1.本发明涉及航运信息化、智能化技术领域,具体涉及一种船舶运力指标生成及相似系数计算方法及系统。
背景技术:
2.航运与我们的日常生活、社会经济发展息息相关。航运作为全球经济贸易最主要的载体,深刻影响着世界格局,见证世界强国与地区的兴起,影响着世界方方面面的运转,也是我国经济社会发展的重要支柱。航运市场的变化不仅能随着市场的经济状况进行变化,还能影响世界市场的经济变化。
3.目前在航运信息领域还没有一款方便快捷的工具用于快速简单的建立指数并分析,本发明弥补了市场上的空白,能够简单快捷的对航运信息进行对比和分析,对于航运信息领域的发展以及航运企业分析发展形势,制定决策方案具有重要意义。
技术实现要素:
4.为解决现有技术并没有方便快捷的工具用于快速简单的建立指数并分析的问题,本发明提供一种船舶运力指标生成及相似系数计算方法,该方法通过船舶全生命周期识别、数据库预取算法、面向对象的脚本语言以及相关性计算算法,可以根据多种航运相关条件,生成可用的航运指数,生成的航运指数跟一些经济指数、股票价格之间有很大相关关系,能够用来对市场进行分析、预测或被预测。本发明还涉及一种船舶运力指标生成及相似系数计算系统。
5.本发明的技术方案如下:
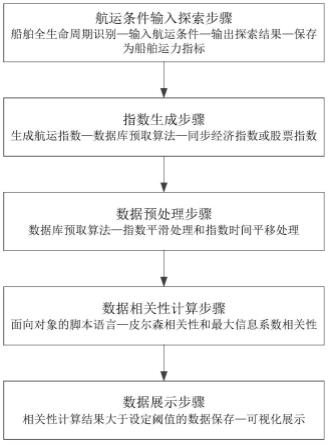
6.一种船舶运力指标生成及相似系数计算方法,其特征在于,包括以下步骤:
7.航运条件输入探索步骤,实时采集船舶运力数据,将采集的船舶运力数据通过大数据实时处理进行船舶全生命周期识别,根据用户的需求输入航运条件后,在船舶全生命周期识别的动态信息中探索满足航运条件的数据,输出探索结果,并将航运条件保存为船舶运力指标;
8.指数生成步骤,将探索结果进行统计分析生成当前航运条件下某时间段的航运指数,通过数据库预取算法生成指数唯一标识和指数生成的相关信息,并同步相同时间段的经济指数和/或股票指数;
9.数据预处理步骤,通过数据库预取算法分别对航运指数以及相同时间段的经济指数和/或股票指数进行指数平滑处理和指数时间平移处理;
10.数据相关性计算步骤,利用面向对象的脚本语言将预处理后的数据两两进行相关性计算,包括计算皮尔森相关性和最大信息系数相关性;
11.数据展示步骤,将相关性计算结果大于设定阈值的数据保存下来进行可视化展示。
12.优选地,所述航运条件输入探索步骤中,采集的船舶运力数据包括船舶属性数据
和港口属性数据,所述船舶属性数据包括船舶资料、船舶标签、船舶动态、货物种类、船舶ais、船舶sts、船舶预测全球航线、全球海区、特殊区域、气象信息中的任意组合,所述港口属性数据包括港口资料、港口标签、港口动态、psc检查、全球海区中的任意组合。
13.优选地,所述指数生成步骤中,所述数据库预取算法采用postgresql,通过postgresql 生成指数唯一标识和指数生成的时间、创建人、条件,将对应生成的指数详细信息保存在另一张指数表中,还同步国内外若干相关经济指数或股票指数。
14.优选地,所述数据相关性计算步骤中,利用的面向对象的脚本语言为python,利用python 进行定时计算相关性,除两两进行相关性计算外,还进行一对多的相关性计算以确定两个指数共同对另一个指数的影响程度。
15.优选地,所述数据相关性计算步骤进行的是离线计算,对相关性计算结果小于设定阈值的数据不保存,生成计算历史以避免重复计算。
16.优选地,所述设定阈值为0.8,将相关性计算结果大于0.8的数据保存下来并使用阿里云 bi工具进行可视化展示,以便查看不同数据间的相关性和指数时间序列图像。
