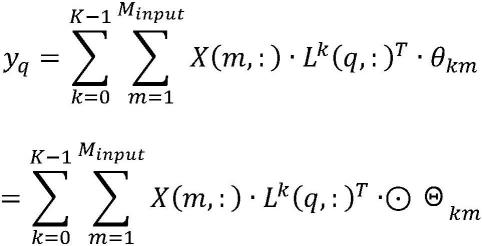
1.本发明涉及一种运动特征技术领域,尤其是一种运动员单目视频的运动特征获取方法。
背景技术:
2.目前顶尖运动员运动特征获取方法,大多数方法都是从高分辨率到低分辨率网络产生的低分辨率表征中恢复高分辨率表征,从低分辨率恢复到高分辨率的过程中可能带来的信息丢失。
3.因此,提出一种顶尖运动员的运动特征获取方法。
技术实现要素:
4.本发明的目的就是解决现有技术中的问题,提出一种运动员单目视频的运动特征获取方法,能够使从输入到输出的整个过程一直使用保持高分辨率特征图、且获取运动员特征更精准清楚。
5.本发明解决其技术问题所采用的技术方案是:一种运动员单目视频的运动特征获取方法,包括以下步骤:步骤一:拍摄运动员的图像视频;步骤二:将拍摄的运动员图像视频帧发送骨干网络模型;步骤三:基于hrnet得到而二维人体骨架结构;步骤四:通过lcn神经网络模型将二维人体骨架结构抬升至三维空间中,得到三维人体姿态,并存入模板动作模块。
6.作为优选:所述步骤三采用hrnet算法,使用自顶向下的人体骨骼关键点检测方式,先利用目标检测算法faster r-cnn检测出图像中的所有人体位置框,随后针对检测出的每个人体位置框单独执行人体骨骼关键点检测。
7.作为优选:所述步骤四三维人体姿态采用局部连接网络,将hrnet算法得到二维人体骨架结构然后通过lcn神经网络模型将二维人体骨架结构抬升至三维空间中,得到三维人体姿态,获得人体17个骨骼关键点的三维坐标,存入领感智体模板动作库。
8.作为优选:所述还包括步骤五:模板动作模块可视化输出;
9.所述模板动作模块可视化输出流程包括:
10.(1)从建模软件的网格模型中绑定骨骼,经过蒙皮、调整、驱动检查等步骤得到fbx格式的骨骼蒙皮模型;
11.(2)将上述模型输出在unity平台中进行位置调整;
12.(3)把获取的人体17个骨骼关键点的三维坐标与unity平台中三维人体模型的相同17个骨骼关节位置进行对应绑定,形成模板动作三位人物模型动画。
13.作为优选:所述通过lcn神经网络模型将二维人体骨架结构抬升至三维空间中的操作方式为:
14.使用基于单目图像的三维人体姿态估计方法(lcn)包括两个模块:(1)基于cnn的二维位姿估计;(2)基于lcn的三维位姿估计。使用三个损失来估计三维人体姿态:
15.l=λhl
heatmap
λ
2d
l
2d
λ
3d
l
3d
16.其中l
heatmap
、l
2d
和λ
3d
分别是在2d姿势热图、2d关节位置和3d关节位置上强制执行的损失函数;
17.作为优选:所述l
heatmap
的计算方法为:
[0018][0019]
用{h_1,
…
,h_n}表示cnn从图像中估计的热图,其中n是身体关节类型的数量。对应的地面真实热图由{h_1^9,
…
,h_n^9}表示,其中每个h_i^9是通过应用以第i个关节的地面真实位置为中心的2d高斯来生成的。在以前的工作的基础上,在估计的热图和地面真实的热图之间实施了 l2损失。
[0020]
作为优选:所述l
2d
的计算方法为:
[0021]
通过使用积分技巧计算热图的“期望值”来将热图hi变换成2d坐标ji,以便它可以被馈送到 lcn网络以估计3d姿态。
[0022]
首先通过在空间轴上应用softmax运算符来归一每个热图hi,使得它们的和为一:
[0023][0024]
其中w和h分别是热图的宽度和高度。超参数α,被称为“逆温度”,用于调整归一化热图的锐度。关节ji的二维位置被计算为~的质心hi:
[0025][0026]
在估计位置ji和地面真实位置之间强制实施稳健的l1损失:
[0027][0028]
当使用不同的α值来归一化热图时计算的2d姿势。(f)通过在每个热图中找到最大热图响应来获得2d姿势。
[0029]
作为优选:所述λ
3d
的计算方法为:
