1.本发明涉及图书分级技术领域,特别涉及一种多维度图书分级方法、系统、可读介质及设备。
背景技术:
2.每个阅读者的阅读能力是不一样的,且每个阅读者对需要阅读的书籍的接收能力也是不一样的,因此,不同的阅读者所具备的阅读需求也是不一样的,也就是需要对不同的阅读者进行针对性的阅读图书的分级。
3.传统的图书分级系统中,是通过人为设定的分级规则来硬性地对图书进行评级,比如,是通过年龄阶段进行的分级,且该分级是面向大众的分级,具备普适性,但是不能很好的满足每个阅读者阅读体验以及阅读需求。
4.因此,本发明提出一种多维度图书分级方法、系统、可读介质及设备。
技术实现要素:
5.本发明提供一种多维度图书分级方法、系统、可读介质及设备,用以通过获取阅读者的测试题目,来基于预设分析模型,确定阅读能力,并通过按照阅读难度以及阅读能力所构建的阅读特性,来匹配多维度分级方式,来实现针对该阅读者的阅读体验以及阅读需求。
6.本发明提供一种多维度图书分级方法,包括:
7.获取阅读者的历史阅读信息,并按照所述历史阅读信息从预设数据库中,调取阅读测试题目;
8.接收所述阅读者对所述阅读测试题目的测试反馈,构建反馈矩阵,并基于预设分析模型,确定所述阅读者的阅读能力;
9.从图书数据库中调取待分析图书集,并分别获取所述待分析图书集中每本阅读图书的图书主题以及图书摘要,确定每本阅读图书的图书阅读难度;
10.基于所述阅读能力以及图书阅读难度,建立与所述阅读者相关的阅读特性,将所述阅读特性划分为多个阅读维度,并匹配每个阅读维度的图书分级方式;
11.按照多维度图书分级方式,对所述待分级图书集进行多维度分级,实现难度进阶阅读。
12.优选的,获取阅读者的历史阅读信息,并按照所述历史阅读信息从预设数据库中,调取阅读测试题目,包括:
13.基于所述历史阅读信息,获取所述阅读者阅读的图书类别、对每本历史图书的阅读时间、对每本历史图书的阅读进度以及对每本历史图书中每章节的理解程度;
14.基于所述图书类别,对所有历史图书进行分类,并根据分类数量确定列表行数量,同时,根据同类别包含的历史图书数量,建立对应行的单元格数量;
15.基于所述阅读时间、阅读进度以及理解程度,确定所述阅读者对对应历史图书的阅读吸收情况;
16.基于吸收-有效性数据库,获取对应历史图书的历史阅读有效性;
17.对同类别历史图书对应的所有历史阅读有效性进行大小排序,并依次从大到小放置在对应单元格中;
18.获取列表中首列单元格中的元素,并基于列表中每行的行属性,构建首列向量,同时,获取列表中最后满元素列单元格中的元素,并基于列表中每行的行属性,构建尾列向量;
19.对所述首列向量中处于同级别的元素进行划分,并分别获取每个级别中的最大元素和最小元素,同时,对所述尾列向量中处于同级别的元素进行划分,并分别获取每个级别中的第一元素和第二元素;
20.将所述最大元素以及最小元素所处位置对应的历史图书的图书类别进行确定,同时,还将所述第一元素以及第二元素所处位置对应的历史图书的图书类别进行确定,基于类别确定结果,从预设数据库中,调取与每个类别一致的阅读测试题目,供所述阅读者测试。
21.优选的,接收所述阅读者对所述阅读测试题目的测试反馈,构建反馈矩阵,包括:
22.对所述阅读者的阅读屏幕进行画面扫描,判断在将当下阅读测试题目下发到所述阅读者的阅读端后,是否在第一预设时间内接收到所述当下阅读测试题目;
23.若接收到,判定传输所述当下阅读测试题目的传输接口正常,并统计所述阅读者对所述当下阅读测试题目的第一答复时间以及对应的第一答复内容;
24.若未接收到,但在第二预设时间内接收到所述当下阅读测试题目,统计所述阅读者对所述当下阅读测试题目的第二答复时间以及对应的第二答复内容;采集所述当下阅读测试题目对应的传输接口的当下日志以及正常传输同个阅读测试题目的历史日志;
25.对所述当下日志进行第一解析,获取第一运行数据,同时,对所述历史日志进行第二解析,获取第二运行数据;
26.将所述第一运行数据与第二运行数据进行同时间戳比较,获取差异数据,并提取同个比较时间点下的差异参数;
27.基于所述差异参数绘制对应的差异离散点,得到差异离散图;
