技术特征:
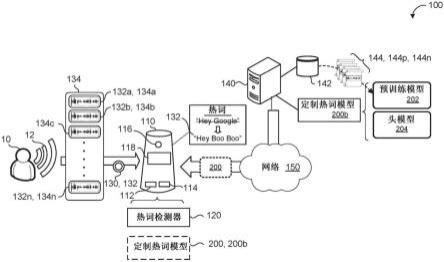
1.一种训练定制热词模型(200)的方法(300),所述方法(300)包括:在数据处理硬件(112)处接收第一训练音频样本集合(134),每个训练音频样本包含定制热词(132),所述定制热词(132)包括一个或多个词;通过所述数据处理硬件(112)使用被配置成接收所述第一训练音频样本集合(134)作为输入的语音嵌入模型(202)来为所述第一训练音频样本集合(134)中的每个训练音频样本(134)生成表示所述定制热词(132)的对应热词嵌入(208),所述语音嵌入模型(202)在与所述第一训练音频样本集合(134)不同的第二训练音频样本集合(144)上被预训练,所述第二训练音频样本集合(144)与所述第一训练音频样本集合(134)比包括更大数目的训练音频样本(144);以及通过所述数据处理硬件(112)训练所述定制热词模型(200)以在音频数据(12)中检测所述定制热词(132)的存在,所述定制热词模型(200)被配置成:接收使用所述语音嵌入模型(202)生成的每个对应热词嵌入(208)作为输入;并且将每个对应热词嵌入(208)分类为对应于所述定制热词(132)作为输出。2.根据权利要求1所述的方法(300),进一步包括,在训练所述定制热词模型(200)之后:在驻留在用户设备(110)上的数据处理硬件(112)处接收由所述用户设备(110)捕获的流音频数据(12);通过所述数据处理硬件(112)使用训练后的定制热词模型(200)来确定所述定制热词(132)是否存在于所述流音频数据(12)中;以及当所述定制热词(132)存在于所述流音频数据(12)中时,通过所述数据处理硬件(112)在所述用户设备(110)上发起唤醒过程以便处理所述定制热词(132)和/或在所述流音频数据(12)中跟随所述定制热词(132)的一个或多个其他词项。3.根据权利要求1或2所述的方法(300),其中,远程系统(140)在所述第二训练音频样本集合(144)上预训练所述语音嵌入模型(202),所述第二训练音频样本集合(144)包括:正训练音频样本(144p),所述正训练音频样本(144p)包含由一个或多个不同的讲话者讲出的目标热词的语料库;以及负训练音频样本(144n),所述负训练音频样本(144n)不包含来自所述目标热词的语料库的目标热词中的任一个。4.根据权利要求3所述的方法(300),其中,所述远程系统(140)被进一步配置成通过以下步骤来预训练所述语音嵌入模型(202):将所述目标热词的语料库划分成目标热词的多个随机组,目标热词的每个组包括来自所述目标热词的语料库的一个或多个目标热词的相应集合;对于从所述目标热词的语料库划分的目标热词的每个组,在所述语音嵌入模型(202)之上训练相应的预训练热词模型(200)以在所述第二训练音频样本集合(144)中检测来自目标热词的相应组的目标热词中的任一个的存在;以及训练所述语音嵌入模型(202)以针对目标热词的多个随机组学习代表性语音嵌入。5.根据权利要求1-4中的任一项所述的方法(300),其中,所述第一训练音频样本集合(134)包括从一个或多个语音合成系统输出的定制热词(132)的合成语音话语(162)。6.根据权利要求1-5中的任一项所述的方法(300),其中,所述第一训练音频样本集合
(134)包括:与讲出所述定制热词(132)的用户相对应的一个或多个人类生成的语音话语;以及从一个或多个语音合成系统输出的定制热词(132)的多个合成语音话语(162)。7.根据权利要求6所述的方法(300),其中,所述多个合成语音话语(162)中的至少一个合成语音话语(162)包括与所述多个合成语音话语(162)中的其他合成语音话语(162)不同的合成话音。8.根据权利要求6或7所述的方法(300),进一步包括:在所述数据处理硬件(112)处接收与所述定制热词(132)相对应的输入文本(164),所述输入文本(164)由用户经由在所述数据处理硬件(112)上运行的图形用户界面加以输入;以及通过所述数据处理硬件(112)使用所述输入文本(164)作为至所述一个或多个语音合成系统的输入来生成所述定制热词(132)的多个合成语音话语(162)。