1.本发明属于计算机视觉、身份识别、特征融合等交叉技术领域,具体涉及一种基于人体轮廓和关键点特征融合的步态识别方法。
背景技术:
2.步态是人类生物行为特点的一种,描述了人行走过程中上下关节的运动变化规律,医学上认为每个人的步态是独一无二的,人体步态特征具有全球唯一性、长期不变性、不易撤销性、易采集性、不可模仿性、不易伪装性、非接触性等特点,是目前最适合大范围多领域普及的生物特征。步态识别是从个体的行走模式中提取身体和行为的特征来进行身份识别。在高级安保领域,由于步态特征的难以伪装和模仿性,可辅助虹膜特征进行混合生物特征识别以提高安全性能,给金融和军事等领域带来更强的安全保障。
3.虽然每个人步态是独一无二的,但是服装、随身携带的东西、视角以及视角等因素都给步态识别带来了重大挑战,为了解决这些问题,人们提出了各种方法。早期人们从每个人行走时身体各个部分的不同来对人物进行区别,但这意味着要对身体的众多结构进行建模,涉及大量的变量和复杂的运算;从原始的rgb图像中进行识别也是一个研究方向,但是该方法面临是消除步态不相关信息的挑战;随着深度学习的迅速发展,目前基于人体轮廓和人体骨骼关键点的两种步态识别方法渐渐变成了主流。
4.基于人体轮廓的方法可以很大程度上避免视频序列中无关像素点的干扰,迅速、有效地提取轮廓序列中的特征,且该方法适用于低分辨率的条件。尽管基于轮廓序列的方法有很多优势,但是该方法只保留了人体外部轮廓,在行走过程中人物的躯干信息无法得到利用。基于人体骨骼关键点的方法对视频序列中的人物进行姿态估计,提取人物的骨骼关键点,并从骨骼关键点序列中进行识别,该方法可以很好的提取身体结构信息,但是忽略了可鉴别的体型信息,导致性能不高。
5.人体轮廓图保留了体型信息,人体骨骼关键点保留了身体结构信息,这两种特征是互补的,他们的组成有望成为步态的更全面的表示,然后轮廓和骨骼关键点的互补优势在以往的研究中并没有被充分利用。
技术实现要素:
6.发明目的:为了克服现有技术中的不足,本发明提供一种基于人体轮廓和关键点特征融合的步态识别方法,该方法从一段行人步态视频中分别提取人体轮廓序列和人体关键点序列,利用人体轮廓特征提取模块和人体关键点特征提取模块分别提取其特征,然后进行特征层融合得到步态融合特征,提高步态识别的准确率和鲁棒性。
7.技术方案:第一方面本发明提供一种基于人体轮廓和关键点特征融合的步态识别方法,包括:
8.基于输入的单人行走步态视频,获取视频中的行人轮廓序列,并将步态视频代入openpose算法模块,获得归一化的人体关键点信息序列;
9.将行人轮廓序列代入gaitset算法模块,获得步态轮廓序列的特征;将人体关键点信息序列导入人体关键点特征提取模块,得到人体关键点的特征;
10.基于步态轮廓序列的特征和人体关键点的特征,分别获得步态轮廓特征向量和人体关键点特征向量;
11.将步态轮廓特征向量和人体关键点特征向量连接后输入特征融合模块,获得步态融合特征;
12.将步态融合特征导入融合网络进行特征学习,识别出视频中人物的身份。
13.在进一步的实施例中,输入单人行走的步态视频,获取视频中的行人轮廓序列的方法包括:
14.步态视频利用knn算法,获得步态视频每帧图像的人体轮廓;
15.基于每帧图像的人体轮廓计算每帧单人轮廓图像的非零像素点个数,并根据图像像素的阈值选择是否输出图像;
16.对输出的图像获取不为0的行像素和的上限值和下限值的索引值区间,并根据索引值区间裁剪输出图像的上下区域,获得裁剪图像;
17.在裁剪图像中查找基于x轴的中位数,并以查找出中位数确定图像中人的x轴中心点;
18.从中心点开始各向两侧进行切片,得到行和列都为64位的图像数组;
19.转换图像数组类型,获得行人轮廓序列。
20.在进一步的实施例中,将步态视频代入openpose算法模块,获得归一化的人体关键点信息序列的方法包括:
21.基于步态视频,获取视频中人体各个关键点的位置坐标;
22.在视频中人体各个关键点的位置坐标中选取颈部关键点的位置为原点,以颈部和臀部的距离为基准,对其他关键点做归一化,获得归一化后的人体关键点帧序列;
