1.本发明涉及信号处理(signal processing),特别是涉及一种音频处理(audio processing)方法及音频处理装置,诸如基于多长度卷积/去卷积层的(multi-length-convolution/deconvolution-layer-based)音频处理方法及装置,以及非暂态计算机可读取媒体(non-transitory computer-readable medium)。
背景技术:
2.音频分离(audio separation)旨在分离音频混合信号(audio mixture signal)并提取我们感兴趣的部分。它可以应用于许多不同的领域,例如耳机、扬声器和电视产业,以改善用户体验。举例来说,歌声(singing voice)分离可将音频混合信号分离为人声和背景音乐。干净的人声可以用于歌手识别(singer identification)、自动歌词转录(automatic lyrics transcriptions)、音调追踪(pitch tracking)、人声增强效果(vocal enhancement effect)等。分离的背景音乐也可能是用于娱乐的资产(asset)。因此,需要一种新颖的方法及相关架构,以在没有副作用或较不可能带来副作用的状况下实现可靠的音频分离处理。
技术实现要素:
3.本发明的一目的在于提供一种音频处理方法及音频处理装置,诸如基于多长度卷积/去卷积层的音频处理方法及装置,以及非暂态计算机可读取媒体,以解决上述问题。
4.本发明的另一目的在于提供一种音频处理方法及音频处理装置,诸如基于多长度卷积/去卷积层的音频处理方法及装置,以及非暂态计算机可读取媒体,以提升针对音频处理的神经网络(neural network)架构的整体效能。
5.本发明的至少一实施例提供一种音频处理方法,其中所述方法是可应用于(applicable to)具备音频处理功能的一电子装置(例如电视、影音系统等)。所述方法可包括:利用一第一卷积(convolution)层电路及一第二卷积层电路分别对一音频混合信号进行卷积处理,以产生一输入特征图(feature map),其中所述第一卷积层电路及所述第二卷积层电路中的每一卷积层电路包括多层一维(one-dimensional,1d)卷积内核(convolution kernel),以及所述第一卷积层电路及所述第二卷积层电路的卷积内核层长度分别等于一第一长度及一第二长度;对所述输入特征图进行对应于一预定神经网络模型的分离处理,以取得分别对应于一第一类型及一第二类型的一第一输出特征图及一第二输出特征图;以及利用一第一去卷积(deconvolution)层电路及一第二去卷积层电路分别对所述第一输出特征图的不同部分进行去卷积处理以产生对应的处理结果,以产生一第一音频输出信号,且利用所述第一去卷积层电路及所述第二去卷积层电路分别对所述第二输出特征图的不同部分进行去卷积处理以产生对应的处理结果,以产生一第二音频输出信号,其中所述第一去卷积层电路及所述第二去卷积层电路中的每一去卷积层电路包括多层一维卷积内核,以及所述第一去卷积层电路及所述第二去卷积层电路的卷积内核层长度分别
等于所述第一长度及所述第二长度。
6.本发明的至少一实施例提供一种音频处理装置。所述音频处理装置可包括:一音频信号分析器,其中所述音频信号分析器包括一第一卷积层电路及一第二卷积层电路;一分离器,耦接至所述音频信号分析器;以及一音频信号合成器,耦接至所述分离器,其中所述音频信号合成器包括一第一去卷积层电路及一第二去卷积层电路。例如:所述第一卷积层电路及所述第二卷积层电路可用来分别对一音频混合信号进行卷积处理,以产生一输入特征图,其中所述第一卷积层电路及所述第二卷积层电路中的每一卷积层电路包括多层一维卷积内核,以及所述第一卷积层电路及所述第二卷积层电路的卷积内核层长度分别等于一第一长度及一第二长度;所述分离器可用来对所述输入特征图进行对应于一预定神经网络模型的分离处理,以取得分别对应于一第一类型及一第二类型的一第一输出特征图及一第二输出特征图;以及所述第一去卷积层电路及所述第二去卷积层电路可用来分别对所述第一输出特征图的不同部分进行去卷积处理以产生对应的处理结果,以产生一第一音频输出信号,且利用所述第一去卷积层电路及所述第二去卷积层电路分别对所述第二输出特征图的不同部分进行去卷积处理以产生对应的处理结果,以产生一第二音频输出信号,其中所述第一去卷积层电路及所述第二去卷积层电路中的每一去卷积层电路包括多层一维卷积内核,以及所述第一去卷积层电路及所述第二去卷积层电路的卷积内核层长度分别等于所述第一长度及所述第二长度。