9.根据权利要求6-8中的任一项所述的方法(300),进一步包括:在所述数据处理硬件(112)处接收与讲出所述定制热词(132)的用户相对应的一个或多个人类生成的语音话语;通过所述数据处理硬件(112)来生成所述一个或多个人类生成的语音话语中的至少一个的转录(164);以及通过所述数据处理硬件(112)使用所述一个或多个人类生成的语音话语中的至少一个的转录(164)作为至所述一个或多个语音合成系统的输入来生成所述定制热词(132)的多个合成语音话语(162)。10.根据权利要求1-9中的任一项所述的方法(300),其中:所述语音嵌入模型(202)包括五个卷积块(210);并且所述定制热词模型(200)包括:一个卷积块(210),所述一个卷积块(210)被配置成接收来自所述语音嵌入模型(202)的五个卷积块(210)的最后卷积的输出作为输入;以及分类块(210),所述分类块(210)被配置成接收来自所述卷积块(210)的输出作为输入。11.根据权利要求10所述的方法(300),其中,所述语音嵌入模型(202)和所述定制热词模型(200)的每个卷积块(210)包括四个卷积层(212)和一个最大池层(212)。12.根据权利要求10或11所述的方法(300),其中,所述定制热词模型(200)的分类块(210)包括最大池层(212),跟随有卷积层(212)或全连接层(212)之一。13.根据权利要求1-12中的任一项所述的方法(300),其中,所述数据处理硬件(112)驻留在与用户相关联的用户设备(110)上。14.根据权利要求13所述的方法(300),其中,所述用户设备(110)的用户将所述定制热词(132)指配给所述用户设备(110)。15.一种系统(110),所述系统(110)包括:数据处理硬件(112);以及与所述数据处理硬件(112)通信的存储器硬件(114),所述存储器硬件(114)存储指令,所述指令当在所述数据处理硬件(112)上运行时使所述数据处理硬件(112)执行操作,所述操作包括:
接收第一训练音频样本集合(134),每个训练音频样本包含定制热词(132),所述定制热词(132)包括一个或多个词;使用被配置成接收所述第一训练音频样本集合(134)作为输入的语音嵌入模型(202)来为所述第一训练音频样本集合(134)中的每个训练音频样本(134)生成表示所述定制热词(132)的对应热词嵌入(208),所述语音嵌入模型(202)在与所述第一训练音频样本集合(134)不同的第二训练音频样本集合(144)上被预训练,所述第二训练音频样本集合(144)与所述第一训练音频样本集合(134)比包括更大数目的训练音频样本(144);以及训练所述定制热词模型(200)以在音频数据(12)中检测所述定制热词(132)的存在,所述定制热词模型(200)被配置成:接收使用所述语音嵌入模型(202)生成的每个对应热词嵌入(208)作为输入;并且将每个对应热词嵌入(208)分类为对应于所述定制热词(132)作为输出。16.根据权利要求15所述的系统(110),其中,所述操作进一步包括,在训练所述定制热词模型(200)之后:在用户设备(110)上接收由所述用户设备(110)捕获的流音频数据(12);使用训练后的定制热词模型(200)来确定所述定制热词(132)是否存在于所述流音频数据(12)中;以及当所述定制热词(132)存在于所述流音频数据(12)中时,在所述用户设备(110)上发起唤醒过程以便处理所述定制热词(132)和/或在所述流音频数据(12)中跟随所述定制热词(132)的一个或多个其他词项。17.根据权利要求15或16所述的系统(110),其中,远程系统(140)在所述第二训练音频样本集合(144)上预训练所述语音嵌入模型(202),所述第二训练音频样本集合(144)包括:正训练音频样本(144p),所述正训练音频样本(144p)包含由一个或多个不同的讲话者讲出的目标热词的语料库;以及负训练音频样本(144n),所述负训练音频样本(144n)不包含来自所述目标热词的语料库的目标热词中的任一个。18.