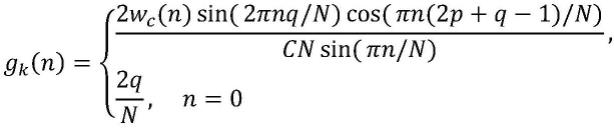
information&systems,2016,99(7):1877-84.
22.[14]mehri s,kumar k,gulrajani i,et al.samplernn:an unconditional end-to-end neural audio generation model[j].2016.
[0023]
[15]kalchbrenner n,elsen e,simonyan k,et al.efficient neural audio synthesis[j].2018.
[0024]
[16]oord a,li y,babuschkin i,et al.parallel wavenet:fast high-fidelity speech synthesis;proceedings of the international conference on machine learning,f,2018[c].pmlr.
[0025]
[17]kingma d p,dhariwal p.glow:generative flow with invertible 1x1 convolutions[j].arxiv preprint arxiv:180703039,2018.
[0026]
[18]neekhara p,donahue c,puckette m,et al.expediting tts synthesis with adversarial vocoding[j].arxiv preprint arxiv:190407944,2019.
[0027]
[19]kong j,kim j,bae j.hifi-gan:generative adversarial networks for efficient and high fidelity speech synthesis[j].2020.
技术实现要素:
[0028]
本发明提供了一种基于滤波器组频率区分的深度网络波形合成方法及装置,本发明使合成的语音尽量逼近人的真实语音波形,在文本转语音中,减轻第二阶段中从中间特征表示梅尔谱到语音波形映射时产生的明显伪影,加快模型的推断速度,使模型更适用于实时的场景,解决已有gan网络技术中高频部分混叠失效的问题,减轻高频频段频谱失真,详见下文描述:
[0029]
第一方面,一种基于滤波器组频率区分的深度网络波形合成方法,所述方法包括:
[0030]
采用解析方法设计多个任意频率通带的滤波器组;将生成器输出的语音信号并行馈入到滤波器组中,获得多个窄频带的信号;
[0031]
将窄频带的信号分别输入到各个子鉴别器中进行处理,综合子鉴别器的损失函数对生成对抗网络的参数进行训练,将测试文本馈入到给定的声学模型前端网络中,生成测试梅尔谱,再将该测试梅尔谱输入到生成器中,生成语音信号。
[0032]
其中,所述生成对抗网络包括:生成器网络和鉴别器网络,所述生成器网络包括:转置卷积模块和多感受野融合模块;所述鉴别器网络由若干子鉴别器组成,每个子鉴别器对输入语音波形的某一任意指定的窄频段内的信号进行处理。
[0033]
进一步地,所述综合子鉴别器的损失函数对生成对抗网络的参数进行训练具体为:
[0034]
1)随机初始化生成器网络g(θ)与鉴别器网络d(φ)的网络参数;
[0035]
2)从训练集中采集m条语音样本,{x
(m)
},1≤m≤m;训练梅尔谱数据集中选出与这m条语音样本对应的梅尔谱样本,{s
(m)
},1≤m≤m;
[0036]
3)将{s
(m)
},1≤m≤m输入到生成器中,得到生成语音{y
(m)
},1≤m≤m,y
(m)
=g(s
(m)
);
[0037]
4)将x
(m)
与y
(m)
依次输入到k个长度为2n-1的解析窄带滤波器g1(n),
…
,gk(n)中,
n∈[-n 1,-1]∪[1,n-1]
