nlp中基于样本的序列到序列任务的影响函数解释方法
技术领域
1.本发明涉及自然语言处理nlp领域,更具体地,本发明涉及基于样本的序列到序列任务的影响函数解释方法。
背景技术:
2.随着复杂模型成为许多人工智能众多领域中不可或缺的工具,人们对解释这些“黑箱”模型的工作机制越来越感兴趣,并致力于研究出能够解释模型决策的方法。但深度学习的诞生使模型发展地越来越复杂,数据集的规模也在与日俱增,这对解释方法在可解释性、忠实度等方面的能力提出了挑战。
3.目前,对于机器学习模型的解释方法已取得了不小的进展,在现有技术中,基于训练样本的、对模型的行为做出解释的影响函数得到了多数的认可。与使用输入擦除、显着图或注意力矩阵等其他方法不同,影响函数通过基于训练示例的解释对于特定的输入如何使模型产生这样的结果,从而了解模型的决策。该解释方法设计之初主要适用于图像处理的任务当中,对于自然语言处理的任务还不能够全面适用。
4.自然语言处理(natural language processing,简称nlp)就是用计算机来处理、理解以及运用人类语言(如中文、英文等),它属于人工智能的一个分支,是计算机科学与语言学的交叉学科,又被称为计算语言学。
5.现有研究中,基于bert的文本分类和自然语言推理模型开始使用这种方法尝试对决策做出解释,这些工作证明影响函数在自然语言处理领域是有用的。但同时,现有影响函数方法在自然语言处理领域的序列到序列任务(例如,对话生成、自动摘要等)中的应用依然是空白,很多针对性的问题还需要够适应性解决。首先,遵循影响函数的原始方法if(influence function),对于现代自然语言处理模型和大规模数据集,由于原始公式中的逆hessian矩阵计算,影响函数的应用可能会导致过高的计算成本,新引入的tracin方法无hessian矩阵计算,但它可能对次优检查点的参与做出虚假解释而导致不忠实于所讨论的模型;其次,影响函数应用于序列到序列任务中,还需要解决一个样本中多个标签如何进行计算的问题;最后,对于在序列到序列任务中常见的长段自然语言文本,模型的决策可能仅取决于样本的特定部分,将整个原始样本作为解释单元还不够精准。
6.因此,nlp中基于样本的序列到序列任务的影响函数解释方法仍待完善。
技术实现要素:
7.针对目前存在的问题,本发明提出一种nlp中基于样本的序列到序列任务的影响函数解释方法,从而衡量基于待测模型(自然语言处理模型)、特定的训练样本对测试样本的影响大小。
8.本发明包括以下步骤:
9.一种nlp中基于样本的序列到序列任务的影响函数解释方法,包括步骤:
10.1)选取需要获取解释的序列到序列任务,并针对序列到序列任务选取待测的自然
语言处理模型和数据集;
11.2)将数据集内的语料进行编码,将编码后的每条数据划分不同区间得到的多条数据并作为新的样本;
12.3)将步骤2)得到的新的样本送入待测模型进行训练,在损失趋于稳定时结束训练;
13.在待测模型训练过程输出的所有检查点中,选取趋近于待测模型最终参数的检查点用于影响分数的计算;
14.4)基于步骤3)选取的检查点中的待测模型参数,计算训练样本与测试样本的损失;
15.5)利用步骤4)得到的损失,基于待测模型参数计算梯度向量,按照影响函数公式计算得到影响分数。
16.本发明的技术改进主要有:
17.(1)对于序列到序列的任务,制定数据处理策略,通过设置滑动窗口来获取合适的样本区间粒度作为解释单元;
18.(2)对于序列到序列任务中,标签数即为词汇数的多标签问题,将样本中各个token的损失加和作为样本的损失;
19.(3)选取合适的模型输出的检查点作为模型训练过程的记录,参与计算。
20.本发明的技术效果主要有:
21.(1)采取合适的数据处理方式既能够尽可能提升模型功能,同时充分实现方法的可解释性;
22.(2)消除了序列到序列任务中,多标签问题对样本损失计算的障碍;
23.(3)降低了计算成本,并保证影响分数结果忠实于最终模型。
附图说明
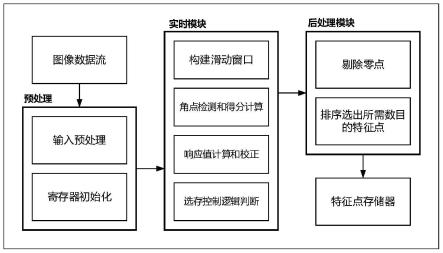
24.图1是本发明的nlp中基于样本的序列到序列任务的影响函数的流程图。
具体实施方式
25.下面结合附图1的流程,详细说明本发明的nlp中基于样本的序列到序列任务的影响函数的具体实施方式。
26.一种基于样本的序列到序列任务的影响函数解释方法,包括以下步骤:
27.步骤一:选取需要获取解释的序列到序列(seq2seq)任务,并针对具体的序列到序列任务选取待测模型和数据集;
28.步骤二:将选取的数据集内的语料进行编码处理,将编码后的每条数据按策略划分不同区间后得到的多条数据作为新的样本,并将新样本的集合作为待使用的数据集;
29.步骤三:将数据集送入模型(自然语言处理模型)进行训练,在损失趋于稳定时结束训练。在训练过程中模型输出的检查点中选取部分用于影响分数的计算;
30.步骤四:基于选取的待测模型的检查点内模型参数计算特定训练样本与测试样本的损失;
