1.本发明涉及一种基于双分支融合模型的抑郁脑电分类方法,属于计算机应用技术领域。
背景技术:
2.抑郁症(major depression disorder,mdd)是一种常见的精神障碍疾病,其临床症状表现为对一切事物的兴趣低下、自我认同感不强和注意力不集中等症状,甚至会出现反复自残和自杀的行为。据世界卫生组织(world health organization,who)估计,到2030年抑郁症患者人数将超过所有心血疾病患者人数的总和,并且抑郁症将成为世界第一大自残诱因。在中国,抑郁症的发病人数约占总人口的4.2%,并呈现逐年上升和年轻化的趋势。抑郁症不仅会对个人造成严重的伤害,而且还会对患者家庭和社会带来负面的影响。如果能够在抑郁症早期就对患者进行正确的诊断,患者的病情就可以及时通过心理治疗、药物治疗、电休克疗法以及改变生活方式等手段得到显著的改善。因此,对抑郁症的准确率诊断具有重要意义。
3.一方面,脑电信号能够捕捉大脑毫秒级的神经元电活动,具有较高的时间分辨率和可靠性,同时价格相对低廉。另一方面,已有研究表明患者的抑郁程度主要与前额叶脑电的活跃程度和左右额叶间eeg的对称性有关。因此,可以选取大脑前额叶三通道脑电数据作为抑郁症诊断的依据。
技术实现要素:
4.为了准确地区分出健康和抑郁以及抑郁程度,本发明提供了一种基于双分支融合的抑郁脑电分类方法。该方法以前额叶三通道脑电数据的小波时频图以及原始脑电序列作为输入,来训练双分支融合模型从而区分出健康和中度抑郁脑电以及轻度脑电和中度脑电。
5.本发明为解决上述技术问题采用以下技术方案:
6.本发明提供一种基于深度学习的抑郁脑电分类方法,包括以下步骤:
7.(1)获取若干组健康人的大脑前额叶fp1、fpz和fp2电极的脑电信号,并使用滑动窗口切分成窗口数据,接着使用小波变换转换成小波时频图,最后将三个通道的小波时频图和对应的原始窗口序列作为模型的输入。
8.(2)获取若干组轻度抑郁患者的大脑前额叶fp1、fpz和fp2电极的脑电信号,并使用滑动窗口切分成窗口数据,接着使用小波变换转换成小波时频图,最后将三个通道的小波时频图和对应的原始窗口序列作为模型的输入。
9.(3)获取若干组中度抑郁患者的大脑前额叶fp1、fpz和fp2电极的脑电信号,并使用滑动窗口切分成窗口数据,接着使用小波变换转换成小波时频图,最后将三个通道的小波时频图和对应的原始窗口序列作为模型的输入。
10.(4)步骤以(1)、(2)和(3)中的健康对照、轻度抑郁患者和中度抑郁患者的输入形
式,对双分支融合模型进行训练学习。
11.(5)将待分析窗口脑电信号转换成对应的小波时频图,输入步骤(4)中训练完成的双分支融合模型,完成该脑电信号的分析。
12.作为本发明的进一步技术方案,大脑前额叶采集使用的是普适化三导脑电采集系统。
13.作为本发明的进一步技术方案,(1)、(2)和(3)的滑动窗口长度为2秒,重叠率为0。
14.作为本发明的进一步技术方案,使用的小波变换为小波变换的选取为以复morlet小波(宽带参数为3,中心波长为3)为基小波的小波变换。
15.作为本发明的进一步技术方案,双分支融合模型是以卷积神经网络和通道注意力机制为基础搭建的深度学习分类模型。
16.有益效果:本发明采用以上技术方案与现有技术相比,具有以下技术效果:本发明提出的双分支融合模型能够有效地提取脑电信号的时频特征,并且使用卷积神经网络从两个模态提取脑电的有效信息,在区分健康和中度抑郁、健康和轻度抑郁、轻度抑郁和中度抑郁以及健康和轻度抑郁和中度抑郁上的准确率、精确度、召回率和f1分数均高于现有抑郁脑电方法。
附图说明
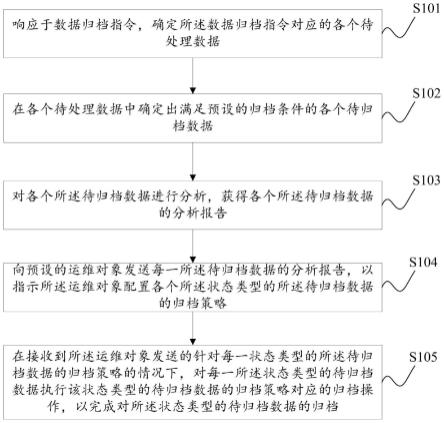