28.对所述差异离散图进行同参数的最外边缘包络绘制以及最内边缘包络绘制;
29.基于同参数包络绘制结果,确定对应同参数的差异面积;
30.根据每个同参数的差异面积,从参数-面积-比例列表中,确定对应同参数的延迟比例;
31.基于所有延迟比例,获取时间延迟调节因子;
32.确定基于所述第二预设时间的当下接收时间点以及第一预设时间内的正常接收时间点,得到初始延迟时间;
33.基于所述时间延迟调节因子,对所述初始延迟时间进行调节,得到当下延迟时间;
34.基于所述当下延迟时间,对所述阅读者对所述当下阅读测试题目的第二答复时间进行修正,得到第三答复时间;
35.将所述第一答复时间以及第一答复内容作为测试反馈以及将所述第三答复时间以及第二答复内容作为测试反馈;
36.获取每个测试反馈的反馈向量,并依次输入到空白矩阵中,得到反馈矩阵。
37.优选的,基于预设分析模型,确定所述阅读者的阅读能力,包括:
38.获取所述反馈矩阵中的行向量,并将所述行向量依次输入到预设分析模型中,得到所述阅读者的阅读能力。
39.优选的,从图书数据库中调取待分析图书集,并分别获取所述待分析图书集中每本阅读图书的图书主题以及图书摘要,确定每本阅读图书的图书阅读难度,包括:
40.提取所述待分析图书集中每本阅读图书的一级主题以及二级主题,并分别获取所述一级主题对应的第一摘要以及二级主题对应的第二摘要;
41.获取每本阅读图书的内容部署构架,来确定每个一级主题的第一构架权重、以及所述一级主题下包含的每个二级主题的第二构架权重;
42.基于所述第一构架权重以及第二构架权重,确定同章构架权重;
43.基于所述同章构架权重,匹配对应的特征提取方式,并按照所述特征提取方式,对同章包含的第一摘要以及第二摘要进行特征提取;
44.获取同本阅读图书的所有提取特征,并基于阅读难度分析模型,得到同本阅读图书的图书阅读难度。
45.优选的,基于所述阅读能力以及图书阅读难度,建立与所述阅读者相关的阅读特性,将所述阅读特性划分为多个阅读维度,并匹配每个阅读维度的图书分级方式,包括:
46.建立所述阅读能力与每个图书阅读难度以及对应阅读图书的图书类别的第一关系;
47.获取每个所述阅读测试题目对应的预设能力范围以及预设难度范围,进而得到对应的综合能力范围以及综合难度范围;
48.建立所述综合能力范围与所述阅读能力的第二关系以及所述综合难度范围与每个图书阅读难度以及阅读图书的图书类别的第三关系;
49.按照关系约束条件,对所述第一关系、第二关系以及第三关系进行预设约束,建立得到阅读特性;
50.对所述阅读特性进行划分,得到多个阅读维度;
51.基于每个阅读维度的唯一维度标识,从标识-分级数据库中匹配得到所述唯一维度标识对应的图书分级方式。
52.优选的,按照多维度图书分级方式,对所述待分级图书集进行多维度分级,实现难度进阶阅读,包括:
53.在按照唯一维度标识匹配得到图书分级方式后,获取与所述唯一维度标识所匹配类别的阅读图书子集;
54.确定所述阅读图书子集中的第一图书的第一阅读难度以及第一图书类别的优先值;
[0055][0056]
其中,yi表示第i本第一图书的优先值;
∝i表示第i本第一图书的第一阅读难度;表示第i本第一图书的类别的转换系数;e表示常熟,取值为2.6;σi表示第i本第一图书的历史优先推荐系数;si表示第i本第一图书的在对应的唯一维度标识所对应的单一阅读维度
的当下取值;s
i,1
表示对应的唯一维度标识所对应的单一阅读维度的左边界取值;s
i,2
表示对应的唯一维度标识单一阅读维度的右边界取值,其中,s
i,2
大于s
i,1
,且si∈[s
i,1
,s
i,2
];
[0057]
基于所有图书分级方式,对每个分级方式对应的所有优先值进行大小分级,完成对同个阅读图书子集的子分级,进而完成对所述待分级图书集进行多维度分级,实现难度进阶阅读。
[0058]
本发明提供一种多维度图书分级系统,包括:
[0059]
题目调取模块,用于获取阅读者的历史阅读信息,并按照所述历史阅读信息从预设数据库中,调取阅读测试题目;
[0060]
能力确定模块,用于接收所述阅读者对所述阅读测试题目的测试反馈,构建反馈矩阵,并基于预设分析模型,确定所述阅读者的阅读能力;
