1.下文总体上涉及图像处理技术、医学图像诊断分析技术、患者匿名化技术、人工智能(ai)技术和相关技术。
背景技术:
2.在医学图像的分析中,正在越来越多地使用ai。例如,人工智能分类器能够用于检测病变、对图像进行分类以确定其是否描绘了某种医学状况、等等。通常,使用一组训练图像对ai组件进行训练,这些图像经常是由临床专家标记为“正确的”分类(指导训练)。例如,利用临床医生标记肿瘤,有和没有肿瘤的临床图像可以用作训练集合。然后对ai组件进行训练,以最大化区分有肿瘤和无肿瘤图像的准确性。
3.然而,出现了一个问题,即,训练图像可能被认为是私人身份的患者数据。即使与图像关联的元数据是匿名的,图像本身也能够潜在地被识别为被特定的个人,而且可以包含有关个人的医学状况的信息。经过训练的ai组件能够潜在地嵌入训练图像。因此,适用的患者隐私法规可能禁止分发在临床患者图像上训练的ai组件。这能够通过获得患者同意在培训中使用图像来克服,但很难以这种方式建立足够大和多样化的培训组,并维护所有相关联患者同意文件的可审计记录。另一种方法是合成训练图像,例如使用解剖模型和产生合成训练图像的成像物理模型,但合成图像可能与真实临床图像不同,其对于人类查看者来说可能并不明显,但可能会将系统误差引入到所产生的经过训练的ai组件中。
4.下文公开了为了克服这些问题和其他问题的一些改进。
技术实现要素:
5.在一个方面,一种用于生成匿名图像的训练集以训练来自多个人的图像的ai组件的装置。所述装置包括至少一个电子处理器,所述电子处理器被编程为:将多个人的图像空间映射到参考图像,以生成公共参考系中的图像;将公共参考系中的图像划分为p个空间区域,以生成对应于p个空间区域的p个图像块集合;通过针对公共参考系中的每幅训练图像,从p个图像块集合中的每个中选择图像块,并将所选择的图像块组合到公共参考系中的训练图像来组合公共参考系中的训练图像的集合;并且,处理公共参考系中的训练图像以生成匿名图像的训练集合,包括将统计逆空间映射应用于公共参考系中的训练图像,其中,统计逆空间映射是从多个人的图像到参考图像的空间映射(33)导出的。
6.在另一方面,一种非瞬态计算机可读介质存储指令,所述指令可由至少一个电子处理器执行,以执行生成用于根据多个人的图像训练ai组件的匿名图像的训练集合的方法。所述方法包括:将图像划分为p个空间区域,以生成对应于p个空间区域的p个图像块集合;针对每个公共参考系中的训练图像,通过从p个图像块集合中的每个中选择图像块并将所选择的图像块组合到训练图像来组合公共参考系中的训练图像的集合;并且,处理公共参考系中的训练图像,以生成匿名图像的训练集合。
7.在另一方面,一种生成用于根据多个人的图像来训练ai组件的匿名图像的训练集
合的方法。所述方法包括:将图像划分为p个空间区域,以生成与对应于p个空间区域的p个图像块集合;针对公共参考系中的每幅训练图像,通过从p个图像块集合中的每个中选择图像块并将所选择的图像块组合到公共训练图像来组合公共参考系中的训练图像的集合;处理公共参考系中的训练图像,以生成匿名图像的训练集合;并且,在匿名图像的训练集合上训练医学诊断设备的ai组件。
8.一个优点在于仅使用几个患者图像的一部分根据患者图像生成训练图像数据集。