17.图1为本发明的公开的方法流程图;
18.图2为本发明设计的双分支融合模型;
19.图3为本发明中的所选取的前额叶三通道脑电位置的示意图。
具体实施方式
20.下面结合附图和具体实施方式,进一步阐明本发明。
21.实施例:如图1所示,为本发明公开的基于深度学习的抑郁脑电分类方法的流程图,具体包括以下步骤:
22.(1)获取若干组健康人的大脑前额叶fp1、fpz和fp2电极的脑电信号,并使用滑动窗口切分成窗口数据,接着使用小波变换转换成小波时频图,最后将三个通道的小波时频图和对应的原始窗口序列作为模型的输入。
23.(2)获取若干组轻度抑郁患者的大脑前额叶fp1、fpz和fp2电极的脑电信号,并使用滑动窗口切分成窗口数据,接着使用小波变换转换成小波时频图,最后将三个通道的小波时频图和对应的原始窗口序列作为模型的输入。
24.(3)获取若干组中度抑郁患者的大脑前额叶fp1、fpz和fp2电极的脑电信号,并使用滑动窗口切分成窗口数据,接着使用小波变换转换成小波时频图,最后将三个通道的小波时频图和对应的原始窗口序列作为模型的输入。
25.依据大脑前额叶和抑郁症的关系,选取了前额叶的fp1、fpz和fp2的脑电作为数据来源,并使用普适化三导脑电采集系统作为采集工具。具体的采集步骤为:i、测量鼻根点(眉心)到后脑枕骨粗隆的距离,记为从眉心到头顶取的十分之一处,记为,即为fpz的位置;ii、经过双侧乳突过头顶测量乳突间的距离取左耳乳突向头顶的十分之一处,记为点;iii、取枕骨向头顶十分之一处,取经过上左右各十分之一处,分别为fp1、fp2的位置。
26.将采集到的脑电数据按照如下预处理步骤,得到较为干净的脑电数据:首先,采用0.5hz到100hz的巴特沃斯带通滤波器获取脑电的有效频率,然后使用ica算法去除伪迹和使用50hz的陷波滤波器去除工频噪声,最后采用min-max数据归一化来防止量纲带来的影响和提高模型的收敛速度。
27.其次,使用如下步骤将脑电数据转换成适合双分支融合模型的输入形式:首先,使用滑动窗口截取脑电信号:使用长度为2秒,重叠率为0的滑动窗口来截取采集的原始脑电。然后,通过以复morlet小波(宽带参数为3,中心波长为3)为基小波的小波变换变成小波系数矩阵。最后取复morlet小波系数的模作为图片的像素值并将图片的大小采样至224x224大小。
28.(4)步骤以(1)、(2)和(3)中的健康对照、轻度抑郁患者和中度抑郁患者的输入形式,对双分支融合模型进行训练学习。
29.(4-1)双分支融合模型是由图片特征提取分支和时序特征提取分支组成。
30.(4-2)双分支融合模型中的时序特征提取分支在fcn模型中嵌入基于离散傅里叶变换系数的注意力机制。fcn分支是由三个基本块(conv1d bn relu)组成,其中三个基本块的卷积输出通道分别128,256,128。基于离散傅里叶变换系数的注意力机制是se模型在dft频域上的扩展。
31.(5)将待分析窗口脑电信号转换成对应的小波时频图,输入步骤(4)中训练完成的双分支融合模型,完成该脑电信号的分析。
32.实施例2:
33.步骤(1)(2)(3):采集受试者脑电并根据抑郁量表划分抑郁程度,接着对脑电数据进行预处理。在本实施例中,使用普适化三导脑电采集系统采集受试者大脑前额叶fp1、fpz和fp2的脑电信号,采样频率f取1000hz,并且每个受试者由至少两个专业的精神科医生经过《汉密尔顿抑郁量表》(hamilton depression rating scale,hdrs-17)进行分组,共分为20例健康人、34例轻度抑郁患者和29例中度抑郁患者。然后使用长度为2s,重叠率为0的滑动窗口切分每个受试者的三导脑电信号,并将其经过以复morlet小波(宽带参数为3,中心波长为3)为基小波的小波变换变成小波系数矩阵,接着取复morlet小波系数的模作为图片的像素值并将图片的大小采样至224