[0061]
难度确定模块,用于从图书数据库中调取待分析图书集,并分别获取所述待分析图书集中每本阅读图书的图书主题以及图书摘要,确定每本阅读图书的图书阅读难度;
[0062]
方式匹配模块,用于基于所述阅读能力以及图书阅读难度,建立与所述阅读者相关的阅读特性,将所述阅读特性划分为多个阅读维度,并匹配每个阅读维度的图书分级方式;
[0063]
多维度分级模块,用于按照多维度图书分级方式,对所述待分级图书集进行多维度分级,实现难度进阶阅读。
[0064]
本发明提供一种计算机可读介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行任一项所述方法的步骤。
[0065]
本发明提供一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行任一项所述方法的步骤。
[0066]
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
[0067]
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
[0068]
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
[0069]
图1为本发明实施例中一种多维度图书分级方法的流程图;
[0070]
图2为本发明实施例中一种多维度图书分级系统的结构图;
[0071]
图3为本发明实施例中差异离散图。
具体实施方式
[0072]
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
[0073]
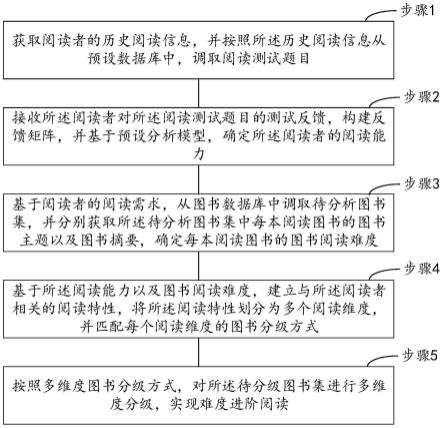
在一个实施例中,本发明提供一种多维度图书分级方法,如图1所示,包括:
[0074]
步骤1:获取阅读者的历史阅读信息,并按照所述历史阅读信息从预设数据库中,调取阅读测试题目;
[0075]
步骤2:接收所述阅读者对所述阅读测试题目的测试反馈,构建反馈矩阵,并基于预设分析模型,确定所述阅读者的阅读能力;
[0076]
步骤3:基于阅读者的阅读需求,从图书数据库中调取待分析图书集,并分别获取所述待分析图书集中每本阅读图书的图书主题以及图书摘要,确定每本阅读图书的图书阅读难度;
[0077]
步骤4:基于所述阅读能力以及图书阅读难度,建立与所述阅读者相关的阅读特性,将所述阅读特性划分为多个阅读维度,并匹配每个阅读维度的图书分级方式;
[0078]
步骤5:按照多维度图书分级方式,对所述待分级图书集进行多维度分级,实现难度进阶阅读。
[0079]
该实施例中,历史阅读信息指的是阅读者的历史读书记录,比如读书类别、进度、时间等参数,且预设数据库是预先构建好的,且包括不同列别所包含的的测试题目,由于测试题目不止一个,因此,通过对每个测试题目都构建一个阅读者针对该测试题目的测试答复也就是测试反馈,来得到一个测试向量,进而构建成为一个反馈矩阵,比如,测试向量1为:{1002},测试向量2为:{2001},对应的反馈矩阵就为
[0080]
实施例中,预设分析模型,是以各种组合的测试向量以及对应的能力为样本训练得到的。
[0081]
该实施例中,待分析图书集是按照阅读需求确定的,进而可以确定出阅读者想要阅读的书籍类别。
[0082]
该实施例中,图书主题指的是该本阅读图书的总摘要,图书摘要指的是该图书中每个章节的摘要,进而来确定阅读难度,且阅读难度是按照图书本身摘要来确定的。
[0083]
该实施例中,阅读能力与阅读图书难度,一个是基于阅读者本身进行的考虑,一个是基于阅读图书本身进行的考虑,来确定阅读特性,也就是阅读者对不同类别的书的阅读难易程度,来得到不同阅读维度。
[0084]
