1.本发明涉及在线教育技术领域,具体涉及一种面向在线教育的学习者异常学习状态预测方法。
背景技术:
2.随着现代计算机网络的广泛普及和家用电子设备终端的快速发展,利用计算机网络和人工智能等现代化技术进行在线教育已经成为家庭教育的重要组成部分。2020年在线教育行业市场规模同比增长35.5%,但作为一种远程教育手段,在线教育师生互动少、学习监管难的特性对教学效果造成了不容忽视的负面影响。近年来,在线教育的参与人数和上线课程的逐年增加积累了海量的在线教育学习者注册信息和日志数据,有效地对这些数据进行分析并构建模型实现学习者异常学习状态预测对于教师及时了解学习者的学习情况并给予针对性的指导和监督具有重要意义。
3.现有相关研究主要聚焦于学习不良者发现问题,将学习不良者发现视为一个0/1分类问题(正常学习者和不良学习者),基于学习者注册信息及其学习过程中产生的日志数据提取特征,利用二值化后的学习成绩作为标签,使用监督学习的方法对学习不良者进行预测。以下文献提供了可参考的学习不良者发现问题的技术解决方案:
4.文献1:一种基于校园卡数据的学习不良者预测方法(201910833015.9)。
5.文献2:一种面向网络教育的成绩不良学习者识别方法(201610864980.9)。
6.文献1提出了一种基于校园卡数据的学习不良者预测方法。此方法将学习者的校园卡数据表示为矩阵形式、将学习结果作为标签,并利用卷积神经网络(cnn)和长短期记忆神经网络(lstm)相结合来训练一个判别学习者是否为学习不良者的二分类器。
7.文献2设计了一种面向网络教育的成绩不良学习者识别方法,面向在线教育数据,基于时间窗口和学习时长等构建了高维特征,依据成绩是否大于60分为将训练数据集划分为正例和负例,并利用随机森林算法训练一个二分类器以发现成绩不良者。
8.以上文献方法用于发现学习状态异常的学习者主要存在以下问题:首先,文献1和文献2都针对学习不良者发现问题展开,而在实际应用中,针对具有不同异常程度的学习状态的学习者进行个性化的指导尤为重要,例如,偶然出现和反复出现学习不良行为的学习者需要不同程度的监管和指导方法;其次,某学期或课程的学习结果或考试成绩无法充分反映学习者在学习过程中是否需要进行针对性的监管,考试成绩依赖于课程考题的不同侧重,在考题侧重的部分学习较为认真的同学会得到更高的分数,这导致学习成绩并不能充分反映学习者当前教学部分的学习状态;在在线教育中,教师希望在任何教学部分出现学习状态异常的学习者都可以及时被发现并提供针对性指导,因此直接将学习成绩作为训练标签衡量全过程学习状态引入了标签噪声;同时,文献1和文献2挖掘学习者画像特征或时序表征进行学习,缺乏对特征不同视角的关注同样使得其难以基于多视角特征展开标签消歧以解决噪声问题。而想要获得准确的不良学习状态及其程度标签需要大量的人工标注成本,如何基于已有学习成绩和多视角特征构造标签以更准确地评价学习者的各阶段异常学
习状态及其程度已经成为一个亟待解决的问题。
技术实现要素:
9.本发明的目的在于提供一种面向在线教育的学习者异常学习状态预测方法,以解决现有技术中存在的问题。
10.为达到以上目的,本发明采取以下技术方案来实现的:
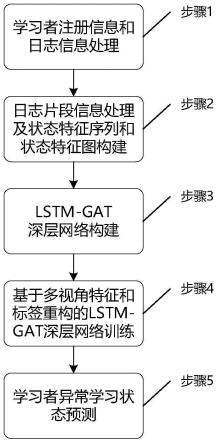
11.一种面向在线教育的学习者异常学习状态预测方法,包括:
12.首先,将高维在线教育平台日志信息和学习者注册信息进行预处理并基于自监督学习方法编码构建学习者画像特征;其次,基于时间窗口对学习者日志信息分片并分别编码构建学习者状态特征,进而基于状态特征的产生时序构建状态特征序列,基于状态特征间的余弦相似度构造状态特征图;再次,构建符合在线教育的学习不良程度预测的长短时记忆-图注意力lstm-gat深层网络,基于所构造的学习者状态特征、状态特征序列和状态特征图来确定网络的层数、每层的神经元个数以及输入输出的维度;从次,以映射至[0,1]的学习成绩作为噪声标签,基于噪声标签构造伪标签以对网络进行迭代训练,每次迭代首先基于多视角特征及伪标签优化网络,随后基于状态特征的时序局部连续性、空间局部一致性和样本预测误差选取可靠样本,并为状态特征图中每个未被选取的非可靠样本构建一个以此样本为中心的子图,最终在每个子图聚合可靠样本标签实现中心样本的伪标签重构,并将重构后的伪标签用于下一次迭代训练;最后,利用训练后的网络预测学习者在待预测学习阶段的异常学习状态及其程度。
[0013]
本发明进一步的改进在于,该方法具体包括以下步骤:
[0014]
1)学习者注册信息和日志信息处理
[0015]