7.本发明的至少一实施例提供一种非暂态计算机可读取媒体,其存储有计算机可读取指令码使得一音频处理装置于执行所述计算机可读取指令码时进行一音频处理程序,所述音频处理程序包括:利用一第一卷积层电路及一第二卷积层电路分别对一音频混合信号进行卷积处理,以产生一输入特征图,其中所述第一卷积层电路及所述第二卷积层电路中的每一卷积层电路包括多层一维卷积内核,以及所述第一卷积层电路及所述第二卷积层电路的卷积内核层长度分别等于一第一长度及一第二长度;对所述输入特征图进行对应于一预定神经网络模型的分离处理,以取得分别对应于一第一类型及一第二类型的一第一输出特征图及一第二输出特征图;以及利用一第一去卷积层电路及一第二去卷积层电路分别对所述第一输出特征图的不同部分进行去卷积处理以产生对应的处理结果,以产生一第一音频输出信号,且利用所述第一去卷积层电路及所述第二去卷积层电路分别对所述第二输出特征图的不同部分进行去卷积处理以产生对应的处理结果,以产生一第二音频输出信号,其中所述第一去卷积层电路及所述第二去卷积层电路中的每一去卷积层电路包括多层一维卷积内核,以及所述第一去卷积层电路及所述第二去卷积层电路的卷积内核层长度分别等于所述第一长度及所述第二长度。
8.本发明的音频处理方法及音频处理装置可借助于不同长度的卷积层以及不同长度的去卷积层来进行音频处理,以提升针对音频处理的神经网络架构的整体效能。相较于相关技术,本发明的音频处理方法及音频处理装置可大幅地改善音频分离处理的声音输出的质量。
附图说明
9.图1为依据本发明一实施例的一种音频处理装置的示意图。
10.图2是依据本发明一实施例绘示的一种音频处理方法的一基于多长度卷积/去卷
积层的控制方案的示意图。
11.图3绘示所述音频处理方法所涉及的1d卷积/去卷积层的例子。
12.图4绘示所述音频处理方法所涉及的特征图的例子。
13.图5绘示所述音频处理方法所涉及的遮罩(mask)的例子。
14.图6依据本发明一实施例绘示所述音频处理方法的流程图。
15.图7依据本发明一实施例绘示所述音频处理方法所涉及的一种非暂态计算机可读取媒体。
具体实施方式
16.本发明的一或多个实施例涉及一种音频处理方法及音频处理装置以提升针对音频处理的神经网络架构的整体效能。相较于采用短时傅立叶变换(short time fourier transform,简称stft)的传统音频分离方法,时域神经网络(time-domain neural network)诸如全卷积时域音频分离网络(fully-convolutional time-domain audio separation network,简称conv-tasnet),其可视为一种端到端音频分离模型(end-to-end audio separation model),能达到更好的性能。conv-tasnet的编码器和解码器中的多个一维(one-dimensional,简称1d)卷积内核(convolution kernel)的长度相对较短并且长度都相同,这意味着编码器输出的内容具有较高的时间分辨率(temporal resolution)但具有较低的频率分辨率(frequency resolution)。肇因于上述较低的频率分辨率,声音的谐波之间的多个时频区域(time-frequency region)不能被妥善地解析(resolve),所以音频混合信号不能被妥善地分离。基于conv-tasnet的基本架构,本发明的音频处理方法及音频处理装置可借助于不同长度的卷积(convolution)层以及不同长度的去卷积(deconvolution)层来进行音频处理,以提升针对音频处理的神经网络架构的整体效能。
17.针对上述conv-tasnet,请参照下列文件:yi luo,and nima mesgarani,“conv-tasnet:surpassing ideal time
–
frequency magnitude masking for speech separation”,transactions on audio,speech,and language processing(taslp)2019,ieee;通过以上参照,这个文件的整体被纳入本发明的说明以提供某些相关实施细节的支持。
