基于张量分解和模糊c-均值聚类的协同推荐算法
技术领域
1.本发明涉及协同过滤推荐算法技术领域,尤其涉及基于张量分解和模糊c-均值聚类的协同推荐算法。
背景技术:
2.随着互联网技术的快速发展以及大数据时代的来临,信息过载问题日益严重,用户想要从海量信息中找到自己所需要的信息越来越难。目前,大部分的电影在线平台,如迅雷、豆瓣电影等,都不同程度地应用推荐系统为用户推荐适合的影片,由此可见,个性化推荐技术能有效解决信息过载问题。与此同时,研究者们也越发关注如何为用户提供高效、准确的推荐服务这一热点问题。
3.协同过滤算法是推荐系统中具有代表性的一种算法。它一般分为基于内存的协同过滤算法和基于模型的协同过滤算法。其中,基于内存的协同过滤算法是通过计算用户或项目之间的相似度来预测用户对项目的喜好程度;基于模型的协同过滤算法是利用机器学习的思想建模来预测空白的物品和数据之间的评分关系,并找到最高评分的物品推荐给用户。另外,研究者们也将多种推荐算法进行融合,提出混合推荐算法,从而提高推荐精度。然而,协同过滤也面临着各种各样的挑战,如冷启动、可扩展性差、数据稀疏等问题。大数据时代,随着用户和项目数量的迅猛增长,在某些购物网站上,受多种因素影响,用户对所购买商品很少进行评分,这就导致了用户项目评分数据矩阵异常稀疏,在这种情况下,采用传统的协同过滤推荐算法为用户进行推荐,推荐质量明显下降。
4.为了解决数据稀疏性问题,所以亟需一种基于张量分解和模糊 c-均值聚类的协同推荐算法来改变这一现状。
技术实现要素:
5.本发明的目的是为了解决现有技术中存在的缺点,而提出的基于张量分解和模糊c-均值聚类的协同推荐算法。其优点在于具有很好的推荐性能。
6.为了实现上述目的,本发明采用了如下技术方案:
7.基于张量分解和模糊c-均值聚类的协同推荐算法,包括以下步骤:
8.s1:首先,捕捉一些个性化的信息,在传统的用户项目的二元关系基础上,增加项目类型等多个维度的信息,构成张量;
9.s2:综合考虑用户、项目和项目类别三个方面,构建一个三阶张量,通过张量分解可以充分挖掘数据的隐含信息,采用梯度下降对三阶张量进行分解,得到用户特征矩阵、项目特征矩阵和项目类别特征矩阵,从而求得缺失值,解决张量的稀疏性;
10.s3:将张量分解的过程看作是一个低秩逼近问题,如果简单地使总的误差最小,那么,可以将张量分解的逼近问题转化为一个无约束的优化问题,并得到优化公式;
11.s4:根据以上思路,设计基于张量分解的稀疏张量填充算法,得到的用户特征矩阵、项目特征矩阵、类别特征矩阵以及填充后的张量。
12.通过采用以上技术方案:一方面,利用张量分解对缺失数据进行填充,降低其稀疏性,并挖掘潜在信息,去除噪声;另一方面,基于填充后的矩阵,采用模糊c-均值聚类算法对用户进行分类,减小目标用户的最近邻搜索空间,提高算法的可扩展性,最后用传统推荐算法在目标用户所在的类中产生推荐结果,具有很好的推荐性能。
13.本发明进一步设置为,所述张量的稀疏性分解公式为其中,u
mk
表示用户特征矩阵的用户因子; v
nk
表示项目特征矩阵的项目因子;c
ck
表示项目类别矩阵的类别因子。
14.通过采用以上技术方案:可计算出张量r在位置索引上的评分估计值。
15.本发明进一步设置为,所述优化公式为
16.通过采用以上技术方案:通过优化公式可以使得总的误差最小。
17.本发明进一步设置为,所述稀疏张量填充算法包括第一算法和第二算法。
18.通过采用以上技术方案:两种算法可以针对不同的条件进行计算,降低了计算时的转化难度。
19.本发明进一步设置为,所述第一算法为输入原始张量r,用户数m、项目数n、迭代步长η以及项目类别数c;
20.输出:u、v、c、
