1.本发明属于图像处理技术领域,特别涉及一种非平衡高光谱图像分类方法,可用于矿产勘测,生态监测,智慧农业及医疗诊断。
背景技术:
2.高光谱图像的光谱分辨率高,可覆盖可见光、近红外以及短波红外波长范围,通常具有数十至数百个波段。不同物质独特而又精细的光谱信息,使得区分仅仅具有细微差异的土地覆盖类别成为可能,目前在矿产勘测,生态监测,智慧农业,医疗诊断等方面得到了广泛的应用。高光谱图像分类是高光谱图像解译的重要手段之一,致力于将图像中的每一个像素点赋予特定的标签,从而实现对场景的像素级语义解析,可为地物监测、变化检测等更高层次的应用提供有力的支持。
3.在实际拍摄的高光谱图像中,不同类别的地物在图像中所占面积比例的差异较大,因此用于训练分类器的样本数据呈现非平衡的分布规律,即有的类别样本数量较大,属于大类别,有的类别样本数量较少,属于小类别。在上述情况下,分类器的训练过程将严重依赖大类别样本的标注信息,而较少关注小类别的样本,导致分类结果偏向于大类别,小类别的分类精度较差。然而,在一个场景中的少数类通常是更有价值的,需要得到高质量的识别率。例如,在植被覆盖场景分类中,人们更关注的珍贵稀有物种通常在图像中只占据少部分像素;在实时分类应用中,森林火灾在初始阶段仅占据图像场景中很小的区域,分类器应尽早准确划分出这一小类别,从而实现及时的防灾减灾。因此,设计非平衡高光谱图像分类方法,具有十分重要的意义和价值。
4.传统的用于解决非平衡高光谱图像分类的方法直接对原始样本数据进行重采样,即对小类别和大类别样本分别进行上采样和下采样,使得所有类别的样本数目实现均衡。该方法针对的是相对低维的样本特征,即样本对应的一维光谱曲线,难以处理三维的光谱-空间邻域样本等高维数据。深度学习模型能够由原始数据驱动,有效地将高维数据映射到区分能力更强的低维特征嵌入空间。受此启发,研究人员将重采样策略引入深度学习模型中,通过训练深度网络捕捉嵌入空间中的数据分布,然后以嵌入空间作为桥梁合成新的样本,该类方法统一称为深度生成模型,其中具有代表性的算法是条件变分自编码器和生成对抗网络。条件变分自编码器利用网络提取的隐含特征捕获数据的依赖关系,能够以标签信息作为条件,从学习到的潜在变量分布中生成特定类别的样本,无需复杂的对抗学习过程。然而,如果直接使用条件变分自编码器合成样本,数据的生成和分类是彼此孤立的过程,导致分类效果不佳。此外,条件变分自编码器通常用于生成简单的一维序列信号或二维自然图像,而不是高维的高光谱空谱邻域样本数据,导致丰富的光谱-空间信息无法被充分利用。
5.swalpa kumar roy等人在其发表的文章“generative adversarial minority oversampling for spectral-spatial hyperspectral image classification”(《ieee transactions on geoscience&remote sensing》,2022,60:1-15)中提出了一种基于生成
对抗网络的小类别上采样方法(hypergamo),其用于克服非平衡高光谱分类中存在的问题。该方法设计了一个基于条件生成对抗网络的三维凸包生成器,在小类别样本的深度特征形成的凸包内生成新的样本特征,从而将样本生成和分类的过程以“端到端”的方式实现,降低了深度生成模型用于分类任务的复杂度。尽管如此,该方法仍然存在的缺陷是小类别的凸包与真实的数据分布相差甚远,导致合成样本的有用信息量较少,无法解决小类别样本不足的问题,且分类性能有待进一步的提升。
技术实现要素:
6.本发明的目的是针对上述现有技术的不足,提出一种基于深度生成光谱-空间分类器的非平衡高光谱图像分类方法,以充分利用光谱-空间信息,增强小类样本的质量和数量,提高图像分类效果。