对学习者注册信息以及学习者日志信息进行预处理作为学习者初始特征,对初始特征进行编码以使其具有统一的数学表示,随后基于自监督方法训练一个掩蔽自编码器,并基于掩蔽自编码器对编码后的特征进行再编码以实现特征降维从而得到学习者画像特征;
[0016]
2)日志片段信息处理及状态特征序列和状态特征图构建
[0017]
将学习者日志信息基于时间窗口划分为多个日志信息片段,对日志信息片段进行与步骤1)中日志信息处理相似的预处理和编码后获得学习者状态特征;将相同学习者的状态特征基于其日志产生的时序构造状态特征序列,计算所有学习者状态特征之间的特征相似度并基于k近邻的方法构造状态特征图;
[0018]
3)lstm-gat深层网络构建
[0019]
构建一个由并行的ltsm和gat组成的深层网络组来分别提取时序和空间表征,二者输入分别来自于状态特征序列和状态特征图,将经过ltsm和gat深层网络组处理后输出的向量与学习者画像特征向量连接后输入至全连接层组,全连接层组输出学习者学习状态异常概率;
[0020]
4)基于多视角特征和标签重构的lstm-gat深层网络训练
[0021]
将学习成绩映射至[0,1]作为噪声标签,将学习者状态特征和学习者画像特征作为训练特征,每次训练迭代分为网络参数更新和伪标签重构两个部分,模型训练时将基于噪声标签构造的伪标签对网络参数进行更新;伪标签重构时,首先选取可靠样本,然后以非
可靠样本作为中心构建子图,聚合子图中可靠样本的伪标签以重构中心非可靠样本的伪标签;
[0022]
5)学习者异常学习状态预测
[0023]
将待预测的学习者注册信息和日志信息进行处理和编码后作为所训练lstm-gat模型的输入,经过模型处理后输出学习者学习状态异常的概率。
[0024]
本发明进一步的改进在于,步骤1)中,学习者注册信息和日志信息处理具体包括以下步骤:
[0025]
step1:学习者注册信息处理
[0026]
针对原始的学习者注册信息中包含许多冗余和缺失字段的问题,从这些字段中选出与学习者相关性高且缺失少的性别、出生日期、身份类型、最高学历、毕业院校和所在地相关信息作为初始特征;同时,将出生日期保留出生年份,以每10年作为一个区间进行映射将其转化为类别特征;将所在地根据新一线城市研究所《2020城市商业魅力排行榜》映射为一线城市、新一线城市、二线城市、三线城市、四线城市和五线城市六类作为特征,从而获得时间和类别特征的统一数学表示;随后将以上特征利用独热编码one-hot encoding的方式进行编码并连接作为学习者注册信息特征;
[0027]
所属one-hot encoding编码方式,详细步骤为:
[0028]
s1.记类别特征集合为对有ni种可能取值的类别特征ci设置一个ni位状态寄存器mi;
[0029]
s2.mi中的每一位表示ci的一种取值是否有效,有效取1,无效取0;
[0030]
s3.对所有的i∈{1,2,3,
…
,lc},将ci依次进行编码,得到所有类别特征的one-hot向量;
[0031]
step2:日志信息处理
[0032]
每学期日志信息的统计学特征反映了学习者在本学期内的一般状态,因此利用求和、求平均和计数聚合函数,从每学期的日志信息中分别构造当前学期的课程视频观看总次数、课程视频观看总时长、参与学习课程数、平均单次观看时长、评论互动总次数、平均单个视频评论互动次数、视频暂停次数、平均视频观看间隔和同章节平均视频观看间隔统计数据,将数值特征基于z-score标准化进行映射,使其均值为0,标准差为1;由此将日志信息中包含的难以直接使用的冗杂特征转化为直接使用的具有统一数学表示的学习者统计日志特征;
[0033]
所述z-score方法具体步骤为:
[0034]
s1.记数值特征集合为对数值特征vi计算其样本均值μi和样本标准差σi;
[0035]
s2.将特征υi依照以下z-score公式进行标准化处理:
[0036][0037]
s3.对所有的i∈{1,2,3,
…
,lv},将vi依次进行编码,得到所有类别特征的one-hot向量;
[0038]
step3:学习者画像特征编码构建
[0039]
学习者注册信息和设定学期的日志信息结合宏观描述学习者在设定学期的一般状态,学习者的一般学习状态对学习者学习状态预测有重要参考作用,将学习者注册信息