23.其中,归一化公式为:
[0024][0025]
式中,pi是关键点i的位置,p
′i是关键点归一化后的位置,p是颈部关节点的位置,d是颈部和臀部关键点之间的距离。
[0026]
在进一步的实施例中,所述人体关键点特征提取模块包括:lstm模块和cnn模块;将人体关键点信息序列导入人体关键点特征提取模块,得到人体关键点的特征的方法为获取的人体关键点帧序列分别传入lstm模块和cnn模块,获得人体关键点的每帧的特征。
[0027]
在进一步的实施例中,基于人体关键点的特征,获得人体关键点特征向量的方法包括:
[0028]
基于人体关键点的每帧的特征,得到每帧特征所关联的特征向量,并将得到的每帧的特征向量进行连接;
[0029]
将连接后特征向量输入压缩块,得到62
╳
128维的人体关键点特征向量。
[0030]
在进一步的实施例中,所述lstm模型由全连接层和lstm层组成,将lstm的特征维度设置为256维;
[0031]
所述cnn模块为设置10层3
╳
3的卷积层,第一层卷积层的过滤器数量设置为32个,
第二层和第三层卷积层以及第五层和第六层卷积层中间分别设置一个池化层,第二层到第四层卷积层的过滤器数量设置为64个,其余过滤器数量设置为128个,并将第一层池化层与第四层卷积层进行残差连接、第二层池化层和第七层卷积层进行残差连接,全连接层的维度设置为256维数;
[0032]
特征提取模块还包括压缩模块,所述压缩模块由bn层、relu层、dropout层和128维的全连接层组成。
[0033]
在进一步的实施例中,将步态轮廓特征向量和人体关键点特征向量连接后输入特征融合模块,获得步态融合特征的方法包括:
[0034]
将步态轮廓特征向量和人体关键点特征向量的每一维度进行连接,获得每一维度的连接向量;
[0035]
将每一维度的连接向量导入特征融合模块的全连接层,得到人体步态融合特征向量;
[0036]
其中,特征融合模块引入三元损失函数进行训练,三元损失函数的表达公式为:
[0037][0038][0039]
式中,l
ba
()表示正负样本的损失值之和,表示锚点样本与正样本之间的距离和锚点样本与负样本之间的距离的差,表示第i个锚点样本,表示第j个锚点样本,d表示两个样本之间的距离,表示第i个正样本,表示第i个负样本,m表示根据实际需要设定的阈值参数,用于控制锚点样本与正样本的距离和锚点样本与负样本的距离之差,a表示锚点样本,p表示负样本,n表示负样本,i表示正样本编号,j表示负样本编号,p表示有p个id,k表示每个id有k个样本。
[0040]
在进一步的实施例中,将步态融合特征导入融合网络进行特征学习,识别出视频中人物的身份的方法包括:
[0041]
将步态融合特征fq与融合网络特征库中的每一个特征fg进行欧氏距离的计算,获得将步态融合特征fq与融合网络特征库中的每一个特征fg距离结果;
[0042]
基于距离结果的远近,选择近似的距离结果并基于近似的距离结果关联的特征确定识别结果,从而对该视频中的人物完成身份识别。
[0043]
第二方面本发明提供一种处理装置,包括存储器和处理器,存储器存储有计算机程序,其被处理器执以实现上述的基于人体轮廓和关键点特征融合的步态识别方法。
[0044]
第三方面本发明提供一种可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述方法的步骤。
[0045]
有益效果:本发明与现有技术相比具有以下优点:
[0046]
(1)本发明运用形态学方法和openpose算法分别提取步态视频中人物的轮廓序列和骨骼关键点序列,作为行人的初始行走特征表示。
[0047]
(2)本发明引入gaitset算法提取轮廓序列中的特征,再通过lstm网络和cnn网络
的组合提取骨骼关键点序列中的时序特征。
[0048]
(3)本发明运用特征层融合方法获取步态的融合特征,通过融合网络的学习得到每个人的全面的特征表达,有效提高步态识别的准确性与可靠性。
附图说明
[0049]
