1.本发明涉及时间序列预测领域,特别是涉及一种基于双注意力机制的多要素海表面温度预测方法。
背景技术:
2.目前已存在的预测海温的方法分为两类。一类是基于海洋学物理的数值预测,它使用一系列复杂的物理方程来描述海温变化规律,这些方程通常很复杂,需要大量的计算工作。另一类是数据驱动模型,如支持向量机(svm)和人工神经网络(神经网络),它们从海温数据中自动学习海温变化趋势,随着大量海洋监测数据的不断收集,数据驱动的海温时间序列预测方法显示出良好的效果。
3.由于多要素时间序列模型更接近客观实际,可以实现更准确的预测。因此,利用多要素时间序列海温数据,可以通过模型学习有效提取物理机制对海温的影响,提高在不同海域的适用性,实现更准确的海温预测。然而,长期多要素时间序列的海温预测仍然是一个具有挑战性的问题,主要体现在不同序列之间关系的特征表示和选择机制上。sst(海表温度)数据是长期数据序列,通常涉及大量数据。许多学者将海温预测视为时间序列回归问题,并提出了许多预测海温的时间序列方法。例如,自回归综合移动平均(arima)模型只关注季节性和规律性,这虽然有效地提取了时间序列本身的长期相关性,但忽略了其他序列的相关性。因此,arima模式不适用于非平稳多要素时间序列海温预测。又比如递归神经网络(rnn)是一个专门用于时间序列建模的神经网络,然而,传统rnn在处理长期时间序列时容易出现梯度消失的问题。因此,基于rnn的时间序列预测模型很少用于海温预测。由此可得知,现有的海温预测模型没有考虑到海温和其他海洋要素之间的复杂相互作用,并且存在随着输入序列长度增加而性能下降的问题。
技术实现要素:
4.基于此,有必要针对现有的海温预测模型没有考虑到海温和其他海洋要素之间的复杂相互作用,并且存在随着输入序列长度增加而性能下降的问题,提供一种基于双注意力机制的多要素海表面温度预测方法。
5.一种基于双注意力机制的多要素海表面温度预测方法,所述方法包括:
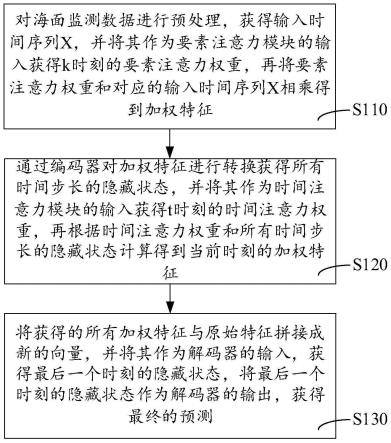
6.对海面监测数据进行预处理,获得输入时间序列x,并将其作为要素注意力模块的输入获得k时刻的要素注意力权重再将要素注意力权重和对应的输入时间序列x相乘得到加权特征x
′
;
7.通过编码器对加权特征x
′
进行转换获得所有时间步长的隐藏状态h
l
,并将其作为时间注意力模块的输入获得t时刻的时间注意力权重β
t
,再根据时间注意力权重β
t
和所有时间步长的隐藏状态h
l
计算得到当前时刻的加权特征x
″
t-1
;
8.将获得的所有加权特征x
″
与原始特征x
t-1
拼接成新的向量,并将其作为解码器的输入,获得最后一个时刻的隐藏状态c
t
,将最后一个时刻的隐藏状态c
t
作为解码器的输出,
获得最终的预测。
9.进一步的,所述海面监测数据,包括:
10.气温、气压、风速、风向和海面温度。
11.进一步的,所述对海面监测数据进行预处理,包括:
12.将缺少度量值的数据替换为默认值-999;
13.将不可度量的数据替换为nan值;
14.使用-999或nan前后5个有效值的平均值来对-999或nan进行替换。
15.进一步的,所述获得输入时间序列x,包括:
16.增加一个新的特征ssta来表示当前sst与年平均sst的相对差异;
17.确定原始sst时间序列的向量a、年际平均值和年际标准差σ;然后据此获得每个时间步长的sst与年际平均变化的差值a
*
;
18.将a
*
作为ssta要素,将该ssta要素与原始特征x
t-1
合并作为输出序列x。
19.进一步的,所述每个时间步长的sst与年际平均变化的差值a
*
,为:
[0020][0021]
式中,a是原始sst时间序列的向量,是年际平均值,σ是标准差。
[0022]
进一步的,所述将其作为要素注意力模块的输入获得k时刻的要素注意力权重包括:
[0023]
将多个输入时间序列x作为要素注意力模块的输入,并通过点积运算获得注意力评分e
l
;
[0024]
使用softmax函数将k时刻的要素注意力评分映射为要素注意力权重αk。
[0025]
进一步的,所述将多个输入时间序列x作为要素注意力模块的输入,并通过点积运算获得注意力评分e
l
,包括:
[0026]el
=xwe(xk)
t
,
[0027]
式中,we∈r
p
×
p
是要学习的参数,xk表示sst的特征向量。
[0028]