21.begin
22.1initialize the u∈rm×k,v∈rn×k,c∈rc×k23.2for r
mnc
≠0do
[0024]3[0025]4[0026]5[0027]6[0028]
7 end
[0029]
8 returnu、v、c、
[0030]
end。
[0031]
通过采用以上技术方案:第1行初始化用户特征矩阵、项目特征矩阵和类别特征矩阵;第2~7行进行张量分解,并通过迭代法填充稀疏张量;第8行返回得到的用户特征矩阵、项目特征矩阵、类别特征矩阵以及填充后的张量。
[0032]
本发明进一步设置为,所述第二算法为输入用户项目评分数据集 a,项目类别数据集b,模糊系数m1,聚类数c1,收敛精度epsm,迭代次数t。
[0033]
输出:目标用户u对未评分项目i的预测评分p
ui
。
[0034]
begin
[0035]
1 m1←
2,c1←
3,epsm
←
1.0e-6,t
←
100,
[0036]
2 r
←
data(a,b)
[0037]3[0038]
4[s,v',obj]
←
fcm(u,c1,t,m1,epsm)
[0039]
5 user
category
←
max(s)
[0040]
6 cu←
(user
category
,u)
[0041]
7 for v∈cu∩v≠u∩r
vi
≠0
[0042]
8 n
←
n∪v
[0043]
9 end
[0044]
10
[0045]
11.return p
ui
[0046]
end。
[0047]
通过采用以上技术方案:第1行进行初始化;第2行基于评分矩阵及项目类别矩阵构造用户-项目-类别三维张量;第3行基于张量分解填充稀疏张量得到用户特征矩阵、项目特征矩阵和类别特征矩阵;第4行基于得到的用户特征矩阵对用户进行模糊聚类;第5行通过求最大隶属度得到用户所属类别矩阵;第6行找到用户u所属类别;第 7~9行得到用户u所属类别里对项目i进行评分的用户集合;第10~11 行计算用户u对项目i的预测评分并返回。
[0048]
本发明进一步设置为,根据随机梯度下降法对u
mk
、v
nk
和c
ck
进行迭代更新,公式如下所示:下所示:其中,a(a》0) 表示梯度下降的步长,又称为学习率;s表示张量中所能观测到的位置索引集合。n,c:(m,n,c)∈s、m,c:(m,n,c)∈s、m,n:(m,n,c)∈s分别表示r(m,:,:)、 r(:,n,:)、r(:,:,c)上所有非零元素的位置索引所构成的集合。
[0049]
通过采用以上技术方案:根据随机梯度下降法对u
mk
、v
nk
和c
ck
进行迭代更新可进一步方便使得总的误差最小,提高了计算的便捷性。
[0050]
本发明进一步设置为,所述第一算法和第二算法算出的结果均需进行试验与评价,评价计算公式为
[0051]
其中,n为测试集大小,p
ui
为推荐算法的预测评分,r
ui
为用户的真实评分;
[0052]
另外,衡量推荐结果的准确性也可以采用准确率(precision)和召回率(recall),它们的数值越大,表示推荐效果越好;
[0053]
准确率(precision)公式如下:
[0054]
[0055]
召回率(recall)公式如下:
[0056][0057]
其中,p(u)表示系统为用户u推荐的项目集合,t(u)表示用户u喜好的项目集合。
[0058]
通过采用以上技术方案:可以更加直观的反映出协同推荐算法相对于现有算法的优势,同时可以验证协同推荐算法是否合理。
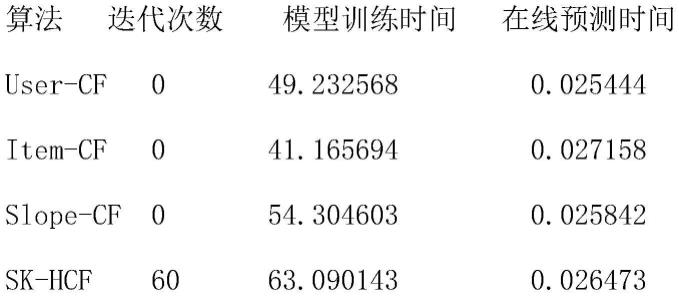
[0059]
本发明的有益效果为:
[0060]