比如,阅读者对类别图书1与类别图书2的阅读理解程度是一样的,此时,就可以获取阅读理解程度一样以及与两个类别一致的分级方式,且分级方式,主要是为了对难度进行分析,每个阅读维度的理解程度都是依次递减的,比如:容易理解、不容易理解、难理解等,以此对理解程度递减,来进行一个层级的划分,且图书分级方式是对该阅读维度所对应的所有图书进行分级的,比如:容易理解的阅读维度所对应的容易理解的范围是标定在[0,1]之间的,不容易理解的阅读维度所对应的不容易理解的范围是标定在[1,2]之间的,此时,虽然上边类别图书1与类别图书2都处于容易理解的阅读维度,但是,具体的阅读理解程度还是会存在不一样的,假如,按照对应的图书分级方式,可以将类别图书1处于一个级别,类别图书2处于一个级别,且类别图书1对应的级别是更容易比类别图书2对应的级别所理解的,此时,难度进阶阅读即为:类别图书1、类别图书2。
[0085]
该实施例中,多维度图书分级方式,也就是每个阅读维度都对应一个分级方式,且按照该分级方式,对该阅读维度所包含的图书进行难易理解程度的分级,最后实现难度进阶阅读。
[0086]
上述技术方案的有益效果是:通过获取阅读者的测试题目,来基于预设分析模型,确定阅读能力,并通过按照阅读难度以及阅读能力所构建的阅读特性,来匹配多维度分级
方式,实现难度进阶阅读,可以针对该阅读者提高阅读体验以及满足阅读需求。
[0087]
在一个实施例中,获取阅读者的历史阅读信息,并按照所述历史阅读信息从预设数据库中,调取阅读测试题目,包括:
[0088]
基于所述历史阅读信息,获取所述阅读者阅读的图书类别、对每本历史图书的阅读时间、对每本历史图书的阅读进度以及对每本历史图书中每章节的理解程度;
[0089]
基于所述图书类别,对所有历史图书进行分类,并根据分类数量确定列表行数量,同时,根据同类别包含的历史图书数量,建立对应行的单元格数量;
[0090]
基于所述阅读时间、阅读进度以及理解程度,确定所述阅读者对对应历史图书的阅读吸收情况;
[0091]
基于吸收-有效性数据库,获取对应历史图书的历史阅读有效性;
[0092]
对同类别历史图书对应的所有历史阅读有效性进行大小排序,并依次从大到小放置在对应单元格中;
[0093]
获取列表中首列单元格中的元素,并基于列表中每行的行属性,构建首列向量,同时,获取列表中最后满元素列单元格中的元素,并基于列表中每行的行属性,构建尾列向量;
[0094]
对所述首列向量中处于同级别的元素进行划分,并分别获取每个级别中的最大元素和最小元素,同时,对所述尾列向量中处于同级别的元素进行划分,并分别获取每个级别中的第一元素和第二元素;
[0095]
将所述最大元素以及最小元素所处位置对应的历史图书的图书类别进行确定,同时,还将所述第一元素以及第二元素所处位置对应的历史图书的图书类别进行确定,基于类别确定结果,从预设数据库中,调取与每个类别一致的阅读测试题目,供所述阅读者测试。
[0096]
该实施例中,元素就是历史阅读有效性,且首列向量就是由历史阅读有效性为元素构建得到的。
[0097]
该实施例中,同级别的元素指的是处于同个阅读有效性级别的历史阅读有效性,进而,来确定该级别中的最大元素和最小元素,也就是该级别中的最大历史阅读有效性以及最小历史阅读有效性,进而,确定该有效性在列表中的位置,也就是该位置对应的图书类别。
[0098]
其中,列表中最后满元素列单元格中的元素指的是,该列中每个单元格都存在可以表示有效性的元素,但是在该列的下一列中某个单元格不存在可以表示有效性的元素,且该列即为最后满元素列,针对末尾第一元素指的是同级别中的最大元素,第二元素指的同级别中的最小元素。
[0099]
该实施例中,图书分类指的是对同类别的图书归为一类,比如分类数量为20,对应的列表行数为20,此时,如果第一行中存在同类别的5本图书,此时,就该行就存在10个单元格,且列表行数是大于10的,且每行的单元格是大于3的。
[0100]
该实施例中,阅读进度以及理解程度越高,以及阅读时间越短,对应的阅读吸收情况越好,且吸收-有效性数据库是包括吸收情况以及将该吸收情况进行标准数值转换为有效性两部分数据在内的。
[0101]
该实施例中,通过对有效性大小排序,来依次放在在单元格,且该单元格中的元素
即为有效性。
[0102]
该实施例中,预设数据库中是包括类别以及针对该类别的测试题目在内的。
[0103]
