1.本发明涉及词语替换的技术领域,尤其涉及一种基于句子复述模型的英文 词语替换方法。
背景技术:
2.给定一个句子和对应的目标词,词汇替换方法旨在为句子中的目标词找到 合适的替代词;词汇替换方法可以用来解决各种nlp应用的问题,如词汇简 化、词义消岐等。
3.目前基于预训练语言模型bert来进行词汇替换;bert使用transformer 编码器作为语言模型;在语言模型预训练的时候,提出了两个目标任务,即掩 码语言模型mlm和预测下一个句子;mlm在输入的词序列中,随机掩码上 15%的词并预测;相比传统的语言模型,mlm可以从任何方向去预测这些掩码 上的词;为了让模型能够学习到句子之间的关系,bert中的第二个目标任务 就是预测下一个句子;若掩码的是句子中的复杂词,则mlm的思想与候选词 生成的思想是一致的;因此,可利用bert生成候选词。
4.基于bert的方法利用dropout的思想对目标词输入的词向量进行随机部 分掩码;将词向量部分维度的值随机赋为0后,输入到bert中,以获取目标 词对应位置的预测概率;这种情况下,bert仅仅利用了复杂词的模糊信息和 上下文信息,最终产生复杂词的候选替代词集合;由于对目标词进行了部分掩 码,损失了目标词的语义信息而更多关注与上下文信息进行关联的词语,可能 最终会得到语义完全相反的句子;此外,该类方法只能生成由一个标记组成的 词语,而不能生成两个或多个标记组成的词语作为候选替代词。
技术实现要素:
5.本部分的目的在于概述本发明的实施例的一些方面以及简要介绍一些较 佳实施例。在本部分以及本技术的说明书摘要和发明名称中可能会做些简化或 省略以避免使本部分、说明书摘要和发明名称的目的模糊,而这种简化或省略 不能用于限制本发明的范围。
6.鉴于上述现有存在的问题,提出了本发明。
7.为解决上述技术问题,本发明提供如下技术方案,包括:利用公开的复述 语料,训练复述生成模型;利用所述复述生成模型,结合聚焦目标词的解码方 法,生成复述句子;从所述复述句子中,提取候选替代词;利用bertscore 过滤所述候选替代词,以获取最终替代词。
8.作为本发明所述的一种基于句子复述模型的英文词语替换方法的一种优 选方案,其中,所述复述生成模型是基于transformer的端到端的模型。
9.作为本发明所述的一种基于句子复述模型的英文词语替换方法的一种优 选方案,其中,所述基于transformer的端到端的模型的编码器和解码器分别 都是8层,向量维数为1024,每一层采用的是16个头注意力机制,采用adam 优化,采用的子词分割方法subword-nmt。
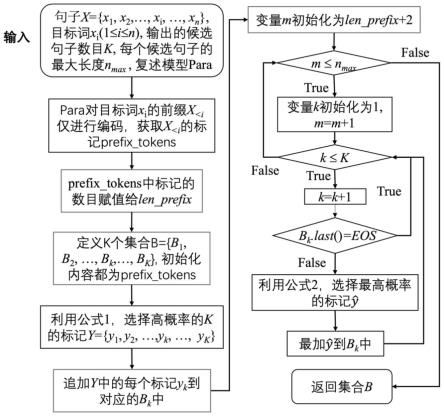
10.作为本发明所述的一种基于句子复述模型的英文词语替换方法的一种优 选方案,其中,所述生成复述句子包括:利用所述复述生成模型即para,结合 聚焦目标词的解码方法,生成k个复述句子;其中,k为用户给定的输出候选 句子的数目,每个候选句子的最大长度为n
max
且n
max
》i。
11.作为本发明所述的一种基于句子复述模型的英文词语替换方法的一种优 选方案,其中,所述生成k个复述句子包括:
12.a1:令输入的句子为x={x1,x2,
…
,xi,
…
,xn},目标词为xi(1≤i≤n); 其中,n为句子中词语的数目;
13.a2:利用para对目标词xi的前缀x
《i
={x1,x2,
…
,x
i-1
}进行编码,获取 x
《i
对应的标记prefix_tokens;
14.a3:定义变量len_prefix,其值为prefix_tokens中标记的数目;
15.a4:定义k个集合b={b1,b2,
…
,bk,
…
,bk};其中,每个bk初始化 的内容都为prefix_tokens;
16.a5:para对输入的句子x进行编码之后,para在解码过程中,强制指定 前面的前len_prefix个产生的标记为x
《i
对应的prefix_tokens;
17.a6:基于先前生成的prefix_tokens,利用para解码下一个标记y,获取词 汇表的概率分布p(y|x
《i
,x):
18.p(y|x
《i
,x)=softmax(g(x
i-1
,ti,si))
19.其中,softmax为归一化指数函数,g为非线性函数,ti为时间步长i时的 解码状态,si为时间长i时的输入句子的表示,由注意模型计算为输入句子的 加权和;
20.从概率分布p(y|x
《i
,x)中选择最高概率的k个标记y={y1,y2,
…
,yk,
…
,yk}:
[0021][0022]
其中,为词汇表;
[0023]
a7:追加y中每个标记yk到对应集合bk的最后;
[0024]
a8:对每个集合bk,分别采用贪婪搜索进行解码,直接遇到停止符eos 或者满足最大长度n
max
约束。
[0025]
作为本发明所述的一种基于句子复述模型的英文词语替换方法的一种优 选方案,其中,所述采用贪婪搜索进行解码包括:
[0026]
a81:初始化变量m为len_prefix 2;
[0027]
a82:若m≤n
max