[0038]
其中,k=1
…
k,p、q分别为用于控制滤波器gk(n)的通带起始频点和带宽的整数参数,wc(n)为卷积窗,将x
(m)
与y
(m)
各自分为k个窄频段信号,再将窄频段信号分别输入对应的子鉴别器中,根据非消失梯度的迭代策略来最小化鉴别器损失函数ld,更新鉴别器网络d(φ);
[0039]
5)从训练梅尔谱数据集中采集m条样本,
[0040]
6)将m条样本输入到生成器中,经过转置卷积使输出序列的长度与原始波形x的时间分辨率相匹配;将序列输入到多感受野融合模块中,并行观察各种不同序列长度的模式,输出多个残差模块的总和,作为生成语音进而根据非消失梯度的迭代策略来最小化生成器损失函数lg,更新生成器网络g(θ)。
[0041]
第二方面,一种基于滤波器组频率区分的深度网络波形合成装置,所述装置包括:所述装置包括:处理器和存储器,所述存储器中存储有程序指令,所述处理器调用存储器中存储的程序指令以使装置执行第一方面中的任一项所述的方法步骤。
[0042]
本发明提供的技术方案的有益效果是:
[0043]
1、本发明合成的语音具有逼近真实语音波形的效果,且合成语音波形的梅尔谱细节部分更加清晰;该模型在推断速度方面得到提高,促进语音波形合成更加适用于实时场景的发展;
[0044]
2、本发明从实验部分给出的合成语音波形的梅尔谱,也可以看到本发明提出的语音波形合成gan网络解决了高频部分混叠失效的问题,大大减轻了高频频段的频谱失真。
附图说明
[0045]
图1为波形生成gan网络中生成器的简单结构示意图;
[0046]
图2为波形生成gan网络中鉴别器的简单结构示意图;
[0047]
图3为生成对抗网络的流程图;
[0048]
图4为生成器的具体结构示意图;
[0049]
其中,生成器将梅尔谱上采样|ks
up
|次以匹配原始语音波形的分辨率。mrf模块通过|ks
res
|个具有不同核大小及扩张率的残差块来添加多样化的特征,其中第j个残差块中扩展卷积的核大小及扩张率分别为ks
res
[j]和d
res
[j,n,l]。
[0050]
图5为鉴别器的具体结构示意图;
[0051]
其中,mfd是10个子鉴别器的混合结构,每个子鉴别器接收解析滤波器后某一段频段内的波形。每个子鉴别器中的conv block均由经过“leaky relu”激活的步进卷积和群卷积组成,此外,将权重标准化应用于每一个子鉴别器当中。
[0052]
图6为解析滤波器组示意图;
[0053]
图7为原始波形经过analytic filter4的实验图;(a)为原始波形;(b)为经过analytic filter4滤波后的波形;(c)为原始波形频谱;(d)为经过analytic filter4滤波
后的波形频谱。
[0054]
图8为本模型合成句子"i am very happy to see you again!"语音波形的梅尔谱示意图;
[0055]
图9为hifigan合成句子"i am very happy to see you again!"语音波形的梅尔谱示意图;
[0056]
图10为本模型合成句子"when i was twenty,i fell in love with a girl."语音波形的梅尔谱示意图;
[0057]
图11为hifigan合成句子"when i was twenty,i fell in love with a girl."语音波形的梅尔谱示意图。
具体实施方式
[0058]
为使本发明的目的、技术方案和优点更加清楚,下面对本发明实施方式作进一步地详细描述。
[0059]
基于语音信号是一种多频率成分的结构,并且在文本转语音的后端声码器中,需要由梅尔谱转换为语音波形,因而本发明实施例提出将语音信号波形生成的过程与滤波器组设计相结合,从而对鉴别器网络参数进行优化。
[0060]