上述技术方案的有益效果是:通过图书类别以及同类别图书数量,来构建列表,且通过对列表中的有效性大小排序依次放置到单元格,进而通过提取首列与尾列中元素,且通过对同级别的元素进行提取,来获取最后的测试题目,保证可以对阅读者的阅读能力进行有效测试,提高后续对图书分级效率,间接提高阅读体验感。
[0104]
在一个实施例中,接收所述阅读者对所述阅读测试题目的测试反馈,构建反馈矩阵,包括:
[0105]
对所述阅读者的阅读屏幕进行画面扫描,判断在将当下阅读测试题目下发到所述阅读者的阅读端后,是否在第一预设时间内接收到所述当下阅读测试题目;
[0106]
若接收到,判定传输所述当下阅读测试题目的传输接口正常,并统计所述阅读者对所述当下阅读测试题目的第一答复时间以及对应的第一答复内容;
[0107]
若未接收到,但在第二预设时间内接收到所述当下阅读测试题目,统计所述阅读者对所述当下阅读测试题目的第二答复时间以及对应的第二答复内容;
[0108]
采集所述当下阅读测试题目对应的传输接口的当下日志以及正常传输同个阅读测试题目的历史日志;
[0109]
对所述当下日志进行第一解析,获取第一运行数据,同时,对所述历史日志进行第二解析,获取第二运行数据;
[0110]
将所述第一运行数据与第二运行数据进行同时间戳比较,获取差异数据,并提取同个比较时间点下的差异参数;
[0111]
基于所述差异参数绘制对应的差异离散点,得到差异离散图;
[0112]
对所述差异离散图进行同参数的最外边缘包络绘制以及最内边缘包络绘制;
[0113]
基于同参数包络绘制结果,确定对应同参数的差异面积;
[0114]
根据每个同参数的差异面积,从参数-面积-比例列表中,确定对应同参数的延迟比例;
[0115]
基于所有延迟比例,获取时间延迟调节因子;
[0116]
确定基于所述第二预设时间的当下接收时间点以及第一预设时间内的正常接收时间点,得到初始延迟时间;
[0117]
基于所述时间延迟调节因子,对所述初始延迟时间进行调节,得到当下延迟时间;
[0118]
基于所述当下延迟时间,对所述阅读者对所述当下阅读测试题目的第二答复时间进行修正,得到第三答复时间;
[0119]
将所述第一答复时间以及第一答复内容作为测试反馈以及将所述第三答复时间以及第二答复内容作为测试反馈;
[0120]
获取每个测试反馈的反馈向量,并依次输入到空白矩阵中,得到反馈矩阵。
[0121]
该实施例中,在向阅读者下发阅读测试题目之后,且阅读者的阅读端接收到阅读测试题目开始作答时,才算做答复开始,进行答复时间的统计,但是,在统计的过程中,可能会存在接口延迟接收到测试题目的情况,因此,通过对接口接收测试题目的日志与正常情况下(不出现延迟的情况下)的日志进行比较,来获取延迟调节因子,因为,当用户答复完测试题并基于接收进行反馈的时候,还是会因为存在的延迟(比如由于卡顿导致的)问题,导
致阅读者在提交测试题目的时候出现卡顿延迟,此时,虽然阅读者已经答复完成,但是提交不了,仍然将延迟时间作为答复时间的一部分,此时,需要对该延迟问题造成的时间延迟进行删减,来保证阅读者答复时间的合理性。
[0122]
该实施例中,画面扫描主要是为了捕捉阅读屏幕是否接收到阅读测试题目,且传输接口指的是阅读屏幕可以接收到测试题目的接收端口。
[0123]
该实施例中,日志进行解析,主要是为了获取运行数据,且历史日志指的是在第一预设时间内可以正常接收到测试题目时,所产生的日志。
[0124]
该实施例中,同时间戳比较,主要是为了确定存在的差异数据,比如网路差异数据,进而来获取该同时间戳的同个时间点下的网络差异参数,因为,网络运行数据会存在整个日志过程中,因此,来确定同个时间点下不同差异参数的数值,如图3所示,比如存在差异参数1,此时与正常参数1比较后,得到差异离散点,进而得到差异离散图,且图中a1表示最外边缘包络,a2表示最内边缘包络。
[0125]
该实施例中,差异面积就是同参数确定的包络所构成的区域面积,且参数-面积-比例列表中是包含参数类型、差异面积、延迟比例三者在内的,当延时比例越大时,对应的延迟调节因子越大,且主要是为了对初始延迟时间进行调节。
