1.本发明属于安全驾驶技术领域,具体涉及一种基于面部特征的安全驾驶行为分析的方法及系统。
背景技术:
2.随着经济的迅速发展,汽车也得到了快速的普及,在很多的长途行程中,驾驶员需要连续驾车几个小时或者通宵驾车,这种情况下驾驶员很容易处于疲劳状态,当出现接电话或者抽烟的行为时,驾驶员更容易分神,非常容易造成交通事故。因此对驾驶员的行为和疲劳状态进行监测并作出提醒是当下必需的。
3.现有技术中,通过监控器对驾驶员的驾驶行为进行监测,如驾驶员在驾驶过程中出现干扰驾驶的行为(如抽烟、接打电话等)或者是驾驶员处于疲劳状态(如不停地眨眼睛或者不停地打哈欠等),此时系统需要及时检测并分析出当前驾驶人的行为或者疲劳程度,再给予驾驶人相应的警示。
4.现有技术存在以下问题:
5.现有的驾驶行为分析能够分析一些基本的行为,但是随着图像背景变得复杂,往往不能很好地区分所识别的物体和图像背景而导致失效,虽然深度学习的方法能够提高动作识别的准确率,但是深度学习模型的网络规模过大,使得模型参数过大和计算量过大,导致应用在一般配置的硬件上很难实现实时性检测,同时因为疫情需要佩戴口罩导致对人脸关键点的检测上造成很大影响。
技术实现要素:
6.针对现有技术中存在的随着图像背景变得复杂,往往不能很好地区分所识别的物体和图像背景而导致失效,虽然深度学习的方法能够提高动作识别的准确率,但是深度学习模型的网络规模过大,使得模型参数过大和计算量过大,导致应用在一般配置的硬件上很难实现实时性检测,同时因为疫情需要佩戴口罩导致对人脸关键点的检测上造成很大影响问题,本发明提出了一种基于面部特征的安全驾驶行为分析的方法及系统,其目的为:能够保证实时性和准确性的前提下,对驾驶行为进行分析。
7.为实现上述目的本发明所采用的技术方案是:提供一种基于面部特征的安全驾驶行为分析的方法及系统,包括:
8.s1:利用联合监督和自监督的多任务学习,在各类人脸尺度图像上执行像素方面的人脸定位,定位出候选目标驾驶员人脸的位置;
9.s2:根据识别到的驾驶员人脸图像,使用3d人脸关键点检测模块对其进行标定,得到用于检测人脸行为特征的数个人脸关键点和头部姿态;
10.s3:提取s2得到的数个人脸关键点信息和头部姿态信息,将他们结合为特定的图像特征向量,然后将每帧的图像特征向量输入到卷积神经网络中,卷积神经网络输出状态特征向量,然后将所述状态特征向量输入到bilstm中,实时判断驾驶员的驾驶状态;
11.s4:首先使用rpn网络产生一系列粗粒度的候选框信息,然后对所述粗粒度的候选框信息进行分类与回归,以便进一步回归从而得到更加精确的候选框信息,然后采用特征融合操作用于目标检测网络,得到行为检测结果。
12.较优的,本发明所述s1具体为:
13.s1.1:将人脸尺度图像缩放成像素300*300;
14.s1.2:然后将人脸尺度图像输入到卷积神经网络中,提取人脸特征并输入到特征金字塔,得到带特征点的标定人脸框,并计算标定人脸框的预测值,所述预测值包括分类预测值、边界框回归值和特征点回归值;
15.s1.3:计算标定人脸框和所有预设的候选人脸框的交互比,取交互比中最大值的候选人脸框作为有效人脸框;
16.s1.4:通过标定人脸框和选择的有效人脸框,计算标定人脸框的特征点损失、边界框损失和分类损失。
17.较优的,本发明所述s2具体为:
18.基于有效人脸框,识别到驾驶员的人脸图像,然后通过模型训练得到一系列含有人脸关键点的特征图,最终输出基于五官和脸部轮廓的数个人脸关键点,以及头部姿态,所述头部姿态包括方位角、仰俯角和翻滚角;
19.然后通过损失函数计算预测值和真值之间的误差,所述损失函数的公式为:
[0020][0021]
其中,
[0022]
其中,φ(w)为正则化项,l(yi,f(xi;w))是损失函数,损失函数l采用的是l2损失, f(xi;w)表示网络预测的五官和脸部轮廓的预测值,yi表示五官和脸部轮廓的真实位置,即为真值,φ(w)表示参数w的正则化项,来对系数做限制。
[0023]
较优的,本发明s3中,所述驾驶状态包括专心驾驶、疲劳驾驶和左顾右盼。
[0024]
较优的,本发明s4具体为:
[0025]
s4.1:首先通过rpn网络产生一系列粗粒度的候选框信息,然后对所述候选框信息进行分类与回归,采用特征融合操作用于目标检测网络,整个目标检测网络采用的损失函数如下所示:
[0026][0027]
损失函数定义为位置误差与置信度误差的加权和,其中,权重系数α通过交叉验证设置为1,n是先验框的正样本数量;是一个指示参数,当时表示第i个先验框与第j个ground truth匹配,并且ground truth的类别为p;c为类别置信度预测值,l为先验框的所对应边界框的位置预测值,g是ground truth的位置参数;
[0028]
s4.2:对于位置误差,采用如下公式进行定义:
[0029]
[0030]
其中,b={cx,cy,w,h}、其中,b={cx,cy,w,h}、其中,b={cx,cy,w,h}、i表示每一个训练批次的锚框索引id为正样本 (pos),g表示预测的值,d表示真实的值;
[0031]
s4.3:对于置信度误差,采用如下公式进行定义:
[0032][0033][0034]
其中,表示对于每个预测检测框的真实类别,是网络的预测类别;
[0035]
s4.4:进行驾驶行为预测时,首先根据类别置信度确定其类别与置信度值,并过滤掉属于背景的预测框;然后根据设置的置信度阈值过滤掉低于置信度阈值的预测框;将留下的预测框进行解码,并根据置信度值进行降序排列,根据先验框得到每个预测框真实的位置参数,然后保留top-k个预测框,并通过nms算法,过滤掉存在重叠的预测框,剩余的预测框即为行为检测结果。
[0036]
本发明还提供了一种基于面部特征的安全驾驶行为分析的系统,包括:
[0037]
人脸检测模块:利用联合监督和自监督的多任务学习,在各类人脸尺度图像上执行像素方面的人脸定位,定位出候选目标驾驶员人脸的位置;
[0038]
人脸关键点检测模块:根据识别到的驾驶员人脸图像,使用3d人脸关键点检测模块对其进行标定,得到用于检测人脸行为特征的数个人脸关键点和头部姿态;
[0039]
疲劳检测模块:提取人脸关键点检测模块得到的数个人脸关键点信息和头部姿态信息,将他们结合为特定的图像特征向量,然后将每帧的图像特征向量输入到卷积神经网络中,卷积神经网络输出状态特征向量,然后将所述状态特征向量输入到bilstm 中,实时判断驾驶员的驾驶状态;
[0040]
行为检测模块:首先使用rpn网络产生一系列粗粒度的候选框信息,然后对所述粗粒度的候选框信息进行分类与回归,以便进一步回归从而得到更加精确的候选框信息,然后采用特征融合操作用于目标检测网络,得到行为检测结果。
[0041]
较优的,本发明人脸检测模块定位驾驶员人脸具体为:
[0042]
步骤1:将人脸尺度图像缩放成像素300*300;
[0043]
步骤2:然后将人脸尺度图像输入到卷积神经网络中,提取人脸特征并输入到特征金字塔,得到带特征点的标定人脸框,并计算标定人脸框的预测值,所述预测值包括分类预测值、边界框回归值和特征点回归值;
[0044]
步骤3:计算标定人脸框和所有预设的候选人脸框的交互比,取交互比中最大值的候选人脸框作为有效人脸框;
[0045]
步骤4:通过标定人脸框和选择的有效人脸框,计算标定人脸框的特征点损失、边界框损失和分类损失。
[0046]
较优的,本发明所述人脸关键点检测模块具体为:
[0047]
基于有效人脸框,识别到驾驶员的人脸图像,然后通过模型训练得到一系列含有人脸关键点的特征图,最终输出基于五官和脸部轮廓的数个人脸关键点,以及头部姿态,所述头部姿态包括方位角、仰俯角和翻滚角;
[0048]
然后通过损失函数计算预测值和真值之间的误差,所述损失函数的公式为:
[0049][0050]
其中,
[0051]
其中,φ(w)为正则化项,l(yi,f(xi;w))是损失函数,损失函数l采用的是l2损失, f(xi;w)表示网络预测的五官和脸部轮廓的预测值,yi表示五官和脸部轮廓的真实位置,即为真值,φ(w)表示参数w的正则化项,来对系数做限制。
[0052]
较优的,本发明所述疲劳检测模块中,所述驾驶状态包括专心驾驶、疲劳驾驶和左顾右盼。
[0053]
较优的,本发明所述行为检测模块对驾驶员行为检测具体为:
[0054]
首先通过rpn网络产生一系列粗粒度的候选框信息,然后对所述候选框信息进行分类与回归,采用特征融合操作用于目标检测网络,整个目标检测网络采用的损失函数如下所示:
[0055][0056]
损失函数定义为位置误差与置信度误差的加权和,其中,权重系数α通过交叉验证设置为1,n是先验框的正样本数量;是一个指示参数,当时表示第i个先验框与第j个ground truth匹配,并且ground truth的类别为p;c为类别置信度预测值,l为先验框的所对应边界框的位置预测值,g是ground truth的位置参数;
[0057]
对于位置误差,采用如下公式进行定义:
[0058][0059]
其中,b={cx,cy,w,h}、其中,b={cx,cy,w,h}、
i表示每一个训练批次的锚框索引id为正样本 (pos),g表示预测的值,d表示真实的值;
[0060]
对于置信度误差,采用如下公式进行定义:
[0061][0062][0063]
其中,表示对于每个预测检测框的真实类别,是网络的预测类别;
[0064]
进行驾驶行为预测时,首先根据类别置信度确定其类别与置信度值,并过滤掉属于背景的预测框;然后根据设置的置信度阈值过滤掉低于置信度阈值的预测框;将留下的预测框进行解码,并根据置信度值进行降序排列,根据先验框得到每个预测框真实的位置参数,然后保留top-k个预测框,并通过nms算法,过滤掉存在重叠的预测框,剩余的预测框即为行为检测结果。
[0065]
相比现有技术,本发明的技术方案具有如下优点/有益效果:
[0066]
1.本发明使用3d关键点检测,弥补了2d关键点检测在实际应用中存在着一些不足,例如识别准确率不高、活体检测准确率不高等问题。
[0067]
2.本发明在疲劳检测模方面,通过将人脸关键点信息和头部姿态的俯仰角信息结合,再通过设计的卷积神经网络中,能有效的判别疲劳状态。
[0068]
3.本发明在行为检测模块,使用rpn网络产生一系列粗粒度的候选框信息,然后对这些粗粒度的候选框信息进行分类与回归,以便进一步回归从而得到更加精确的框信息,采用了特征融合操作用于目标检测网络,有效提高了对小目标的检测效果。
附图说明
[0069]
为了更清楚地说明本发明实施方式的技术方案,下面将对实施方式中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
[0070]
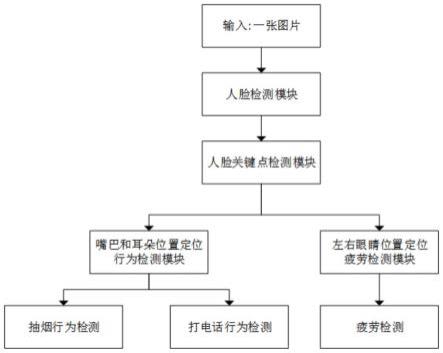
图1是本发明实施例1的流程示意图。
[0071]
图2是本发明实施例1的关键点检测示意图。
[0072]
图3是本发明实施例1的关键点人脸示意图。
[0073]
图4是本发明疲劳检测流程图。
具体实施方式
[0074]
为使本发明目的、技术方案和优点更加清楚,下面对本发明实施方式中的技术方案进行清楚、完整地描述,显然,所描述的实施方式是本发明的一部分实施方式,而不是全
部的实施方式。基于本发明中的实施方式,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施方式,都属于本发明保护的范围。因此,以下提供的本发明的实施方式的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施方式。
[0075]
实施例1:
[0076]
如图1、图2、图3和图4所示,本发明提出一种基于面部特征的安全驾驶行为分析的方法及系统,包括:
[0077]
s1:利用联合监督和自监督的多任务学习,在各类人脸尺度图像上执行像素方面的人脸定位,定位出候选目标驾驶员人脸的位置;s1具体为:
[0078]
s1.1:将人脸尺度图像缩放成像素300*300;
[0079]
s1.2:然后将人脸尺度图像输入到卷积神经网络中,提取人脸特征并输入到特征金字塔,得到带特征点的标定人脸框,并计算标定人脸框的预测值,所述预测值包括分类预测值、边界框回归值和特征点回归值;
[0080]
s1.3:计算标定人脸框和所有预设的候选人脸框的交互比,取交互比中最大值的候选人脸框作为有效人脸框;
[0081]
s1.4:通过标定人脸框和选择的有效人脸框,计算标定人脸框的特征点损失、边界框损失和分类损失。
[0082]
s2:根据识别到的驾驶员人脸图像,使用3d人脸关键点检测模块对其进行标定,如图2所示,得到用于检测人脸行为特征的68个人脸关键点和头部姿态;s2具体为:
[0083]