9.另一个优点在于根据患者图像生成训练图像数据集,而无需从图像中提取患者特定信息。
10.另一个优点在于以不可逆的方式匿名化患者图像的图像内容。
11.另一个优点在于在使用图像训练ai组件之前对患者图像的图像内容进行匿名化。
12.另一个优点在于生成在其中每幅训练图像包括来自不同患者的多个患者图像的部分的训练图像数据集。
13.所给出的实施例可以不提供、提供一个、两个、多个或所有上述优点,和/或可以提供对于本领域普通技术人员在阅读和理解本公开后将变得显而易见的其他优点。
附图说明
14.本公开可以以各种组件和组件布置的形式,以及以各种步骤和步骤布置的形式呈现。附图仅用于说明优选实施例的目的而不应被解释为限制本公开。
15.图1示意性示出了根据本公开的生成用于根据多个人的图像来训练ai组件的匿名图像的训练集合的说明性装置。
16.图2-7示出了由图1的装置生成的图像的范例。
具体实施方式
17.下文提出了匿名化真实临床图像(而不仅仅是相关联的元数据)的系统和方法。为此,公开了以下过程。首先,将一组真实的临床图像{r}
r=1,
…
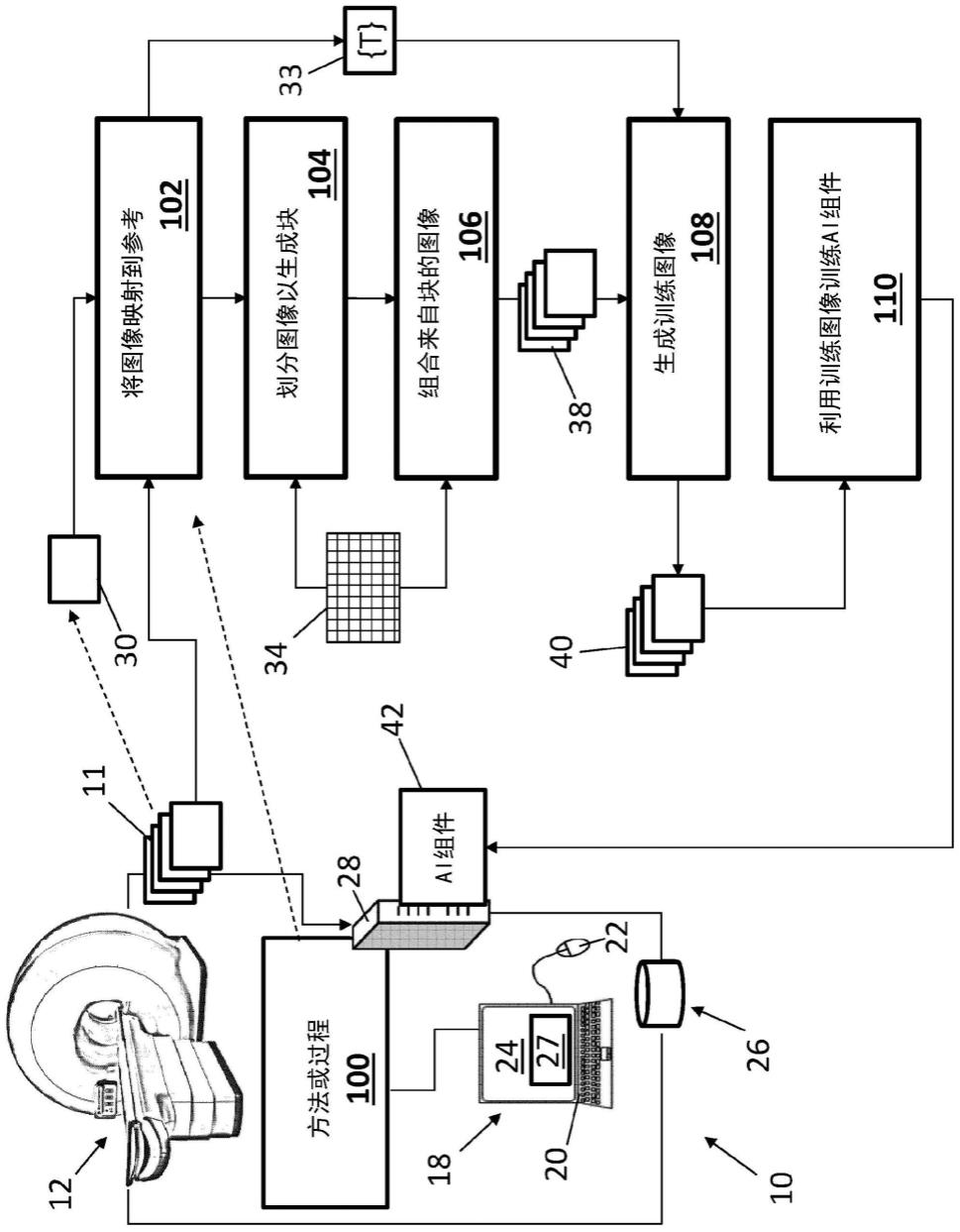
,r
空间映射到参考图像。参考图像可以是临床图谱图像,或者也可以是“典型”临床图像(可选地取自集合{r})。例如,空间映射通常将是非刚性空间配准,并且将产生针对每个图像r∈{r}的空间变换zr。结果是一组空间变换{zr}
r=1,...,r
(或者如果将一个图像作为参考图像,结果是{zr}
r=1,...,r-1
)。
18.接下来,将空间映射的图像划分为一组空间区域{p}
p=1,
…
,p
。可以使用直线网格来定义空间区域集合{p},或者可以沿着解剖线定义空间区域。这提供了对应于空间区域集合{p}的每个空间区域p的r个块。
19.然后,构建一组训练图像{n}
n=1,
…
,n
。每幅训练图像n∈{n}是通过随机选择与每个空间区域p对应的r个块中的一个,然后将所选择的块组合成训练图像n来构建的。产生的n个块形成的图像在参考图像空间中,这是不合需要的,因为它没有捕捉到被成像的解剖结构的大小和形状的真实分布。为了解决这个问题,将随机选择的逆变换应用于每个块形成的图像。在一种方法中,随机选择的逆变换是从空间变换集合{zr}中随机选择的。在另一种方法中,确定集合{zr}的空间变换的参数的统计分布,并且使用这些分布生成逆变换。
20.这种方法可能出现的问题是,在训练图像中,块的边界可能是不连续的。例如,肢体骨骼可以在两个相邻空间区域之间的边界处表现出人为的“断裂”。这是否是一个问题能
够取决于正在被训练的ai组件的性质。(显然,如果ai被训练为检测肢体骨折,这将是一个问题;但是,如果ai被训练为检测小损伤,则这个块的边界被ai误认为是损伤的可能性可以是很低的)。
21.公开了解决该问题的两种方法。第一实施例包括在边界处执行平滑的过程。这可能在应用逆变换之前最容易完成,因为在逆变换之前,对于每个分成块(patched)的图像,边界位置都是相同的。在第二实施例中,空间区域集合{p}被设计为避免使空间区域边界切断式跨越(cut across)主要解剖边界。例如,参考图像的肝脏可以被划分为空间区域的子集,这些空间区域都完全在肝脏内;每个肺部可以被划分为空间区域的子集,这些空间区域都完全在肺部内;等等。该实施例允许避免空间区域边界跨越解剖边界,并且是可行的,因为空间区域集合{p}仅被描绘一次,然后相同的空间区域集合{p}被应用于{r}临床图像中的每个图像来生成块。