×
224大小。最后,将三张小波时频图与其对应的原始脑电序列组成输入张量。
34.步骤(4),构建双分支融合模型并将输入张量输入到双分支融合模型中进行训练。在本实施例中,双分支融合模型的参数如下表。图片特征提取分支下方的conv表示二维卷积层,而特征提取分支的conv表示一维卷积层;bn表示批量归一化,relu表示relu层,maxpool表示最大池化层。
35.1)特征提取模块1:由一维卷积层、批量归一化层、relu层、dropout层和dftc-att层的丢弃率为0.3;
36.2)特征提取模块2:结构上,与特征提取模块1完全相同;参数上,卷积核的大小变为了5,卷积层输入和输出的通道数变成了128和256。
37.3)特征提取模块3:结构上,对比特征提取模块1,使用gap替换了dftc-att;参数上,卷积核的大小变为3,卷积层输入和输出的通道数变成了256和128。
38.最后,将两个分支学习到的特征向量拼接成最终的特征向量(长度为192),并经过
分类模块输入分类结果。
39.步骤(5),利用准确率、精确率、召回率和f1分数对模型学习的效果进行评估。
40.本发明中,记non-de为健康受试者,mid-de为轻度抑郁患者,con-de为中度抑郁患者,tn(true negative,真阴性)为被模型预测为负类的负类样本,fp(false positive,假阳性)为被模型预测为正类的负类样本,fn(false negative,假阴性)为被模型预测为负类的正类样本,则,准确率(accuracy)定义为所有样本正确分类的概率:
[0041][0042]
精确率(precision)可分为正类样本的精确率和负类样本的精确率,正类样本的精确率即为在预测为正类的样本中实际也为正类的占比:
[0043][0044]
负类样本的精确率为在预测为负类的样本中实际也为负类的占比:
[0045][0046]
召回率(recall)也可分为正类样本的召回率和负类样本的召回率,正类样本的召回率即为在实际为正类的样本中,被判定为正类的占比:
[0047][0048]
负类样本的召回率为在实际为负类的样本中,被判定为负类的占比:
[0049][0050]
f1值综合考虑了精确率和召回率,为精确率和召回率的调和平均数,常作为机器学习分类方法的最终评价方法,每一类的f1值越高代表分类结果越好。每个类别下的f1值表示为:
[0051][0052]
本发明中采用不同分类模型(resnet、fcn、mlstm-fcn、cnn-lstm)作为对比,如表1至表4所示。
[0053]
表1 non-de和con-de任务下不同分类方法的结果对比
[0054][0055]
表2 non-de和mid-de任务下不同分类方法的结果对比
[0056][0057]
表3 mid-de和con-de任务下不同分类方法的结果对比
[0058][0059]
表5 non-de和mid-de和con-de任务下不同分类方法结果对比
[0060][0061]
从表1至表5的实验结果可以得出,本发明的分类效果要明显好于其他模型。
[0062]
以上所述,仅为本发明中的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉该技术的人在本发明所揭露的技术范围内,可理解想到的变换或替换,都应涵盖在本发明的包含范围之内,因此,本发明的保护范围应该以权利要求书的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。