[0030]
最后一步中估计的2d位姿{j1,
…
,jn}被馈送到lcn网络以估计相应的3d位姿在估计的3d姿势和地面真实3d姿势之间强制l2损失:
[0031][0032]
其中是第i个关节的地面真实3d位置。
[0033]
作为优选:所述lcn网络构建流程为:
[0034]
通过将拉普拉斯算子分解为结构矩阵和权重矩阵的乘积来重构gcn。权重分担方
案损害了gcn 的代表权,去掉两个矩阵中的结构约束后,得到了更一般的公式,其中gcn和fcn是它的特例。最后,在公式的基础上,通过构造不同的矩阵,我们引入了lcn,它结合了fcn和gcn的优点。
[0035]
重新表述了gcn,使得拉普拉斯算子固有的权重分担方案可以清楚地暴露出来。基于公式eq.,通过对输入特征y∈rn应用过滤器g
θ
来获得n个节点的输出特征向量
[0036][0037]
对于不同的特征维度(总计m
input
)和扩展阶数(总计k),该过滤器具有不同的θ。但是,图形中的不同节点共享相同的过滤器θ。我们可以看到上面的等式,同一组θ用于计算对应于不同节点的不同维度的y。通过修改上面的公式得到:
[0038][0039]
基于拉普拉斯矩阵lk的定义,更仔细地查看对应于第q个节点yq的输出特征,其是y的第q 个维度,如果连接关节i和j的最小边数(即,它们在图上的距离)大于k,则lk(i,j)=0。特征 yq可以表示为:
[0040][0041]
其中θkm∈rn
×
1是通过重复θkm n次构造的。然后用更紧致的矩阵形式重新表示m上的内和,得到
[0042][0043]
其中k表示串联。是一个lk(:,q)重复n次的向量。它包含节点q的邻
域信息,可以将该公式推广到图中的所有节点:
[0044][0045]
其中sk和wk都是形状为m
i0putn×
n,specifically,的2d矩阵。具体地说,是sk的第q列,是wk的第q列。
[0046]
本发明的有益效果是:
[0047]
1、现有的大多数方法都是从高分辨率到低分辨率网络产生的低分辨率表征中恢复高分辨率表征。hrnet在此基础上对高分辨率特征进行了改进,从输入到输出的整个过程一直使用保持高分辨率特征图的方式,避免了从低分辨率恢复到高分辨率的过程中可能带来的信息丢失,同时通过重复跨行并行卷积来执行多尺度融合以增强高分辨率表示。在一定程度上缓解了中、低分辨率检测准确率低的情况。
[0048]
2、运用lcn网络,显著地降低了3d姿态估计的误差,并且其性能优于最先进的方法。更重要的是,由于人体关节之间的稀疏连接,它表现出很强的跨数据集泛化能力。
[0049]
3、通过unity平台,对三维人体模型模型动画进行驱动,将取得的模板动作进行可视化,一方面方便平台对于取得的模板动作是否正确进行检查,修正;另一方面方便用户使用系统检测功能前学习模仿标准动作与用户使用系统检测功能,得到报告意见后后,对自己动作动画与模板动作动画进行对比学习
具体实施方式
[0050]
下面对本发明作进一步描述:
[0051]
本实施例提供一种运动员单目视频的运动特征获取方法,包括以下步骤:
[0052]
步骤一:拍摄运动员的图像视频;步骤二:将拍摄的运动员图像视频帧发送骨干网络模型;步骤三:基于hrnet得到而二维人体骨架结构;步骤四:通过lcn神经网络模型将二维人体骨架结构抬升至三维空间中,得到三维人体姿态,并存入模板动作模块;步骤五:模板动作模块可视化输出;模板动作模块可视化输出流程包括:(1)从建模软件的网格模型中绑定骨骼,经过蒙皮、调整、驱动检查等步骤得到fbx格式的骨骼蒙皮模型;(2)将上述模型输出在unity平台中进行位置调整;(3)把获取的人体17个骨骼关键点的三维坐标与unity平台中三维人体模型的相同17 个骨骼关节位置进行对应绑定,形成模板动作三位人物模型动画。
[0053]