,则继续a73;否则,对集合b的每个集合bk分别进行 去标记化处理,并返回最后的k的复述句子;
[0028]
a83:初始化变量k=1,并将m 1赋值给m;
[0029]
a84:若k<k,则继续a85;否则,返回a82;
[0030]
a85:将k 1赋值给k;
[0031]
a86:若集合bk的最后一个标记bk.last()为停止符eos,则返回a84; 否则,继续a87;
[0032]
a87:基于前一个解码的字符bk.last(),利用概率分布p,以选择最大概 率标记
[0033]
a88:追加到bk中,并返回a84。
[0034]
作为本发明所述的一种基于句子复述模型的英文词语替换方法的一种优 选方案,其中,所述提取候选替代词包括:
[0035]
从生成的k个候选句子b中,提取候选替代词;具体步骤如下:
[0036]
b1:从b中每个一个候选句子bk中,选择第i个词,构建初始候选词集合 cs={cs1,cs2,
…
,csk};
[0037]
b2:从cs中排除目标词xi和其对应的形态衍生词,生成最后的候选词集 合cs’={c1,
…
,co,
…
,c
p
}。
[0038]
作为本发明所述的一种基于句子复述模型的英文词语替换方法的一种优 选方案,其中,所述获取最终替代词包括:
[0039]
采用bertscore对cs’进行过滤,获取最终的替代词;
[0040]
所述bertscore自动计算原句子与新句子的相似度。
[0041]
作为本发明所述的一种基于句子复述模型的英文词语替换方法的一种优 选方案,其中,所述获取最终的替代词包括:
[0042]
c1:初始变量o为0,定义一个空的替代词集合ss;
[0043]
c2:将o 1赋值给o,若o≤p,继续c3;否则跳转到c7;
[0044]
c3:从cs’中选择co替代x中目标词xi,构建新句子xo;
[0045]
c4:计算xo和x的相似度s(x,xo):
[0046]
s(x,xo)=bertscore(x,xo)
[0047]
c5:若s(x,xo)>指定阈值μ,则将对应的co保存到替代词集合ss中;否 则,过滤到co;
[0048]
c6:执行步骤c2;
[0049]
c7:返回替代词集合ss,此即最终替代词。
[0050]
作为本发明所述的一种基于句子复述模型的英文词语替换方法的一种优 选方案,其中:所述阈值μ设置为0.7~0.85。
[0051]
本发明的有益效果:首次提出利用复述模型进行词语简化,很好地结合了 复述模型中包含的隐含监督信息;首次利用bertscore进行替代词的过滤,且 生成替代词时同时考虑目标词及其上下文信息;简化了替代步骤,在不需要转 换词语形态的情况下,即可生成替代词。
附图说明
[0052]
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需 要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的 一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下, 还可以根据这些附图获得其它的附图。其中:
[0053]
图1为本发明第一个实施例所述的一种基于句子复述模型的英文词语替换 方法的聚焦目标词的解码方法流程图;
[0054]
图2为本发明第二个实施例所述的一种基于句子复述模型的英文词语替换 方法的复述生成模型程序结果图;
[0055]
图3为本发明第二个实施例所述的一种基于句子复述模型的英文词语替换 方法的复述生成模型词语替换示意图;
[0056]
图4为本发明第二个实施例所述的一种基于句子复述模型的英文词语替换 方法的改进复述生成模型程序结果图;
[0057]
图5为本发明第二个实施例所述的一种基于句子复述模型的英文词语替换 方法的改进复述生成模型词语替换示意图。
具体实施方式
[0058]
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合说明书 附图对本发明的具体实施方式做详细的说明,显然所描述的实施例是本发明的 一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通人员 在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明的 保护的范围。
[0059]
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明 还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不 违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施例 的限制。
[0060]
其次,此处所称的“一个实施例”或“实施例”是指可包含于本发明至少 一个实现方式中的特定特征、结构或特性。在本说明书中不同地方出现的“在 一个实施例中”并非均指同一个实施例,也不是单独的或选择性的与其他实施 例互相排斥的实施例。