和日志信息结合后进行编码以构建一个能够描述学习者一般学习状态的学习者画像特征;学习者画像特征编码构建首先将step1和step2中生成的特征进行连接组成一个学习者初始特征以描述学习者,然后构造一个由线性编码器和线性解码器组成的掩蔽自编码器以处理稀疏特征,并通过对学习者初始特征的部分掩蔽和恢复来挖掘学习者初始特征的深层关联;设置编码器由输入层和两个隐藏层组成,第一个隐藏层由个神经元组成,第二个隐藏层由个神经元组成,记学习者初始特征向量长度为ls,则输入层维度为ls,其中第一个隐藏层的神经元由尺寸为的线性层和tanh激活函数组成、第二个隐藏层的神经元由尺寸为的线性层和tanh激活函数组成,解码器则由结构和顺序同编码器相反的两层组成,同时在激活前设置批标准化层以提高模型收敛程度,所述tanh激活函数形式化表述为:
[0040][0041]
将特征向量进行随机mask后输入自编码器网络,mask率在训练中以t为步长按照设定序列m
t
阶梯增长,t为一个控制mask率增长速度的超参,m
t
为控制增长率的超参序列;损失函数设为均方误差损失,设解码器输出向量为原始特征向量为xs,则均方误差损失函数表示为:
[0042][0043]
训练后取出掩蔽自编码器中的编码器作为学习者画像特征编码器,对所有学习者初始特征进行编码得到学习者画像特征。
[0044]
本发明进一步的改进在于,步骤2)中,日志片段信息处理及状态特征序列和状态特征图构建具体包括以下步骤:
[0045]
step1:日志片段信息处理
[0046]
学习者学习状态由一段时间内的学习情况反映,日志片段信息处理将日志信息依照设定时间窗口分片为日志信息片段,以时间片段内的日志信息反映学习者在当前时间片段的学习状态;
[0047]
具体来说,首先将每个学习者的日志信息按照星期划分为日志信息片段,其次与日志信息处理相似,对学习者每周学习日志构造章视频观看总次数、课程视频观看总时长、参与学习课程数、平均单次观看时长、评论互动总次数、平均单个视频评论互动次数、视频暂停次数、平均视频观看间隔和每章节内平均视频观看间隔统计数据,然后,将以上统计数据依照日志信息处理方式进行编码,最后构造一个由线性编码器和线性解码器组成的掩蔽自编码器,编码器层数和每层的神经元个数与学习者画像特征编码构建相同,记编码后的特征向量长度为l
p
,则输入层维度为l
p
,两个隐藏层神经元的线性层尺寸分别为和其余网络及训练设置与上文中提到的学习者画像特征编码构建相同;利用训练后的编码器将链接后的特征进行嵌入得到学习者状态特征;
[0048]
step2:状态特征序列构建
[0049]
学习者状态特征的产生具有时间上的序列顺序,为了充分利用这一信息,基于学习状态产生时间的构造了状态特征序列,首先,根据每个学习者状态特征产生的时间顺序对其进行排序构造学习者的状态特征总序列,然后,为每个学习者状态特征选取其前序的lb个状态特征与其自身组成一段状态特征序列,以便于利用前lb周的日志片段信息辅助预
测;对于前序状态特征不足的状态特征,其前序使用设定的数值填充以便于训练中的批量处理;由此为每个学习者状态特征都构建了一个包含其本身和前序节点的序列以便于模型训练中的数据时序信息挖掘;
[0050]
step3:状态特征图构建
[0051]
将日志片段信息嵌入到表示空间并基于样本相似度构造状态特征图以在学习中利用日志片段的空间局部一致性进行标签消歧义和挖掘相似样本关联,记学习者状态特征样本数为n,为状态特征相似度矩阵,s
ij
表示状态特征与之间的余弦相似度矩阵,则
[0052][0053]
基于余弦相似度和k近邻方法构造图,即在状态特征嵌入空间中每个样本点与最相似的k个样本点连接以构成一张无向图,记所构造图的邻接矩阵为an×n,则图构造形式化表示为:
[0054][0055]
其中,表示对si中的元素进行降序排序后的向量,记降序算法为dsc,则形式化表示为:
[0056][0057]
由此获得了状态特征图及其邻接矩阵表示。
[0058]
本发明进一步的改进在于,步骤3)中,lstm-gat深层网络构建具体包括以下步骤:
[0059]
step1:lstm网络构建
[0060]
学习者状态特征经过状态特征序列构建后得到了基于时序的学习者状态特征序列,构建一个两层的lstm网络对学习者状态特征序列中的信息进行学习以挖掘数据时序信息,网络将状态特征序列作为输入,输出学习者状态时序表征;设置lstm神经单元输入层维度为隐藏层包含c
lstm
个神经元,输出层维度为o
lstm
;
[0061]
step2:gat网络构建
[0062]
学习者状态特征经过状态特征图构建后得到了基于特征空间中的学习者状态特征余弦相似度的学习者状态特征图,构建一个带有多头注意力机制的两层的gat网络对学习者状态特征图进行学习以挖掘学习者状态特征在特征空间的关系信息,使用leakyrelu作为激活函数,将状态特征图作为其输入,为每个节点聚合其相似节点特征以获得一个学习者状态空间表征;