具体来说,首先采用解析方法设计多个任意频率通带的滤波器组;然后将生成器输出的语音信号并行馈入到这些滤波器组中,而获得多个窄频带的信号;进而将这些窄频带的信号分别输入到各个子鉴别器中进行处理,再综合这些子鉴别器的损失函数对网络参数做优化,从而提升声码器中生成器与鉴别器的协同功能,保证了整个语言编码器可合成更高质量的语音。
[0061]
实施例1
[0062]
本发明实施例提供了一种基于滤波器组频率区分的深度网络文本转语音波形合成方法,参见图1-图6,该方法包括以下步骤:
[0063]
101:训练所用语音数据集、与语音所对应的转录文本、测试文本,给定可实现从文本到梅尔谱转换的声学模型前端网络;
[0064]
102:将数据集中的语音分出训练集,然后依次计算每条语音的梅尔谱,从而构造出训练梅尔谱数据集,实现对数据集的预处理;
[0065]
103:构建网络:
[0066]
构建如图1所示的生成器网络,包括:转置卷积(transposed convolutional)模块和多感受野融合模块(multi-receptive field fusion,mrf);以及如图2所示的多频率鉴别器网络,该鉴别器由若干子鉴别器组成,每个子鉴别器对输入语音波形的某一任意指定的窄频段内的信号进行处理。
[0067]
104:网络训练阶段:
[0068]
其中,该步骤具体为:
[0069]
1)随机初始化生成器网络g(θ)与鉴别器网络d(φ)的网络参数;
[0070]
2)从训练集中采集m条语音样本,{x
(m)
},1≤m≤m;训练梅尔谱数据集中选出与这m条语音样本对应的梅尔谱样本,{s
(m)
},1≤m≤m;
[0071]
3)将{s
(m)
},1≤m≤m输入到生成器中,得到生成语音{y
(m)
},1≤m≤m,y
(m)
=g(s
(m)
);
[0072]
4)将x
(m)
与y
(m)
依次输入到k个长度为2n-1的解析窄带滤波器g1(n),
…
,gk(n)中,n∈[-n 1,-1]∪[1,n-1]
[0073]
其中,k=1
…
k(其中p、q分别为用于控制滤波器gk(n)的通带起始频点和带宽的整数参数,wc(n)为卷积窗),从而将x
(m)
与y
(m)
各自分为k个窄频段信号,再将这些窄频段信号分别输入对应的子鉴别器中,进而根据非消失梯度的迭代策略来最小化鉴别器损失函数ld,从而更新鉴别器网络d(φ)。
[0074]
5)从训练梅尔谱数据集中采集m条样本,
[0075]
6)将m条样本输入到生成器中,首先经过转置卷积使输出序列的长度与原始波形x的时间分辨率相匹配;然后将序列输入到多感受野融合模块中,并行观察各种不同序列长度的模式,最终输出多个残差模块的总和,作为生成语音察各种不同序列长度的模式,最终输出多个残差模块的总和,作为生成语音进而根据非消失梯度的迭代策略来最小化生成器损失函数lg,从而更新生成器网络g(θ)。
[0076]
105:网络推断阶段:在完成生成对抗网络的参数训练后,将测试文本馈入到给定的声学模型前端网络中,生成测试梅尔谱,再将该测试梅尔谱输入到生成器中,输出生成语音信号。
[0077]
其中,声学模型前端网络为fastspeech(本领域技术人员所公知,本发明实施例对此不做赘述),经过训练后可以将文本转换为梅尔谱声学特征的神经网络。
[0078]
综上所述,本发明实施例通过上述步骤101-步骤105解决了已有gan网络技术中高频部分混叠失效的问题,减轻高频频段频谱失真。
[0079]
实施例2
[0080]
下面结合具体的计算公式、实例对实施例1中的方案进行进一步地介绍,详见下文描述:
[0081]
一、基于生成对抗网络的声码器设计
[0082]
1、网络结构
[0083]
假设在低维空间中有一个简单容易采样的分布p(z),p(z)通常为标准多元正态分布n(0,i)。用神经网络构建一个映射函数称为生成网络。利用神经网络强大的拟合能力,使得g(z)服从数据分布pr(x)。这种模型就称为隐式密度模型,所谓隐式密度模型就是指并不显式地建模pr(x),而是建模生成过程。
[0084]
隐式密度模型的一个关键是如何确保生成网络产生的样本一定是服从真实的数据分布。