进一步的,所述将其作为时间注意力模块的输入获得t时刻的时间注意力权重,包括:
[0029]
将h
l
作为时间注意力模块的输入向量,在t时刻,通过解码器上一个时刻隐藏状态c
t-1
和编码器所有的隐藏状态计算得到时间注意力评分g
t
;
[0030]
使用softmax函数将时间注意力评分g
t
映射为时间注意力权重β
t
。
[0031]
进一步的,所述将h
l
作为时间注意力模块的输入向量,在t时刻,通过解码器上一个时刻隐藏状态c
t-1
和编码器所有的隐藏状态计算得到时间注意力评分g
t
,包括:
[0032][0033]
式中,是t时刻的时间注意力评分,wg∈rm×q,ug∈rm×m,bg∈rm,是学习的参数。
[0034]
进一步的,所述获得最后一个时刻的隐藏状态c
t
,包括:
[0035]ct
=f2(c
t-1
,[x
″
t-1
,x
t-1
]),
[0036]
式中,[x
″
t-1
,x
t-1
]∈r
m n
,c
t
∈r
m n
是t时刻解码器的隐藏状态,c
t-1
为t时刻的隐藏状态。
[0037]
上述基于双注意力机制的多要素海表面温度预测方法,通过编码器-解码器架构的预测模型用于长期时间序列sst预测,显著提高了预测精度。其中要素注意力和时间注意力模块不仅可以自适应地选择最相关的要素特征,还可以适当地捕捉时间序列sst数据的长期时间相关性。
附图说明
[0038]
图1为一个实施例中的预测方法的流程图;
[0039]
图2为图1中预测模型的总体框架图;
[0040]
图3为图2中要素注意力模块详解图;
[0041]
图4为图2中时间注意力模块详解图。
具体实施方式
[0042]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地说明,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0043]
如图1至图4所示,在一个实施例中,一种基于双注意力机制的多要素海表面温度预测方法,包括以下步骤:
[0044]
步骤s110,对海面监测数据进行预处理,获得输入时间序列x,并将其作为要素注意力模块的输入获得k时刻的要素注意力权重再将要素注意力权重和对应的输入时间序列x相乘得到加权特征x
′
。其中对海面监测数据进行预处理,包括:将缺少度量值的数据替换为默认值-999(missing_val=-999);将不可度量的数据替换为nan值;使用-999或nan前后5个有效值的平均值来对-999或nan进行替换。同时,增加一个新的特征ssta来表示当前sst与年平均sst的相对差异;随后确定原始sst时间序列的向量a、年际平均值和年际标准差σ;然后据此获得每个时间步长的sst与年际平均变化的差值a
*
;最后将a
*
作为ssta要素,将该ssta要素与原始特征x
t-1
合并作为输出序列x。其中a为原始sst时间序列的向量a=(a1,
…
,a
t-1
,
…
,a
t
)。t为sst序列的总长度。多要素时间序列的输入为x=(x1,
…
,xk,
…
,xn)=(x1,
…
,x
t-1
,
…
,x
t
)
t
∈rn×
t
,t为时间窗口的大小,n为要素的个数。
[0045]
示例性的,上述海面监测数据来自中国沿海站点(ccs)监测数据,包括在中国海域13个站点观测的多要素水文数据。为了证明该方法的泛化能力,使用了六个站点数据集(zhi、xmd、dcn、lsi、nji、zlg)来验证所提出的方法。从2012/1年至2013/7年,每小时对数据进行采样。zhi和dcn相当于大约12925小时的监测数据,lsi站点和zlg站点相当于大约13160小时的监控数据,xmd站点和nji站点分别对应大约13395、12690小时的监测数据。在本次实验中,采用海温作为目标要素。最终数据包含了五种要素:气温、气压、风速、风向、海面温度。
[0046]
上述将其作为要素注意力模块的输入获得k时刻的要素注意力权重包括:将多个输入时间序列x作为要素注意力模块的输入,并通过x与xk点积运算获得要素注意力评分e
l
。其中xk表示sst的特征向量,它是获得注意力权重的重要特征。而要素注意力评分表示为公式为:
[0047]el
=xwe(xk)
t
,
[0048]
式中,we∈r
p
×
p
是要学习的参数,xk表示sst的特征向量。
[0049]