22.在本文公开的一些实施例中,在分成块的训练集合{n}上训练的ai组件的性能能够通过将其性能与在临床图像的原始集合{r}上训练的类似ai组件的性能进行比较来容易地分级。后者的类似ai组件(其可能包含个人识别图像信息)在其用作基准后将被丢弃,并且在分成块的训练集合{n}上训练的ai组件将分发给客户。
23.所公开的系统和方法可以是不限于训练ai组件以分析医学图像,而且更普遍地应用于任何ai图像分析组件的训练,所述ai图像组件将在全部都具有相同的基础布局的一组训练图像上进行训练(例如,用于训练面部识别ai的面部图像、或用于训练ai以对被拍摄人的属性进行分类的人的图像、或用于训练视网膜扫描器以执行用户识别的视网膜扫描图像,都是所公开的方法可以有用的情况的其他范例)。此外,方法适用于二维或三维(即,体积)图像。在体积图像的情况下,空间区域集合{p}将定义在体积上,并且图像块将是体积图像块。
24.参考图1,示出了说明性装置10,其用于生成匿名训练图像40的训练集合,以根据多个人的图像11训练ai组件42。例如,装置10能够从图像获取设备(也称为成像设备)12接收多个人的图像11。成像设备12能够采集图像11作为解剖结构的医学图像。在该范例中,图像采集设备12能够是磁共振(mr)图像采集设备、计算机断层摄影(ct)图像采集设备;正电子发射断层摄影(pet)图像采集设备;单光子发射计算机断层摄影(spect)图像采集设备;x射线图像采集设备;超声(us)图像采集设备;或其他模态的医学成像设备。额外地或备选地,成像设备12能够是适合于要训练的具体ai组件42的(例如,视频、rbg、红外等)相机(在这种情况下,图像11是肖像图像)、或者视网膜扫描器(在这种情况下,图像是视网膜图像)、等等。应当理解,说明性成像设备12是代表性的,并且更普遍地,图像集合11可以通过多个不同的成像设备来采集。例如,图像11可以从诸如图片存档和通信系统(pacs)的数据库或可以为医院、医院网络或其他实体服务的其他医学图像储存库28收集。图像集合11的图像都具有相同的基本布局。例如,在临床图像的情况下,图11都是相同的成像模式和相同的解剖部分(例如,全部都是头部mri图像、全部都是肝脏mri图像、全部都是胸部ct图像、等等),并且全部都是相同的或相似的取向(例如,全部都是矢状头部mri图像,或全部都是冠状头部mri图像、等等),并且使用相同或相似的成像条件(例如,全部使用相同的造影、或全部都不使用造影剂)或跨越要使用ai组件的成像条件的操作空间的成像条件。作为另一范例,为了在训练视网膜扫描器中进行使用,图像11可以全是视网膜图像。作为另一范例,为了在训
练面部识别系统中进行使用,图像11可以全是肖像面部图像。此外,图像11应该在统计学上表示人口统计范围和医学状况或将由要训练的ai组件42处理的状况。如果存在可能由ai引起的误诊(或其他错误输出)的已知混淆医学状况,则图像11集合可以包括此类混淆状况的范例。例如,如果图像11是乳房x光图像,并且预期乳房x光图像中的皮肤褶皱可能不利地影响ai组件42的操作,则图像11集合(这里是乳房x光照片)可以任选地包括具有皮肤褶皱的一些乳房x光照片图像,以提高最终训练的ai组件的稳定性。