7.实现上述目的技术思路是:将数据生成与分类结合为一个统一的过程,通过编码器充分挖掘高光谱图像信息,通过在隐含空间对小类别进行上采样,使生成样本更加贴近真实样本,得到更加准确的数据增强效果,进一步提升分类精度。
8.根据上述思路本发明的实现步骤包括如下:
9.1)获取高光谱图像数据并进行波段选择,按照固定尺寸将波段选择后的高光谱图像分割出光谱-空间特征邻域块,再将其按1:99的比例划分为训练样本和测试样本;
10.2)构建非平衡高光谱图像分类网络模型:
11.2a)建立由三个三维卷积模块与二维卷积模块级联,并与两个并联的全连接网络级联,之后再级联重参数模块组成了三维编码器;
12.2b)在隐含空间设置小类别上采样模块;
13.2c)建立由1个全连接层和多个反卷积层构成的三维解码器;
14.2d)建立由1个全连接层构成的图像分类器模块;
15.2e)将三维编码器与小类别上采样模块级联,将三维解码器与分类器并联,小类别上采样模块的输出同时并行输入三维解码器与分类器,形成非平衡高光谱图像分类网络模型;
16.3)对非平衡高光谱图像分类网络模型进行训练:
17.3a)构建该网络模型的总体损失函数l
total
=λ
·
l
mmd
l
pdrec
l
cls
,其中l
mmd
为基于最大化均值差异的正则项损失函数,l
pdrec
为基于邻域距离的重构损失函数,l
cls
为基于交叉熵的分类损失函数,λ为参数;
18.3b)初始化非平衡高光谱图像分类网络模型的参数包括三维编码器中的权重参数w、偏置参数b和参数θ={θ1,θ2}、三维解码器中的权重参数w、偏置参数b和参数小类样本特征上采样模块中的均值参数和方差参数及分类器参数η;
19.3c)将训练样本输入到非平衡高光谱图像分类网络模型,采用梯度下降方法,循环更新非平衡高光谱图像分类网络中的参数,以减小总损失函数的梯度值,直至达到最大迭代次数t为止,得到训练好的非平衡高光谱图像分类网络模型;
20.4)将测试样本输入到训练好的非平衡高光谱图像分类网络模型,输出高光谱图像分类结果图。
21.本发明的有益效果为:
22.第一,本发明由于构建了包含两阶段的三维编码器、小类别上采样模块、三维解码器和分类器的非平衡高光谱图像分类网络,可使输入数据通过训练后的非平衡高光谱图像分类网络直接得到输出端的结果,避免了人工预处理和后续处理,提高了对高光谱图像的分类速度。
23.第二,本发明设计的基于邻域距离的重构损失函数,相较于传统的利用欧氏距离衡量一维信号或二维图像特征的方式计算重构损失函数,有效提升了解码后生成的三维样本与输入的三维样本之间的一致性,提高分类器的总体分类精度。
24.第三,本发明通过在嵌入空间捕捉隐含特征的数据分布,实现小类别样本的重采样,从而将深度光谱-空间特征生成和分类器融入一个统一的框架,使分类器在处理非平衡数据的情况下尤其是对小类别数据具有更高的精度和更强的鲁棒性。
25.综上,本发明与现有技术相比,可更好的利用高光谱图像的光谱-空间一体化特征信息,且在样本非平衡的条件下,不仅能够保持总体分类精度在较高水平,还能有效提升小样本类别的分类性能,可为地物监测、变化检测这些更高级别的应用提供更好的服务。
附图说明
26.图1为本发明的方法流程示意图;
27.图2为本发明中构建的非平衡高光谱图像分类模型框图;
28.图3为从公开网站获取的高光谱图像;
29.图4为用现有hypergamo方法对图3进行分类的仿真结果图;
30.图5为用本发明对图3进行分类的仿真结果图。
具体实施方式
31.下面结合附图对本发明的实施例及效果作进一步说明:
32.本实例以university of pavia高光谱分类标准数据集为例,对其进行分类。由反射光学系统成像光谱仪获取的university of pavia数据的伪彩色合成图如图3(a)所示,对应的真值标签如图3(b)所示,其中包含9类地物,共计42776个标注样本。