其中步骤三采用hrnet算法,使用自顶向下的人体骨骼关键点检测方式,先利用目标检测算法 faster r-cnn检测出图像中的所有人体位置框,随后针对检测出的每个人体位置框单独执行人体骨骼关键点检测。
[0054]
其中hrnet网络总体来看是由包含四个阶段的四个并行的子网组成,在第一个阶段中使用高分辨率子网,随后在每个阶段中,将其分辨率降低为原来的1/2,同时将宽度(通道数)增加为原来的二倍。其中,第一阶段的每一个高分辨率特征图表示,都可以一次又一次地从其它并行表示分支接收信息,从而得到信息更丰富的高分辨率表示。最后阶段采用融合后的最高分辨率进行姿势识别。第一个阶段包含4个残差单元,每个单元由一个宽度为64的bottleneck块组成,然后经过一个3
×
3的卷积层将feature maps减少到c(c为32或48),然后进入到第二个阶段。在第二、三、四阶段中分别包含1、4、3个交换块,在每个交换块
的多分辨率并行卷积中,每个分支包含4个残差单元。其中每个残差单元在每个分辨率中又包含两个3
×
3的卷积,同时每个卷积后面均跟着一个标准化批处理和非线性激活relu操作。这四个分辨率卷积的通道宽度是2c,4c和8c。并行化多分辨率子网络及重复多尺度融合,每一阶段的分辨率特征图都由上一阶段的分辨率特征图以及它的下采样特征图组成,每一条子网络中特征图的尺度不变,但是相邻两条子网络的尺度随着不断加入其尺度会减小,然而,每条子网络内部特征图会接受来自相邻子网络上层特征传递给他们的其他尺度信息,这样的交叉特征融合的进行分为三种情况,从左到右是高分辨率、中分辨率和低分辨率的信息融合方式,这种融合方式统一交给“交换块”完成,其实也就是相应比例上、下采样的统称。高分辨率汇合采用上一层的低分辨率进行上采样以及同子网络的特征图进行融合;中分辨率汇合采用相邻前后俩子网络上一层的特征图分别上采样和下采样以及同自网络上层特征图的融合;低分辨率则是直接由高分辨率下采样汇合到自己原有的低分辨率特征图。与已有的产生高清特征的结构比较一共总结了两类high-to-low和low-to-high结构:以hourglass为例的降分辨率和升分辨率完全对称的方式;simplebaseline为例降分辨率采用较重的分类基网络,升分辨率采用轻量的结构,这种轻量的方式包括:反卷积、空洞卷积。从该情况可以看出,以上结构都有两个共同点:单次地进行多尺度融合而本结构胜在多次交叉融合。
[0055]
heatmap估计:需要明确的是关键点检测的标注数据只是单个像素,在制作训练数据的 groundtruth时,应当用一个以该像素为中心,一个单位像素为方差的二维高斯核表示成heatmap 的形式。
[0056]
网络结构具体化:hrnet的主干网络,包含有4个并行子网络(4个阶段),其分辨率逐渐衰减一半,对应的,网络宽度(通道数)增加2倍。第一个阶段含4个残差单元,与resnet50相同,每个残差单元是由宽度为64的bottleneck组成,其后接一个3
×
3卷积,以将特征图宽度降低到c。第2,3,4个阶段中分别包含1,4,3个交换块(多尺度特征融合结构)。每个交换块包含4个残差单元,每个参差单元在每个分辨率都包含2个3
×
3卷积和一个跨分辨率的交换单元。也就是说,总共包含8个交换单元,得到了8个尺度的融合。实现中,采用了一个小网络hrnet-w32和一个大网络hrnet-w48。其中,32和48分别表示在最后三个阶段中高分辨率子网络的hrnet
‑ꢀ
32的其它三个并行子网络的宽度分别是64,128,256。hrnet-48的其它三个并行子网络的宽度分别为96,192,384。
[0057]
其中步骤四具体流程为:三维人体姿态采用局部连接网络,将hrnet算法得到二维人体骨架结构然后通过lcn神经网络模型将二维人体骨架结构抬升至三维空间中,得到三维人体姿态,获得人体17个骨骼关键点的三维坐标,存入领感智体模板动作库。
[0058]