25.图1还示出了电子处理设备18,例如工作站计算机,或更通用的计算机。备选地,电子处理设备18能够体现为服务器计算机或例如互连形成服务器集群、云计算资源等的多个服务器计算机。工作站18包括典型组件,例如电子处理器20(例如微处理器)、至少一个用户输入设备(例如鼠标、键盘、轨迹球等)22和显示设备24(例如lcd显示器、等离子显示器、阴极射线管显示器、等等)。在一些实施例中,显示设备24能够是与工作站18分开的组件。
26.电子处理器20与一个或多个非临时性存储介质26可操作地连接。非临时性存储介质26通过非限制性范例的方式可以包括以下中的一个或多个:磁盘、raid或其他磁存储介质;固态驱动器、闪存驱动器、电子可擦除只读存储器(eerom)或其他电子存储器;光盘或其他光学存储器;其各种组合;等等;并且可以是例如网络存储器、工作站18的内部硬盘驱动器、它们的各种组合、等等。应当理解,本文中对非瞬态介质或介质26的任何引用应当广义地解释为涵盖单个介质或者相同或不同类型的多个介质。同样,电子处理器20可以体现为单个电子处理器或者两个或多个电子处理器。非瞬态存储介质26存储可由至少一个电子处理器20执行的指令。指令包括生成用于在显示设备24上显示的图形用户界面(gui)27的指令。
27.装置10还包括存储图像11的数据库28,或者以其他方式与存储图像11的数据库28可操作地通信。数据库28能够是任何合适的数据库,包括放射学信息系统(ris)数据库、图片存档和通信系统(pacs)数据库、电子病历(emr)数据库、等等。例如,数据库28能够由服务器计算机和非瞬态介质26来实施。工作站18能够用于访问所存储的图像11。还应当理解,图像11能够如前所述,由多个成像设备采集,而不必仅由代表性的一个图示的图像采集设备12采集。
28.装置10如上所述被配置为执行用于生成匿名图像的训练集合的方法或过程100。非瞬态存储介质26存储指令,所述指令可由至少一个电子处理器20读取和执行,以执行所公开的操作,包括执行用于生成匿名图像的训练集合的方法或过程100。在一些范例中,方法100可以至少部分通过云处理来执行。
29.如图1所示,并且参考图2-7,成像检查工作流程可视化方法100的说明性实施例被示意性示出为流程图。图2-7示出了方法100的操作的输出的范例。图2-7中所示的图像是胸部的二维x射线图像,但是应当理解,方法100能够应用于任何合适的患者的成像模式或解剖区域。不失一般性地,假设图像11形成集合{r},即,图像11的集合存在有r个图像。尽管图1中未示出,但假设与图像11相关联的元数据被剥离,或者至少包含在与图像11相关联的元数据中的任何个人识别信息(pii)被剥离。同样,不失一般性地,假设所生成的匿名训练图像40的集合形成集合{n},即,存在n个匿名训练图像。总体上,r和n之间没有关系,只是图像11的数量r与匿名训练图像40的数量n相比应该足够大,以便通过将r个图像11划分为空间区域p形成的块在匿名化训练图像40中“很好地混合”。(为了说明这一点,如果例如要生成