其中要素注意力权重
[0050]
使用softmax函数将k时刻的要素注意力评分映射为要素注意力权重αk。公式为:
[0051][0052]
式中,表示注意力评分值。
[0053]
最后,将要素注意力权重与对应的输入序列x对应相乘得到加权特征x
′
,它将作为编码器的输入进一步提取时间特征。公式为:
[0054][0055]
步骤s120,通过编码器对加权特征x
′
进行转换获得所有时间步长的隐藏状态并将其作为时间注意力模块的输入获得t时刻的时间注意力权重β
t
,再根据时间注意力权重β
t
和所有时间步长的隐藏状态h
l
计算得到当前时刻的加权特征x
″
t-1
。其中编码器是基于lstm的编码器。基于lstm的编码器能够学习一个函数映射f1,通过加权特征x
′
t
和上一时刻的隐藏状态映射获得当前的隐藏状态其公式为:
[0056][0057]
式中,h
t
∈rm表示t时刻的编码器的隐藏状态,m是编码器隐藏状态的大小,f1是一个基于lstm的非线性激活函数,由此获得了每个时间步长的隐藏状态h
l
。
[0058]
上述将其作为时间注意力模块的输入获得t时刻的时间注意力权重,包括:将h
l
作为时间注意力模块的输入向量,在t时刻,通过解码器上一个时刻隐藏状态c
t-1
和编码器所有的隐藏状态计算得到时间注意力评分计算得到时间注意力评分其公式为:
[0059][0060]
式中,是t时刻的时间注意力评分,wg∈rm×q,ug∈rm×m,bg∈rm,是学习
的参数。
[0061]
使用softmax函数将时间注意力评分g
t
映射为时间注意力权重映射为时间注意力权重
[0062]
其中,根据时间注意力权重β
t
和所有时间步长的隐藏状态h
l
计算得到当前时刻的加权特征,公式为:
[0063][0064]
式中,x
″
t-1
为当前时刻的加权特征。
[0065]
步骤s130,将获得的所有加权特征x
″
与原始特征x
t-1
拼接成新的向量,并将其作为解码器的输入,获得最后一个时刻的隐藏状态c
t
,将最后一个时刻的隐藏状态c
t
作为解码器的输出,获得最终的预测。具体为,获得所有的加权特征x
″
=(x
″1,
…
,x
″
t-1
,
…
,x
″
t
)∈r
t
×m后,将其与原始特征(x1,
…
,x
t-1
,
…
,x
t
)拼接获得新的向量[x
″
t-1
,x
t-1
]∈r
m n
。获得最后一个时刻的隐藏状态c
t
,其公式为:
[0066]ct
=f2(c
t-1
,[x
″
t-1
,x
t-1
]),z
t-1
=[x
″
t-1
,x
t-1
],
[0067]
式中,[x
″
t-1
,x
t-1
]∈r
m n
,c
t-1
为t时刻的隐藏状态,c
t
∈r
m n
是t时刻解码器的隐藏状态,它被用于获取最终的预测结果。公式为:
[0068][0069]
式中,和by∈r1是学习的参数。
[0070]
上述实验数据集以4:1的比例划分为训练集和测试集。模型基于keras theano深度学习框架开发,并使用adam优化器。初始学习率设置为0.001。实验环境为windows10,intel core i7 3.0ghz,8gb ram。结合模型和实验设置,分别对六个站点数据(zhi、xmd、dcn、lsi、nji、zlg)进行训练和预测,并使用预测精度(pacc)、均方根误差(rmse)和平均绝对误差(mae)三种指标来评估预测方法的有效性,计算过程公式为:
[0071][0072][0073][0074]
式中,
yreal,i
表示sst的真实值,y
pred,i
表示样本值,n表示预测点的总数。mae和rmse值越小,性能越好。pacc值与模型性能呈正相关。
[0075]
上述基于双注意力机制的多要素海表面温度预测方法,通过编码器-解码器架构的预测模型用于长期时间序列sst预测,显著提高了预测精度。其中要素注意力和时间注意力模块不仅可以自适应地选择最相关的要素特征,还可以适当地捕捉时间序列sst数据的长期时间相关性。在中国沿海地区的大量实验表明,该tma-seq2seq模型在海温时间序列预
测方面优于其他方法。此外,在不同海域的实验证明,该模型在海温预测中具有实用价值,且具有较强的鲁棒性。
[0076]
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