[0085]
生成对抗网络就是通过对抗训练的方式来使得生成网络产生的样本服从真实数据分布。在生成对抗网络中,有两个网络进行对抗训练。一个是判别网络,目标是尽量准确地判断一个样本是来自于真实数据还是由生成网络产生;另一个是生成网络,目标是尽量生成判别网络无法区分来源的样本。这两个目标相反的网络不断地进行交替训练。当最后
收敛时,如果判别网络再也无法判断出一个样本的来源,那么也就等价于生成网络可以生成符合真实数据分布的样本。生成对抗网络的流程图如图3所示。
[0086]
判别网络(discriminator network)d(x;φ)的目标是区分出一个样本x是来自于真实分布pr(x)还是来自于生成模型p
θ
(x),因此判别网络实际上是一个二分类的分类器。用标签y=1来表示样本来自真实分布,y=0表示样本来自生成模型,判别网络d(x;φ)的输出为x属于真实数据分布的概率,即:
[0087]
p(y=1|x)=d(x;φ),
ꢀꢀ
(1)
[0088]
则样本来自生成模型的概率为p(y=0|x)=1-d(x;φ)。给定一个样本(x,y),y={1,0}表示其来自于pr(x)还是p
θ
(x),判别网络的目标函数为最小化交叉熵,即:
[0089][0090]
假设分布p(x)是由分布pr(x)和分布p
θ
(x)等比例混合而成,即混合而成,即则上式等价于:
[0091][0092][0093]
其中,θ和φ分别是生成网络和判别网络的参数。
[0094]
生成网络(generator network)的目标刚好和判别网络相反,即让判别网络将自己生成的样本判别为真实样本。
[0095][0096][0097]
上面的这两个目标函数是等价的。但是在实际训练时,一般使用前者,因为其梯度性质更好。函数log(x),x∈(0,1)在x接近1时的梯度要比接近0时的梯度小很多,接近“饱和”区间。这样,当判别网络d以很高的概率认为生成网络g产生的样本是“假”样本,即(1-d(g(z;θ);φ))
→
1,这时目标函数关于θ的梯度反而很小,从而不利于优化。
[0098]
2、生成器网络设计
[0099]
生成器是一个纯卷积的神经网络,使用梅尔谱作为输入,首先通过转置卷积(transposed convolutional)使输出序列的长度与原始波形的时间分辨率相匹配。然后每一个转置卷积后都设置一个多感受野融合模块(multi-receptive field fusion,mrf),该结构具体细节见图4。
[0100]
其中,多感受野融合模块用于并行观察各种长度的模式,最终返回多个残差模块(resblocks)的总和。通过赋予每个残差模块不同的核大小(kernel size)以及扩张率(dilation rates)以形成多感受野的结构,如图4所示。
[0101]
3、基于滤波器组频率区分的鉴别器网络设计
[0102]
识别实际语音信号波形的长程相关性并对其进行建模是一个关键问题,例如:当一个音素的持续时间大于100ms时,波形样本中就会有2200个相邻样点高度相关。该问题通过在生成器中添加多感受野融合模块进行解决。在鉴别器当中,考虑语音合成中的另一个
关键问题,即由于语音音频由不同频率成分的谐波组成,因此需要识别音频波形数据中的各种频率成分的模式。
[0103]
因此提出了多频率鉴别器(multi-frequency discriminator,mfd),该鉴别器由若干子鉴别器组成。每个子鉴别器只对音频输入的某一任意指定的短频段内的信号进行处理,该过程通过解析滤波器(analytic filter)的技术来实现,鉴别器的结构见图5所示。
[0104]
4、声码器总体损失函数设计
[0105]
在gan网络的损失上,使用最小二乘损失函数替换原始gan所使用的二元交叉熵,以用于非消失梯度流。鉴别器的训练目标是将真实语音样本归类为1,将生成器合成的语音样本归类为0。生成器的训练目标是通过不断更新合成语音样本的质量以“伪造”真实样本,使得鉴别器将此合成语音归类为几乎接近于1的值。第k个支路的鉴别器的损失函数ld(k)和整个生成器的损失函数lg如下所示:
[0106][0107][0108]
其中,x代表真实语音样本,s代表真实语音样本的梅尔谱,k表示mfd子鉴别器的编号。
[0109]
除了gan损失,还添加了梅尔谱损失(mel-spectrogram loss)来提高生成器的训练效率和生成音频的保真度。考虑到生成器的输入条件为梅尔谱,由于人耳听觉系统的特性,因此该损失函数具有提高感知质量的效果。该损失函数定义为生成器合成语音波形的梅尔谱与真实语音波形的梅尔谱之间的l1范数,如下所示:
[0110][0111]
其中,代表将波形转换为梅尔谱的过程,梅尔谱损失有助于生成器合成与输入条件对应的真实波形,并在训练的早期阶段稳定训练过程。
[0112]
特征匹配损失(feature matching loss)通过衡量鉴别器中真实样本和合成样本之间特征的差异,来衡量二者之间的相似性。该损失函数是通过提取鉴别器中的每一个中间特征,再去计算特征空间中真实样本和合成样本的中间特征的l1范数来实现的。该函数定义如下:
[0113][0114]
其中,l代表鉴别器中神经网络的层数,d
ki
表示第k个鉴别器的神经网络中第i层的特征,ni表示第i层的特征总个数。
[0115]
综上所述,最终的生成器损失lg与鉴别器损失ld为:
[0116]
lg=l
gan_g
λ
fm
l
fm
λ
mel
l
mel
(g)
ꢀꢀ
(11)
[0117]
=∑
k=1,2,
…
[l
gan_g
(dk) λ
fm
l
fm
(dk)] λ
mel
l
mel
(g)
ꢀꢀ
(12)
[0118]
ld=ld(k)
ꢀꢀ
(13)
[0119]
l
gan_g
为生成器损失,λ
fm
为特征匹配损失因子,λ
mel
为梅尔谱损失因子。
[0120]
滤波器组设计原理不失一般性,为设计带通滤波器,需构造如下长度为n的频率采
样向量h:
[0121][0122]
显然式(14)内部元素满足:
[0123]
h(k)=h(n-k), k=0,...,n-1
ꢀꢀ
(15)
[0124]
如果对式(14)的各个元素将ω∈[0,2π]内的均匀分割的n个频率采样位置(频率间隔为2π/n)相对应,则可在0、1交界的元素可导出两个截止数字角频率为:
[0125]
ω1=p2π/n, ω2=(p q-1)2π/n,
ꢀꢀ
(16)
[0126]
假定系统的采样速率为fs,则ω1、ω2对应的两个模拟频率为:
[0127]fl
=pfs/n, fh=(p q-1)fs/n,
ꢀꢀ
(17)
[0128]
相应地,两个正整数p、q应配置为:
[0129]
p=[f
l
n/fs], q=[(f
h-f
l
)n/fs] 1,
ꢀꢀ
(18)
[0130]
其中,“[
·
]”表示四舍五入取整操作。
[0131]
进而对式(14)的频率向量h做逆离散傅立叶变换,有:
[0132][0133]
进一步化简,有:
[0134][0135][0136]
进一步用欧拉公式对上式进行化简,有:
[0137][0138]
式(22)对n=0时,分母为零,故不适用。将n=0代入式(21),有:
[0139]
h(0)=2q/n
ꢀꢀ
(23)
[0140]
将(22)、(23)相结合,得到建议滤波系数g(n)的最终公式:
[0141][0142]
其中,wc(n)是一个长度为2n-1的卷积窗口,定义如下:
[0143]
wc(n)=f(n)*rn(-n), n∈[-n 1,n-1]
ꢀꢀ
(25)
[0144]
在式(25)中,{f(n),n=0,
…
,n-1}是一个长度为n的汉宁窗,{rn(n),n=0,
…
,n-1}是一个长度为n的矩形窗,c为卷积窗中心元素c=wc(0)。
[0145]
6、针对生成器输出语音频带分解的解析滤波器组设计
[0146]