[0126]
该实施例中,比如,初始延迟时间为10s,对应的延迟调节因子为1.2,此时,对应的当下延迟时间为12s。
[0127]
上述技术方案的有益效果是:通过对阅读端接收测试题目的时间进行判断,进而后续通过对传输接口正常与否的判断,来得到时间延迟调节因子,进而,对第二答复时间进行修复,保证测试反馈的合理性,有效避免因为答复时间导致反馈效率低下,进而降低阅读体验。
[0128]
在一个实施例中,基于预设分析模型,确定所述阅读者的阅读能力,包括:
[0129]
获取所述反馈矩阵中的行向量,并将所述行向量依次输入到预设分析模型中,得到所述阅读者的阅读能力。
[0130]
该实施例中,行向量也就是指的反馈向量,且预设分析模型时基于不同组合反馈向量以及匹配的阅读能力训练得到的。
[0131]
上述技术方案的有益效果是:通过预设分析模型对矩阵进行分析,便于得到阅读能力,方便后续进行分级,间接提高阅读体验感。
[0132]
在一个实施例中,从图书数据库中调取待分析图书集,并分别获取所述待分析图书集中每本阅读图书的图书主题以及图书摘要,确定每本阅读图书的图书阅读难度,包括:
[0133]
提取所述待分析图书集中每本阅读图书的一级主题以及二级主题,并分别获取所述一级主题对应的第一摘要以及二级主题对应的第二摘要;
[0134]
获取每本阅读图书的内容部署构架,来确定每个一级主题的第一构架权重、以及所述一级主题下包含的每个二级主题的第二构架权重;
[0135]
基于所述第一构架权重以及第二构架权重,确定同章构架权重;
[0136]
基于所述同章构架权重,匹配对应的特征提取方式,并按照所述特征提取方式,对同章包含的第一摘要以及第二摘要进行特征提取;
[0137]
获取同本阅读图书的所有提取特征,并基于阅读难度分析模型,得到同本阅读图书的图书阅读难度。
[0138]
该实施例中,一级主题指的时章节总主题,二级主题指的是章节中包括的小节的总主题,进而来提取对应的摘要。
[0139]
该实施例中,内容部署构架指的是对应图书的内容布局,且不同章节以及不同章节下的子节所对应的构架权重是不一样的,因此,需要确定同章的构架权重。
[0140]
该实施例中,特征提取方式,指的是按照与权重匹配的方式,来进行特征提取,权重越大,对应匹配的特征提取方式所需要提取的特征就需要越细致。
[0141]
该实施例中,阅读难度分析模型是预先训练好的。
[0142]
上述技术方案的有益效果是:通过确定同章构架权重,匹配特征提取方式,可以提取到有效特征,进而基于模型,得到图书阅读难度,为后续获取分级方式提供基础。
[0143]
在一个实施例中,基于所述阅读能力以及图书阅读难度,建立与所述阅读者相关的阅读特性,将所述阅读特性划分为多个阅读维度,并匹配每个阅读维度的图书分级方式,包括:
[0144]
建立所述阅读能力与每个图书阅读难度以及对应阅读图书的图书类别的第一关系;
[0145]
获取每个所述阅读测试题目对应的预设能力范围以及预设难度范围,进而得到对应的综合能力范围以及综合难度范围;
[0146]
建立所述综合能力范围与所述阅读能力的第二关系以及所述综合难度范围与每个图书阅读难度以及阅读图书的图书类别的第三关系;
[0147]
按照关系约束条件,对所述第一关系、第二关系以及第三关系进行预设约束,建立得到阅读特性;
[0148]
对所述阅读特性进行划分,得到多个阅读维度;
[0149]
基于每个阅读维度的唯一维度标识,从标识-分级数据库中匹配得到所述唯一维度标识对应的图书分级方式。
[0150]
该实施例中,通过数值对同个阅读测试题目的预设能力范围以及预设难度范围进行表示,比如测试题目1对应的预设能力范围为[0,3]以及预设难度范围为[5,6],此时,阅读者的阅读能力为3,阅读图书1的图书阅读难度为6,阅读图书1的图书类别为01,第一关系为:3
‑‑
(1,6)
‑‑
(1,01);第二关系为:3
‑‑
(0,3),第三关系为6-(5,6,01),此时,通过关系约束条件,判断阅读者对该类别的图书的阅读状态,由于阅读能力3是预设能力范围的最大能力值,图书阅读困难6是预设难度范围的最大难度值,此时处于完全轻松状态,也就是将该类别01的阅读图书设置为容易理解阅读特性,还存在较为理解阅读特性、不易理解阅读特性以及难理解阅读特性,且每个程度的理解都可以视为一个维度,进而获得多个阅读维度。
