1.本发明涉及卫星视频目标跟踪领域,特别涉及一种通过引入光流注意力、运动掩膜来融合目标运动信息,结合孪生网络结构对卫星目标进行跟踪的技术方法。以数据驱动的方式完成整个跟踪网络的训练,实现对卫星视频中的飞机、轮船等目标的准确和实时跟踪。
背景技术:
2.目前,自然视频中的目标跟踪技术已经得到较为成熟的发展,并在城市道路监测、车流量分析以及无人驾驶方面都有广泛应用。但是基于卫星视频的目标跟踪技术目前还存在较大的改善空间。卫星视频中目标大多缺乏丰富的纹理信息和色彩信息,对于车辆类较小的目标来说,所占据的像素较少,代表性特征不明显,目标与背景的相似度较高,且存在较多难以分辨的伪目标,这些缺陷导致适用于自然视频的目标跟踪算法在卫星视频中往往表现较差,很容易出现目标跟丢的情况。由于卫星视频中目标自身特点的限制,目标跟踪算法在卫星视频中的发展较为缓慢。较早的卫星视频目标跟踪算法大多采用光流法、卡尔曼滤波等对跟踪器进行建模,但是这类算法在面对复杂的跟踪环境时呈现出较低的鲁棒性。一些方法在实现更高的鲁棒性的同时又无法满足实时性的要求。近年来,深度学习发展迅速,被广泛在应用于各个领域,且取得了很好的效果。基于深度学习的卫星视频目标跟踪算法也逐渐产生,并在实际应用中得到逐步发展和改进。从深度学习角度考虑,卫星视频目标跟踪问题实质上是一个特征提取融合问题和定位问题,即需要准确提取目标的特征信息和实现精准的定位。深度学习方法对不同层次的目标特征有着强大的挖掘能力,在与非深度学习的方法结合后,也同时能够达到对目标进行精准定位的要求。
3.总体来说,目前的卫星视频目标跟踪算法可归为三类:
4.基于光流的方法:该方法以光流为基础,通过将灰度场与二维速度场联系,引入光流约束方程,在假设运动物体灰度在很短的间隔时间内保持不变以及给定领域内的速度向量场变化缓慢的情况下,得到运动物体的光流,进而通过特征点的偏移实现目标跟踪。该方法的优点是直接引入目标的运动场,计算复杂度小,其缺点是不适用于复杂的运动场景。
5.基于卡尔曼滤波的方法:该方法是一种基于线性滤波的预测方法,主要分为两个步骤:预测与校正,预测是基于上一时刻目标状态估计当前状态,而校正则是综合当前的估计状态与观测状态,估计最优的状态。该方法的缺点是模型的建立决定了滤波效果的正确性,且目标估计状态与物体的运动速度有一定的关系,适用范围小,同时模型受参数的影响较大。
6.基于深度学习的方法:该类方法主要是以孪生网络为主,将包含目标的目标模板和搜索区域通过同样的特征提取网络,将得到的目标模板特征作为卷积核对搜索区域进行卷积,结果即为目标中心落在搜索区域上每个点的可能性。通过后续寻找最高点可以直接得到目标的位置。该方法以数据驱动为主,需要大量的数据来训练性能良好的特征提取网络,合适的训练数据对网络的性能有着关键作用即。该方法的优点在于能够挖掘目标多层
次的深度特征,具有很好的目标表达能力,能够应对任何复杂的目标以及目标运动场景。但是该方法大多还是在目标检测的基础上做目标跟踪,当背景存在很多相邻伪目标,跟踪器的判别能力将会下降。同时,在基于深度学习的方法中,仅仅考虑目标的空间信息而忽略了目标的时序信息,很大程度上限制了该类算法的跟踪性能。
7.因此,基于深度学习的卫星视频目标跟踪算法还有很大的改进空间,有必要发展同时兼顾跟踪实时性和准确性的跟踪算法。
技术实现要素:
8.针对现有基于深度学习的卫星视频目标跟踪算法的缺点,本发明提出一种基于运动先验的孪生网络卫星视频目标跟踪方法,通过构建光流注意力将目标的运动信息引入,对目标位置进行进一步约束,此外,为了增强跟踪器的鲁棒性,处理存在相似运动特点的含伪目标场景,引入带速度和方向的运动掩膜代替常用的汉宁窗,综合提升目标的识别准确性和定位精度。
9.本发明的技术方案提供一种基于运动先验的孪生网络卫星视频目标跟踪方法,包括以下步骤:
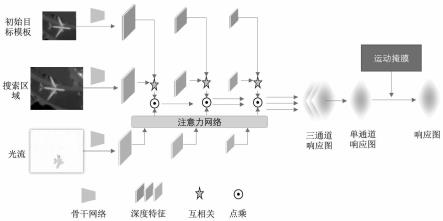
10.步骤1,根据已知的上一帧目标中心位置,得到目标模板、搜索区域以及和搜索区域对应的光流rgb图,并利用特征提取网络对目标模板、搜索区域以及光流rgb图分别进行特征提取,得到三层不同深度的目标特征;
11.步骤2,构建光流注意力网络,将光流的深度特征经过注意力网络得到带有运动信息的光流空间注意力,作用于目标模板深度特征和搜索区域深度特征互相关得到的相似性响应图上,将三个不同深度的相似性响应图在通道维进行拼接,经过两层卷积网络变成单通道的最终带运动特征的响应图,通过参数优化,对整个跟踪算法网络进行训练直至损失收敛至最低;
12.步骤3,在网络训练结束后的跟踪过程中,当帧数超过阈值,计算跟踪目标在一定阈值内的历史帧中位置偏移的平均速度,包括大小和方向,进一步得到运动掩膜代替传统汉宁窗,通过将该运动掩膜以一定的权重和网络得到的最终带运动特征的响应图相加对响应图进行优化,选取响应图上值最大的位置作为目标在当前帧中的中心位置,并将目标在最终响应图上的位置偏移映射到搜索区域对应的视频帧中。
13.进一步的,步骤1中,得到不同深度的目标特征的方式为,给定上一帧目标的位置和大小,设置上一帧中得到目标模板z和目标光流模板zf,在当前帧中得到搜索区域x,通过借助opencv的稠密光流计算函数cv2.calcopticalflowfarneback()计算zf和x之间的光流f,即光流rgb图,特征提取网络是三个共享权重的resnet网络组成的平行分支结构,分别包括目标模板分支,搜索区域分支和光流分支,目标模板分支由z作为输入,搜索区域分支由x作为输入,光流分支由f作为输入,三个分支共享cnn结构和参数,以搜索区域分支为例,输出特征为:
[0014][0015]
其中代表resnet网络,输出第三层、第四层和第五层特征,另外两分支通过同样的操作得到三层不同深度的输出特征。
[0016]
进一步的,步骤2中,光流的深度特征经过注意力网络得到带运动信
息的空间注意力其中,c代表特征的通道数,w和h分别代表特征的宽和高,目标模板深度特征和搜索区域深度特征进行互相关得到相似性响应图,进一步将得到的空间注意力施加到响应图上,将三个不同深度的相似性响应图在通道维进行拼接,然后通过通道维拼接和降维,得到最终带运动特征的相似性响应图;
[0017]
在该部分使用的注意力网络可以把深度特征转换为仅剩一个通道的空间注意力特征,输入的光流特征经过线性变化和permute操作得到序列和键其中q经过平均池化和最大池化,过程可以表示为:
[0018]
q'=avgpool(q) maxpool(q)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0019]
其中q'和k经过reshape操作分别得到和然后q经过softmax操作,与k进行矩阵乘法,进一步通过reshape和sigmoid操作得到空间注意力,该过程表示为:
[0020][0021]
经过注意力网络得到的空间注意力a包含了目标的运动特点,然后将其赋予相似性响应图,得到经过注意力机制作用后的相似性响应图:
[0022][0023]
o'=a
⊙oꢀꢀꢀꢀꢀꢀ
(5)
[0024]
其中o为目标模板深度特征和搜索区域深度特征互相关得到的相似性响应图,o'为加入光流注意力之后的相似性响应图;得到的三个不同网络深度下的相似性响应图,在通道维进行拼接,经过卷积网络降维为单通道作为最终的输出结果;
[0025]
进一步的,通过最小化损失函数来进行训练整个跟踪算法网络,损失函数采用logistic损失:
[0026]
l(y,o)=log(1 exp(-yo))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0027]