本发明针对传统协同过滤推荐算法中的数据稀疏性问题,提出了基于张量分解和模糊聚类的协同过滤推荐算法,一方面,利用张量分解对缺失数据进行填充,降低其稀疏性,并挖掘潜在信息,去除噪声;另一方面,基于填充后的矩阵,采用模糊c-均值聚类算法对用户进行分类,减小目标用户的最近邻搜索空间,提高算法的可扩展性,最后用传统推荐算法在目标用户所在的类中产生推荐结果,具有很好的推荐性能。
附图说明
[0061]
图1为本发明提出的基于张量分解和模糊c-均值聚类的协同推荐算法的流程结构示意图;
[0062]
图2为本发明提出的基于张量分解和模糊c-均值聚类的协同推荐算法的张量建模结构示意图;
[0063]
图3为本发明提出的基于张量分解和模糊c-均值聚类的协同推荐算法的张量分解填充结构示意图;
[0064]
图4为本发明提出的基于张量分解和模糊c-均值聚类的协同推荐算法的基于fcm的协同推荐结构示意图。
[0065]
图5为本发明提出的基于张量分解和模糊c-均值聚类的协同推荐算法的k值对实际预测结果的影响的结构示意图。
[0066]
图6为本发明提出的基于张量分解和模糊c-均值聚类的协同推荐算法的聚类数对推荐精度的影响的结构示意图。
[0067]
图7为本发明提出的基于张量分解和模糊c-均值聚类的协同推荐算法的目标用户邻居数目对mae值的影响的结构示意图。
[0068]
图8为本发明提出的基于张量分解和模糊c-均值聚类的协同推荐算法的准确率和召回率的结构示意图。
具体实施方式
[0069]
下面结合具体实施方式对本专利的技术方案作进一步详细地说明。
[0070]
参照图1-4,基于张量分解和模糊c-均值聚类的协同推荐算法,包括以下步骤:
[0071]
s1:首先,捕捉一些个性化的信息,在传统的用户项目的二元关系基础上,增加项目类型等多个维度的信息,构成张量;
[0072]
s2:综合考虑用户、项目和项目类别三个方面,构建一个三阶张量,通过张量分解可以充分挖掘数据的隐含信息,采用梯度下降对三阶张量进行分解,得到用户特征矩阵、项目特征矩阵和项目类别特征矩阵,从而求得缺失值,解决张量的稀疏性;
[0073]
s3:将张量分解的过程看作是一个低秩逼近问题,如果简单地使总的误差最小,那么,可以将张量分解的逼近问题转化为一个无约束的优化问题,并得到优化公式;
[0074]
s4:根据以上思路,设计基于张量分解的稀疏张量填充算法,得到的用户特征矩阵、项目特征矩阵、类别特征矩阵以及填充后的张量。
[0075]
一方面,利用张量分解对缺失数据进行填充,降低其稀疏性,并挖掘潜在信息,去除噪声;另一方面,基于填充后的矩阵,采用模糊 c-均值聚类算法对用户进行分类,减小目标用户的最近邻搜索空间,提高算法的可扩展性,最后用传统推荐算法在目标用户所在的类中产生推荐结果,具有很好的推荐性能。
[0076]
本实施例中,所述张量的稀疏性分解公式为其中,u
mk
表示用户特征矩阵的用户因子; v
nk
表示项目特征矩阵的项目因子;c
ck
表示项目类别矩阵的类别因子。通过张量的稀疏性分解公式可计算出张量r在位置索引上的评分估计值。
[0077]
本实施例中,所述优化公式为通过优化公式可以使得总的误差最小。
[0078]
本实施例中,所述稀疏张量填充算法包括第一算法和第二算法。通过两种算法可以针对不同的条件进行计算,降低了计算时的转化难度。
[0079]
本实施例中,所述第一算法为输入原始张量r,用户数m、项目数n、迭代步长η以及项目类别数c;
[0080]
输出:u、v、c、
[0081]
begin
[0082]
1 initialize the u∈rm×k,v∈rn×k,c∈rc×k[0083]
2 for r
mnc
≠0do