仅r=5个图像11和n=100幅训练图像40,则至少一些训练图像将可能包括大部分从五个输入图像11中的一个中提取的块,这是不合需要的。另一方面,如果r=1000且n=20,则很可能没有匿名训练图像包含超过来自1000个源图像11中的任何一个的一个或两个块。
30.在操作102处,至少一个电子处理器20被编程为将多个人的图像11空间映射到参考图像30,以在公共参考系中生成图像32。当图像11是医学图像时,参考图像30能够是解剖结构的解剖图谱图像。当图像11为肖像图像时,参考图像30能够是面部图谱图像。备选地,在任何一个这些范例中,参考图像30能够是多个人的图像11之一(在图1中示意性地指示了该选项)。在后一种情况下,参考图像30可以手动从图像11的集合中选择——例如,优选地选择“典型”图像作为参考图像。(典型地,在这种情况下,适当地是平均大小的解剖结构的图像,并且优选地没有任何明显的异常)。
31.图2示出了操作102的范例。四个图像11由成像设备12采集和/或从数据库28中检索。所示的四个图像11中的每个都来自不同的患者(在图2的“顶部”示出)。图像11被映射到参考图像30(在这种情况下,是图谱图像,并且在图2的“中间”示出)。能够使用本领域已知的任何合适的映射算法来执行映射(例如在a.franz等人的“precise anatomy localization in ct data by an improved probabilistic tissue type atlas”(spie medical imaging:image processing,2016年第9784卷,978444)中描述的一种算法)。这种franz方法提供了一种非线性映射函数,所述函数允许将所有图像11映射到公共图谱参考30。在映射之后,公共参考系中的所有图像32是可比较的,例如,一个图像中的位置/像素与所有其他图像中的相应解剖位置相关。这些图像32示出在图2的“底部”。
32.映射操作102还输出一组映射或变换33。在一种方法中,图像11的集合中的每个图像到参考图像30的映射是映射33的集合的一种映射。这产生r个映射33(或者,如果参考图像30是r个图像11之一,则可能是r-1个映射)。在另一种方法中,映射33的集合被输出为多维统计分布。例如,如果映射操作102采用参数化映射算法,则相应的r个图像11到参考图像30的r个映射中的每个参数的分布由(例如)gaussian拟合到参数分布的均值和标准偏差来表示。
33.在操作104处,至少一个电子处理器20被编程为将公共参考系中的图像32划分成多个(不失一般性地指定为p个)空间区域34,以生成对应于p个空间区域的图像块36的p个集合。在一些实施例中,p个空间区域34形成直线网格,而在其他实施例中,p个空间区域34与参考图像30中的感兴趣区域对齐,例如参考图像30中器官之间的解剖边界。在这个实施例中例如,当图像11是医学图像时,p个空间区域34的边界不跨越参考图像30中的解剖结构的解剖边界。空间区域34的集合{p}是预先定义的,或者自动(例如使用计算机生成的直线网格)或者手动绘制的,例如,使用轮廓绘制gui 27在参考图像30上进行绘制,如在针对放射治疗规划对器官进行轮廓绘制中所使用的gui 27。还设想了一种混合方法,其中,使用轮廓绘制gui 27手动绘制主要器官的边界,以定义与器官或其他解剖结构对齐的粗略的空间区域,然后,将每个粗略的空间区域本身自动划分为计算机生成的直线网格,从而定义p个空间区域34的最终集合。