[0063]
step3:全连接层组构建
[0064]
构建两个全连接层组成的全连接层组以整合所有编码信息以预测学习者状态异常程度,第一个全连接层尺寸为使用tanh作为激活函数,第二个全连接层尺寸为h
concat
×
1,使用sigmoid作为激活函数以输出一个表示学习者学习状态异常程度的概率;其输入为lstm、gat网络以及学习者画像特征编码器输出的连接;三个部分输出的特征向量分别提供了学习者状态的时序信息、空间信息以及学习者一般状态信息,
全连接层组同时利用三个维度的信息来预测学习者状态异常程度;
[0065]
所述sigmoid函数形式化表述如下:
[0066][0067]
其中,z为第二个全连接层的输出,sigmoid(z)为学习者异常学习状态的概率预测。
[0068]
本发明进一步的改进在于,所述gat网络第l-1层的向量在第l层的向量聚合形式化表示为:
[0069][0070]
其中,为状态特征图中的样本点,ni为样本的近邻向量索引列表,α
ij
为注意力系数,w为参数矩阵;
[0071]
所述注意力系数计算形式化表示为:
[0072][0073]
其中,concat表示拼接操作,
·
t
表示矩阵的转置操作,a是一个单层前馈神经网络中连接两层的权重矩阵;
[0074]
所述leakyrelu函数形式化表示为:
[0075][0076]
其中,k是一个表示斜率的超参。
[0077]
本发明进一步的改进在于,步骤4)中,基于多视角特征和标签重构的lstm-gat深层网络训练具体包括以下步骤:
[0078]
step1:训练数据准备
[0079]
为了针对阶段性的学习者状态异常程度进行预测,将学期内的每个状态特征都与当前学期的学习者画像特征结合来组成一个训练样本实例,则预处理和编码后的训练样本集表示为其中表示学习者状态特征,为表示的日志片段所在学期的学习者画像特征,为表示的日志片段所在学期的噪声标签;噪声标签通过将学习者学期内的平均学习成绩映射至[0,1]之间来构建,记第k个学期学习者的各科成绩集合为则计算第k学期噪声标签的形式化表示为:
[0080][0081]
其中表示第k学期第i门科目的满分成绩;将中的样本特征依次进行特征编码、状态特征序列构建以及状态特征图构建后得到一个有统一数学表示的训练数据集;
[0082]
step2:网络参数更新
[0083]
网络参数的初始化对于提高深度学习网络的训练速度和收敛性非常重要,故基于xavier初始化方式初始化网络参数以加快训练速度和减少梯度弥散;记参数w所在层的输入维度为,输出维度为o,所述xavier初始化方法形式化表示如下:
[0084][0085]
为了减少噪声影响,在网络训练中基于噪声标签构造伪标签进行训练,在训练开始阶段,将伪标签初始化为噪声标签,在每次训练迭代过程中将状态特征图、状态特征序列、学习者画像特征和伪标签输入网络,设损失函数为均方误差,基于反向传播算法更新网络参数;
[0086]
step3:伪标签重构
[0087]
由于学习者在不同学习阶段的状态异常程度不同,而基于学期成绩为每个阶段生成的标签都相同,这为训练样本带来了标签噪声,因此需要在训练过程中细化标签,构造更加贴近学习状态异常程度的伪标签来减少标签噪声;
[0088]
具体来说,在每次迭代的参数更新后基于可靠性较高的伪标签信息对可靠性较低的伪标签进行更新以减少标签噪声,首先,基于状态特征的时序局部连续性、空间局部一致性和样本预测误差筛选可靠样本,并将其交集作为可靠训练样本以实现三个状态特征视角的标签消歧,所选可靠样本集合形式化表示如下:
[0089][0090]
其中和分别为基于时序局部连续性、空间局部一致性和样本预测误差所选取的可靠的样本集;具体来说,时序局部连续性是指学习者在短期的连续的时间内会具有连续的学习状态,故状态特征序列中连续的样本会具有相似的标签,因此利用状态特征序列上连续样本的伪标签差异来衡量样本在时序上的可靠性;空间局部一致性是指在状态特征图中相近的样本具有相似的状态特征,而特征相似的样本会具有相似的标签,因此利用状态特征图上相似样本的伪标签差异来衡量样本在空间上的可靠性;同时,使用均方误差来衡量样本预测和伪标签之间的误差以及样本伪标签之间的差异;则和集合的形式化表示为:
[0091][0092][0093][0094]
其中,τg、τs和τr为三个表示阈值的超参,分别控制基于时序局部连续性、空间局部一致性和样本预测误差的可靠样本选择;为矩阵s第i行的元素的和,为矩阵d第i行的元素的和,xi表示第i个训练样本,y
′i表示表示基于构造的伪标签,seqi表示样本xi序列上的前后序样本索引列表,d