17.一种船舶运力指标生成及相似系数计算系统,其特征在于,包括依次连接的航运条件输入探索模块、指数生成模块、数据预处理模块、数据相关性计算模块和数据展示模块,
18.航运条件输入探索模块,实时采集船舶运力数据,将采集的船舶运力数据通过大数据实时处理进行船舶全生命周期识别,根据用户的需求输入航运条件后,在船舶全生命周期识别的动态信息中探索满足航运条件的数据,输出探索结果,并将航运条件保存为船舶运力指标;
19.指数生成模块,将探索结果进行统计分析生成当前航运条件下某时间段的航运指数,通过数据库预取算法生成指数唯一标识和指数生成的相关信息,并同步相同时间段的经济指数和/或股票指数;
20.数据预处理模块,通过数据库预取算法分别对航运指数以及相同时间段的经济指数和/或股票指数进行指数平滑处理和指数时间平移处理;
21.数据相关性计算模块,利用面向对象的脚本语言将预处理后的数据两两进行相关性计算,包括计算皮尔森相关性和最大信息系数相关性;
22.数据展示模块,将相关性计算结果大于设定阈值的数据保存下来进行可视化展示。
23.优选地,所述航运条件输入探索模块中,采集的船舶运力数据包括船舶属性数据和港口属性数据,所述船舶属性数据包括船舶资料、船舶标签、船舶动态、货物种类、船舶ais、船舶sts、船舶预测全球航线、全球海区、特殊区域、气象信息中的任意组合,所述港口属性数据包括港口资料、港口标签、港口动态、psc检查、全球海区中的任意组合。
24.优选地,所述指数生成模块中,所述数据库预取算法采用postgresql,通过postgresql 生成指数唯一标识和指数生成的时间、创建人、条件,将对应生成的指数详细信息保存在另一张指数表中,还同步国内外若干相关经济指数或股票指数。
25.优选地,所述数据相关性计算模块进行的是离线计算,设定阈值为0.8,对相关性计算结果小于0.8的数据不保存,生成计算历史以避免重复计算;将相关性计算结果大于0.8的数据保存下来并使用阿里云bi工具进行可视化展示,以便查看不同数据间的相关性
和指数时间序列图像。
26.本发明的有益效果为:
27.本发明提供的一种基于船舶运力指标生成及相似系数计算方法,将采集的船舶运力数据通过大数据实时处理进行船舶全生命周期识别,在进行航运条件输入以及探索,作为航运指数生成的各种条件,得到满足航运条件的数据,再将探索结果进行统计分析生成当前航运条件下某段时间的航运指数,通过数据库预取算法生成指数唯一标识和指数生成的相关信息,并同步经济指数或股票指数,也就是说,指数生成后,后续再计算航运指数与其它外部指数或股票的相关关系,很多航运信息会反映当前市场或未来市场,也有可能别的市场可以预测航运信息,具体同步、预处理和相关性计算。通过数据库预取算法分别对航运指数以及相同时间段的经济指数和/或股票指数进行指数平滑处理和指数时间平移处理,指数平滑处理可以有效降低突变值带来的影响,指数时间平移处理是将指数日期加减一定的时间,达到时间差的效果,目的是计算相差一定时间后,两组指数的相关性最大,即探索价值更高。在数据相关性计算计算步骤中,是对数据库已有数据进行预处理后,两两进行相关性计算,计算主要计算皮尔森相关性和最大信息系数相关性(mic相关性),除了两两进行计算,还可进一步获知两个指数共同对另一个指数的影响程度,即一对多进行相关性计算,以提高相关性计算精度,最后将相关性计算结果大于设定阈值的数据保存下来进行可视化展示,使用户可以随时查看不同数据间的相关性和指数时间序列图像。本发明通过航运条件的梳理,生成指数的方式设置,指数存储,指数自动更新,外部指数获取和更新,指数展示,指数平滑处理,指数时间平移处理,指数间相关性计算等,涉及船舶全生命周期识别、数据库预取算法以及面向对象的脚本语言,可以根据多种航运相关条件,生成可用的航运指数,生成的航运指数跟一些经济指数、股票价格之间有很大相关关系,进行指数同步以及相关性结算,得到航运指数与经济指数、航运指数与股票价格等经济状况的关联影响程度,能够用来对市场进行分析、预测或被预测。