34.适当地选择空间区域34的集合以确保得到的匿名训练图像40的匿名性。为此,空间区域34应当选择得足够小,以使没有单个块36是个人化识别的。此外,空间区域(p)的数量应当足够大,以使构成给定训练图像的大多数或所有随机选择的块将来自图像11的集合
中的单个图像的可能性在统计学上可以忽略不计。此外,图像11的数量r比空间区域p的数量大(并且优选地大得多)是有用的,这再次降低了构成给定训练图像的大多数或所有随机选择的块将来自图像11的集合中的单个图像的可能性。
35.图3a、图3b和图4示出了操作104的两个范例。如图3a和图3b所示,公共参考系中的图像32被划分为多个空间区域34。图3a示出了在其中空间区域34形成直线网格的实施例的范例(例如,4个空间区域被示出,并且具有相同的大小),同时,图3b示出了在其中空间区域34与参考图像30中的感兴趣区域对齐的实施例的范例(例如,仅示出3个空间区域)。应当注意,如本文所使用的,“空间区域”指代用于将图像11分割为块的空间描绘。本文使用的术语“块”则指给定的已分割图像11对应于给定的空间区域的部分。由于存在r个图像11,则划分操作104将产生对应于p个空间区域34的集合的每个空间区域的r个块。将有对应于p个空间区域的块的p个集合,块的每个集合包括r个块。如图4所示,空间区域34被应用于公共参考系中的图像32以生成块36。每个块36能够被识别为包括(图像标识符、块编号)的元组。图像标识符优选地不是个人化识别的。相反,例如,r个图像能够简单地编号为1,
…
,r,并且分配给图像的编号则是图像标识符。对应于给定空间区域34的每个块36在公共参考系中的图像32之间在解剖学上是可比较的。
36.在操作106处,至少一个电子处理器20被编程为在公共参考系中组合训练图像38的集合(也参见图5)。为此,从针对公共参考系中的每幅训练图像38的图像块的p个集合中的每个中选择图像块36。根据空间区域34的集合的空间布局,在公共参考系中将所选图像块36组合为训练图像30。在一些范例中,从p个图像块集合中的每个中选择图像块36包括随机或伪随机地选择图像块。如本文所使用的,术语“伪随机”和类似的命名法在计算机科学领域具有其通常和普通的含义,并且指的是在技术上是确定性的但产生的结果在统计上与随机过程相似且产生的结果的过程,并且所述结果对于伪随机过程的多次运行不重复。例如,普通的伪随机值生成器包括数字序列生成器,其产生确定的数字序列,所述数字序列具有与真正的随机数字序列相似的统计数据,并且很长(可能无限长)。对于每次运行,都会选择一个种子来确定序列中的起点。例如,可以基于运行开始时计算机时钟值的一组低位来选择种子,这对于以千兆赫兹或更高速度运行的高速计算机处理器而言本质上是随机数。其他伪随机生成器,例如蒙特卡罗模拟方法,也是适用的。此外,本文所使用的术语“随机”应当理解为包括采用伪随机值生成器的实施方式。