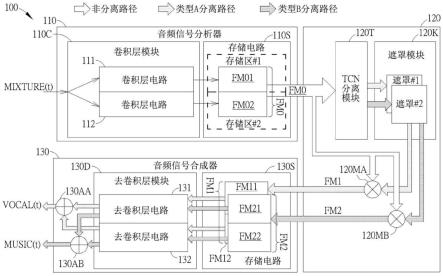
18.图1为依据本发明一实施例的一种音频处理装置100的示意图,其中音频处理装置100可作为上述音频处理装置的例子。为了便于理解,音频处理装置100可代表具备音频处理功能的一电子装置(例如电视、影音系统等),但本发明不限于此。于某些实施例中,音频处理装置100可包括所述电子装置的至少一部分(例如一部分或全部)。例如,音频处理装置100可包括所述电子装置的一部分,诸如所述电子装置的一控制电路,其可通过集成电路(integrated circuit,ic)等方式来实施。再例如,音频处理装置100可包括存储于所述电子装置中的非暂态计算机可读取媒体(例如,存储器)当中的特定计算机可读取指令码(例如,软件脚本或固件脚本),所述电子装置的所述控制电路或其他特殊功能电路可通过执行所述计算机可读取指令码以实施以下实施例所述的操作。又例如,音频处理装置100可包括所述电子装置的全部,诸如所述电子装置的整体(例如,包括软件、固件及硬件)。如图1所示,音频处理装置100可包括一音频信号分析器110及一音频信号合成器130,且包括一分离器120,其中分离器120耦接至音频信号分析器110,而音频信号合成器130耦接至分离器
120。音频信号分析器110可包括一卷积层模块110c及一存储电路110s,分离器120可包括一时间卷积网络(temporal convolution network,简称tcn)分离模块120t、一遮罩(mask)模块120k以及多个乘法器120ma及120mb,且音频信号合成器130可包括一去卷积层模块130d、一存储电路130s以及多个加法器130aa及130ab。另外,卷积层模块110c可包括卷积层电路111及112,且卷积层电路111及112中的每一卷积层电路可包括多层1d卷积内核。卷积层电路111及112的各自的卷积内核层长度彼此不同,尤其,卷积层电路111及112的卷积内核层长度可分别等于一第一长度诸如长度m及一第二长度诸如长度n。此外,去卷积层模块130d可包括去卷积层电路131及132,且去卷积层电路131及132中的每一去卷积层电路可包括多层1d卷积内核。去卷积层电路131及132的各自的卷积内核层长度彼此不同,尤其,去卷积层电路131及132的卷积内核层长度可分别等于所述第一长度诸如长度m及所述第二长度诸如长度n。在一些实施例中,音频信号分析器110及音频信号合成器130可分别为音频信号编码器及音频信号解码器,但本发明不限于此。
19.针对上述conv-tasnet,由于卷积/去卷积计算、tcn分离、遮罩处理(masking processing)等连同对应的卷积/去卷积层计算单元、tcn分离模块、遮罩等的实施方式为conv-tasnet领域的普通技术人员所熟知,故相关细节在此予以省略。本发明所提出的架构,诸如图1所示架构,可利用不同长度的卷积层来进行音频信号分析/编码以及利用不同长度的去卷积层来进行音频信号合成/解码,以提升整体效能。
20.基于图1所示架构,卷积层电路111及112可分别对一音频混合信号mixture(t)进行卷积处理,以产生一输入特征图fm0。举例来说,卷积层电路111可对音频混合信号mixture(t)的多个样本(sample)进行对应于所述第一长度诸如长度m的卷积处理,以产生输入特征图fm0的一局部(partial)特征图fm01,且卷积层电路112可对音频混合信号mixture(t)的所述多个样本进行对应于所述第二长度诸如长度n的卷积处理,以产生输入特征图fm0的一局部特征图fm02。存储电路110s的多个存储区(例如存储区#1及#2)可暂时地存储这些局部特征图fm01及fm02,且音频信号分析器110可组合这些局部特征图fm01及fm02成为输入特征图fm0,以供输入至分离器120中。