28.本发明还涉及一种基于船舶运力指标生成及相似系数计算系统,该系统与上述的基于船舶运力指标生成及相似系数计算方法相对应,可理解为是一种实现上述基于船舶运力指标生成及相似系数计算方法的系统,包括航运条件输入探索模块、指数生成模块、数据预处理模块、数据相关性计算模块和数据展示模块,各模块相互协同工作,能够实现智能化计算处理,探索航运业务对其它经济指数或股票的影响程度,弥补了市场上的空白,能够简单快捷的对航运信息进行对比和分析,对于航运信息领域的发展以及航运企业分析发展形势,制定决策方案具有重要意义。
附图说明
29.图1是本发明基于船舶运力指标生成及相似系数计算方法的流程图。
30.图2a-图2h均是本发明船舶运力数据界面示意图。
31.图3a是本发明船型分析界面示意图,图3b是本发明探索结果界面示意图。
32.图4为本发明航运指数生成界面示意图。
33.图5为本发明指数相关性计算结果的界面示意图。
具体实施方式
34.下面结合附图对本发明进行说明。
35.本发明涉及一种基于船舶运力指标生成及相似系数计算方法,该方法的流程图如图1所示,包括如下步骤:
36.航运条件输入探索步骤,实时采集船舶运力数据,将采集的船舶运力数据通过大数据实时处理进行船舶全生命周期识别,根据用户的需求输入航运条件后,在船舶全生命周期识别的动态信息中探索满足航运条件的数据,输出探索结果,并将航运条件保存为船舶运力指标。该步骤涉及航运数据中台船舶行为识别技术,对船舶全生命周期进行了识别,加上船舶属性和港口属性组成了航运指数生成的各种条件。
37.船舶属性数据即船舶大类主要包括船舶资料、船舶标签、船舶动态、货物种类、船舶ais、船舶sts、船舶预测、全球航线、全球海区、特殊区域、气象信息等任意组合;港口属性数据即港口大类主要包括港口资料、港口标签、港口动态、psc检查、全球海区等任意组合。进一步地,船舶资料包括:船舶类型(如图2a所示,客船、集装箱、液体散货、干散货、杂货、特种船等)、船舶属性(如图2b所示,指船舶的长宽高等具体属性)、船舶主体(指船舶的运营主体、管理主体、所有权主体)和船舶设备(主要包括主机、辅机、锅炉、螺旋浆等);船舶标签如图2c所示,可以自己给部分船舶打标签,方便后期选择,如标签为双燃料船、风电安装船、中国沿海内贸干散货、中国兼营干散货等;船舶动态是基于ais进行识别后,将船舶动态分为航行(途中航行、到港后航行)、锚泊(途中锚泊、到港锚泊)、靠泊 (作业、修理、建造、检验)、搁浅几大类,同时可以选择动态持续时长和航次起始港(国家、泊位)目的港(国家、泊位);货物种类如图2d所示,包括大宗干散货糖、铁矿石、煤炭等,液散原油、lng、lpg,特种船等,同时可以选择船舶载货状态(空、满、装、卸);船舶ais主要包括船舶航速、吃水、dest目的地、ais状态等ais信息;船舶sts指加油或海上过驳;船舶预测,可以选择船舶预测目的地,剩余时间,剩余里程;全球航线如图2e所示,如跨太平洋航线、欧洲航线、欧洲支线及大西洋航线、亚太航线、拉非航线等;全球海区可以如图2f所示选择任意海区;特殊区域如图2g所示;气象信息如图2h所示的风向风级,浪向浪级等;还可以是周边船舶,可以选择船舶附近信息;除已经固定的选项之外,还支持自定义内容,包括船队、区域以及航线。