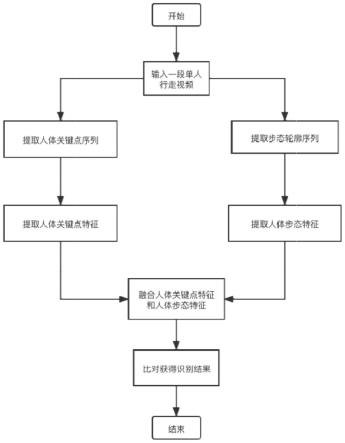
图1是总体方法流程图。
[0050]
图2是基于特征融合的步态特征提取网络的架构图。
具体实施方式
[0051]
为了更充分理解本发明的技术内容,下面结合具体实施例对本发明的技术方案进一步介绍和说明,但不局限于此。
[0052]
如图1、图2所示一种基于人体轮廓和关键点特征融合的步态识别方法,包括以下步骤:
[0053]
步骤1)输入单人行走的步态视频,获取视频中的行人轮廓序列
[0054]
其中在获取视频中的行人轮廓序列过程中,还对行人轮廓序列裁剪,去除无效像素点,具体步骤如下:
[0055]
步骤11)利用knn算法提取每帧图像的人体轮廓;
[0056]
步骤12)计算每帧单人轮廓图像的非零像素点个数,如果图像像素和小于10000,不返回图像信息;
[0057]
步骤13)获取不为0的行像素和的最高和最低索引,以此对图像的上下区域进行裁剪;
[0058]
步骤14)获取x轴的中位数,并将其视为人的x中心,如果找不到图像中位数,不返回图像信息;
[0059]
步骤15)从中心点开始各向两侧进行切片,得到行和列都为64的图像数组,如果取值超出图像范围,则向右平移,再通过全0数组从两侧进行拼接;
[0060]
步骤16)转换图像数组类型并返回,获得裁剪后的行人轮廓序列。
[0061]
步骤2、将步态视频代入openpose算法模块,获得归一化的人体关键点信息序列,将行人轮廓序列代入gaitset算法模块,获得步态轮廓序列的特征;
[0062]
获得归一化的人体关键点信息序的步骤如下:
[0063]
步骤21)获取视频中人体各个关键点的位置坐标;
[0064]
步骤22)在人体关键点检测中,颈部和臀部是相对稳点的关键点,选取颈部关节点的位置为原点;
[0065]
步骤23)以颈部和臀部的距离为基准,对其他关键点做归一化,归一化公式为:
[0066][0067]
其中pi是关键点i的位置,p
′i是关键点归一化后的位置,p是颈部的位置,d是颈部和臀部关键点之间的距离。
[0068]
其次行人轮廓特征提取包括以下步骤:
[0069]
步骤24)将步骤1)得到的行人轮廓序列输入gaitset网络,从而获得行人轮廓特
征;
[0070]
步骤25)经gaitset网络计算,得到62*128维的特征向量。
[0071]
步骤3、将人体关键点信息序列由lstm和cnn组成的人体关键点特征提取模块,得到人体关键点的特征;
[0072]
步骤4基于人体关键点的特征,获得人体关键点特征向量的方法包括:
[0073]
步骤41)获取的人体关键点帧序列分别传入lstm模块和cnn模块,获得人体关键点的每帧的特征,并将得到的每帧的特征向量进行连接;
[0074]
步骤42)将连接后特征向量输入压缩块,得到62
╳
128维的人体关键点特征向量。
[0075]
人体关键点特征提取模块由提取时序信息lstm网络、提取空间信息的cnn网络组成和压缩模块组成。
[0076]
lstm模型由全连接层和lstm层组成,将lstm的特征维度设置为256维。
[0077]
cnn模型设置10层3
╳
3的卷积层,第一层卷积层的过滤器数量设置为32,第二层和第三层卷积层以及第五层和第六层卷积层中间分别设置一个池化层,第二层到第四层卷积层的过滤器数量设置为64,其余过滤器数量设置为128,借鉴resnet的残差连接思想,将第一层池化层与第四层卷积层进行残差连接、第二层池化层和第七层卷积层进行残差连接,全连接层的维度设置为256。
[0078]
为防止过拟合,设置一个压缩模块,由bn层、relu层、dropout层和128维的全连接层组成。
[0079]
步骤5、将步态轮廓特征向量和人体关键点特征向量连接后输入特征融合模块,获得步态融合特征的方法包括:
[0080]
步骤51)将62
╳
128维步态轮廓特征向量和62
╳
128维人体关键点特征向量的每一维度进行连接,获得每一维度的连接向量;
[0081]