37.图5示出了操作106的范例。对于每个空间区域34,通过例如随机数生成器选择随机图像标识符,并且选择与具有该图像标识符的该空间区域相对应的r个块36的集合中的块。这对于p个空间区域34的集合中的每个空间区域重复进行。因此,所选择的块36总体上是来自图像11的集合的不同图像,并且使用空间区域34(参见图3)进行组合以在公共参考系中生成训练图像38的集合。图4所示的公共参考系中的训练图像38包括来自4个不同患者的块36。在实践中,块的数量p可能远大于4。
38.在上述方法中,存在一些可能性,即,来自图像11的集合中的单个图像的两个(或者甚至多个)块可以包括在公共参考系中的单幅训练图像38中。只要图像11的数量r远大于空间区域的数量p,并且优选地也远大于所产生的训练图像40的数量n,这不太可能成为问题。然而,如果希望确保公共参考系中没有一幅训练图像38具有来自单个图像11的多于一个的块,则能够检查针对每幅训练图像组合的最终的块的集合是否有重复(即,来自单个图
像11的两个或多个块)。如果找到这样的重复,则丢弃公共参考系中的训练图像。这种方法要求r》p成立,优选应当是r>>p。
39.重复操作106,直到组合了公共参考系中所期望的数量n个的训练图像38。公共参考系中的训练图像38是匿名的。然而,它们不表示图像11的集合中的人(或其成像的解剖部分)的大小/形状的统计变化。这是映射操作102的结果,其导致训练图像38全部在参考图像30的公共参考系内。
40.因此,在操作108,至少一个电子处理器20被编程为处理公共参考系中的训练图像38,以生成匿名图像40的训练集合,其代表人(或其被成像的解剖部分)的尺寸/形状在图像11的集合中的统计变化。为此,将统计逆空间映射应用于公共参考系中的训练图像38。根据多个人的图像11到参考图像30的空间映射33导出统计逆空间映射。在一个范例中,图像11到参考图像30的空间映射33被反转,以形成逆空间映射的集合,从中随机或伪随机地选择统计逆空间映射。在另一范例中,计算图像11的空间映射33的参数的统计分布,以形成逆空间映射的集合,并且根据这些统计分布生成统计逆空间映射。任选地,操作108还能够包括平滑操作,其能够在图像块36的边界处执行,以进一步生成匿名图像40的训练集。
41.图6示出了操作108的范例。通过应用逆图谱映射,公共参考系中的训练图像38被重新映射到图像11的原始患者图像空间(参见图2)。在操作102处计算的映射之一被随机选择、反转并应用于公共参考图像30空间中的训练图像38,以生成匿名图像40的训练集合。
42.图6还示出了匿名图像40之一的范例。然而,匿名图像40可以不具有在解剖学上彼此完美匹配的块36的边缘。如图6所示,右上角和右下角的块36引入了在肺的边界处可见的偏移。这种偏移能够通过原始图像11中的图像强度的变化和/或不完美的映射算法来解释。所产生的匿名图像40应当尽可能接近真实的患者扫描。因此,在块36的边界处的图像强度和边缘结构均任选地通过使用平滑或其他合适的图像处理技术来修复。例如,强度值能够通过调整在块边界附近计算的强度平均值来校正,不匹配的边缘能够通过非线性图像变换进行局部偏移。能够重复操作106和108,以生成新的匿名图像40的数据库。然后能够不再从匿名图像40的集合重建原始图像11。