[0151]
该实施例中,标识-分级数据库是包含不同的唯一维度标识以及对应的分级方式在内的,比如:存在图书1(容易理解),图书2(容易理解),此时,图书1与图书2对应同个阅读维度,此时的阅读维度的唯一维度标识标识容易理解的标识,进而来从标识-分级书库中得到分级方式,将图书1和图书2作为同个分级。
[0152]
该实施例中,通过按照第一关系、第二关系、以及第三关系,可以有效的按照理解程度,来进行阅读特性的划分,进而,来得到不同理解程度的阅读图书,且阅读维度的唯一标识可以是包括:理解程度以及对应的同个理解程度的所有类别标识在内的。
[0153]
比如,阅读维度的唯一标识是包括:理解程度-类别01、02在内的,此时,就可以按
照该标识,来获取对应的图书分级方式。
[0154]
上述技术方案的有益效果是:通过建立不同的第一关系、第二关系以及第三关系,可以有效的确定获取到多个唯一维度标识,进而,得到该维度对应的图书分级方式,保证对该阅读者的阅读针对性。
[0155]
在一个实施例中,按照多维度图书分级方式,对所述待分级图书集进行多维度分级,实现难度进阶阅读,包括:
[0156]
在按照唯一维度标识匹配得到图书分级方式后,获取与所述唯一维度标识所匹配类别的阅读图书子集;
[0157]
确定所述阅读图书子集中的第一图书的第一阅读难度以及第一图书类别的优先值;
[0158][0159]
其中,yi表示第i本第一图书的优先值;
∝i表示第i本第一图书的第一阅读难度;表示第i本第一图书的类别的转换系数;e表示常熟,取值为2.6;σi表示第i本第一图书的历史优先推荐系数;si表示第i本第一图书的在对应的唯一维度标识所对应的单一阅读维度的当下取值;s
i,1
表示对应的唯一维度标识所对应的单一阅读维度的左边界取值;s
i,2
表示对应的唯一维度标识单一阅读维度的右边界取值,其中,s
i,2
大于s
i,1
,且si∈[s
i,1
,s
i,2
];
[0160]
基于所有图书分级方式,对每个分级方式对应的所有优先值进行大小分级,完成对同个阅读图书子集的子分级,进而完成对所述待分级图书集进行多维度分级,实现难度进阶阅读。
[0161]
该实施例中,转换系数的取值范围为[0.9,1],历史推荐越频繁,对应的优先推荐系数越高,且取值范围为[0,1]。
[0162]
该实施例中,优先值的计算是为了对该唯一维度标识所对应匹配每个阅读图书进行分级确定,比如,该唯一维度标识对应的阅读图书包括:图书1、2、3、4、5、6,且对优先值进行大小分级后,得到图书1、3、4为一级,图书2、5、6为一级,此时,其中,图书1、3、4相比较图书2、5、6更容易理解。
[0163]
此时,就可以实现对该唯一维度标识对应的图书子集的分级处理。
[0164]
该实施例中,多维度分级,指的是所有唯一阅读标识都按照对应的分级方式实现完成了分级处理。
[0165]
上述技术方案的有益效果是:通过按照唯一维度标识匹配阅读图书子集,并通过难度与类别计算优先值,最后通过按照图书分级方式,实现多维度分级,最后实现难度进阶阅读,间接提高阅读者的阅读体验。
[0166]
在一个实施例中,本发明提供一种多维度图书分级系统,如图2所示,包括:
[0167]
题目调取模块,用于获取阅读者的历史阅读信息,并按照所述历史阅读信息从预设数据库中,调取阅读测试题目;
[0168]
能力确定模块,用于接收所述阅读者对所述阅读测试题目的测试反馈,构建反馈矩阵,并基于预设分析模型,确定所述阅读者的阅读能力;
[0169]
难度确定模块,用于从图书数据库中调取待分析图书集,并分别获取所述待分析
图书集中每本阅读图书的图书主题以及图书摘要,确定每本阅读图书的图书阅读难度;
[0170]
方式匹配模块,用于基于所述阅读能力以及图书阅读难度,建立与所述阅读者相关的阅读特性,将所述阅读特性划分为多个阅读维度,并匹配每个阅读维度的图书分级方式;
[0171]