33.参照图1,本实例的具体实现步骤如下:
34.步骤1:构造训练和测试样本。
35.1.1)利用主成分分析法对高光谱图像进行处理,实现特征降维,并保留前20个主成分;
36.1.2)以固定尺寸取光谱-空间邻域特征的方式,采用主成分波段构造样本,每个样本的尺寸为13
×
13
×
20;
37.1.3)从图3所示的样本中,随机选取1%的比例作为训练集,共计423个样本,剩下的样本作为测试集,共计42353个样本,其中,训练集表示为x={x1,...,x
423
},标签为y={y1,...,y
423
},xi为任意一个训练样本,由于该数据中共存在9类地物,因此xi对应的标签yi∈{1,2,...,9};
38.1.4)将每个训练样本的标签以one-hot形式编码为向量yi。
39.步骤2:构建基于深度生成模型的非平衡高光谱图像分类算法模型。
40.参照图2,本步骤的具体实现如下:
41.2.1)建立三维编码器f
θ
:
42.2.1.1)设置三个三维卷积模块,其中前两个三维卷积模块,均由卷积层、标准化层和激活层级联组成,最后一个三维卷积模块由卷积层、标准化层、激活层和重构层级联组成,三个标准化层与三个激活层结构与参数相同,三个卷积层的卷积核参数不同,即:
43.第一个三维卷积层,其输入向量的个数为1,每个输入向量的尺寸为(13,13,20),卷积核的个数为32,每个卷积核的尺寸为(3,3,7),步长为(1,1,1),输出向量个数为32,每个输入向量尺寸为(11,11,14);
44.第二个三维卷积层,其输入向量的个数为32,每个输入向量的尺寸为(11,11,14),卷积核的个数为64,每个卷积核的尺寸为(3,3,5),步长为(1,1,1),输出向量个数为64,每个输出向量的尺寸为(9,9,10);
45.第三个三维卷积模块,其输入向量尺寸为64,每个输入向量的尺寸为(9,9,10),卷积核的个数为128,每个卷积核的尺寸为(3,3,3),步长为(1,1,1),输出向量个数为128,每个输出向量尺寸为(7,7,8),为了便于与后续模块连接,通过其中的重构层将128个(7,7,8)的输出向量尺寸转化为(7,7,1024)。
46.2.1.2)设置一个二维卷积模块,该模块由卷积层、标准化层、激活层和重构层级联组成,卷积层的输入向量个数为1024,每个向量的尺寸为(7,7),卷积核的个数为128,每个卷积核的尺寸为(3,3),输出向量个数为128,每个向量的尺寸为(5,5)。
47.二维卷积的输出需要通过其中的重构层将尺寸转化为一维向量,即将该输出重构为一个尺寸为3200的一维输出向量其中,θ1表示第一阶段的参数,xi为第i个训练样本。二维卷积模块挖掘出高光谱样本中的深度空间特征,从而充分利用高光谱中包含的空间信息。
48.2.1.3)设置全连接网络,它由一个连接层级联两个并联的全连接网络组成,其中:
49.连接层将标签yi与特征连接,以使得特征向量获得标签的信息;
50.第一个全连接网络由两个大小不同的全连接层组成,第一个全连接层的转换矩阵大小是(3209,3200),第二个全连接层的转换矩阵大小为(3200,64);
51.第二个全连接网络也由两个大小不同的全连接层组成,第1个全连接层的转换矩阵大小是(3209,3200),第2个转换矩阵大小为(3200,64)的全连接层。
52.2.1.4)将上述3个三维卷积模块、1个二维卷积模块、1个全连接模块及现有的重参数模块依次级联组成三维编码器;
53.2.2)选用小类别上采样模块,在隐含空间对变量zi中的小样本上采样,上采样数目为其中,nc表示样本xi所属第c类的样本数;
54.2.3)建立三维解码器