21.另外,分离器120可对输入特征图fm0进行对应于一预定神经网络模型(例如:上述端到端音频分离模型诸如conv-tasnet模型)尤其对应于其内的分离模块的分离处理,以取得分别对应于一第一类型诸如类型a及一第二类型诸如类型b的输出特征图fm1及fm2。举例来说,分离器120可利用对应于所述预定神经网络模型的tcn模块120t对输入特征图fm0进行所述分离处理(例如所述tcn分离)以产生分别对应于所述第一类型(例如类型a)及所述第二类型(例如类型b)的遮罩#1及#2,以及利用乘法器120ma对输入特征图fm0及对应于所述第一类型的遮罩#1进行乘法计算以产生输出特征图fm1,且利用乘法器120mb对输入特征图fm0及对应于所述第二类型的遮罩#2进行乘法计算以产生输出特征图fm2。
22.此外,去卷积层电路131及132可分别对输出特征图fm1的不同部分进行去卷积处理以产生对应的处理结果,以产生对应于所述第一类型诸如类型a的一第一音频输出信号,诸如音频输出信号vocal(t)。举例来说,音频信号合成器130可从分离器120接收输出特征图fm1,且利用存储电路130s的一组存储区暂时地存储输出特征图fm1的上述不同部分,尤其,进行下列操作:
23.(1)利用去卷积层电路131对输出特征图fm1的一局部特征图fm11进行对应于所述
第一长度(例如长度m)的去卷积处理,以产生对应于局部特征图fm11的一组第一中间样本;
24.(2)利用去卷积层电路132对输出特征图fm1的一局部特征图fm12(于图中绘示为位于另一局部特征图fm2的图层下方,仅以标号标记)进行对应于所述第二长度的(例如长度n)去卷积处理,以产生对应于局部特征图fm12的一组第二中间样本;以及
25.(3)利用加法器130aa分别对对应于局部特征图fm11的所述组第一中间样本以及对应于局部特征图fm12的所述组第二中间样本进行加法计算,以产生一组加法计算结果作为所述第一音频输出信号(诸如音频输出信号vocal(t))的多个样本,其中所述第一音频输出信号诸如音频输出信号vocal(t)可载有这多个样本。
26.相仿地,去卷积层电路131及132可分别对输出特征图fm2的不同部分进行去卷积处理以产生对应的处理结果,以产生对应于所述第二类型诸如类型b的一第二音频输出信号,诸如音频输出信号music(t)。举例来说,音频信号合成器130可从分离器120接收输出特征图fm2,且利用存储电路130s的另一组存储区暂时地存储输出特征图fm2的上述不同部分,尤其,进行下列操作:
27.(1)利用去卷积层电路131对输出特征图fm2的一局部特征图fm21进行对应于所述第一长度(例如长度m)的去卷积处理,以产生对应于局部特征图fm21的一组第一中间样本;
28.(2)利用去卷积层电路132对输出特征图fm2的一局部特征图fm22进行对应于所述第二长度(例如长度n)的去卷积处理,以产生对应于局部特征图fm22的一组第二中间样本;以及
29.(3)利用加法器130ab分别对对应于局部特征图fm21的所述组第一中间样本以及对应于局部特征图fm22的所述组第二中间样本进行加法计算,以产生一组加法计算结果作为所述第二音频输出信号(诸如音频输出信号music(t))的多个样本,其中所述第二音频输出信号诸如音频输出信号music(t)可载有这多个样本。
30.为了便于理解,于图1中绘示了非分离路径、类型a分离路径(例如对应于类型a的分离路径)及类型b分离路径(例如对应于类型b的分离路径),以分别指出相关数据的数据路径及其上的数据流,但本发明不限于此。另外,上述信号(例如音频混合信号mixture(t)、音频输出信号vocal(t)及music(t))的各自的符号中的“(t)”可指出这些信号分别是时间的函数。在一些实施例中,所述类型a及所述类型b可根据音频的特定频率(例如,成年男性的人声基本频率大致为85~180hz,成年女性的人声基本频率则大致为165~255hz)来区分,所述类型a大致对应于音频混合信号mixture(t)当中的人声成分(故标示为音频输出信号vocal(t)),而所述类型b大致对应于音频混合信号mixture(t)当中的音乐(或称背景)成分(故标示为音频输出信号music(t))。
31.依据某些实施例,卷积层电路111可包括分别具有所述第一长度(例如长度m)的一组1d卷积层,作为卷积层电路111中的所述多层1d卷积内核。卷积层电路112可包括分别具有所述第二长度(例如长度n)的一组1d卷积层,作为卷积层电路112中的所述多层1d卷积内核。另外,去卷积层电路131可包括分别具有所述第一长度(例如长度m)的一组1d去卷积层,作为去卷积层电路131中的所述多层1d卷积内核。去卷积层电路132可包括分别具有所述第二长度(例如长度n)的一组1d去卷积层,作为去卷积层电路132中的所述多层1d卷积内核。
