特征的adaboost级联人脸检测分类器,判断是否有人脸:如果有,则将人的脸部区域截取出来,缩放到84
×
84尺寸,得到预处理样本,避免样本中除人脸以外的因素干扰;否则,重新选择图
片;2.2)取一个迭代集里经过上一步预处理之后的支持集样本和查询集样本,送入嵌入子网络:依次经过一个64滤波器的3
×
3的卷积、一个批归一化层、一个relu非线性层和2
×
2的最大池化,得到每个样本的特征图;2.3)将所有特征图输入到两个分别是8
×
64和1
×
128维的全连接层,得到对应的特征向量,将这些特征向量进行批归一化处理和relu非线性激活,得到样本的低维特征向量;2.4)对一个迭代集里支持集中每个类所有样本的低维特征向量计算平均值,即对每个类中支持集所有样本的低维特征向量求和,除以每个类中支持集的样本数量来计算一个虚拟点,作为这个类在特征空间中的“原型点”;步骤3:原型图神经网络构建3.1)首先进行图神经网络初始化,由步骤2中计算的所有样本的低维特征向量以及“原型点”构造原型图神经网络,节点为样本的低维特征向量和“原型点”,边特征介于0和1之间,表示两个节点属于同一个类的可能性,如果两个节点标签相等,边特征设为1,如果不等,边特征设为0,否则边特征设为0.5;3.2)节点特征更新,首先设置一个节点特征更新网络,将节点特征和边特征输入到节点特征更新网络中,得到更新的节点特征;3.3)边特征更新,节点特征更新后,接下来对边特征更新,设置一个边特征更新网络,将所有更新的节点特征输入到边特征更新网络,得到更新的边特征;3.4)节点标签传播,设置一个节点标签传播网络,将更新的边特征及节点标签输入到节点标签传播网络中,得到更新的节点标签;3.5)经过l次节点特征更新、边特征更新以及节点标签传播后,得到更新后的原型图神经网络;步骤4:标签预测4.1)得到更新后的原型图神经网络之后,查询图像的预测标签根据最大值自变量点集,选择概率值最大的罕见病类作为查询图像的分类预测结果;4.2)设计两个损失函数优化网络参数,其一计算每个查询点与特征空间中对应“原型点”的欧氏距离得到几何正则化损失,其二计算查询集中每个查询点的预测标签和真实标签之间的二元交叉熵损失;由这两个损失函数构造出整个网络最终的损失,进行反向传播,更新原型图神经网络模型参数;4.3)通过测试集计算原型图神经网络模型分类准确度,选择准确度最高的模型参数作为最优模型参数;4.4)分类时,用最优模型参数为原型图神经网络赋值,将待分类罕见病人脸样本作为查询集,罕见病人脸数据集中所有样本作为支持集送入原型图神经网络,网络输出即为分类结果。
7.所述训练集和测试集均采用n-way k-shot的小样本学习的划分方式,是从数据集中随机选择n个类,在这n个类中每个类都随机选择k个样本作为支持集,继续在这n个类的剩余样本中随机选择q个样本作为查询集;这n
×
k q个样本构成一个迭代集。
8.所述设置一个节点特征更新网络,该网络由聚合模块和卷积模块组成,聚合模块,
是指对于每一个当前节点,使用它的所有邻接节点的特征以及对应的标签聚合当前节点特征,使用邻接节点特征除以当前节点标签与邻接节点标签的欧氏距离获得聚合信息;卷积模块是由两个卷积层、批处理归一化层以及relu非线性激活层组成;将聚合信息和当前节点特征一并送入卷积模块中,输出即为当前节点的更新节点特征。
9.所述设置一个边特征更新网络,该网络由四个卷积层、批处理归一化层以及relu非线性激活层组成,网络的输出即为两个节点之间的边特征。
10.所述设置一个节点标签传播网络,该网络由权重更新模块和卷积模块组成,权重更新模块是指对于每一个当前节点标签,首先对它所有邻接节点标签进行重新加权,即当前节点的每一个边特征除以它所有边特征的和,然后与当前节点的所有邻接节点标签相乘,得到所有邻接节点标签的加权更新节点标签;卷积模块是由两个卷积层、批处理归一化层以及relu非线性激活层组成,将当前节点标签与所有加权更新节点标签送入卷积模块中,输出即为当前节点的更新标签,实现标签传播。
11.本发明采用“原型点”的方式构造图神经网络,忽略样本数量的影响,尽管每个类仅有一个点,但对小样本学习而言非常有意义。由于“原型点”的存在,引入几何约束项来补充交叉熵损失,损失函数更可靠。同时鼓励模型更多地关注类内的公共特征,降低过拟合的风险,让模型的鲁棒能力更强。另外一方面,原型图神经网络不仅关注数据样本本身,还要关注样本之间的关系,通过缩短特征空间中的距离将同一类别的点拉到一起,并在完全连通的图神经网络中传播它们的标签,提高小样本学习分类的准确性。
附图说明
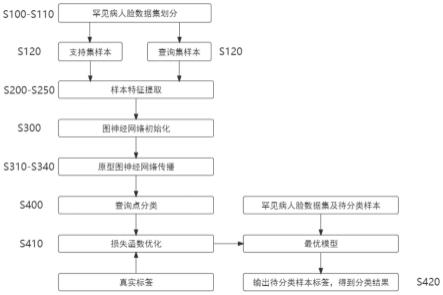