[0084]3[0085]4[0086]5[0087]6[0088]
7 end
[0089]
8 returnu、v、c、
[0090]
end。
[0091]
第1行初始化用户特征矩阵、项目特征矩阵和类别特征矩阵;第 2~7行进行张量分解,并通过迭代法填充稀疏张量;第8行返回得到的用户特征矩阵、项目特征矩阵、类别特征矩阵以及填充后的张量。
[0092]
本实施例中,所述第二算法为输入用户项目评分数据集a,项目类别数据集b,模糊系数m1,聚类数c1,收敛精度epsm,迭代次数t。
[0093]
输出:目标用户u对未评分项目i的预测评分p
ui
。
[0094]
begin
[0095]
1 m1←
2,c1←
3,epsm
←
1.0e-6,t
←
100,
[0096]
2 r
←
data(a,b)
[0097]3[0098]
4[s,v',obj]
←
fcm(u,c1,t,m1,epsm)
[0099]
5 user
category
←
max(s)
[0100]
6 cu←
(user
category
,u)
[0101]
7 for v∈cu∩v≠u∩r
vi
≠0
[0102]
8 n
←
n∪v
[0103]
9 end
[0104]
10
[0105]
11.return p
ui
[0106]
end。
[0107]
第1行进行初始化;第2行基于评分矩阵及项目类别矩阵构造用户-项目-类别三维张量;第3行基于张量分解填充稀疏张量得到用户特征矩阵、项目特征矩阵和类别特征矩阵;第4行基于得到的用户特征矩阵对用户进行模糊聚类;第5行通过求最大隶属度得到用户所属类别矩阵;第6行找到用户u所属类别;第7~9行得到用户u所属类别里对项目i进行评分的用户集合;第10~11行计算用户u对项目i 的预测评分并返回。
[0108]
本实施例中,根据随机梯度下降法对u
mk
、v
nk
和c
ck
进行迭代更新,公式如下所示:进行迭代更新,公式如下所示:其中,a(a》0)表示梯度下降的步长,又称为学习率;s表示张量中所能观测到的位置索引集合。 n,c:(m,n,c)∈s、m,c:(m,n,c)∈s、m,n:(m,n,c)∈s分别表示r(m,:,:)、r(:,n,:)、 r(:,:,c)上所有非零元素的位置索引所构成的集合。通过根据随机梯度下降法对u
mk
、v
nk
和c
ck
进行迭代更新可进一步方便使得总的误差最小,提高了计算的便捷性。
[0109]
本实施例中,所述第一算法和第二算法算出的结果均需进行试验与评价,评价计算公式为
[0110]
其中,n为测试集大小,p
ui
为推荐算法的预测评分,r
ui
为用户的真实评分。
[0111]
另外,衡量推荐结果的准确性也可以采用准确率(precision)和召回率(recall),它们的数值越大,表示推荐效果越好。
[0112]
准确率(precision)公式如下:
[0113][0114]
召回率(recall)公式如下:
[0115][0116]
其中,p(u)表示系统为用户u推荐的项目集合,t(u)表示用户u喜好的项目集合。通过试验与评价可以更加直观的反映出协同推荐算法相对于现有算法的优势,同时可以验证协同推荐算法是否合理。
[0117]
在第一个试验中,基于张量分解填充后的数据进行协同过滤推荐,测试不同的k值(张量的秩)对实际预测结果的影响,设置k的取值范围为[10,60],对得出结果用mae评价,实验结果参照图5所示。
[0118]
由图可知,在不同的k值下分解张量,随着k值的增加,mae的值减小,即随着k的增加推荐精度提高,在k=50时,推荐精度最高。因此选取50为张量的秩,在保证推荐精度的基础上降低了算法的计算复杂度。
[0119]