43.上文将操作104-108描述为在解剖图像相关联的背景下执行。然而,这些操作104-108能够在功能图像相关性的背景下执行。即,能够组合来自具有匹配图案的功能数据的图像的块36,以形成训练图像38。为此,对图像11的集合执行图案识别操作,以形成具有跨越块36的相关功能数据的图像的子组合。这种块36的子组合用于形成训练图像38。在训练图像38的创建(即操作108)之前完成的图案识别操作和子组合形成能够在解剖图像中使用,以改善块的相关性,例如通过患者/器官大小、疾病状态、异常的位置或临床影响等。这些数据能够来自图像分析,或者用患者数据(例如来自患者的临床记录)来补充。
44.在一些范例中,pacs数据库28能够从能够定位于一个或多个医疗机构处的多个成像设备12接收图像11。来自这些图像的块36能够与子组合规范一起存储,直到满足子集标准的足够图像数据可用于创建额外的训练图像38。
45.返回参考图1,在操作110处,至少一个电子处理器20被编程为在匿名图像40的训练集合上训练ai组件42。训练过的ai组件42能够部署在工作站18中用作计算机辅助临床诊断工作站的一部分(例如,由放射科医师在解释成像检查时使用的放射学工作站)。解剖图像11能够用于训练医学断设备的ai组件42,而肖像图像11能够用于训练面部识别设备的ai
组件42(例如,ai部署在用于控制对受限区域的访问的面部识别扫描器中)。作为又一范例,如果图像11是视网膜图像,则经过训练的ai组件42可以部署在用于控制对受限区域的访问的视网膜扫描器中。这些只是一些说明性的应用。
46.在一些范例中,操作110能够包括验证ai组件42在匿名图像40的训练集合上的训练。为此,在图像40的训练集合上训练ai组件42,以生成经过训练的人工智能组件。在原始图像11上训练ai组件42的单独实例,以生成参考训练ai组件。在匿名图像40的训练集合上训练的ai组件42的性能,通过将在匿名图像40的训练集合上训练的经过训练的ai组件的性能与参考训练ai组件的性能(即,在原始图像上11训练的)的性能进行比较来验证。
47.总体上,能够增加空间区域p的数量来提供匿名图像40的更高程度的匿名化。如前所述,空间区域34的集合能够具有各种空间几何形状和布局。例如,“类似拼图”形状、图案、分解铺贴(decomposition tiling)能够用于定义空间区域34。具体地,能够以这样的方式在参考图像30中定义空间区域,使得空间区域34的边界不切割通过解剖边缘,或者至少垂直切割通过解剖边缘。图7示出了使用这种铺贴生成的匿名图像的范例。这仍然可能导致空间区域34之间的边界处的误差,但它们被大大减少并且能够更容易地通过平滑或其他图像处理来校正。
48.在一些实施例中,为了进一步匿名化原始图像11,如前所述,能够计算所有映射33的均值和方差。根据这些,能够生成随机逆映射,进一步增加匿名化程度。
49.在其他实施例中,当块36被合并时,能够考虑到图像内容或解剖类型(例如,性别),从而仅将相似的患者块合并在一起。在另一个范例中,能够使用配准算法来合并块36。
50.已经参考优选实施例描述了本公开。在阅读和理解前面的详细描述后,其他人可能会想到修改和变更。旨在将范例性实施例解释为包括所有这些修改和变更,只要它们落入所附权利要求或其等同物的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