38.指数生成步骤,将探索结果进行统计分析生成当前航运条件下某时间段的航运指数,通过数据库预取算法生成指数唯一标识和指数生成的相关信息,并同步相同时间段的经济指数和/或股票指数。主要包括指数生成和数据存储过程,其中,指数生成:航运指数可以选择选择任意条件,进行查询,默认条件下查询当前最新情况,也可以选择时间段,比如一年的数据,这样就生成当前条件下的航运指数。数据存储过程:在用户选择条件后,可以进行保存,如果想指数自动更新则结束时间不选择,这样数据会在每日凌晨1点自动更新最新数据,保存后系统会在后台采用postgresql生成指数唯一标识和指数生成的时间、创建人、条件等,同时将对应生成的指数详细信息保存在另一张指数表中,除了用户自己生成的指数外,还可同步国内外许多相关经济指数、股票信息等方便用户对比分析。也就是说,在指数生成并同步后,本发明能够计算航运指数与其它外部指数或股票的相关关系,很多航运信息会反应当前市场或未来市场,也有可能别的市场可以预测航运信息。
39.数据预处理步骤,通过数据库预取算法分别对航运指数以及相同时间段的经济指数和/或股票指数进行指数平滑处理和指数时间平移处理。可以对航运指数、经济指数、股
票指数都进行数据预处理。预处理使用postgresql进行,主要处理包括指数平滑处理,或称为滑动平均,即将是将指数若干天的数据取平均值,作为当日数据,此操作可以有效降低突变值带来的影响;另一个处理就是指数时间平移处理,或称为时间移动,即指数日期加减一定的时间,达到时间差的效果,目的是计算相差一定时间后,两组指数的相关性最大,即探索价值更高。
40.数据相关性计算步骤,利用面向对象的脚本语言将预处理后的数据两两进行相关性计算,包括计算皮尔森相关性和最大信息系数相关性。可以是对预处理后的航运指数和经济指数两两进行相关性计算,也可以是预处理后的航运指数和股票指数两两进行相关性计算,甚至可以是预处理后的航运指数和航运指数两两进行相关性计算,以及预处理后的经济指数和股票指数两两进行相关性计算。具体地,利用的面向对象的脚本语言为python,利用python进行定时计算相关性。对数据库已有数据,进行预处理后,两两进行相关性计算,计算主要计算皮尔森相关性和mic相关性(maximal information coefficient,最大信息系数相关性),除了两两进行计算,还可以进一步获知两个指数共同对另一个指数的影响程度,即进行一对多进行相关性计算。进一步地,由于数据量很大,该数据相关性计算步骤进行的是离线计算,对相关性计算结果小于设定阈值的数据不保存,生成计算历史以避免重复计算。
41.数据展示步骤,将相关性计算结果大于设定阈值的数据保存下来进行可视化展示。设定阈值优选为0.8(也可以设定为其它阈值),将相关性计算结果大于0.8的数据保存下来并使用可视化工具—阿里云bi工具进行可视化展示,可以随时查看不同数据间的相关性和指数时间序列图像。
42.实施例一:
43.针对全球在运铁矿石船当日情况,在航运条件输入探索步骤中,航运条件选项比如选择散货船、航行或锚泊状态、货种为铁矿石,满载状态,目的港中国,船型分析界面示意图如 3a所示,可以查看当前条件下都有什么样的船型,将航运条件保存,即可下次快捷查看,如图3b,探索结果可存储在数据库中。将指标发布到指数中,即可生成对应的指数,在发布时可以选择艘次或载重吨,结束时间不选择,指数会随时间而更新,这样就可以将指数发布出来。指数发布后,可以在指数工具中进行查看,如图4所示,也可以选择任意两个指数进行对比,如果想让其他人也能查看,可以选择共享成公共指数。指数共享出来后,再将其与其它外部指数和其他公共指数进行相关性计算,计算出与之相关性最高的,这样就可以根据计算结果再进行更深度分析。数据相关性计算步骤的指数相关性计算结果如图5所示,示出了内部指数、外部指数、移动平均、时间差、皮尔森相关性和mic计算结果,显示了内外指数相关分析,还可以进一步将内外指数通过比较曲线展示。