[0061]
本发明结合示意图进行详细描述,在详述本发明实施例时,为便于说明, 表示器件结构的剖面图会不依一般比例作局部放大,而且所述示意图只是示例, 其在此不应限制本发明保护的范围。此外,在实际制作中应包含长度、宽度及 深度的三维空间尺寸。
[0062]
同时在本发明的描述中,需要说明的是,术语中的“上、下、内和外”等 指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述 本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、 以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第 一、第二或第三”仅用于描述目的,而不能理解为指示或暗示相对重要性。
[0063]
本发明中除非另有明确的规定和限定,术语“安装、相连、连接”应做广 义理解,例如:可以是固定连接、可拆卸连接或一体式连接;同样可以是机械 连接、电连接或直接连接,也可以通过中间媒介间接相连,也可以是两个元件 内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在 本发明中的具体含义。
[0064]
实施例1
[0065]
参照图1,为本发明的第一个实施例,该实施例提供了一种基于句子复述 模型的英文词语替换方法,包括:
[0066]
s1:利用公开的复述语料,训练复述生成模型。
[0067]
复述生成模型是基于transformer的端到端的模型;基于transformer的端 到端的模型的编码器和解码器分别都是8层,向量维数为1024,每一层采用的 是16个头注意力机制,采用adam优化,采用的子词分割方法subword-nmt。
[0068]
具体的,复述生成模型能够在不改变句子语义的情况下,主要通过修改句 法或词汇的方式,生成多个候选句子;使用的复述语料是parabank2,包含了 19370798个句子对,
下载地址为https://nlp.jhu.edu/parabank/;基于transformer 的端到端的模型的初始学习率=0.0003,dropout比率=0.1,采用adam优化, 其中,β1=0.9,β2=0.999,ε=10-8
;句子的子词分割技术subword-nmt,来源于 https://github.com/rsennrich/subword-nmt。
[0069]
s2:利用复述生成模型,结合聚焦目标词的解码方法,生成复述句子。
[0070]
见图1,利用复述生成模型即para,结合聚焦目标词的解码方法,生成k 个复述句子;其中,k为用户给定的输出候选句子的数目,每个候选句子的最 大长度为n
max
且n
max
》i;
[0071]
生成k个复述句子包括:
[0072]
a1:令输入的句子为x={x1,x2,
…
,xi,
…
,xn},目标词为xi(1≤i≤n); 其中,n为句子中词语的数目;
[0073]
a2:利用para对目标词xi的前缀x
《i
={x1,x2,
…
,x
i-1
}进行编码,使用采 用的子词分割技术subword-nmt,获取x
《i
对应的标记prefix_tokens;
[0074]
a3:定义变量len_prefix,其值为prefix_tokens中标记的数目;
[0075]
a4:定义k个集合b={b1,b2,
…
,bk,
…
,bk};其中,每个bk初始化 的内容都为prefix_tokens;
[0076]
a5:para对输入的句子x进行编码之后,para在解码过程中,强制指定 前面的前len_prefix个产生的标记为x
《i
对应的prefix_tokens;
[0077]
a6:基于先前生成的prefix_tokens,利用para解码下一个标记y,获取词 汇表的概率分布p(y|x
《i
,x):
[0078]
p(y|x
《i
,x)=softmax(g(x
i-1
,ti,si))
[0079]
其中,softmax为归一化指数函数,g为非线性函数,ti为时间步长i时的 解码状态,si为时间步长i时的输入句子的表示,由基于transformer的端到端 的模型的注意力机制获取的输入句子的加权和;
[0080]
从概率分布p(y|x
《i
,x)中选择最高概率的k个标记y={y1,y2,
…
,yk,
…
, yk}:
[0081][0082]
其中,为词汇表;
[0083]
a7:追加y中每个标记yk到对应集合bk的最后;
[0084]
a8:对每个集合bk,分别采用贪婪搜索进行解码,直接遇到停止符eos 或者满足最大长度n
max
约束;
[0085]
a81:初始化变量m为len_prefix 2;
[0086]
a82:若m≤n
max
,则继续a73;否则,对集合b的每个集合bk分别进行 去标记化处理,并返回最后的结果;
[0087]
a83:初始化变量k=1,并将m 1赋值给m;
[0088]
a84:若k<k,则继续a85;否则,返回a82;
[0089]