基于有效人脸框,识别到驾驶员的人脸图像,然后通过模型训练得到一系列含有人脸关键点的特征图,最终输出基于五官和脸部轮廓的68个人脸关键点,以及头部姿态,所述头部姿态包括方位角、仰俯角和翻滚角;如图3所示,其中,对重要的几个关键点作以说明:鼻尖为31,鼻根为28,下巴为9,左眼外角为37,左眼内角为40,右眼内角为43,右眼外角为46,嘴中心为67,嘴右角为55,左脸为1,右脸为17。
[0084]
然后通过损失函数计算预测值和真值之间的误差,所述损失函数的公式为:
[0085][0086]
其中,
[0087]
其中,φ(w)为正则化项,l(yi,f(xi;w))是损失函数,损失函数l采用的是l2损失, f(xi;w)表示网络预测的五官和脸部轮廓的预测值,yi表示五官和脸部轮廓的真实位置,即为真值,φ(w)表示参数w的正则化项,来对系数做限制。
[0088]
本实施例1中真值表示为五官和脸部轮廓的人脸关键点的真实位置。
[0089]
s3:提取s2得到的68个人脸关键点信息和头部姿态信息,将他们结合为68*6的图像特征向量,然后将每帧的图像特征向量输入到卷积神经网络中,卷积神经网络输出状态特征向量,然后将所述状态特征向量输入到bilstm中,实时判断驾驶员的驾驶状态;所述驾驶状态包括专心驾驶、疲劳驾驶和左顾右盼。在对戴口罩的驾驶员进行驾驶状态判断时,本实施例1通过判断不停眨眼睛或者打哈欠等表现,来判断驾驶员的疲劳程度。
[0090]
s4:首先使用rpn网络产生一系列粗粒度的候选框信息,然后对所述粗粒度的候选
框信息进行分类与回归,以便进一步回归从而得到更加精确的候选框信息,然后采用特征融合操作用于目标检测网络,得到行为检测结果。s4具体为:
[0091]
s4.1:首先通过rpn网络产生一系列粗粒度的候选框信息,然后对所述候选框信息进行分类与回归,采用特征融合操作用于目标检测网络,有效提高对小目标的检测效果,整个目标检测网络采用的损失函数如下所示:
[0092][0093]
损失函数定义为位置误差与置信度误差的加权和,其中,权重系数α通过交叉验证设置为1,n是先验框的正样本数量;是一个指示参数,当时表示第i个先验框与第j个ground truth匹配,并且ground truth的类别为p;c为类别置信度预测值,l为先验框的所对应边界框的位置预测值,g是ground truth的位置参数;
[0094]
s4.2:对于位置误差,采用如下公式进行定义(本发明对于位置的优化,采用smooth l1损失来优化):
[0095][0096]
其中,b={cx,cy,w,h}、其中,b={cx,cy,w,h}、其中,b={cx,cy,w,h}、其中,i表示每一个训练批次的锚框索引id为正样本(pos),对于检测出来的每一个识别框,通过和真实位置l在每个点的位置b(检测框的中心坐标x,y,和宽w和高h)通过对比来优化.g表示预测的值,d表示真实的值;
[0097]
该函数实际上是一个分段函数,在输入点x属于[-1,1]之间就是l2损失,解决l1 在0处有折点,在[-1,1]区间以外就是l1损失,解决离群点梯度爆炸问题。
[0098]
s4.3:对于置信度误差,采用如下公式进行定义(对于分类类别的优化,采用交叉熵损失来进行优化):
[0099][0100]
其中,交叉熵损失函数对每个检测框i属于不同的正样本(pos)和负样本(neg) 进行优化,表示对于每个预测检测框的真实类别,是网络的预测类别;
[0101][0102][0103]
其中,对于网络的预测类别得分,通过sotmax,归一化到[0,1]之间;
[0104]
s4.4:进行驾驶行为预测时,首先根据类别置信度确定其类别与置信度值,并过滤掉属于背景的预测框;然后根据设置的置信度阈值过滤掉低于置信度阈值的预测框;将留下的预测框进行解码,解码后还需要做clip,防止预测框位置超出图片,并根据置信度值进行降序排列,根据先验框得到每个预测框真实的位置参数,然后保留400 个预测框,并通过nms算法,过滤掉存在重叠的预测框,剩余的预测框即为行为检测结果。
[0105]
本发明还提供了一种基于面部特征的安全驾驶行为分析的系统,包括:
[0106]
