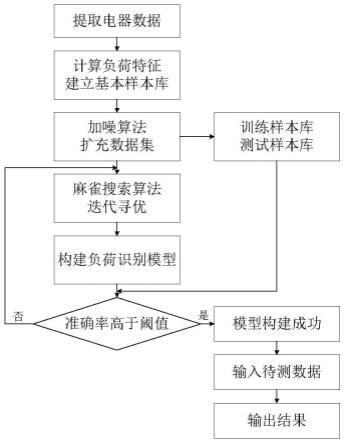
1.本发明属于非侵入式负荷识别监测领域,具体涉及一种基于自适应优化随机森林的非侵入式负荷识别方法。
背景技术:
2.居民用电负荷监测作为智能电网建设体系下的关键一环,其中的一项重点研究方向便是非侵入式的负荷识别。为了实现客户侧居民用电负荷识别的实时性与有效性,各种不同的算法被应用其中,取得了一个又一个的进展与突破。但是,随着经济的发展,居民的用电手段也越来越多,每家每户的负载类型之间可能有着非常大的不同,这大大降低了识别算法对于不同用户的普适性,一个训练好的模型可能对于某一家用户有很高的识别精度,但却无法很好的应用于其他用户。
3.所以,需要一个新的技术方案来解决这个问题。
技术实现要素:
4.发明目的:为了克服现有技术中存在的识别模型普适性差的不足,提供一种基于自适应优化随机森林的非侵入式负荷识别方法,通过将麻雀搜索算法内嵌入其中,在应用随机森林进行模型训练之前,对参数进行优化,使对应模型能够更完美的契合指定的特征样本库,提升识别模型对于不同用户负荷类型的自适应能力。
5.技术方案:为实现上述目的,本发明提供一种基于自适应优化随机森林的非侵入式负荷识别方法,包括如下步骤:
6.s1:提取负荷稳态工作时的电气数据,计算对应负荷类型的稳态特征,根据稳态特征建立基本样本库;
7.s2:使用加噪算法,在基本样本库的基础上进行数据扩充,分别建立训练样本库和测试样本库;
8.s3:初始化麻雀种群参数,将随机森林模型对负荷的识别准确率作为适应度函数,传入麻雀搜索算法模块,迭代寻优,获取随机森林模型的最优参数;
9.s4:使用得到的最优参数初始化随机森林模型,使用训练样本库训练模型,并用测试样本库进行验证,获取到识别模型;
10.s5:将待测数据输入到识别模型,通过识别模型输出负荷类型。
11.进一步地,所述步骤s1中电气数据包括电流有效值、电压有效值、电流的各次谐波、电压与电流的相位差。
12.进一步地,所述步骤s1中负荷类型的稳态特征包括电流平均有效值、电压与电流的比值、电流三次谐波畸变、电流五次谐波畸变、有功功率、无功功率。
13.负荷类型的稳态特征的计算公式如下:
14.15.p=utcosα
16.q=uisinα
17.其中,thd为谐波畸变,ik为第k次谐波,i
t
为第t次谐波,用于计算第t次谐波畸变;p和q分别为有功功率和无功功率,α为电压与电流对应的绝对相位差。
18.进一步地,所述步骤s2中使用的加噪算法采取在原特征值数据的基础上,添加加性随机高斯白噪声的方式进行数据扩充,具体的公式为:
19.value=value0 gauss(mu,s)
20.其中,value0表示原特征值,gauss表示随机高斯白噪声,mu和s分别表示白噪声的均值和方差。
21.进一步地,所述步骤s2中为了符合原始数据的实际噪声情况,高斯白噪声的方差基于原始数据的波动方差来决定,训练样本特征库数据采取1倍基本方差来生成加性噪声,测试样本特征库采取1.5倍基本方差来生成加性噪声。
22.进一步地,所述步骤s3中随机森林模型的最优参数的获取过程为:
23.初始化麻雀种群参数,包括种群数量、迭代次数、维度,其中,迭代次数和维度分别表示随机森林依据的决策树数量和最小叶子节点数,设定两个参数的上下边界;
24.适应度函数为随机森林对负荷类型的识别准确率变化函数,将训练样本库划分为训练数据和验证数据,划分比例为2:8,每次迭代根据上次迭代得到的最优参数来初始化随机森林,并用训练数据进行训练,最后使用验证数据得到识别准确率并返回给下一轮迭代,直至获取到随机森林模型的最优参数。
25.进一步地,所述步骤s3中麻雀搜索算法的具体算法过程为:
26.将种群内的个体分为探索者和追随者,其中在每次迭代过程中,探索者的位置更新公式为:
[0027][0028]
其中,x
i,j
为麻雀个体位置,i为当前迭代次数,iter
max
为最大的迭代次数,α为[0,1]内的随机数,r2和st分别为预警值和安全值,q为服从正态分布的随机值,l为1
×
d的矩阵,内部的值全为1;
[0029]
追随者的位置更新公式为:
[0030][0031]
其中,x
p
为最优探索者的位置,x
worst
为当前全局最差的位置,n为种群规模,a为一个1
×
d的矩阵,每个元素随机幅值为1或-1,且有a
=a
t
(aa
t
)-1
。