a85:将k 1赋值给k;
[0090]
a86:若集合bk的最后一个标记bk.last()为停止符eos,则返回a84; 否则,继续a87;
[0091]
a87:基于前一个解码的字符bk.last(),利用概率分布p,以选择最大概 率标记
[0092]
a88:追加到bk中,并返回a84。
[0093]
s3:从复述句子中,提取候选替代词;
[0094]
从生成的k个候选句子b中,提取候选替代词;具体步骤如下:
[0095]
b1:从b中每个一个候选句子bk中,选择第i个词,构建初始候选词集合 cs={cs1,cs2,
…
,csk};
[0096]
b2:从cs中排除目标词xi和其对应的形态衍生词,生成最后的候选词集 合cs’={c1,
…
,co,
…
,c
p
}。
[0097]
s4:利用bertscore过滤候选替代词,以获取最终替代词。
[0098]
采用bertscore对cs’进行过滤,获取最终的替代词;
[0099]
bertscore自动计算原句子与新句子的相似度。
[0100]
c1:初始变量o为0,定义一个空的替代词集合ss;
[0101]
c2:将o 1赋值给o,若o≤p,继续c3;否则跳转到c7;
[0102]
c3:从cs’中选择co替代x中目标词xi,构建新句子xo;
[0103]
c4:计算xo和x的相似度s(x,xo):
[0104]
s(x,xo)=bertscore(x,xo)
[0105]
c5:阈值μ设置为0.7~0.85;若s(x,xo)>指定阈值μ,则将对应的co保存 到替代词集合ss中;否则,过滤到co;
[0106]
c6:执行步骤c2;
[0107]
c7:返回替代词集合ss,此即最终替代词。
[0108]
需要说明的是,给定两个句子a和b,bertscore计算a中每个标记与b 中每个标记的相似性得分;bertscore对句子a和b的每一个词分别计算内积, 可以得到一个相似性矩阵;基于这个矩阵,bertscore分别对a和b做一个最 大相似性得分的累加然后归一化,得到bertscore的精确率pre、召回率rec 和f1,其中,f1是pre和rec的调和平均值;实验中,使用的是bertscore 计算得到的f1值作为两个句子的相似度;采用bertscore的目的是使生成的 替代词对原句子语义的改变最小,因此选择嵌入替代词,计算新句子和原句子 的相似度。
[0109]
实施例2
[0110]
参照图2~5,为本发明的第二个实施例;为了对本方法中采用的技术效果 加以验证说明,本实施例选择传统方法和本方法进行对比,以科学论证的手段 对比试验结果,以验证本方法所具有的真实效果。
[0111]
实验一
[0112]
用户输入一个句子“thebooks were adaptedinto a television series”(这些书 被改编成电视剧)和目标词“adapted”;实验目标为:不改变句子意思的情况 下,获取adapted的替代词。
[0113]
(1)利用训练好的复述生成模型,设置k=5,采用光束搜索,如图2, 得到以下候选句子:
[0114]
①
books have been adapted to the tv series
[0115]
②
thebooks havebeen adapted to thetv series
[0116]
③
books have been adjusted to the tv series
[0117]
④
books were adapted to thetv series
[0118]
⑤
thebooks havebeen adjusted to thetv series
[0119]
如图3,可以更形象地显示这5个候选句子,其中,箭头上方的数字对应 候选句子的序号;从图3中可以看出,候选句子中也包含了“adapted”的替代 词“adjusted”;但是由于候选句子是关注整个句子而不只是目标词的变化,很 难从光束搜索得到的候选句子中获取目标词的多个替代词。
[0120]
(2)结合本方法的聚焦目标词的解码方法,如图4,生成的候选句子为:
[0121]
①
thebooks were adapted to the tv series
[0122]
②
thebooks were adjusted to thetv series
[0123]
③
thebooks were customized to the tv series
[0124]
④
thebooks were tailored to the tv series
[0125]
⑤
thebooks were modified into atv series
[0126]
如图5,可以更形象地显示这5个候选句子;从这些候选句子中,很容易 获取目标词的候选替代词“adapted,adjuisted,customized,tailored,modified”。
[0127]
实验二
[0128]