31.步骤五:将获取到的特定样本的损失基于待测模型参数计算梯度向量,按照设定
的影响函数公式计算得到影响分数,生成影响分数文件。
32.具体到本具体实施方式中:
33.步骤一中,选取合适的语言模型和数据集如下:
34.步骤1.1:序列到序列任务是实现一个序列到另一个序列之间的转换的自然语言处理任务。序列到序列任务的选择较多,例如机器翻译、自动摘要、对话生成等。相比于机器翻译、文本摘要等人类对于结果生成的缘由能够一目了然的应用,对于对话生成任务的完成获取解释的意义相对更大,基于此本实施例选取对话生成任务作为基础任务;
35.步骤1.2:处理对话生成任务这种生成类任务时,模型在生成序列的时候按顺序生成。
36.对话生成任务在实际生成内容的时候,是从左向右的,而自回归语言模型根据上文内容预测下文内容,天然匹配这个过程,基于此实施例选取自回归语言模型gpt-2作为待测模型;
37.步骤1.3:对话生成任务的选择根据应用场景有任务型、闲聊型、问答型三类。
38.这三类在不同的应用场景和业务中都有广泛的应用。相比于需要涉及到背景知识的任务型对话相比,日常生活当中的闲聊型对话人们更加需要了解其中模型决策的原因,使用解释方法的意义更大,基于此本实施例选择闲聊对话作为数据集。
39.步骤二中,对语料进行编码的方法如下:
40.步骤2.1:数据集中包含多段对话样本,其中每段对话包含两个角色的多轮发言,每个角色的单轮发言包含多条句子。将数据集中每段对话样本按照模型词表中单词的序号进行编码;
41.步骤2.2:在对话样本中的每轮的角色发言前插入代表发言角色的编码符号,在每轮发言的开头和结尾插入代表每轮对话起始与结束的编码符号;
42.步骤2.3:设置一个滑动窗口,对于每段编码后的对话样本进行框选处理。依据角色编码符号将窗口每次向后滑动一个角色单轮发言的长度,将滑动窗口长度设置为5次发言的长度,每滑动一次都将窗口中的内容保存。将对话样本截取成多段不同长度的新对话样本;
43.本例优选为将滑动窗口长度设置为5次发言的长度,这样能有效缩短样本长度,保证数据不会太冗余的同时,也保留了对话上下文之间的关系。
44.步骤2.4:保留新对话样本中最后发言角色相同的所有样本,作为新的数据集。
45.步骤三中,模型检查点获取过程如下:
46.步骤3.1:假设训练过程中每次都会访问训练样本,那么训练期间,访问特定的训练样本将改变模型的参数,这种改变会影响测试样本上的损失。为获取特定训练样本对特定测试样本的影响大小,需跟踪训练过程,捕获各个训练样本被访问后测试样本上损失的变化,即训练样本的影响力将归因于各次访问训练样本的累计值。这一过程通过记录模型训练过程中输出的检查点来代替;
47.步骤3.2:选取一组模型输出的检查点。在模型训练过程中输出的多个检查点中,选取趋近于最终模型的检查点,以保证影响函数计算过程以及影响分数结果忠实于模型最终参数。即对于模型输出的检查点内的参数i是选取的检查点的遍历,选取足够小的
δ使都趋近于
48.步骤四中,样本损失计算方法如下:
49.步骤4.1:计算各检查点下特定训练实例的相对贡献。逐点计算损失梯度时,对于特定的训练样本z,设样本序列表示为z={t0,...,tm},t为样本中的各token。
50.步骤4.2:基于模型参数利用交叉熵损失函数(cross entropy loss function)计算token的损失,损失计算方法如下:
[0051][0052]
其中,c是标签类别的数量,即词表内词汇个数,p=[p0,...,p
c-1
]是概率分布,每个元素pi表示tm属于类别i的概率,y=[y0,...,y
c-1
],是tm标签的one hot表示,每个元素yi在tm的标签为类别i时取1,否则取0;
[0053]
步骤4.3:序列到序列任务的生成机制的损失计算为token级,为获取每段样本的损失,将每段样本中各个token的损失做加和处理,计算方法如下:
[0054][0055]
步骤4.4:同样的,对于特定的测试样本z
′
,样本序列表示为z
′
={t
′0,...,t
′n},t
′
为样本中的各token。样本损失计算方法如下:
[0056][0057]
步骤五中,影响分数计算的方法如下:
[0058]
步骤5.1:基于参数计算样本的损失梯度表达式如下:
[0059][0060]
步骤5.2:按照影响函数tracins公式,基于各检查点内参数按照步骤5.1计算测试和训练样本损失梯度做简单形式点积,逐检查点求和,计算训练样本z对测试样本z
′
的影响分数:
[0061][0062]
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所做的等效结构或等流程变换,或直接或间接运用在相关技术领域,均同理包括在本发明的专利保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。