人脸检测模块:利用联合监督和自监督的多任务学习,在各类人脸尺度图像上执行像素方面的人脸定位,定位出候选目标驾驶员人脸的位置;本发明人脸检测模块定位驾驶员人脸具体为:
[0107]
步骤1:将人脸尺度图像缩放成像素300*300;
[0108]
步骤2:然后将人脸尺度图像输入到卷积神经网络中,提取人脸特征并输入到特征金字塔,得到带特征点的标定人脸框,并计算标定人脸框的预测值,所述预测值包括分类预测值、边界框回归值和特征点回归值;
[0109]
步骤3:计算标定人脸框和所有预设的候选人脸框的交互比,取交互比中最大值的候选人脸框作为有效人脸框;
[0110]
步骤4:通过标定人脸框和选择的有效人脸框,计算标定人脸框的特征点损失、边界框损失和分类损失。
[0111]
人脸关键点检测模块:根据识别到的驾驶员人脸图像,使用3d人脸关键点检测模块对其进行标定,得到用于检测人脸行为特征的68个人脸关键点和头部姿态;本发明所述人脸关键点检测模块具体为:
[0112]
基于有效人脸框,识别到驾驶员的人脸图像,然后通过模型训练得到一系列含有人脸关键点的特征图,最终输出基于五官和脸部轮廓的68个人脸关键点,以及头部姿态,所述头部姿态包括方位角、仰俯角和翻滚角;
[0113]
然后通过损失函数计算预测值和真值之间的误差,所述损失函数的公式为:
[0114][0115]
其中,
[0116]
其中,φ(w)为正则化项,l(yi,f(xi;w))是损失函数,损失函数l采用的是l2损失, f(xi;w)表示网络预测的五官和脸部轮廓的预测值,yi表示五官和脸部轮廓的真实位置,即为真值,φ(w)表示参数w的正则化项,来对系数做限制。
[0117]
疲劳检测模块:如图4所示,提取人脸关键点检测模块得到的68个人脸关键点信息和头部姿态信息,将他们结合为68*6的图像特征向量,然后将每帧的图像特征向量输入到卷积神经网络中,卷积神经网络输出状态特征向量,然后将所述状态特征向量输入到bilstm中,实时判断驾驶员的驾驶状态;所述驾驶状态包括专心驾驶、疲劳驾驶和左顾右盼。
[0118]
行为检测模块:首先使用rpn网络产生一系列粗粒度的候选框信息,然后对所述粗粒度的候选框信息进行分类与回归,以便进一步回归从而得到更加精确的候选框信息,然后采用特征融合操作用于目标检测网络,得到行为检测结果。行为检测模块对驾驶员行为
检测具体为:
[0119]
首先通过rpn网络产生一系列粗粒度的候选框信息,然后对所述候选框信息进行分类与回归,采用特征融合操作用于目标检测网络,整个目标检测网络采用的损失函数如下所示:
[0120][0121]
损失函数定义为位置误差与置信度误差的加权和,其中,权重系数α通过交叉验证设置为1,n是先验框的正样本数量;是一个指示参数,当时表示第i个先验框与第j个ground truth匹配,并且ground truth的类别为p;c为类别置信度预测值,l为先验框的所对应边界框的位置预测值,g是ground truth的位置参数;
[0122]
对于位置误差,采用如下公式进行定义:
[0123][0124]
其中,b={cx,cy,w,h}、其中,b={cx,cy,w,h}、其中,b={cx,cy,w,h}、i表示每一个训练批次的锚框索引id为正样本(pos),g表示预测的值,d表示真实的值;
[0125]
对于置信度误差,采用如下公式进行定义:
[0126][0127][0128]
其中,表示对于每个预测检测框的真实类别,是网络的预测类别;
[0129]
进行驾驶行为预测时,首先根据类别置信度确定其类别与置信度值,并过滤掉属于背景的预测框;然后根据设置的置信度阈值过滤掉低于置信度阈值的预测框;将留下的预测框进行解码,解码后还需要做clip,防止预测框位置超出图片,并根据置信度值进行降序排列,根据先验框得到每个预测框真实的位置参数,然后保留400个预测框,并通过nms算法,过滤掉存在重叠的预测框,剩余的预测框即为行为检测结果。
[0130]
以上仅是本发明的优选实施方式,应当指出的是,上述优选实施方式不应视为对本发明的限制,本发明的保护范围应当以权利要求所限定的范围为准。对于本技术领域的普通技术人员来说,在不脱离本发明的精神和范围内,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。