lcn神经网络模型将二维人体骨架结构抬升至三维空间中的操作方式为:
[0059]
使用基于单目图像的三维人体姿态估计方法(lcn)包括两个模块:(1)基于cnn的二维位姿估计;(2)基于lcn的三维位姿估计。使用三个损失来估计三维人体姿态:
[0060]
l=λhl
heatmap
λ
2d
l
2d
λ
3d
l
3d
[0061]
其中l
heatmap
、l
2d
和λ
3d
分别是在2d姿势热图、2d关节位置和3d关节位置上强制执行的损失函数;
[0062]
l
heatmap
的计算方法为:
[0063][0064]
用{h_1,
…
,h_n}表示cnn从图像中估计的热图,其中n是身体关节类型的数量。对应的地面真实热图由{h_1^9,
…
,h_n^9}表示,其中每个h_i^9是通过应用以第i个关节的地面真实位置为中心的2d高斯来生成的。在以前的工作的基础上,在估计的热图和地面真实的热图之间实施了 l2损失。
[0065]
l
2d
的计算方法为:
[0066]
通过使用积分技巧计算热图的“期望值”来将热图hi变换成2d坐标ji,以便它可以被馈送到 lcn网络以估计3d姿态。
[0067]
首先通过在空间轴上应用softmax运算符来归一每个热图hi,使得它们的和为一:
[0068][0069]
其中w和h分别是热图的宽度和高度。超参数α,被称为“逆温度”,用于调整归一化热图的锐度。关节ji的二维位置被计算为~的质心hi:
[0070][0071]
在估计位置ji和地面真实位置之间强制实施稳健的l1损失:
[0072][0073]
当使用不同的α值来归一化热图时计算的2d姿势。(f)通过在每个热图中找到最大热图响应来获得2d姿势。
[0074]
所述λ
3d
的计算方法为:
[0075]
最后一步中估计的2d位姿{j1,
…
,jn}被馈送到lcn网络以估计相应的3d位姿在估计的3d姿势和地面真实3d姿势之间强制l2损失:
[0076][0077]
其中是第i个关节的地面真实3d位置。
[0078]
lcn网络构建流程为:
[0079]
通过将拉普拉斯算子分解为结构矩阵和权重矩阵的乘积来重构gcn。权重分担方案损害了gcn 的代表权,去掉两个矩阵中的结构约束后,得到了更一般的公式,其中gcn和fcn是它的特例。最后,在公式的基础上,通过构造不同的矩阵,我们引入了lcn,它结合了fcn和gcn的优点。
[0080]
重新表述了gcn,使得拉普拉斯算子固有的权重分担方案可以清楚地暴露出来。基
于公式eq.,通过对输入特征y∈rn应用过滤器g
θ
来获得n个节点的输出特征向量
[0081][0082]
对于不同的特征维度(总计m
i0put
)和扩展阶数(总计k),该过滤器具有不同的θ。但是,图形中的不同节点共享相同的过滤器θ。我们可以看到上面的等式,同一组θ用于计算对应于不同节点的不同维度的y。通过修改上面的公式得到:
[0083][0084]
基于拉普拉斯矩阵lk的定义,更仔细地查看对应于第q个节点yq的输出特征,其是y的第q 个维度,如果连接关节i和j的最小边数(即,它们在图上的距离)大于k,则lk(i,j)=0。特征 yq可以表示为:
[0085][0086]
其中θkm∈rn
×
1是通过重复θkm n次构造的。然后用更紧致的矩阵形式重新表示m上的内和,得到
[0087][0088][0089]
其中k表示串联。是一个lk(:,q)重复n次的向量。它包含节点q的邻域信息,可以将该公式推广到图中的所有节点:
[0090][0091]
其中sk和wk都是形状为m
inputn×
n,specifically,的2d矩阵。具体地说,是sk的第q列,是wk的第q列。
[0092]
上述实施例是对本发明的说明,不是对本发明的限定,任何对本发明简单变换后的方案均属于本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。