多维度分级模块,用于按照多维度图书分级方式,对所述待分级图书集进行多维度分级,实现难度进阶阅读。
[0172]
上述技术方案的有益效果是:通过获取阅读者的测试题目,来基于预设分析模型,确定阅读能力,并通过按照阅读难度以及阅读能力所构建的阅读特性,来匹配多维度分级方式,实现难度进阶阅读,可以针对该阅读者提高阅读体验以及满足阅读需求。
[0173]
在一个实施例中,提出了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行以下步骤:
[0174]
步骤1:获取阅读者的历史阅读信息,并按照所述历史阅读信息从预设数据库中,调取阅读测试题目;
[0175]
步骤2:接收所述阅读者对所述阅读测试题目的测试反馈,构建反馈矩阵,并基于预设分析模型,确定所述阅读者的阅读能力;
[0176]
步骤3:基于阅读者的阅读需求,从图书数据库中调取待分析图书集,并分别获取所述待分析图书集中每本阅读图书的图书主题以及图书摘要,确定每本阅读图书的图书阅读难度;
[0177]
步骤4:基于所述阅读能力以及图书阅读难度,建立与所述阅读者相关的阅读特性,将所述阅读特性划分为多个阅读维度,并匹配每个阅读维度的图书分级方式;
[0178]
步骤5:按照多维度图书分级方式,对所述待分级图书集进行多维度分级,实现难度进阶阅读。
[0179]
在一个实施例中,提出了一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行以下步骤:
[0180]
步骤1:获取阅读者的历史阅读信息,并按照所述历史阅读信息从预设数据库中,调取阅读测试题目;
[0181]
步骤2:接收所述阅读者对所述阅读测试题目的测试反馈,构建反馈矩阵,并基于预设分析模型,确定所述阅读者的阅读能力;
[0182]
步骤3:基于阅读者的阅读需求,从图书数据库中调取待分析图书集,并分别获取所述待分析图书集中每本阅读图书的图书主题以及图书摘要,确定每本阅读图书的图书阅读难度;
[0183]
步骤4:基于所述阅读能力以及图书阅读难度,建立与所述阅读者相关的阅读特性,将所述阅读特性划分为多个阅读维度,并匹配每个阅读维度的图书分级方式;
[0184]
步骤5:按照多维度图书分级方式,对所述待分级图书集进行多维度分级,实现难度进阶阅读。
[0185]
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一非易失性计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,本技术所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性
和/或易失性存储器。非易失性存储器可包括只读存储器(rom)、可编程rom(prom)、电可编程rom(eprom)、电可擦除可编程rom(eeprom)或闪存。易失性存储器可包括随机存取存储器(ram)或者外部高速缓冲存储器。作为说明而非局限,ram以多种形式可得,诸如静态ram(sram)、动态ram(dram)、同步dram(sdram)、双数据率sdram(ddrsdram)、增强型sdram(esdram)、同步链路(synchlink)dram(sldram)、存储器总线(rambus)直接ram(rdram)、直接存储器总线动态ram(drdram)、以及存储器总线动态ram(rdram)等。
[0186]
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
[0187]
以上所述实施例仅表达了本技术的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本技术专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。因此,本技术专利的保护范围应以所附权利要求为准。请输入具体实施内容部分。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