本文算法的推荐效果不仅与张量的秩相关,也取决于聚类个数 c1的大小。因此,在第二个实验中,需要研究聚类个数对推荐准确度的影响。同时,探究fcm聚类相较于传统的k-means聚类和层次聚类的优势。首先,令k=50,c1=3,聚类数每次增加1,直到c1=8,并依次得出其分别对应的mae值,以此探究聚类数对推荐精度的影响,如图6所示。
[0120]
由图所知,在三种聚类算法中,总体上,fcm算法的聚类效果最好,并且当c1=4时,取得其全局最优点,mae的值最小,推荐精度最高。
[0121]
为了验证本文算法的性能,将本文所提出的算法cf-tdfc和以下 4种算法进行对比实验分析。
[0122]
(1)user-cf[25]:基于用户协同过滤推荐算法。
[0123]
(2)item-cf[26]:基于项目的协同过滤推荐算法。
[0124]
(3)slope-cf[19]:基于slope-one算法改进评分矩阵填充的协同过滤算法研究。
[0125]
(4)sk-hcf[27]:基于svd填充和用户属性特征聚类的混合推荐算法。
[0126]
将以上5种算法在数据集movielens上进行对比实验,设置邻居区间为[10,70],间隔为10,并使用mae值来衡量推荐精度的大小,以探究邻居数目对mae的影响,并求得最优解,其值越小则说明推荐精度越高。
[0127]
由图7的实验数据表明:总体上,user-cf、slope-cf、sk-hcf 及cf-tdfc这4种协同过滤推荐算法的mae值会随着目标用户邻居数目的增加而逐渐减小,并且它们分别在邻居数目为60、60、40及50 时取得全局最优解,而item-cf的mae值与邻居数目无关。此外,无论邻居数目的取值大小,本文提出的基于张量分解和模糊c-均值聚类的协同过滤推荐算法的mae值都是最小的,主要是因为cf-tdfc算法利用张量分解对缺失数据进行填充,有效缓解了数据稀疏性问题,提高了评分预测的准确性,在mae衡量标准上,与item-cf、user-cf、 slope-cf及sk-hcf算法相比有较好的精确度。
[0128]
为了进一步说明实验的有效性,基于movielens数据集采用准确率和召回率评价推荐结果的准确性,准确率和召回率的数值越大,则推荐质量越好。
[0129]
从图8看出,item-cf和user-cf算法的准确率和召回率差距不大,slope-cf和sk-hcf算法相较于传统的算法推荐效率有一定的提高,而本文所提的cf-tdfc算法的准确率和召回率均优于图中其他4 种算法,是由于算法cf-tdfc不仅利用张量分解缓解了极端稀疏性张量的弊端,还用fcm算法减小最近邻搜索范围,有效缓解了相似度计算过程中,用户数
量巨大引起的可扩展性问题,降低了计算复杂度,提高了算法推荐质量。
[0130]
为了评价算法的时间复杂度,根据本文算法和对比算法的模型训练时间来对比分析算法的时间性能。
[0131][0132][0133]
由上述数据可知,算法cf-tdfc的模型训练时间较长,由于该算法首先需要进行张量分解和模糊聚类操作,并对用户特征矩阵、项目特征矩阵和类别特征矩阵进行迭代运算;其次是算法sk-hcf,主要包括svd分解和k-means聚类操作以及对用户特征矩阵和项目特征矩阵的迭代运算,算法user-cf、item-cf及slope-cf算法用时相差不大。对于在线预测时间而言,5种算法用时都相差无几,时间很短。
[0134]
经由以上一系列对比实验表明,本文提出的cf-tdfc算法在保证时间效率的前提下,推荐性能优于现有的其他算法。
[0135]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。