根据权利要求17所述的系统(110),其中,所述远程系统(140)被进一步配置成通过以下步骤来预训练所述语音嵌入模型(202):将所述目标热词的语料库划分成目标热词的多个随机组,目标热词的每个组包括来自所述目标热词的语料库的一个或多个目标热词的相应集合;对于从所述目标热词的语料库划分的目标热词的每个组,在所述语音嵌入模型(202)之上训练相应的预训练热词模型(200)以在所述第二训练音频样本集合(144)中检测来自目标热词的相应组的目标热词中的任一个的存在;以及训练所述语音嵌入模型(202)以针对目标热词的多个随机组学习代表性语音嵌入。19.根据权利要求15-18中的任一项所述的系统(110),其中,所述第一训练音频样本集合(134)包括从一个或多个语音合成系统输出的定制热词(132)的合成语音话语(162)。20.根据权利要求15-19中的任一项所述的系统(110),其中,所述第一训练音频样本集合(134)包括:与讲出所述定制热词(132)的用户相对应的一个或多个人类生成的语音话语;以及从所述一个或多个语音合成系统输出的定制热词(132)的多个合成语音话语(162)。
21.根据权利要求20所述的系统(110),其中,所述多个合成语音话语(162)中的至少一个合成语音话语(162)包括与所述多个合成语音话语(162)中的其他合成语音话语(162)不同的合成话音。22.根据权利要求20或21所述的系统(110),其中,所述操作进一步包括:接收与所述定制热词(132)相对应的输入文本,所述输入文本由用户经由在所述数据处理硬件(112)上运行的图形用户界面加以输入;以及使用所述输入文本作为至所述一个或多个语音合成系统的输入来生成所述定制热词(132)的多个合成语音话语(162)。23.根据权利要求20-22中的任一项所述的系统(110),其中,所述操作进一步包括:接收与讲出所述定制热词(132)的用户相对应的一个或多个人类生成的语音话语;生成所述一个或多个人类生成的语音话语中的至少一个的转录(164);以及使用所述一个或多个人类生成的语音话语中的至少一个的转录(164)作为至所述一个或多个语音合成系统的输入来生成所述定制热词(132)的多个合成语音话语(162)。24.根据权利要求15-23中的任一项所述的系统(110),其中:所述语音嵌入模型(202)包括五个卷积块(210);并且所述定制热词模型(200)包括:一个卷积块(210),所述一个卷积块(210)被配置成接收来自所述语音嵌入模型(202)的五个卷积块(210)的最后卷积的输出作为输入;以及分类块(210),所述分类块(210)被配置成接收来自所述卷积块(210)的输出作为输入。25.根据权利要求24所述的系统(110),其中,所述语音嵌入模型(202)和所述定制热词模型(200)的每个卷积块(210)包括四个卷积层(212)和最大池层(212)。26.根据权利要求24或25所述的系统(110),其中,所述定制热词模型(200)的分类块(210)包括最大池层(212),跟随有卷积层(212)或全连接层(212)之一。27.根据权利要求15-26中的任一项所述的系统(110),其中,所述数据处理硬件(112)驻留在与用户相关联的用户设备(110)上。28.根据权利要求27所述的系统(110),其中,所述用户设备(110)的用户将所述定制热词(132)指配给所述用户设备(110)。
技术总结
一种训练定制热词模型(200)的方法(300)包括接收第一训练音频样本集合(134)。该方法还包括使用被配置成接收第一训练音频样本集合作为输入的语音嵌入模型(202)来为第一训练音频样本集合中的每个训练音频样本生成表示定制热词(132)的对应热词嵌入(208)。语音嵌入模型在与第一训练音频样本集合比具有更大数目的训练音频样本的不同的训练音频样本集合(144)上被预训练。该方法进一步包括训练定制热词模型以在音频数据(12)中检测定制热词的存在。定制热词模型被配置成接收每个对应热词嵌入作为输入并且将每个对应热词嵌入分类为对应于定制热词作为输出。对应于定制热词作为输出。对应于定制热词作为输出。
技术研发人员:马修
受保护的技术使用者:谷歌有限责任公司
技术研发日:2020.12.16
技术公布日:2022/7/22
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。