本方法利用最新的ls数据集——来自斯坦福单词替换数据集(swords) 来进行评估;swords包含833个样本,每个样本都由上下文、目标词和相应的 替代词组成;替代词组中的每个词都有一个分数,表明该词的恰当性;如果替 代词的得分大于50%,则可以采纳,而采纳的替代词平均数量为3.3。
[0129]
本方法将pre、rec和f1值用于候选替代词进行比较:假设测试集中有m 个样本,pre和recall、rec的度量精度由以下公式计算:
[0130][0131][0132]
其中pi表示第i个样本的一组带注释的替代词,qi表示生成的第i个样本的 一组候选词;#(pi)和#(qi)分别代表pi和qi中的单词数;只有前10个替代 词用于计算这些指标。
[0133]
本方法的评估结果将与现有方法embedding、wordnet、ppdb、bert-mask、 bert-keep、bert-drop、bert-merge、gpt3和wordtune进行比较:
[0134]
评估结果见表1,可知本方法获得了最高的pre评分和f1评分,大大优于 最佳基线bert-merge、gpt-3和wordtune;此外,本方法精确性得分最高, 因为该方法是唯一一种既考虑上下文又保留原始句子意义的方法,用于指导替 代词的生成。
[0135]
表1:评估结果对比表。
[0136][0137]
应当认识到,本发明的实施例可以由计算机硬件、硬件和软件的组合、或 者通过存储在非暂时性计算机可读存储器中的计算机指令来实现或实施。所述 方法可以使用标准编程技术-包括配置有计算机程序的非暂时性计算机可读存 储介质在计算机程序中实现,其中如此配置的存储介质使得计算机以特定和预 定义的方式操作——根据在具体实施例中描述的方法和附图。每个程序可以以 高级过程或面向对象的编程语言来实现以与计算机系统通信。然而,若需要, 该程序可以以汇编或机器语言实现。在任何情况下,该语言可以是编译或解释 的语言。此外,为此目的该程序能够在编程的专用集成电路上运行。
[0138]
此外,可按任何合适的顺序来执行本文描述的过程的操作,除非本文另外 指示或以其他方式明显地与上下文矛盾。本文描述的过程(或变型和/或其组合) 可在配置有可执行指令的一个或多个计算机系统的控制下执行,并且可作为共 同地在一个或多个处理器上执行的代码(例如,可执行指令、一个或多个计算 机程序或一个或多个应用)、由硬件或其组合来实现。所述计算机程序包括可 由一个或多个处理器执行的多个指令。
[0139]
进一步,所述方法可以在可操作地连接至合适的任何类型的计算平台中实 现,包括但不限于个人电脑、迷你计算机、主框架、工作站、网络或分布式计 算环境、单独的或集成的计算机平台、或者与带电粒子工具或其它成像装置通 信等等。本发明的各方面可以以存储在非暂时性存储介质或设备上的机器可读 代码来实现,无论是可移动的还是集成至计算平台,如硬盘、光学读取和/或 写入存储介质、ram、rom等,使得其可由可编程计算机读取,当存储介质 或设备由计算机读取时可用于配置和操作计算机以执行在此所描述的过程。此 外,机器可读代码,或其部分可以通过有线或无线网络传输。当此类媒体包括 结合微处理器或其他数据处理器实现上文所述步骤的指令或程序时,本文所述 的发明包括这些和其他不同类型的非暂时性计算机可读存储介质。当根据本发 明所述的方法和技术编程时,本发明还包括计算机本身。计算机程序能够应用 于输入数据以执行本文所述的功能,从而转换输入数据以生成存储至非易失性 存储器的输出数据。输出信息还可以应用于一个或多个输出设备如显示器。在 本发明优选的实施例中,转换的数据表示物理和有形的对象,包括显示器上产 生的物理和有形对象的特定视觉描绘。
[0140]
如在本技术所使用的,术语“组件”、“模块”、“系统”等等旨在指代计算 机相关实
体,该计算机相关实体可以是硬件、固件、硬件和软件的结合、软件 或者运行中的软件。例如,组件可以是,但不限于是:在处理器上运行的处理、 处理器、对象、可执行文件、执行中的线程、程序和/或计算机。作为示例, 在计算设备上运行的应用和该计算设备都可以是组件。一个或多个组件可以存 在于执行中的过程和/或线程中,并且组件可以位于一个计算机中以及/或者分 布在两个或更多个计算机之间。此外,这些组件能够从在其上具有各种数据结 构的各种计算机可读介质中执行。这些组件可以通过诸如根据具有一个或多个 数据分组(例如,来自一个组件的数据,该组件与本地系统、分布式系统中的 另一个组件进行交互和/或以信号的方式通过诸如互联网之类的网络与其它系 统进行交互)的信号,以本地和/或远程过程的方式进行通信。
[0141]
应说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参 照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可 以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精 神和范围,其均应涵盖在本发明的权利要求范围当中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。