32.图2是依据本发明一实施例绘示的一种音频处理方法的一基于多长度卷积/去卷积层的控制方案的示意图。所述方法是可应用于图1所示的音频处理装置100,尤其,具备音
频处理功能的所述电子装置(例如电视、影音系统等)。举例来说,所述第一长度可代表长度m,而所述第二长度可代表长度n。为了便于理解,于图2中绘示了具有长度m的1d卷积/去卷积层(例如卷积层电路111中的所述组1d卷积层及去卷积层电路131中的所述组1d去卷积层)、具有长度n的1d卷积/去卷积层(例如卷积层电路112中的所述组1d卷积层及去卷积层电路132中的所述组1d去卷积层)、对应于具有长度m的1d卷积层(例如卷积层电路111中的所述组1d卷积层)的特征图(例如局部特征图fm01、fm11及fm21)以及对应于具有长度n的1d卷积层(例如卷积层电路112中的所述组1d卷积层)的特征图(例如局部特征图fm02、fm12及fm22),但本发明不限于此。为了简明起见,于本实施例中类似的内容在此不重复赘述。
33.图3绘示所述音频处理方法所涉及的1d卷积/去卷积层的例子,图4绘示所述音频处理方法所涉及的特征图的例子,且图5绘示所述音频处理方法所涉及的遮罩的例子,其中参数诸如m、n、h、k等可指出相关的1d卷积/去卷积层、特征图/局部特征图以及遮罩的大小。举例来说,m、n、h及k中的任意一个可为大于一的正整数,而在一些实施例中,h》m》n且h可远大于m及n,但本发明不限于此。如图3所示,卷积层电路111中的任一卷积层的长度以及去卷积层电路131中的任一去卷积层的长度都等于长度m,卷积层电路112中的任一卷积层的长度以及去卷积层电路132中的任一去卷积层的长度都等于长度n,且卷积层电路111及112中的每一卷积层电路的层数以及去卷积层电路131及132中的每一去卷积层电路的层数都等于k。如图4所示,特征图fm0、fm1及fm2中的每一特征图的宽度及高度分别等于h及2k(例如,(k k)=2k),且特征图fm0、fm1及fm2的各自的局部特征图{fm01,fm02}、{fm11,fm12}及{fm21,fm22}中的每一局部特征图的宽度及高度分别等于h及k。如图5所示,遮罩#1及#2中的每一遮罩的宽度及高度分别等于h及2k。为了简明起见,于本实施例中类似的内容在此不重复赘述。
34.承前所述,若所述类型a对应于音频混合信号mixture(t)当中的人声成分而所述类型b对应于音频混合信号mixture(t)当中的音乐成分,表示本发明的音频处理方法可分别对音频混合信号mixture(t)当中不同频率的成分(前述实施例中的人声成分与音乐成分)采用不同的卷积内核长度来处理,以希望获得优于现有技术以相同内核长度来处理的效果。
35.依据某些实施例,h=1001,m=480(对应于类型a分离路径当中的卷积层/去卷积层的卷积内核长度),n=32(对应于类型b分离路径当中的卷积层/去卷积层的卷积内核长度),且k=256,但本发明不限于此。为了简明起见,于这些实施例中类似的内容在此不重复赘述。
36.表1
[0037][0038]
表2
[0039][0040]
表3
[0041][0042]
表1展示依据本发明多个实施例中通过音频处理装置100来处理公开于因特网的dsd100音频数据组所得的实验结果,表2展示依据本发明多个实施例中通过音频处理装置100来处理上述dsd100音频数据组所得的实验结果,而表3展示依据现有技术来处理上述dsd100音频数据组所得的实验结果,其中表1及表2中的每一表的任一组实验结果对应于多个内核长度(标示为“(长,短)”以求简明),而表3的任一组实验结果对应于一个内核长度。
[0043]
表4
[0044][0045]
表5
[0046]
[0047]
表6
[0048][0049]
表4展示依据本发明多个实施例中通过音频处理装置100来处理公开于因特网的musdb18音频数据组所得的实验结果,表5展示依据本发明多个实施例中通过音频处理装置100来处理上述musdb18音频数据组所得的实验结果,而表6展示依据现有技术来处理上述musdb18音频数据组所得的实验结果,其中表4及表5中的每一表的任一组实验结果对应于多个内核长度(标示为“(长,短)”以求简明),而表6的任一组实验结果对应于一个内核长度。