[0032]
进一步地,所述步骤s4具体为:
[0033]
利用麻雀搜索算法得到的最优参数,初始化随机森林模型,使用完整的训练样本库进行训练,并使用测试样本库进行验证,判断识别准确率是否符合设定阈值要求,如果低
于设定阈值,则返回步骤s3,增大迭代次数,从而修正参数值。
[0034]
本发明通过将随机森林算法应用于非侵入的负荷识别,提高了识别准确率,进一步地采用麻雀搜索算法,实现随机森林重点参数的自适应优化,能够保证在不同环境下的高识别准确率。
[0035]
有益效果:本发明与现有技术相比,具备如下优点:
[0036]
1、本发明基于数据本身的噪声波动情况,将对应方差作为数据库扩充的依据,能够很好的模拟负荷实际运行所收到的干扰,使得模型建立过程中所依赖的数据更加合理可靠。
[0037]
2、本发明通过将随机森林算法应用于非侵入式负荷识别,利用样本抽取的随机性,使其具有较高的基础分类精度,为多用户类型的自适应识别提供基础。
[0038]
3、本发明将麻雀搜索算法,内嵌入随机森林的模型训练体系中,使其对于不同类型用户用电负荷,能够获取对应的最优参数进行初始化,使对应模型能够更完美的契合指定的特征样本库,提升识别模型对于不同用户负荷类型的自适应能力,从而提高了整体识别精度与泛化能力。
附图说明
[0039]
图1是本发明方法的流程示意图;
[0040]
图2是本发明中基于麻雀搜索算法的自适应参数寻优算法的流程示意图;
[0041]
图3是本发明提出的改进随机森林模型应用于大量待测数据的识别结果图;
[0042]
图4为不同噪声条件下各模型的识别准确率图。
具体实施方式
[0043]
下面结合附图和具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本技术所附权利要求所限定的范围。
[0044]
本发明提供一种基于自适应优化随机森林的非侵入式负荷识别方法,如图1所示,包括如下步骤:
[0045]
s1:通过数据采集模块提取负荷稳态工作时的电气数据,计算对应负荷类型的稳态特征,根据稳态特征建立基本样本库;
[0046]
电气数据包括电流有效值、电压有效值、电流的各次谐波、电压与电流的相位差;
[0047]
负荷类型的稳态特征包括电流平均有效值、电压与电流的比值、电流三次谐波畸变、电流五次谐波畸变、有功功率、无功功率;
[0048]
负荷类型的稳态特征的计算公式如下:
[0049][0050]
p=utcosα
[0051]
q=uisinα
[0052]
其中,thd为谐波畸变,ik为第k次谐波,i
t
为第t次谐波,用于计算第t次谐波畸变;p
和q分别为有功功率和无功功率,α为电压与电流对应的绝对相位差。
[0053]
s2:数据预处理,使用加噪算法,在基本样本库的基础上进行数据扩充,分别建立模型训练所要使用的训练样本库和数据验证所要使用的测试样本库;
[0054]
具体的扩充方法为在基本样本库的基础上,采取在原特征值数据的基础上,添加加性随机高斯白噪声的方式进行数据扩充,具体的公式为:
[0055]
value=value0 gauss(mu,s)
[0056]
其中,value0表示原特征值,gauss表示随机高斯白噪声,mu和s分别表示白噪声的均值和方差;
[0057]
为了符合原始数据的实际噪声情况,本实施例中高斯白噪声的方差基于原始数据的波动方差来决定,训练样本特征库数据采取1倍基本方差来生成加性噪声,测试样本特征库采取1.5倍基本方差来生成加性噪声。
[0058]
s3:用麻雀搜索算法对随机森林所需参数进行自适应调优,具体如下:
[0059]
初始化麻雀种群参数:本实施例中麻雀搜索算法的参数设置为:种群数量设置为20,迭代次数设置为30,维度设置为2,分别表示随机森林依据的决策树数量和最小叶子节点数,两个参数的上下边界分别为(1,50)和(1,20)。
[0060]
将随机森林模型对负荷的识别准确率作为适应度函数,传入麻雀搜索算法模块,迭代寻优,获取随机森林模型的最优参数;
[0061]
本实施例中适应度函数为随机森林对负荷类型的识别准确率变化函数,将训练样本库划分为训练数据和验证数据,划分比例为2:8,每次迭代根据上次迭代得到的最优参数来初始化随机森林,并用训练数据进行训练,最后使用验证数据得到识别准确率并返回给下一轮迭代,直至获取到随机森林模型的最优参数。
[0062]
s4:随机森林模型的构建:
[0063]
使用麻雀搜索算法计算得到的最优参数初始化随机森林模型,使用训练样本库训练模型得到初步的识别模型,并用测试样本库进行验证,如果识别准确率高于设定阈值,则表示最终识别模型构建完毕,否则返回步骤三重新调整参数。
[0064]
s5:将待测数据输入到识别模型,通过识别模型输出负荷识别类型。
[0065]
如图2所示,上述步骤s3中基于麻雀搜索算法的自适应参数寻优算法的具体步骤如下:
[0066]
步骤一:初始化种群,设种群有n只麻雀(本实施例中初步设置为20,可以通过实际情况进行调整),则由所有个体组成的种群可以表示为x=[x
1 x2…
xn]
t
,适应度值为fi=f(x1,x2,
…
,xn),适应度函数为第i代随机森林识别准确率,参数为需要寻优的随机森林参数,其个数为预先设定好的维度,种群中的每一个个体是维度大小的向量。
[0067]
步骤二:将麻雀种群中所有的n只麻雀,选取种群中位置最好的pn只为探索者,剩余的麻雀设定为追随者。
[0068]
步骤三:更新探索者位置。每一代发现者的位置更新公式如下:
[0069]
[0070]
其中,x
i,j
为麻雀个体位置,i为当前迭代次数,iter
max
为最大的迭代次数,α为[0,1]内的随机数,r2和st分别为预警值和安全值,r2为[0,1]中的均匀随机数,st的取值范围是[0.5,1],q为服从正态分布的随机值,l为1
×
d的矩阵,内部的值全为1。
[0071]
步骤四:更新追随者位置。每一代追随者的位置更新公式如下:
[0072][0073]
其中,x
p
为最优探索者的位置,x
worst
为当前全局最差的位置,n为种群规模,a为一个1
×
d的矩阵,每个元素随机幅值为1或-1,且有a
=at(aa
t
)-1
;
[0074]
步骤五:随机选择警戒者并更新位置。种群中的部分个体会负责警戒,当危险靠近时,他们会放弃当前食物,及无论探索者还是在追随着,都将放弃当前食物移动到一个新的位置。每一代将从种群中随机选取sd个个体进行预警,位置更新公式如下:
[0075][0076]
其中,x
best
为当前全局最优位置,β为步长控制参数,其值为服从均值为0,方差为1的正态分布的随机数,k为[-1,1]内一随机数,f为适应度值,fg和fw分别为当前最优、最差适应度值,ε为避免分母为0的常数。
[0077]
步骤六:获取最优参数并输出。
[0078]
本发明提供一种基于自适应优化随机森林的非侵入式负荷识别模型,该模型包括数据采集模块、特征库建立模块、自适应参数调节模块、随机森林训练模块、负荷类型输出模块。该模型的运行过程为:
[0079]
首先通过数据采集模块获取到所需数据,将其传送给特征库建立模块进行特征提取,并建立训练与测试样本库;通过自适应参数调节模块,利用麻雀搜索算法自适应参数寻优,将最优参数输出,进行随机森林建模;最后根据训练与测试样本库,建立对应的识别模型,对输入的待测负荷继续识别,并输出识别类型。
[0080]
为了验证本发明方法和模型的实际效果,本实施例中利用本发明方法和模型对大量测试数据进行识别,识别结果具体如图3所示,图中横轴表示待测数据的序号,共1210组数据,纵轴表示模型识别出的负荷类型的序号,纵轴表示每组数据的识别结果,即待测数据经过模型输出的识别类型,为了表示方便,使用序号来代替实际的负荷类型(如使用1代替48v电池 60v电池的组合)。总体来看,例如数据1-25的识别结果为负荷类型0,则表示识别正确,以此类推。则从图中可以看出,部分零散的点为识别错误的数据,通过识别正确数可以大致看出模型的识别准确率,属于较高的水平。
[0081]
所以从图3可以看出,通过对大量测试数据的识别,其准确率有着较高的水准,能够满足非侵入式条件下对居民用电负荷类型的识别。
[0082]
为了进一步验证本发明所提供的优化后的随机森林模型的识别效果,本实施例中将本发明的随机森林模型与现有的决策树模型和bagging模型同时在不同噪声条件下进行
识别,识别结果如图4所示,从图4中可以看出,对待测数据提高噪声干扰强度,本专利所提出的优化随机森林模型有很好的识别准确率。在低噪声强度下,本模型识别准确率很高,而且相比于bagging算法,本模型在高噪声情况下有更好的识别效果,表明其抗干扰能力更强。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