其中y∈{-1, 1}为真实标签,o为输出值,对于最终带运动特征的响应图,d表示响应图二维离散区域,|d|表示区域内点数之和,定义整个响应图的损失表示为:
[0028][0029]
通过adam优化最小损失函数,u指最终带运动特征的响应图中的每个离散点。
[0030]
进一步的,在步骤3中,在网络训练完成后的目标跟踪阶段,设置跟踪帧数阈值t,当跟踪帧数超过阈值之后,根据之前积累的最近t帧的目标位置偏移量得到目标平均每帧的偏移,即目标的速度v,响应图的大小为h
×
w,以最终带运动特征的响应图的中心点为原点,运动掩膜可表示为:运动掩膜上每个点值得计算过程为:
[0031][0032]
式中,代表运动掩膜上每个点相对于原点的向量与速度向量的夹角余弦值,其中(i,j)表示坐标点,v
x
和vy分别表示目标在横轴方向和纵轴方向上的速
度大小,同时,产生与运动掩膜相同大小的汉宁窗,用汉宁窗上每个位置的值乘以该位置对应的夹角余弦值,得到运动掩膜上该点的最终值。
[0033]
本发明提出的基于光流注意力与运动掩膜的孪生网络卫星视频目标跟踪方法,在目标特征与搜索区域特征融合阶段采用多尺度特征融合的方式,首次提出光流注意力机制,通过目标的运动信息排除静止背景的干扰,增强了跟踪器的判别性能,在对轮船等于背景极为相似的目标跟踪上起到很大的作用。
[0034]
同时,针对卫星视频中跟踪环境中存在很多与目标相似的伪目标情况,本发明提出的方法考虑了遥感目标的运动规律,利用带速度和方向表示的运动掩膜代替常用的汉宁窗。本发明提出的方法在卫星视频的后续应用,比如城市交通流量监测、轮船飞机等大型物体的实时位置监测等方面都具有重大作用。因此,基于光流注意力和运动掩膜的孪生网络卫星视频目标跟踪算法不仅具有非常重要的学术价值而且具有重要的现实意义。
[0035]
本发明不仅可以利用深度学习挖掘遥感视频目标在不同层次的空间特征,还可以利用光流和带方向和速度约束的运动掩膜对目标运动的时序特征进行挖掘,从而在“时-空”多角度捕捉更准确的目标特征、约束目标与背景的相似性,在保证实时性跟踪的前提下提升卫星视频目标跟踪的精度。
附图说明
[0036]
图1是本发明的整体网络结构图;
[0037]
图2是光流注意力网络结构图。
具体实施方式
[0038]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,将结合实例对带光流注意力和运动掩膜的跟踪方法进一步详细说明。应当理解,此处所描述的具体实例仅仅用于解释本发明,并不用于限定本发明。
[0039]
本发明通过一种基于运动先验的孪生网络卫星视频目标跟踪方法,针对获得更具代表性的深度特征,在深度特征提取上用多层不同深度的输出特征代替最后一层输出特征,通过相似性判别得到目标位置的相似性得分图,并引入光流注意力网络产生带有遥感目标运动特征的空间注意力对相似性得分图进一步纠正,提高网络的判别性和鲁棒性。除此之外,本发明引入了一种新的窗口函数,来代替常用的汉宁窗,该窗口函数具备表征遥感目标运动速度和方向的能力,能够弥补深度学习方法在目标运动变化的时序特征上挖掘不够的缺点。
[0040]
步骤1,根据已知的上一帧目标中心位置,得到目标模板、搜索区域以及和搜索区域对应的光流rgb图,通过resnet网络对目标模板、搜索区域以及和搜索区域对应的光流rgb图分别进行特征提取,分别得到三层不同深度的深度特征;
[0041]
步骤2,构建光流注意力网络,将光流的深度特征经过注意力网络得到带有运动信息的光流空间注意力,作用于目标模板深度特征和搜索区域深度特征互相关得到的相似性响应图上,将三个不同深度的相似性响应图在通道维进行拼接,经过两层卷积网络变成单通道的最终带运动特征的响应图,通过参数优化,对整个跟踪算法网络进行训练直至损失收敛至最低;
[0042]