ij
表示样本xi和xj在序列上相
差的时间片段数,由此获得了可靠样本集用于后续训练和伪标签重构;
[0095]
然后,在每次迭代后为不可靠样本聚合周边可靠样本的信息以更新其标签,选取不可靠样本作为中心,选取其状态特征图上的可靠近邻样本构造子图;若有不可靠样本的所有近邻均不可靠则表示以此样本为中心的局部标签噪声过多,有效信息少,因此跳过此样本的伪标签重构,子图上的伪标签重构基于标签传播方法展开,其形式化表示为:
[0096][0097]
其中表示噪声样本xi近邻中的可靠样本列表。
[0098]
本发明进一步的改进在于,步骤5)中,学习者异常学习状态预测具体包括以下步骤:
[0099]
将需要预测的学习者注册信息和学习者日志信息经过步骤1)和步骤2)处理后得到状态特征编码xe、学习者画像特征编码xs以及状态特征序列seq作为网络输入,将xe及其前序输入lstm网络部分,将lstm部分的输出作为样本的状态特征时序表征;将xe嵌入至训练样本的图空间找到其k近邻,基于距离聚合其k近邻的gat网络输出来表示样本的状态特征空间表征,其形式化表示为:
[0100][0101]
其中,gat(x)表示样本x经过gat网络处理后的输出,n
train
表示样本xe在训练集中的近邻集合,s(x1,x2)表示样本x1,x2之间的余弦相似度;将lstm部分输出的状态特征时序表征、gat部分输出的状态特征空间表征和学习者画像特征编码连接作为全连接层组的输入,经过全连接层组得到一个学习者状态异常概率p
x
∈[0,1],p
x
越大表示学习者状态异常程度越高,反之越低。
[0102]
本发明至少具有以下有益的技术效果:
[0103]
本发明提供的一种面向在线教育的学习者异常学习状态预测方法,利用学习者注册信息及学习者日志信息预测学习者状态异常程度,为教师对学习者进行针对性指导和帮助提供了参考。基于时序-空间表征构造不同状态特征视角并基于不同状态特征视角实现标签重构,改进了现有的技术,使方法在无需针对每个学习者状态片段进行标注的情况下可以构建一个标签噪声鲁棒的学习者异常学习状态预测模型。与现有技术相比,本发明的优点是:
[0104]
(1)本发明将学习者异常学习状态预测视为一个回归问题,将学习成绩映射为连续的带噪标签以训练预测模型。区别于现有技术直接将学习成绩二值化作为标签,本发明构造的带噪标签更能反映训练数据中的学习者在不同阶段的学习状态异常程度,利用此数据训练而来的学习者异常学习状态预测模型更符合辅助教师对不同状态异常程度的学习者展开针对性指导的场景需求。
[0105]
(2)本发明提出了一种基于多视角可靠样本消歧和标签传播的噪声标签学习方法,基于带噪标签构造迭代更新的伪标签。具体的,方法基于状态特征的时序局部连续性、空间局部一致性和样本预测误差划分可靠样本和非可靠样本,随后构造以非可靠样本为中心的子图并聚合子图中可靠样本伪标签以重构非可靠样本伪标签。区别于现有技术直接利
用带噪标签进行网络的监督训练,本发明实现了样本的伪标签重构,有效降低了标签噪声对网络训练的影响。
[0106]
(3)本发明提出了一种时序-空间表征抽取方法,基于学习者状态特征的时序先后构造状态特征时序结构,基于学习者状态特征间的相似性构造图结构,分别基于lstm和gat学习其时序-空间表征。区别于现有技术通常挖掘学习者画像特征或时序表征进行学习,本发明将静态的学习者画像特征同时序和空间表征相结合,挖掘了深层多视角特征,提升了学习者异常状态预测精度。
附图说明
[0107]
图1为整体框架流程图。
[0108]
图2为学习者注册信息和日志信息处理流程图。
[0109]
图3为日志片段信息处理及状态特征序列和状态特征图构建流程图。
[0110]
图4为lstm-gat深层网络构建流程图。
[0111]
图5为基于多视角特征和标签重构的lstm-gat深层网络训练流程图。
[0112]
图6为学习者异常学习状态预测流程图。
[0113]
图7为学习者异常学习状态预测示意图。
具体实施方式
[0114]
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本发明。
[0115]
实施例
[0116]
选取某在线教育平台中2017年的所有学习者的注册信息及其2017-2020年期间的日志信息。以下参照附图,结合实验案例及具体实施方式对本发明作进一步的详细描述。凡基于本发明内容所实现的技术均属于本发明的范围。
[0117]
如图1所示,本发明的具体实施中,本发明一种面向在线教育的学习者异常学习状态预测方法,包括以下步骤:
[0118]