步骤52)将每一维度的连接向量导入特征融合模块的全连接层,得到人体步态融合特征向量;
[0082]
其中,特征融合模块引入三元损失函数进行训练,三元损失函数的表达公式为:
[0083][0084][0085]
式中,l
ba
()表示正负样本的损失值之和,表示锚点样本与正样本之间的距离和锚点样本与负样本之间的距离的差,表示第i个锚点样本,表示第j个锚点样本,d表示两个样本之间的距离,表示第i个正样本,表示第i个负样本,m表示根据实际需要设定的阈值参数,用于控制锚点样本与正样本的距离和锚点样本与负样本的距离之差,a表示锚点样本,p表示负样本,n表示负样本,i表示正样本编号,j表示负样本编号,p表示有p个id,k表示每个id有k个样本。
[0086]
步骤6、将步态融合特征导入融合网络进行特征学习,识别出视频中人物的身份的方法包括:
[0087]
步骤61)将步态融合特征fq与融合网络特征库中的每一个特征fg进行欧氏距离的计算,获得将步态融合特征fq与融合网络特征库中的每一个特征fg距离结果;
[0088]
步骤62)基于距离结果的远近,选择近似的距离结果并基于近似的距离结果关联的特征确定识别结果,从而对该视频中的人物完成身份识别。
[0089]
本发明获取一段步态视频序列,从视频序列中分别提取人体轮廓序列和人体关键点序列,利用人体轮廓特征提取模块和人体关键点特征提取模块分别提取其特征,然后进行特征层融合得到步态融合特征,通过融合网络进行特征学习,并引入三元损失函数进行训练,从而实现准确识别视频中人物的身份。
[0090]
实施例2提供一种处理装置,包括存储器和处理器,存储器存储有计算机程序,其被处理器执以实现下述的基于人体轮廓和关键点特征融合的步态识别方法:
[0091]
基于输入的单人行走步态视频,获取视频中的行人轮廓序列,并将步态视频代入openpose算法模块,获得归一化的人体关键点信息序列;
[0092]
将行人轮廓序列代入gaitset算法模块,获得步态轮廓序列的特征;将人体关键点信息序列导入人体关键点特征提取模块,得到人体关键点的特征;
[0093]
基于步态轮廓序列的特征和人体关键点的特征,分别获得步态轮廓特征向量和人体关键点特征向量;
[0094]
将步态轮廓特征向量和人体关键点特征向量连接后输入特征融合模块,获得步态融合特征;
[0095]
将步态融合特征导入融合网络进行特征学习,识别出视频中人物的身份。
[0096]
实施例3提供一种可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述方法的步骤。
[0097]
综上本发明运用形态学方法和openpose算法分别提取步态视频中人物的轮廓序列和骨骼关键点序列,作为行人的初始行走特征表示;引入gaitset算法提取轮廓序列中的特征,再通过lstm网络和cnn网络的组合提取骨骼关键点序列中的时序特征;运用特征层融合方法获取步态的融合特征,通过融合网络的学习得到每个人的全面的特征表达,有效提高步态识别的准确性与可靠性。
[0098]
本技术的实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0099]
本技术的实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0100]
本技术是参照根据本技术实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实
现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0101]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0102]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0103]
以上所述仅是本发明的优选实施方式,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。