步骤3,在网络训练结束后的跟踪过程中,当帧数超过阈值,计算跟踪目标在一定阈值内的历史帧中位置偏移的平均速度,包括大小和方向,进一步得到运动掩膜代替传统汉宁窗,通过将该运动掩膜以一定的权重和网络得到的最终带运动特征的响应图相加对响应图进行优化,选取响应图上值最大的位置作为目标在当前帧中的中心位置,并将目标在最终响应图上的位置偏移映射到搜索区域对应的视频帧中。
[0043]
而且,步骤1中,得到深度特征的方式为,给定上一帧目标的位置和大小,在上一帧中得到目标模板z和目标光流模板zf,在当前帧中得到搜索区域x,通过借助opencv的稠密光流计算函数cv2.calcopticalflowfarneback()计算zf和x之间的光流f。特征提取网络由三个分支组成,即三个共享权重的resnet网络组成的平行分支结构,参考附图1,分别包括目标模板分支,搜索区域分支和光流分支。目标模板分支由z作为输入,搜索区域分支由x作为输入,光流分支由f作为输入,三个分支共享cnn结构和参数。以搜索区域分支为例,输出特征为:
[0044][0045]
其中代表resnet深度网络,输出第三层、第四层和第五层特征,另外两分支通过同样的操作得到三层不同深度的输出特征。
[0046]
而且,步骤2中,经过深度网络输出的光流特征经过注意力网络得到带运动信息的空间注意力其中,c代表特征的通道数,w和h分别代表特征的宽和高。目标模板深度特征和搜索区域深度特征进行互相关得到相似性响应图。进一步将得到的空间注意力施加到响应图上,将三个不同深度的相似性响应图在通道维进行拼接,通过通道维拼接和降维,得到最终带运动特征的相似性响应图。
[0047]
在该部分使用的注意力机制可以把深度特征转换为仅剩一个通道的空间注意力特征,输入的光流特征经过线性变化和permute操作得到序列和键其中q经过平均池化和最大池化,过程可以表示为:
[0048]
q'=avgpool(q) maxpool(q)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0049]
其中q'和k经过reshape操作分别得到和然后q经过softmax操作,与k进行矩阵乘法,进一步通过reshape和sigmoid操作得到空间注意力,该过程表示为:
[0050][0051]
经过注意力机制得到的空间注意力a包含了目标的运动特点,然后将其赋予相似性响应图,得到经过注意力机制作用后的相似性响应图:
[0052][0053]
o'=a
⊙oꢀꢀꢀꢀꢀ
(5)
[0054]
其中o为目标模板和搜索区域对应的深度特征互相关得到的相似性响应图,o'为加入光流注意力之后的相似性响应图。得到的三个不同网络深度下的相似性响应图,在通道维进行拼接,经过卷积网络降维为单通道作为最终的输出结果。
[0055]
本发明提出的网络通过最小化损失函数来进行训练。损失函数采用logistic损失:
[0056]
l(y,o)=log(1 exp(-yo))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0057]
其中y∈{-1, 1}为真实标签,o为输出值。对于最终带运动特征的响应图,让d表示响应图二维离散区域,|d|表示区域内点数之和,定义整个响应图的损失表示为:
[0058][0059]
通过adam优化最小损失函数,u指响应图中的每个离散点。
[0060]
而且,在步骤3中,在网络训练完成后的目标跟踪阶段,设置跟踪帧数阈值t,当跟踪帧数超过阈值之后,根据之前积累的最近t帧的目标位置偏移量得到目标平均每帧的偏移,即目标的速度v。响应图的大小为h
×
w,以最终整个网络输出的最终带运动特征的响应图的中心点为原点,运动掩膜可表示为:运动掩膜上每个点值得计算过程为:
[0061][0062]
式中,代表运动掩膜上每个点相对于原点的向量与速度向量的夹角余弦值,其中(i,j)表示坐标点,v
x