12.图1为本发明实施例罕见病人脸数据集收集与划分流程图;图2为本发明实施例样本特征提取流程图;图3为本发明实施例原型图神经网络构建流程图;图4为本发明实施例流程图。
具体实施方式
13.为了便于理解本发明,以下结合附图及实施例对本发明进行详细说明。
实施例
14.参阅图1,本实施例步骤1首先采集数据集,并划分为训练集和测试集,对训练集和测试集采用元学习的样本划分方式采用20-way 5-shot的形式,具体包括:s100:与医院合作采集罕见病人脸样本构成罕见病人脸数据集,根据病名对人脸样本进行分类并进行统计;s110:将收集好的数据集按照8∶2的比例划分为训练集和测试集,训练集和测试集的类别不交叉;s120:训练集和测试集均采用20-way5-shot的样本划分方式划分100次,每次从数据集中随机选择20个类,在这20个类中每个类都随机选择5个样本作为支持集,继续在这20个类中的剩余样本中随机选择20个样本作为查询集。这120(20
×
5 20)个样本构成一个迭代集。
15.参阅图2,本实施例步骤2中对于迭代集中每个样本,进行罕见病人脸样本预处理。将处理后的图片输入到嵌入子网络中,提取其特征,经过两个全连接层得到特征向量,此后将支持集中每个类样本的特征向量求和取平均作为在特征空间中的“原型点”,具体包括:s210:将每个迭代集里的罕见病人脸样本进行二维人脸配准,使用基于haar特征的adaboost级联人脸检测分类器,判断是否有人脸;如果有,则将人的脸部区域截取出来,缩放到84
×
84尺寸,得到预处理样本,避免样本中除人脸以外的因素干扰;否则,重新选择图片;s220:将当前迭代集经过预处理之后的支持集和查询集样本,依次经过一个64滤波器的3
×
3的卷积、一个批归一化层、一个relu非线性层、2
×
2的最大池化以及分别是8
×
64和1
×
128维的全连接层,然后进行批归一化处理和relu非线性激活,得到每个样本的特征向量;s230、s240:对支持集中每个类所有样本的特征向量求和,除以每个类中支持集的样本数量,得到每个类样本的平均特征向量,即“原型点”。
16.参阅图3,本实施例步骤3中对于数据集中每个样本及计算出的“原型点”,建立原型图神经网络,进行3次(3层)节点特征更新、边特征更新以及节点标签传播得到原型图神经网络,具体包括:s300:将支持集特征向量、“原型点”及查询集特征向量送入图神经网络中作为节点特征进行初始化,同时初始化边特征,相同标签的节点之间的边特征初始化为1,不同标签的节点之间的边特征初始化为0,否则初始为0.5;s310:节点特征更新对于每一个当前节点使用它的所有邻接节点特征以及对应的标签聚合当前节点,使用邻接节点特征除以当前节点标签与邻接节点标签的欧氏距离获得聚合信息,将聚合信息和当前节点特征经过两个卷积层、批处理归一化层以及relu非线性激活层,得到当前节点的更新节点特征;s320:边特征更新是将两个节点特征送入四个卷积层、批处理归一化层以及relu非线性激活层,得到两个节点之间的边特征;s330:节点标签传播对于每一个当前节点标签,首先对它所有邻接节点标签进行重新加权,即当前节点的每一个边特征除以它所有边特征的和,然后与当前节点的所有邻接节点标签相乘,得到所有邻接节点标签的加权更新节点标签。将当前节点标签与所有加权更新节点标签送入两个卷积层、批处理归一化层以及relu非线性激活层,得到当前节点的更新标签,实现标签传播;s340:进行3次节点特征更新、边特征更新以及节点标签传播(即图神经网络有3层)得到更新后的原型图神经网络。
17.参阅图4,本实施例步骤4中通过更新后的原型图对查询集的样本进行分类,并与查询集样本的真实标签进行损失函数的构建,将损失函数反向传播更新模型参数。记录准确度最高的模型参数,并用之对待分类样本进行分类,具体包括:s400:查询图像的预测标签根据节点的最大值自变量点集,选择概率值最大的罕见病类作为它的预测分类标签;s410:计算每个查询点与特征空间中对应“原型点”的欧氏距离得到几何正则化损失,计算查询集中每个查询点的预测分类标签和真实标签之间的二元交叉熵损失。由这两
个损失函数构造出整个网络最终的损失,进行反向传播,更新原型图神经网络模型参数。
18.s420:在100个迭代集的训练过程中,记录最优模型的参数。选择最优模型参数为原型图神经网络赋值,将待分类罕见病人脸样本作为查询集,罕见病人脸数据集中所有样本作为支持集送入原型图神经网络,网络输出即为分类结果。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。