[0050]
表1~6中的字段“步长”(stride)指神经网络模型训练中进行卷积运算时卷积层内核所移动的步数,其意义为本领域普通技术人员所熟知,故不赘述。另外,表1~6中的后续字段包括人声及音乐的各自的源失真比(source to distortion ratio,sdr)及源失真比改善(source to distortion ratio improvement,sdri)平均(mean),以下分别简称sdr及sdri。
[0051]
表1~6指出依据本发明一些实施例来处理所得的实验结果与依据现有技术来处理所得的实验结果之间的差异。表1~2及表4~5分别显示了在一些实施例中根据本发明的音频处理装置100以不同卷积层/去卷积层的卷积内核长度处理特定音频数据组(例如,表1~2所处理的音频数据组是公开于因特网的dsd100音频数据组,表4~5所处理的音频数据组是公开于因特网的musdb18音频资料组)所得到的实验结果。表3及表6则分别显示了根据现有技术(传统的conv-tasnet)以相同卷积层/去卷积层的卷积内核长度处理上述特定音频数据组(例如,表3所处理的音频数据组是上述dsd100音频数据组,表6所处理的音频数据组是上述musdb18音频资料组)所得到的实验结果。
[0052]
于实验结果所示的多种组合中,又以前述的m=480且n=32的状况为优选。在此状况下,可以得到最大的sdr数值以及sdri数值。
[0053]
如实验结果所示,sdr数值越大表示分离出的信号与目标信号越相近且较不受其他声源信号的干扰。sdri则是一种增强的sdr,其计算方式可包括:
[0054]
(1)以未分离的信号(例如前述的音频混合信号mixture(t))与目标信号来进行sdr计算以取得第一sdr;
[0055]
(2)以分离后的信号与目标信号来进行sdr计算以取得第二sdr;以及
[0056]
(3)依据第一sdr及第二sdr进行减法计算以产生一sdr差值,诸如将第二sdr减去第一sdr所获得的数值,以作为sdri;
[0057]
其中sdri可用以表示分离后信号相较于未分离信号的优化程度。
[0058]
而无论在表1~3或表4~6中,根据本发明的音频处理装置100以不同卷积层/去卷积层的卷积内核长度进行音频处理时所获得的实验结果均优于根据现有技术以相同卷积
层/去卷积层的卷积内核长度进行音频处理时所获得的实验结果。然而应当理解,不同数据组的特性差异可能影响所选择的卷积内核长度,本发明的应用不以获得实验结果所使用的数据组及卷积内核长度为限制。一般而言,当未分离信号中含有较复杂的乐器成分时,采用本发明的装置/方法来处理会达到更佳的效果。
[0059]
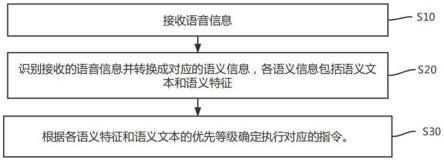
图6依据本发明一实施例绘示所述音频处理方法的流程图。
[0060]
于步骤s10中,音频处理装置100可利用卷积层电路111及112分别对音频混合信号mixture(t)进行卷积处理,以产生输入特征图fm0。
[0061]
于步骤s20中,音频处理装置100可利用分离器120对输入特征图fm0进行对应于所述预定神经网络模型的分离处理,以取得分别对应于所述第一类型诸如类型a及所述第二类型诸如类型b的输出特征图fm1及fm2。
[0062]
于步骤s30中,音频处理装置100可利用去卷积层电路131及132分别对输出特征图fm1的不同部分进行去卷积处理以产生对应的处理结果,以产生对应于所述第一类型诸如类型a的所述第一音频输出信号,诸如音频输出信号vocal(t),且利用去卷积层电路131及132分别对输出特征图fm2的不同部分进行去卷积处理以产生对应的处理结果,以产生对应于所述第二类型诸如类型b的所述第二音频输出信号,诸如音频输出信号music(t)。
[0063]
为了简明起见,于本实施例中类似的内容在此不重复赘述。
[0064]
为了更好地理解,所述音频处理方法可用图6所示的工作流程来说明,但本发明不限于此。依据某些实施例,一个或多个步骤可于图6所示的工作流程中增加、删除或修改。
[0065]
依据某些实施例,所述音频处理方法可还包括执行一训练程序,其中所述训练程序包括:依据预定输入音频信号、对应于类型a的预定音频输出信号及对应于类型b的预定音频输出信号,对这个模型进行训练以训练(例如调整)这个模型的参数,以通过多次进行所述训练,使这个模型的参数达到这些参数的各自的最终值来完成训练,以供进行上述音频信号处理。