55.2.3.1)设置一个转换矩阵的尺寸为(64,4032)、输出尺寸为4032的全连接层;
56.2.3.2)设置一个用于对全连接层输出进行尺寸转化的重构层,其输出为64个尺寸为(3,3,7)的向量;
57.2.3.3)构建三个三维反卷积模块,每个三维反卷积模块均由反卷积层、标准化层和激活层级联组成,其中三个标准化层与三个激活层结构相同,三个反卷积层的卷积核参
数不同,即:
58.所述第一个反卷积层的输入向量个数为64,每个输入向量的尺寸为(3,3,7),卷积核个数为32,每个卷积核尺寸为(3,3,3),步长为(2,2,2),输出向量尺寸个数为32,每个输出向量尺寸为(6,6,10);
59.所述第二个反卷积层的输入向量个数为32,每个输入向量的尺寸为(6,6,10),卷积核个数为16,每个卷积核尺寸为(3,3,3),步长为(2,2,2),输出向量的个数为16,每个输出向量尺寸为(12,12,20);
60.所述第三个反卷积层的输入向量个数为16,每个输入向量的尺寸为(12,12,20),卷积核个数为1,尺寸为(2,2,2),步长为(1,1,1),输出向量尺寸为(13,13,20)。
61.2.3.3)将上述1个全连接层、1个重构层1个二维卷积模块与三个三维反卷积模块依次级联组成三维解码器。
62.2.3.4)三维解码器将步骤2.1获得的隐含特征和步骤2.2获得的上采样特征zi重构为与原始光谱-空间邻域样本近似的生成样本以保证隐含特征对输入样本的表征能力。
63.2.4)构建分类器g
η
。g
η
包括1个全连接层,转换矩阵的尺寸为(64,9),以将上述原始隐含特征和上采样特征,转化为属于各个类别的概率向量用于判断样本所属类别。
64.2.5)将三维编码器与小类别上采样模块级联,将三维解码器与分类器并联,小类别上采样模块的输出同时并行输入三维解码器与分类器,形成非平衡高光谱图像分类网络模型。
65.步骤3:构建非平衡高光谱图像分类网络模型训练模型的损失函数。
66.3.1)构建基于最大化均值差异的正则项损失函数l
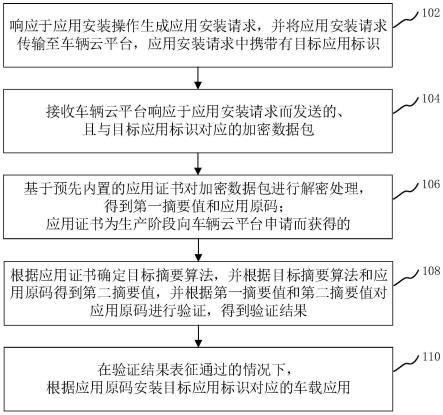
mmd
,用于约束由均值μ和方差参数σ2决定的隐含特征的条件概率分布与高斯先验分布的一致性,具体公式如下:
[0067][0068]
其中,p
θ
(zi|xi,yi)表示隐含特征的条件概率分布,表示隐含特征的高斯先验分布;
[0069]
3.2)构建基于邻域距离的重构损失函数l
pdrec
,用于促使重构三维特征与原始样本特征保持相似:
[0070]
计算像素p
ik
与之间的距离:
[0071]
计算像素与xi之间的距离:
[0072]
利用上面的两个距离,计算像素p
ik
与像素之间的距离:
[0073]
根据像素p
ik
与像素之间的距离,得到基于邻域距离的重构损失函数:
[0074][0075]
其中,d表示计算欧式距离,p
ik
表示xi中的任意一个像素,表示中的任意一个
像素,为xi对应的生成样本;
[0076]
3.3)选用现有基于交叉熵的分类损失函数:用于减小训练样本特征和上采样特征的分类结果与其真值标签之间的差异,其中,y
ic
和分别表示真实和预测的xi属于第c类的概率;
[0077]
3.4)使用基于最大化均值差异的正则项损失函数l
mmd
、基于邻域距离的重构损失函数l
pdrec
、基于交叉熵的分类损失函数l
cls
,得到训练模型的总损失函数l
total
:
[0078]
l
total
=λ
·
l
mmd
l
pdrec
l
cls
,其中,λ表示权重参数,唔实例取值为0.01。
[0079]
步骤4:使用训练样本及采用梯度下降方法对高光谱图像分类模型进行参数训练。
[0080]
4.1)设置出学习率初始值α,最大迭代次数t,批处理数量b;