44.本发明基于船舶运力指标生成及相似系数计算方法,包括航运条件输入探索步骤、指数生成步骤、数据预处理步骤、数据相关性计算步骤和数据展示步骤,将船舶运力指标生成及相似系数计算结果进行集成,探索出来有用的指标,保存在数据库中,以备后期使用;数据预处理步骤使用postgresql,写预处理函数,将处理后的数据单独存储,用来可视化和计算相关性;相关性计算步骤使用python进行定时计算,由于数据量很大,所以离线计算,对相关性过低数据不保存,生成计算历史,避免重复计算,将大于一定数值计算结果存储,方便后期调阅;数据展示步骤依托阿里云bi工具进行展示。
45.本发明还涉及一种基于船舶运力指标生成及相似系数计算系统,该系统与上述的基于船舶运力指标生成及相似系数计算方法相对应,可理解为是一种实现上述基于船舶运力指标生成及相似系数计算方法的系统,包括依次连接的航运条件输入探索模块、指数生成模块、数据预处理模块、数据相关性计算模块和数据展示模块。航运条件输入探索模块,实时采集船舶运力数据,将采集的船舶运力数据通过大数据实时处理进行船舶全生命周期识别,根据用户的需求输入航运条件后,在船舶全生命周期识别的动态信息中探索满足航运条件的数据,输出探索结果,并将航运条件保存为船舶运力指标;指数生成模块,将探索结果进行统计分析生成当前航运条件下某时间段的航运指数,通过数据库预取算法生成指数唯一标识和指数生成的相关信息,并同步相同时间段的经济指数或股票指数;数据预处理模块,通过数据库预取算法分别对航运指数以及相同时间段的经济指数和/或股票指数进行指数平滑处理和指数时间平移处理;数据相关性计算模块,利用面向对象的脚本语言将预处理后的数据两两进行相关性计算,包括计算皮尔森相关性和最大信息系数相关性;数据展示模块,将相关性计算结果大于设定阈值的数据保存下来进行可视化展示。
46.进一步地,在航运条件输入探索模块中,采集的船舶运力数据包括船舶属性数据和港口属性数据,所述船舶属性数据包括船舶资料、船舶标签、船舶动态、货物种类、船舶ais、船舶sts、船舶预测全球航线、全球海区、特殊区域、气象信息中的任意组合,所述港口属性数据包括港口资料、港口标签、港口动态、psc检查、全球海区中的任意组合。
47.进一步地,在指数生成模块中,所述数据库预取算法采用postgresql,通过postgresql 生成指数唯一标识和指数生成的时间、创建人、条件,将对应生成的指数详细信息保存在另一张指数表中,还同步国内外若干相关经济指数或股票指数信息以便用户对比分析。
48.进一步地,在数据相关性计算模块进行的是离线计算,设定阈值为0.8,对相关性计算结果小于0.8的数据不保存,生成计算历史以避免重复计算;将相关性计算结果大于0.8的数据保存下来并使用阿里云bi工具进行可视化展示,以便查看不同数据间的相关性和指数时间序列图像。
49.应当指出,以上所述具体实施方式可以使本领域的技术人员更全面地理解本发明创造,但不以任何方式限制本发明创造。因此,尽管本说明书参照附图和实施例对本发明创造已进行了详细的说明,但是,本领域技术人员应当理解,仍然可以对本发明创造进行修改或者等同替换,总之,一切不脱离本发明创造的精神和范围的技术方案及其改进,其均应涵盖在本发明创造专利的保护范围当中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。