在鉴别器的解析滤波器组设计当中,鉴于生成器输出语音的基频范围一般为50hz~500hz,且语音信号的能量主要集中在30hz~3400hz之间,在主要考虑基频成分,次要考虑低次谐波,不考虑较高次谐波的情况下,设置滤波器组的个数为10个。因而具体的滤波器参数设置如表1所示。
[0147]
表1解析滤波器组的参数设置
[0148][0149]
实施例3
[0150]
实验中所用音频的采样速率为22.05khz,设置频率采样向量长度n=512,以滤波器组中的第九个滤波器为例,b=(f
l
,fh)=[700hz,1000hz],将f
l
=700hz、fh=1000hz、fs=22050hz、n=512代入式(19),得p=16、q=8,进一步将长度为n的汉明窗和翻转的长度为n的矩型窗进行卷积,生成2n-1个卷积窗元素wc(n),将以上值代入式(25),可得带通滤波器系数g(n),进一步求取该滤波器的频率响应函数g(j2πf),如图6中黑色线所示。以滤波器组中得第四个滤波器为例,图7列出原始语音波形及其频谱、经过analytic filter 4滤波后的波形及其频谱。
[0151]
其次,本发明实施例在模型的端到端方面的整体效果进行了验证,首先利用一个tts前端模型进行梅尔谱中间表示的生成,然后训练该模型,利用所提出模型进行语音波形的合成,并使用hifigan模型将相同的中间表示作为输入得到生成语音波形作为对比。
[0152]
图8与图9分别为首先通过tts前端模型生成英文句子"i am very happy to see you again!"的梅尔谱,然后分别利用该模型与hifigan进行语音波形生成,最后绘制生成语音的梅尔谱。
[0153]
图10与图11所示生成语音波形梅尔谱对应的文本为"when i was twenty,i fell in love with a girl."。从图8与图9的对比、图10与图11的对比,可以明显看出本模型的生成波形梅尔谱细节更清晰,尤其在较高频谐波部分,表明本模型能够减轻高频部分混叠失效的问题。
[0154]
首先,使用ljspeech语音数据集对模型进行训练。ljspeech语音数据集包含13100条大约24小时的语音短片段,均由一个说话人所录制。音频格式为16bit pcm,采样频率是22khz。设备采用一台nvidia geforce rtx 3080gpu。
[0155]
fastspeech是一个非自回归的tts前端模型,在由文本生成梅尔谱方面是现如今最为成功的模型之一。fastspeech将文本(音素)作为输入,然后非自回归地生成梅尔谱。该模型采用基于transformer中的自注意力和一维卷积的前馈网络的结构。此外,为了解决梅尔谱序列和相应的音素序列之间的长度不匹配问题(梅尔谱序列比音素序列长很多),fast speech采用了一个长度调节器来根据音素持续时间将音素序列进行上采样,其中音素持续时间就是每一个音素所对应的梅尔谱帧的个数。fastspeech的训练依赖于一个自回归的教
师模型,以为该模型提供1)用来训练“持续时间预测器”的每一个音素的发音持续时间;2)用于知识蒸馏的生成梅尔谱。
[0156]
生成器结构参数设置,具体如下表2所示。ks
up
[i],i=1,2,3,4表示上采样模块中转置卷积核的大小,i是上采样的次数;h
up
表示隐藏维度;ks
res
[j],j=1,2,3表示mrf中残差连接里扩展卷积核的大小,j是残差块的个数;d
res
[j,n,l]表示mrf中残差连接里扩展卷积的扩张率,其中,j是残差块的序号、n是残差块里残差连接的序号、l是每个残差连接里扩展卷积的序号。
[0157]
表2生成器结构设置
[0158][0159]
其次设置本发明提出模型的细节设置,具体设置如表3所示。
[0160]
表3模型的细节设置
[0161][0162]
然后将fastspeech模型和本发明所提出的波形生成gan网络分别在ljspeech数据集上进行训练,利用fastspeech合成给定例句的梅尔谱,再使用该模型将例句的梅尔谱进行语音波形合成。