步骤1.学习者注册信息和日志信息处理
[0119]
学习者注册信息以及日志信息中包含很多与学习者异常学习状态预测无关的冗余字段和大量数据缺失字段;同时,还有许多有用的时间和类别字段无法直接用于模型训练。学习者注册信息和日志信息处理将数据中与训练目标相关性较低的字段删除并将无法直接用于模型训练的字段构建统一的数学表示以便于后续的特征提取和模型训练。学习者注册信息和日志信息处理实施过程如图2,具体包括以下步骤:
[0120]
s101.学习者注册信息处理
[0121]
学习者注册信息包括{性别sex、出生日期birthday、身份类型type、最高学历qualification、毕业院校institution、所在地city、个人简介profile、职业job}等待处理字段。
[0122]
具体的,本实施例中,由于个人简介和职业字段为注册者注册时的可选字段有大量样本的对应字段缺失,并且个人简介信息与目标问题相关性不高且难以作为长文本信息难以对其利用,故从学习者注册信息中删除这两个字段,将剩余字段作为特征。由于日期类特征无法直接使用,因此实施例中以每10年为一个区间,将生日映射为离散的类别特征,记出生日期年份为year,所述映射方式形式化表示为:
[0123][0124]
从而获得yeartype表示映射后的年份类别。此外,将所在地根据新一线城市研究所《2020城市商业魅力排行榜》,将一线城市、新一线城市、二线城市、三线城市、四线城市、五线城市分别映射为{1,2,3,4,5,6},从而获得所在城市类别。至此,学习者注册信息均转化为类别特征,随后基于独热编码的方式对这些类别特征进行编码,实施例中将性别(男/女)、年分类别、身份类型(学生/在职)、最高学历(专科以下/专科/本科/硕士/博士)、毕业院校(双一流院校/普通本科/其他)和城市类别分别编码,然后将上述字段的编码连接作为学习者注册信息特征。
[0125]
s102.日志信息处理
[0126]
每学期日志信息的统计学特征反映了学习者在本学期内的一般状态,但日志信息中包含大量的行为字段和时间字段。
[0127]
具体的,本实施例中,行为字段包括登录平台、观看视频、暂停视频、评论等,时间字段包括观看视频时间、暂停视频时间、登录平台时间、登出平台时间等。这些字段数据量较大且难以直接用于机器学习模型训练,因此利用一些聚合函数来构造其统计量作为特征。实施例中从上述字段中构造当前学期的课程视频观看总次数、课程视频观看总时长、参与学习课程数、平均单次观看时长、评论互动总次数、平均单个视频评论互动次数、视频暂停次数、平均视频观看间隔、同章节平均视频观看间隔等统计数据作为待处理日志信息特征。
[0128]
由于上述统计量为量纲不统一的数值特征,将数值特征基于z-score标准化进行映射。实施例中首先计算上述9列特征的样本均值{μ1,μ2,
…
,μ9}及样本方差{σ1,σ2,
…
,σ9},随后基于z-score公式更新其特征{υ1,υ2,
…
,υ9},由此将日志信息中包含的难以直接使用的冗杂特征转化为可以直接使用的具有统一数学表示的特征。将上述特征进行连接成为学习者统计日志特征。
[0129]
s103.学习者画像特征编码构建
[0130]
学习者注册信息和设定学期的日志信息结合可以宏观描述学习者在设定学期的一般状态,学习者的一般学习状态对学习者学习状态预测有重要参考作用,实施例中将发明将学习者注册信息和日志信息结合后进行编码以构建一个可以描述学习者一般学习状态的学习者画像特征。
[0131]
具体的,本实施例中,学习者画像特征编码构建首先将学习者注册信息特征和学习者统计日志特征进行连接组成一个长度为40的向量作为学习者初始特征,然后构造一个由线性编码器和线性解码器组成的掩蔽自编码器以处理稀疏特征,并通过对学习者初始特征的部分掩蔽和恢复来挖掘学习者初始特征的深层关联。编码器由输入层和两个隐藏层组
成,则输入层维度为40,第一个隐藏层由6个神经元组成,第二个隐藏层由4个神经元组成,其中第一个隐藏层的神经元由尺寸为40
×
32的线性层和tanh激活函数组成、第二个隐藏层的神经元由尺寸为32
×
16的线性层和tanh激活函数组成,解码器则由结构和顺序同编码器相反的两层组成,同时在激活前设置批标准化层(batch normalization layer)以提高模型收敛程度。
[0132]
本实施例掩蔽自编码器训练中,特征向量的mask率在训练中以10为步长按照{0,15%,30%,45%}的顺序阶梯增长,损失函数设为均方误差:取所训练的掩蔽自编码器中的编码器作为学习者画像特征编码器。随后将40维的学习者初始特征经过编码转化为16维的学习者画像特征。