[0081]
4.2)初始化网络模型的参数,包含三维编码器中的权重参数w、偏置参数b和参数θ={θ1,θ2}、三维解码器中的权重参数w、偏置参数b和参数小类样本特征上采样模块中的均值参数和方差参数及分类器参数η;
[0082]
4.3)按批处理的大小将训练样本分成批,依次输入非平衡高光谱图像分类网络进行反向传播更新总损失函数的梯度,根据下降的方向进行正向传播更新网络训练参数,对每个批输入网络进行上述计算,直到对整个训练集样本输入网络进行遍历,完成一次训练;
[0083]
4.4)循环4.3)过程,直至达到最大迭代次数t,得到训练好的非平衡图像分类模型。
[0084]
步骤5:使用训练好的非平衡高光谱图像分类模型对测试样本进行分类。
[0085]
将每一个测试样本输入到训练好的非平衡高光谱图像分类模型中,并将每个样本对应的潜在特征上采样s倍,利用重要性采样逼近贝叶斯规则,得到每个测试样本所属标签的概率p(y|x):
[0086][0087]
其中,softmax为归一化函数,l
total
为总损失函数,x为测试样本,yc为第c类测试样本对应的标签,为上采样s倍的第c类测试样本对应的潜在特征,θ为三维编码器的可训练参数,为三维解码器的可训练参数,η为分类器的可训练参数。
[0088]
本发明的效果可通过以下仿真结果进一步说明。
[0089]
一.仿真条件
[0090]
1.测试数据:使用university of pavia数据,随机选取1%标注样本作为训练集,其余样本作为测试集。
[0091]
2.测试环境:采用ubuntu 16.04lts系统,nvidia geforce gtx 1080ti gpu,tensorflow深度学习框架。
[0092]
二.仿真内容
[0093]
仿真1,在上述条件下,用现有基于生成对抗网络的小类别上采样高光谱图像分类方法hypergamo,对university of pavia数据进行分类,结果如图4所示。
[0094]
仿真2,在上述条件下,用本发明方法对university of pavia数据进行分类,结果如图5所示。
[0095]
通过图4与图5对比能够发现,本发明提出的方法得到的分类结果图与真值图的地物分布更加接近,在大多数小类别上得到的分类效果更好,实现了更优的分类性能。
[0096]
评价指标
[0097]
对上述两种方法分别利用相同的10个随机数重复测试10次,计算出混淆矩阵、各个类别的分类精度pa、平均分类精度aa、总体分类精度oa以及kappa系数,得到的测试结果如表1所示。
[0098]
指标计算公式如下:
[0099][0100][0101][0102]
其中,tp为正确划分为本类别的个数,fn为被错误地划分为其他类的本类样本个数,tn为划分为其他类别的非本类样本个数,fp为被错误地划分为本类样本的其他样本个数,x
i
表示混淆矩阵中第i行所有元素之和,即本类别实际数量之和,x
i
表示混淆矩阵中第i列所有元素之和,即预测成本类别的数量之和,n表示所有元素之和,c为类别数,x
ii
表示混淆矩阵中对角线上的元素,即每个类别预测正确的数量。
[0103]
表1本发明与对比方法的仿真实验结果
[0104][0105]
表1中标粗的类别编号为小样本类别,其样本数目小于每类别平均样本数目。
[0106]
从表1中能够看出,相对于当前较先进的hypergamo方法,本发明对类别编号为3、4、5、7、8的小类别分类精度均有提升,同时平均分类精度、总体分类精度以及kappa系数也均得到了可观的改进。此外,本发明方法得到的标准差较小,验证了本方法在面对非平衡高光谱分类的鲁棒性。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。