和vy分别表示目标在横轴方向和纵轴方向上的速度大小。同时,产生与运动掩膜相同大小的汉宁窗,用汉宁窗上每个位置的值乘以该位置对应的夹角余弦值得到运动掩膜上该点的最终值。
[0063]
本发明可采用计算机软件技术进行实现。以下结合图1详述实施例卫星视频目标跟踪方法的具体步骤。
[0064]
步骤1,根据已知的上一帧目标位置和大小,获取目标模板、搜索区域和光流rgb图并通过resnet得到三层不同网络深度的输出特征。
[0065]
本发明中提出的基于运动先验的孪生网络卫星视频目标跟踪算法,是采用resnet50作为骨干网络进行特征提取,选择layer2,layer3和layer4的输出作为输出特征。实例中,目标模板大小为126
×
126,上下文系数为0.5,将裁剪包含模板的图片重新插值到固定大小。搜索区域大小为256
×
256,根据模板目标选取的尺寸变化倍数确定在当前帧中搜索区域的实际选取大小,同时在上一帧中同一位置选取同样大小的光流模板作为计算光流的第一帧。进一步地,通过opencv计算搜索区域和光流模板之间的稠密光流并将其转换为rgb图。实施例中的光流计算函数的winsize参数根据经验设置为15,poly_n设置为5,poly_sigma设置为1.2。具体实施时本领域技术人员可以根据具体使用的影像在经验值附近进行选取。
[0066]
步骤2,构建光流注意力网络,将输出的光流深度特征经过注意力网络得到空间注意力图,同时对目标模板和搜索区域的输出特征在各个层分别进行互相关,得到相似性得分图。将注意力作用于得分图上并将输出的得分图输入到两层卷积网络,对特征进一步挖掘和改变特征通道数。最后通过优化参数,对网络进行训练直至达到最佳效果。
[0067]
实例中,2、3、4层的输出特征通道数分别为512、1024、2048,模板特征和搜索区域输出特征进行互相关,得到三个不同深度下的相似性响应图;光流输出特征通过空间注意力网络变为单通道空间注意力图。三个不同深度对应的注意力网络结构相同但不共享权重。注意力输出和对应深度的响应图进行点乘得到的三个输出,再通过单层卷积网络变成
相同大小之后在通道维进行拼接,并经过两层卷积网络进一步融合变成最终的响应图输出。本实例中,采用adam优化器来训练网络,学习率设为1e-4。网络训练轮数为500。具体实施时本领域技术人员可以根据具体使用的影像对网络的超参数进行调整。
[0068]
步骤3,待网络收敛或达到最大训练轮数后,利用网络进行模板跟踪。通过第一帧的模板位置进行跟踪,首先通过网络得到响应图,在跟踪帧数到达阈值之前采用汉宁窗对响应图进行运动先验,在跟踪帧数达到阈值之后,采用运动掩膜对响应图进行先验,通过判断最大值位置推断目标位置。
[0069]
在实例中,跟踪帧数阈值设置为15,即在15帧之后计算目标最近15帧的速度大小和方向,进一步得到运动掩膜和运动掩膜先验下的响应图。通过找到响应图中最大值的位置,计算其距离模板中心点的偏移量,再根据响应图和搜索区域原始图片块的大小比例得到目标在原始图片块中的偏移量,从而确定目标在当前帧中的位置。
[0070]
本领域普通技术人员可以理解,本发明通过采用多尺度融合的方式挖掘不同深度下的网络输出特征,使得跟踪器能够应对不同场景下的目标尺寸变化。其次,首次通过引入光流和注意力机制使得在判断相似性的同时引入遥感目标运动特征,减少背景带来的影响。最后,通过运动掩膜,使得跟踪器能够进一步挖掘遥感目标运动的时序规律,避免跟踪器被相似目标干扰,增强跟踪器的准确性和鲁棒性。
[0071]
应该注意到并理解,在不脱离后附的权利要求所要求的本发明的精神和范围的情况下,能够对上述详细描述的本发明做出各种修改和改进。因此,要求保护的技术方案的范围不受所给出的任何特定示范教导的限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