[0133]
步骤2.日志片段信息处理及状态特征序列和状态特征图构建
[0134]
学习者学习状态由一段时间内的学习情况反映,将学习者日志信息基于时间窗口划分为多个日志信息片段,对日志信息片段预处理和编码后获得反映学习者一段时间内学习情况的学习者状态特征;将相同学习者的状态特征基于其日志产生的时序构造状态特征序列,计算所有学习者状态特征之间的特征相似度并基于k近邻的方法构造状态特征图,从而便于在接下来的模型训练中挖掘学习者状态特征之间的时序和空间关系。日志片段信息处理及状态特征序列和状态特征图构建实施过程如图3,具体包括以下步骤:
[0135]
s201.日志片段信息处理
[0136]
将星期作为时间窗口将每个学习者的日志信息划分为日志信息片段。其次构造日志信息处理相似的每周内的统计特征并依照日志信息处理方式进行编码。构造一个由线性编码器和线性解码器组成的掩蔽自编码器对统计特征进行进一步编码以挖掘其深层特征关联信息。
[0137]
具体的,本实施例中,编码器层数和每层的神经元个数与学习者画像特征编码构建相同,编码后的特征向量长度为9,两个隐藏层神经元的线性层尺寸分别为9
×
24和24
×
16,其余网络及训练设置与上文中提到的学习者画像特征编码构建相同;利用训练后的编码器将链接后的特征进行嵌入得到最终状态特征。
[0138]
s202.状态特征序列构建
[0139]
学习者状态特征的产生具有时间上的序列顺序,为了充分利用这一信息,本发明基于学习状态产生时间的构造了状态特征序列。
[0140]
具体的,本实施例中,每学期包括16个星期,记某学期某学习者状态特征及其所属的星期为依照对其进行排序获得此学期此学习者的状态特征总序列。然后,为每个学习者状态特征选取其前序的5个状态特征与其自身组成一段长度为6状态特征序列,以便于在训练中利用前5周的日志片段信息辅助预测;对于前序状态特征不足的状态特征,其前序使用0填充,由此为每学期每个学习者构建16个状态特征序列以便于接下来的学习过程中挖掘数据中的时序信息。
[0141]
s203.状态特征图构建
[0142]
将日志片段信息嵌入到表示空间并基于样本相似度构造状态特征图以在学习中利用日志片段的空间局部一致性进行标签消歧义和挖掘相似样本关联。
[0143]
具体的,本实施例中,首先计算状态特征相似度矩阵s,其中表示状态特征与之间余弦相似度;随后,对矩阵s中的每一列分别排序得到s
dsc
,其中为s第i列降序排序后得到的序列;最后,基于余弦相似度和k近邻方法构造图,实施例中取k=20,即在状态特征嵌入空间中每个样本点与最相似的20个样本点连接以构成一张无向图,所构造的图用邻接矩阵a表示,则有由此获得了状态特征图及其邻接矩阵表示用于挖掘数据中的空间信息。
[0144]
步骤3.lstm-gat深层网络构建
[0145]
构建一个由并行的ltsm和gat组成的深层网络组来分别提取时序和空间表征,二者输入分别来自于状态特征序列和状态特征图,将经过ltsm和gat深层网络组处理后输出的向量与学习者画像特征向量连接后输入至全连接层组,全连接层组输出学习者学习状态异常概率。lstm-gat深层网络构建实施过程如图4,具体包括以下步骤:
[0146]
s301.lstm网络构建
[0147]
学习者状态特征经过s202处理后得到了基于时序的学习者状态特征序列,构建一个lstm网络对序列进行学习以挖掘数据时序信息,从而获得一个学习者状态时序表征。
[0148]
具体的,本实施例中,构建一个两层的lstm,lstm神经单元输入层维度为16,隐藏层包含4个神经元,输出层维度为16。
[0149]
s302.gat网络构建
[0150]
学习者状态特征经过状态特征图构建后得到了基于特征空间中的学习者状态特征余弦相似度的学习者状态特征图,构建一个带有多头注意力机制的两层的gat网络对状态特征图进行学习,以挖掘学习者状态空间表征。
[0151]
具体的,本实施例中,使用leakyrelu作为激活函数,取gat网络第l-1层的向量在第l层的向量聚合形式化表示为其中,为状态特征图中的样本点,ni为样本的近邻向量索引列表,为注意力系数,w为参数矩阵,concat表示拼接操作,
·
t
表示矩阵的转置操作,a是一个单层前馈神经网络中连接两层的权重矩阵。
[0152]
s303.全连接层组构建
[0153]
构建两个全连接层组成的全连接层组以整合所有编码信息以预测学习者状态异常程度,其输入为学习者状态时序表征、学习者状态空间表征以及学习者画像特征三个向量的连接。
[0154]
具体的,本实施例中,第一个全连接层尺寸为48