[0066]
图7依据本发明一实施例绘示所述音频处理方法所涉及的一种非暂态计算机可读取媒体100m,其中非暂态计算机可读取媒体100m存储有计算机可读取指令码100p(computer-readable instruction code)使得音频处理装置100(例如,所述电子装置的所述控制电路,诸如本实施例的控制电路100c,尤其,其内的处理器101)于执行上述计算机可读取指令码100p时进行一音频处理程序诸如上述音频处理(例如,上述实施例中所述的各种操作)。处理器101可代表控制电路100c中的至少一处理器(例如一或多个处理器)。为了便于理解,运行着上述计算机可读取指令码100p的处理器101(例如,处理器101的多个局部电路,诸如单处理器的多个子电路、单处理器的多个处理器核心、多个处理器/处理器核心等)可被配置为图1所示架构(例如音频信号分析器110、分离器120及音频信号合成器130,于图7中仅以标号标记)。非暂态计算机可读取媒体100m可代表某一存储装置/组件,其可通过硬式磁盘驱动器、固态硬盘、通用闪存存储(universal flash storage,ufs)装置、非挥发性存储器组件(例如电子可抹除可编程只读存储器(electrically-erasable programmable read-only memory,eeprom)及快闪(flash)存储器)等方式来实施,但本发明不限于此。为了简明起见,于本实施例中类似的内容在此不重复赘述。
[0067]
依据某些实施例,前述音频信号分析器110、分离器120及音频信号合成器130可通过运行着软件的一处理电路(例如处理器101)等方式来实施,而运行着软件的所述处理电
路所产生的中介数据(intermediate data)可以通过利用所述电子装置的存储器来存储/暂存。例如,在所述电子装置(例如电视)的所述控制电路被实施为ic(例如电视ic)的情况下,这个存储器可位于此ic上。
[0068]
本发明的多频率分辨率架构(multi-frequency-resolution architecture,简称mf架构),诸如图1、图2等所示实施例的架构,可将分别具有不同长度的两类型的1d卷积内核一起应用于一神经网络模型,以同时提供不同频率分辨率(承前所述,人声成分及音乐成分,举例来说)的内容,尤其,使对应的mf模型(例如,具备所述mf架构的所述神经网络模型)中的卷积内核能够充当具有不同频率分辨率的带通滤波器以及学习用不同分辨率内核来分析不同频率的信号,其中这种现象与人耳蜗(human cochlear)的功能是一致的。因此,本发明的音频处理方法及音频处理装置可大幅地改善音频分离处理的声音输出的质量。
[0069]
以上所述仅为本发明的较佳实施例,凡依本发明申请权利要求所作的等同变化与修改,均应属本发明的保护范围。
[0070]
附图标记说明
[0071]
100:音频处理装置
[0072]
110:音频信号分析器
[0073]
110c:卷积层模块
[0074]
110s:存储电路
[0075]
111,112:卷积层电路
[0076]
120:分离器
[0077]
120t:tcn分离模块
[0078]
120k:遮罩模块
[0079]
120ma,120mb:乘法器
[0080]
130:音频信号合成器
[0081]
130d:去卷积层模块
[0082]
130s:存储电路
[0083]
131,132:去卷积层电路
[0084]
130aa,130ab:加法器
[0085]
fm0,fm1,fm2:特征图
[0086]
fm01,fm02,fm11,fm12,fm21,fm22:局部特征图
[0087]
mixture(t):音频混合信号
[0088]
vocal(t),music(t):音频输出信号
[0089]
120m:乘法电路
[0090]
130a:加法电路
[0091]
m,n,h,k:参数
[0092]
s10~s30:步骤
[0093]
100m:非暂态计算机可读取媒体
[0094]
100p:计算机可读取指令码
[0095]
100c:控制电路
[0096]
101:处理器
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。