[0163]
实验表明:本发明提出的基于滤波器组频率结构区分的深度网络文本转语音波形合成方法,合成的语音波形不仅能够保证各个频率成分都不会衰减,而且可消除现有基于gan网络声码器的高频混叠的弊端,具体表现为生成语音信号的梅尔谱中谐波结构更加清晰(特别是在高频端,其谱细节更为突出),相比于已有语音声码器,可合成与人类声音更为
相近的高质量语音波形。此外,由于本发明只采用一类频率结构鉴别器取代了现有基于gan网络的模型中的两类鉴别器(多周期鉴别器和多尺度鉴别器),简化了模型结构,加快了模型训练的收敛。
[0164]
实施例4
[0165]
一种基于滤波器组频率区分的深度网络波形合成装置,该装置包括:处理器和存储器,存储器中存储有程序指令,处理器调用存储器中存储的程序指令以使装置执行以下的方法步骤:
[0166]
采用解析方法设计多个任意频率通带的滤波器组;将生成器输出的语音信号并行馈入到滤波器组中,获得多个窄频带的信号;
[0167]
将窄频带的信号分别输入到各个子鉴别器中进行处理,综合子鉴别器的损失函数对生成对抗网络的参数进行训练,将测试文本馈入到给定的声学模型前端网络中,生成测试梅尔谱,再将该测试梅尔谱输入到生成器中,生成语音信号。
[0168]
其中,生成对抗网络包括:生成器网络和鉴别器网络,生成器网络包括:转置卷积模块和多感受野融合模块;鉴别器网络由若干子鉴别器组成,每个子鉴别器对输入语音波形的某一任意指定的窄频段内的信号进行处理。
[0169]
其中,综合子鉴别器的损失函数对生成对抗网络的参数进行训练具体为:
[0170]
1)随机初始化生成器网络g(θ)与鉴别器网络d(φ)的网络参数;
[0171]
2)从训练集中采集m条语音样本,{x
(m)
},1≤m≤m;训练梅尔谱数据集中选出与这m条语音样本对应的梅尔谱样本,{s
(m)
},1≤m≤m;
[0172]
3)将{s
(m)
},1≤m≤m输入到生成器中,得到生成语音{y
(m)
},1≤m≤m,y
(m)
=g(s
(m)
);
[0173]
4)将x
(m)
与y
(m)
依次输入到k个长度为2n-1的解析窄带滤波器g1(n),
…
,gk(n)中,n∈[-n 1,-1]∪[1,n-1]
[0174]
其中,k=1
…
k,p、q分别为用于控制滤波器gk(n)的通带起始频点和带宽的整数参数,wc(n)为卷积窗,将x
(m)
与y
(m)
各自分为k个窄频段信号,再将窄频段信号分别输入对应的子鉴别器中,根据非消失梯度的迭代策略来最小化鉴别器损失函数ld,更新鉴别器网络d(φ);
[0175]
5)从训练梅尔谱数据集中采集m条样本,
[0176]
6)将m条样本输入到生成器中,经过转置卷积使输出序列的长度与原始波形x的时间分辨率相匹配;将序列输入到多感受野融合模块中,并行观察各种不同序列长度的模式,输出多个残差模块的总和,作为生成语音进而根据非消失梯度的迭代策略来最小化生成器损失函数lg,更新生成器网络g(θ)。
[0177]
这里需要指出的是,以上实施例中的装置描述是与实施例中的方法描述相对应的,本发明实施例在此不做赘述。
[0178]
上述的处理器和存储器的执行主体可以是计算机、单片机、微控制器等具有计算
功能的器件,具体实现时,本发明实施例对执行主体不做限制,根据实际应用中的需要进行选择。
[0179]
存储器和处理器之间通过总线传输数据信号,本发明实施例对此不做赘述。
[0180]
本发明实施例对各器件的型号除做特殊说明的以外,其他器件的型号不做限制,只要能完成上述功能的器件均可。
[0181]
本领域技术人员可以理解附图只是一个优选实施例的示意图,上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
[0182]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