×
16,使用tanh作为激活函数,第
二个全连接层尺寸为16
×
1。记全连接层组输出为z,使用作为激活函数将第二个全连接层的输出映射为表示学习者学习状态异常程度的概率。
[0155]
步骤4.基于多视角特征和标签重构的lstm-gat深层网络训练
[0156]
lstm-gat深层网络训练分为训练数据准备、网络参数更新和伪标签重构三步。训练数据准备中将学习成绩映射至[0,1]作为噪声标签,将学习者状态特征和学习者画像特征作为训练特征。每次训练迭代包括网络参数更新和伪标签重构更新两个部分,网络训练时对网络参数进行更新;伪标签重构时,首先选取可靠样本,然后以非可靠样本作为中心构建子图,聚合子图中可靠样本的标签以重构中心非可靠样本的标签。lstm-gat深层网络训练实施过程如图5,具体包括以下步骤:
[0157]
s401.训练数据准备
[0158]
为了针对阶段性的学习者状态异常程度进行预测,将学期内的每个状态特征都与当前学期的学习者画像特征结合来组成一个训练样本实例。
[0159]
具体的,本实施例中,将2017-2019年的数据按照9∶1的比例划分为训练集和验证集,将2020年的数据作为测试集;利用构造的训练集训练模型,利用验证集选取模型,利用测试集进行模型效果检测。具体训练过程为:预处理和编码后的一个训练样本集可以表示为其中表示16维的学习者状态特征向量,为表示的日志片段所在学期的16维学习者画像特征,为映射至[0,1]的噪声标签,其中为状态特征对应的学习者在对应学期的成绩集合,表示第k学期第i门科目的满分成绩。将中的样本特征依次进行特征编码、状态特征序列构建以及状态特征图构建后得到一个可以在ltsm-gat网络中进行处理的训练集、验证集和测试集。
[0160]
s402.网络参数更新
[0161]
lstm-gat每次训练迭代包括网络参数更新和伪标签重构两个部分,网络参数更新部分基于噪声标签重构得到的伪标签进行训练以更新网络参数。
[0162]
具体的,本实施例中,首先基于xavier初始化方式初始化网络参数以加快训练速度和减少梯度弥散。然后,将状态特征序列输入lstm网络部分将状态特征图输入gat网络部分,得到学习者状态时序表征和学习者状态空间表征。随后将学习者状态时序表征、学习者状态空间表征、和学习者画像特征拼接并输入全连接层组得到一个预测的学习者学习状态异常概率。最终将学习状态异常概率和基于噪声标签重构得到的伪标签计算均方误差并基于反向传播算法更新网络参数。
[0163]
s403.伪标签重构
[0164]
lstm-gat每次训练迭代包括lstm-gat网络训练和伪标签重构两个部分,伪标签重构部分基于训练中lstm-gat网络的输出对噪声标签进行迭代的重构,从而构造更加贴近学习状态异常程度的伪标签来减少标签噪声。
[0165]
具体的,本实施例中,对于样本首先分别基于时序局部连续性、空间局部一致性和样本预测误差计算伪标签差异
其中为矩阵s第i行的元素的和,为矩阵d第行的元素的和,y
′i表示基于构造的伪标签,seqi表示样本xi序列上的前后序样本索引列表,d
ij
表示样本xi和xj在序列上相差的时间片段数。由此获得了可靠样本集用于后续训练和伪标签重构。然后,若满足(es<0.01)∧(eg<0.01)∧(e
l
<0.01)则认为样本可靠,否则样本不可靠。最后,若为不可靠样本,则将其作为中心样本并选取其状态特征图上的可靠近邻样本构造子图,计算以聚合子图信息更新中心样本伪标签。
[0166]
步骤5.学习者异常学习状态预测
[0167]
经过步骤4获得了一个训练后的学习者异常学习状态预测模型(图7),基于此模型可以估计待预测学习者学习状态异常的概率。
[0168]
具体的,本实施例中,首先将待预测的学习者注册信息和学习者日志信息经过步骤1)和步骤2)预处理后得到状态特征编码xe、学习者画像特征编码xs以及状态特征序列seq(图6-s501)。其次,将xe及其前序作为输入,通过lstm网络得到样本的状态特征时序表征(图6-s502)。再次,计算xe与训练集各样本状态特征的相似度,找到其训练集中的10最近邻,基于距离聚合其10最近邻的gat网络的输出来表示待预测样本的状态特征空间表征(图6-s503)。最后,连接状态特征时序表征、状态特征空间表征和学习者画像特征作为全连接层组的输入,经过全连接层组得到一个学习者状态异常概率p
x
(图6-s504)。
[0169]
本领域的技术人员容易理解,以上所述仅为本发明的方法实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。